Existe um padrão para o caos? Vamos tentar encontrá-lo! Aprendizado de máquina com o exemplo de uma amostra específica.
Na verdade, sugiro fazer o download do arquivo no link. Há 3 arquivos csv no arquivo:
- train.csv - a amostra na qual você precisa treinar.
- test.csv - amostra auxiliar, que pode ser usada durante o treinamento, inclusive mesclada com o train.
- exam.csv - uma amostra que não participa do treinamento de forma alguma.
A amostra em si contém 5581 colunas com preditores, o alvo na coluna 5583 "Target_100", as colunas 5581, 5582, 5584, 5585 são auxiliares e contêm:
- 5581 coluna "Time" - data do sinal
- 5582 coluna "Target_P" - direção da negociação "+1" - compra / "-1" - venda
- 5584 coluna "Target_100_Buy" - resultado financeiro da compra
- 5585 coluna "Target_100_Sell" - resultado financeiro da venda.
O objetivo é criar um modelo que "ganhe" mais de 3.000 pontos na amostra exam.csv.
A solução deve ser feita sem espiar o exame, ou seja, sem usar os dados dessa amostra.
Para manter o interesse, é recomendável falar sobre o método que permitiu alcançar esse resultado.
As amostras podem ser transformadas da maneira que você quiser, incluindo a alteração do alvo, mas você deve explicar a essência da transformação, para que não seja um ajuste puro à amostra do exame.
O treinamento do que é chamado fora da caixa com o CatBoost, com as configurações abaixo - com a força bruta do Seed - fornece essa distribuição de probabilidade.
FOR %%a IN (*.) DO ( catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_8\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 8 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_16\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 16 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_24\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 24 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_32\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 32 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_40\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 40 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_48\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 48 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_56\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 56 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_64\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 64 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_72\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 72 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_80\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 80 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 )
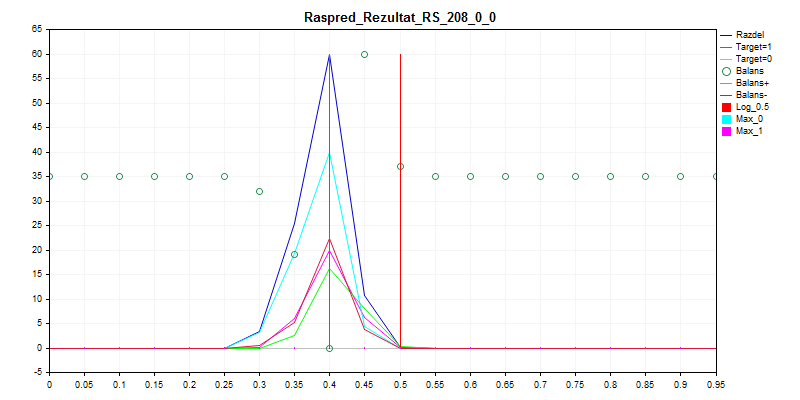
1. Trem de amostragem

2. Teste de amostragem
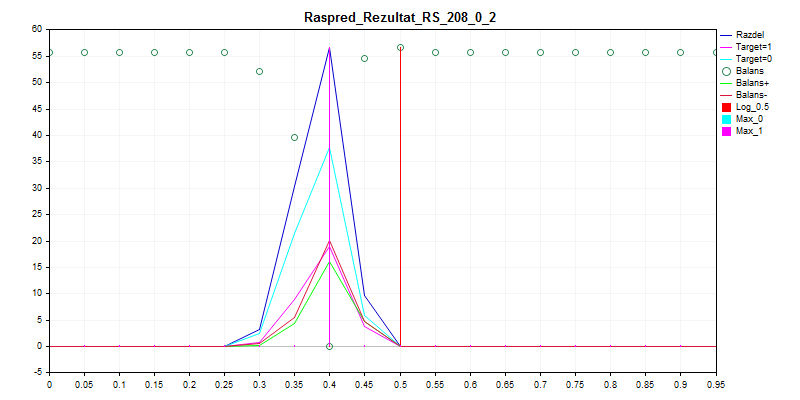
3. Amostra de exame
Como você pode ver, o modelo prefere classificar quase tudo por zero - assim, há menos chance de cometer um erro.
As últimas 4 colunas
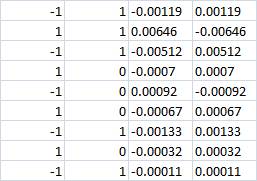
Com a classe 0, aparentemente a perda deve ser em ambos os casos? Ou seja, -0,0007 em ambos os casos. Ou, se a aposta de compra e venda ainda for feita, teremos lucro na direção certa?
Últimas 4 colunas
Com a classe 0, aparentemente a perda deve ser em ambos os casos? Ou seja, -0,0007 em ambos os casos. Ou, se a aposta de compra e venda ainda for feita, teremos lucro na direção certa?
Com nota zero, não entre na negociação.
Eu costumava usar 3 alvos - é por isso que as duas últimas colunas apresentam resultados finos em vez de um, mas com o CatBoost tive de mudar para dois alvos.
A direção 1/-1 é selecionada por uma lógica diferente, ou seja, o MO não está envolvido na seleção da direção? Você só precisa aprender a negociar/não negociar 0/1 (quando a direção é rigidamente escolhida)?
Sim, o modelo só decide se deve entrar ou não. Entretanto, dentro da estrutura desse experimento, não é proibido aprender um modelo com três alvos; para isso, basta transformar o alvo levando em conta a direção de entrada.
Se a classe for zero, não registre a transação.
Anteriormente, eu costumava usar 3 alvos - por isso as duas últimas colunas com resultado financeiro em vez de um, mas com o CatBoost tive de mudar para dois alvos.
Sim, o modelo apenas decide se deve entrar ou não. No entanto, dentro da estrutura desse experimento, não é proibido ensinar o modelo com três alvos; para isso, basta transformar o alvo levando em conta a direção da entrada.
Se a classe for zero, não registre a transação.
Anteriormente, eu costumava usar 3 alvos - por isso as duas últimas colunas com resultado financeiro em vez de um, mas com o CatBoost tive de mudar para dois alvos.
Sim, o modelo apenas decide se deve entrar ou não. No entanto, dentro da estrutura desse experimento, não é proibido ensinar o modelo com três alvos; para isso, basta transformar o alvo levando em conta a direção da entrada.
O Catbusta tem várias classes, é estranho abandonar 3 classes
Ou seja, se na classe 0 (não inserir) a direção correta da transação for escolhida, haverá lucro ou não?
Não haverá lucro (se você fizer uma reavaliação, haverá uma pequena porcentagem de lucro em zero).
É possível refazer o alvo corretamente apenas dividindo "1" em "-1" e "1", caso contrário, a estratégia será diferente.
Existe, mas não há integração na MQL5.
Não há descarregamento de modelos em nenhuma linguagem.
Provavelmente, é possível adicionar uma biblioteca dll, mas não consigo descobrir isso por conta própria.
Não haverá lucro (se você fizer uma reavaliação, haverá uma pequena porcentagem de lucro a zero).
Então, não há muito sentido nas colunas de resultados financeiros. Haverá também erros de previsão de classe 0 (em vez de 0, preveremos 1). E o preço do erro é desconhecido. Ou seja, a linha de equilíbrio não será construída. Especialmente porque você tem 70% da classe 0. Ou seja, 70% de erros com resultado financeiro desconhecido.
Você pode esquecer os 3.000 pontos. Se isso acontecer, não será confiável.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Na verdade, sugiro fazer o download do arquivo no link. Há 3 arquivos csv no arquivo:
A amostra em si contém 5581 colunas com preditores, o alvo na coluna 5583 "Target_100", as colunas 5581, 5582, 5584, 5585 são auxiliares e contêm:
O objetivo é criar um modelo que "ganhe" mais de 3.000 pontos na amostra exam.csv.
A solução deve ser feita sem espiar o exame, ou seja, sem usar os dados dessa amostra.
Para manter o interesse, é recomendável falar sobre o método que permitiu alcançar esse resultado.
As amostras podem ser transformadas da maneira que você quiser, incluindo a alteração da amostra de destino, mas você deve explicar a natureza da transformação para que não seja um ajuste puro à amostra do exame.