
From Basic to Intermediate: Arrays and Strings (III)

Introduction
The content presented here is intended solely for educational purposes. Under no circumstances should it be viewed for any purpose other than to learn and master the concepts presented.
In the previous article, From Basic to Intermediate: Arrays and Strings (II), I demonstrated in a very straightforward and accessible manner how you could already begin applying the knowledge presented up to that point. The goal was to show how to create two simple types of solutions, which many assume require far more advanced knowledge. However, everything covered and implemented in that article can, in fact, be achieved by any beginner in programming. Provided, of course, they use a bit of creativity and apply the concepts introduced thus far.
That said, although what was shown there indeed works and can be created without much difficulty, there's a small detail that can hinder many beginners. And this detail is directly related to the application demonstrated in that very article.
Many of you may have found yourselves wondering: "How was it possible to generate a password from two seemingly simple texts or phrases? I couldn't grasp why that worked. Even though I followed the idea and understood the code, that sort of thing didn't make any sense to me." The truth is, dear reader, there are aspects of programming that don't make much sense when observed by those who are not programmers. One such example is precisely what was done in that article, where we performed text manipulation using very simple and basic mathematics.
Since that kind of concept is widely used in various programming tasks, I believe it's worth explaining in more detail why it works. This will undoubtedly help you begin to think like a programmer rather than just a user. As a result, the main topic of this article - arrays - may be slightly postponed. However, we will still touch on arrays here, albeit in a simpler way. So let's begin with the first topic to understand why what was shown in the previous article actually works.
Translating Values
One of the most common tasks in programming is translating and handling information or databases. Programming is fundamentally about this. If you're thinking about learning how to program but don't understand that the purpose of an application is to create data that a computer can interpret, and then translate that data into information humans can understand, you're heading in the wrong direction. It would be better to stop and start again from scratch. Because, in truth, programming is entirely based on this simple principle. We have information that must be made comprehensible to the computer. Once the computer produces a result, we need to translate that result into something we can understand.
Computers are excellent at working with ones and zeros. But they're completely useless when it comes to processing any other type of information. The same applies to humans: we're terrible at interpreting strings of ones and zeros, but we can easily understand the meaning of a word or a graph.
Now, let's speak a bit more simply about some concepts. At the dawn of computing, the first processors had an OpCode set - a set of instructions for working with decimal values. Yes, dear reader, the earliest processors could understand what an 8 or a 5 was. These instructions were part of the BCD set, which allowed processors to work with numbers in a way that made sense to humans, but using binary logic.
However, over time, BCD instructions fell out of use. As it proved far more complex to design a circuit capable of performing decimal calculations than to perform calculations in binary and then convert the result to decimal. As a result, the responsibility of performing this translation shifted to the programmer.
Back then, dealing with floating-point numbers was practically a mess, a real "fruit salad". But that's a topic for another time, as with the tools and concepts presented so far, it wouldn't yet be possible to explain how floating-point systems work. I need to cover a few more concepts before getting there.
One important note: the BCD system is still used today, though not in the way you might imagine. In a future article, we'll play around with something related to the BCD system.
But let's get back to the main point. This is when the first translation libraries began to emerge, converting decimal values to binary, and vice versa. Other number bases such as hexadecimal and octal, which are more common in specific applications, also became supported.
Alright. This brings us to what was discussed in the previous articles, where I showed that MQL5 includes functions that allow us to perform this kind of translation. In all cases, the transformation is based on a string, which is either input or output. This string represents the human-readable information. The binary data is then sent to the computer for processing. However, although these libraries work well and are very convenient, they hide much of the underlying knowledge about how to manipulate data directly. Because of this, some programming courses don't actually produce programmers - they produce people who think they are programmers but don't understand how things work under the hood.
Since MQL5 gives us a certain degree of creative freedom, we can create something similar to one of these libraries (strictly for educational purposes). But it's important to note: any library created without a low-level language will not be faster or more efficient than the standard library. And when I say low-level language, I mean programming in C or C++. Because these two languages can produce code that closely resembles pure Assembly, nothing will be faster than them. So, what we'll explore here is strictly for educational purposes.
Great. Now that we've covered this initial explanation, let's build a small translator. With the knowledge we've covered so far, this will be a fairly simple task. In this translator, we'll first convert binary values into hexadecimal or octal, since these are easier to translate and require fewer operations. So, we will use the following code as our starting point.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. long value = 0xFEDAF3F4F5F6F7F8; 07. 08. PrintFormat("Translation via standard library.\n" + 09. "Decimal: %I64i\n" + 10. "Octal : %I64o\n" + 11. "Hex : %I64X", 12. value, value, value 13. ); 14. } 15. //+------------------------------------------------------------------+
Code 01
When we run code snippet 01, the terminal will display the output shown in Figure 01. Pay attention to the format specifiers used here. If different specifiers are used, the output will be different. Try experimenting with this later to better understand how this kind of formatting works.
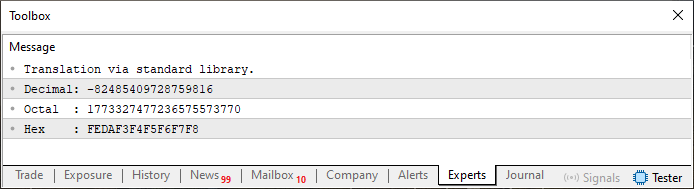
Figure 01
As you can see, this is quite simple, practical, and straightforward. But how does the standard library manage to do this? Well, that's the "magic" we are about to explore, dear reader. But before that, you need to understand another important concept: the formatting of the information being displayed. Yes, there is formatting behind this output. To keep things simple at this point, I'd like you to look up a specific table online. This table is very easy to find: it's called the ASCII table. To make things easier, I'll provide a version of this table below. There are other versions with more details, but what you see in Figure 02 is enough for our purposes here.
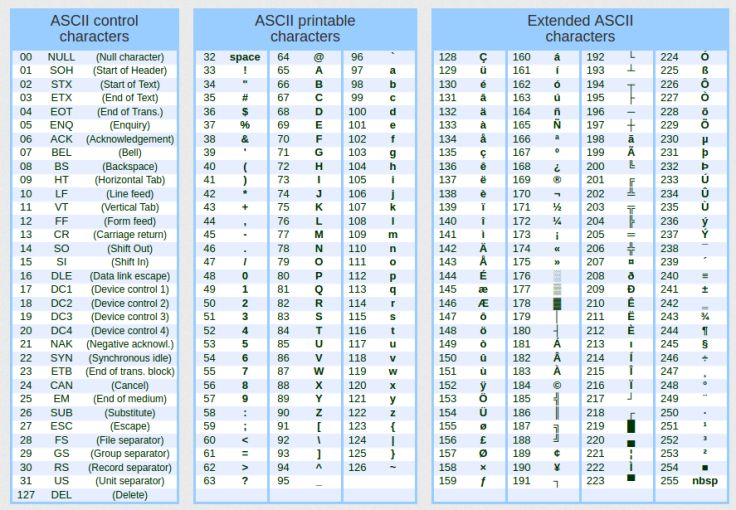
Figure 02
The part of the table that interests us is the section with printable characters, which is found in the center of Figure 02. The left side contains special characters, while the right side may vary depending on the table version; it could even be custom-defined by our application. However, this is not possible in the case of MQL5, since creating that portion would require access to specific parts of the hardware, which MQL5 does not allow, and which is also restricted in most high-level languages. This type of customization is usually only possible when working with low-level languages like C or C++. I'm mentioning this just so you're aware that the symbols on the right side of the table may differ depending on the implementation.
Alright, but why is the ASCII table so important for us here in MQL5? In truth, the ASCII table isn't just important here, it's essential for anyone who wants to manipulate data. There are other encoding tables, such as UTF-8, UTF-16, and ISO 8859, etc. Each of them has different values and symbols for various purposes. But in MQL5, we typically rely on the ASCII table, except in specific cases that require one of the others. We'll cover those exceptions in a future discussion.
Now then, dear reader, in order to translate information, you need to understand one key point. Let's look at Figure 02 again. To convert a binary value into a hexadecimal value, we need the digits 0 through 9 and the letters A through F.
Referring to the ASCII table, you'll see that the digit 0 corresponds to the decimal value 48. From there, each subsequent digit increases by one. So, for example, if we move six positions forward, corresponding to the digit 6, we'll be using the value 54. Got it? The same applies to letters. The uppercase letter A corresponds to the value 65. This gives us a starting point. Just remember that in hexadecimal, the letter A represents the value 10, B is 11, and so on, up to F, which represents 15.
It's all fairly simple. The only thing to be careful about is that between the digit 9 and the letter A, there are a few symbols in the ASCII table that need to be skipped. Otherwise, your hexadecimal string may include strange or unwanted characters. This happens if you directly access the ASCII table without filtering out those in-between values. However, even though this is possible, for our purposes here we'll take a slightly different approach. That's because the goal is to explain why the code shown in the previous article works.
So, to meet that objective, let's take a look at the new code. You can see it just below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. long value = 0xFEDAF3F4F5F6F7F8; 07. 08. PrintFormat("Translation via standard library.\n" + 09. "Decimal: %I64i\n" + 10. "Octal : %I64o\n" + 11. "Hex : %I64X", 12. value, value, value 13. ); 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s", 18. ValueToString(value, 0), 19. ValueToString(value, 1), 20. ValueToString(value, 2) 21. ); 22. } 23. //+------------------------------------------------------------------+ 24. string ValueToString(ulong arg, char format) 25. { 26. const string szChars = "0123456789ABCDEF"; 27. string sz0 = ""; 28. 29. while (arg) 30. { 31. switch (format) 32. { 33. case 0: 34. arg = 0; 35. break; 36. case 1: 37. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 38. arg >>= 3; 39. break; 40. case 2: 41. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 42. arg >>= 4; 43. break; 44. default: 45. return "Format not implemented."; 46. } 47. } 48. 49. return sz0; 50. } 51. //+------------------------------------------------------------------+
Code 02
When we run code snippet 02, the terminal output is as follows.
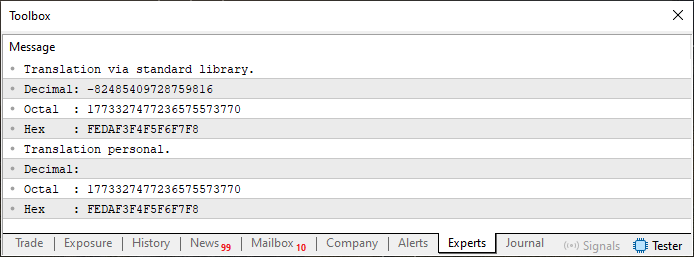
Figure 03
Since most of this code is fairly easy to understand for those who have been following and studying the content from previous articles, I will highlight only what happens in lines 37 and 41. This is due to the use of the AND operator to isolate certain bits. It may seem complicated, but it's actually much simpler than it looks.
Let's focus solely on line 37 for now. We know that an octal value contains only digits from 0 to 7. In binary, the number 7 is represented as 111. So, if we perform a bitwise AND operation with any value, the result will be a number between 0 and 7. The same logic applies to line 41, except that in this case, the resulting value will range from 0 to 15.
Now, take a look at line 26. That line defines the characters that will be used when creating the output. In MQL5, a string is a special kind of array. So when we access the string defined on line 26 in the way it's being accessed in lines 37 and 41, we are essentially retrieving one and only one of the characters within that string. So in fact, at this point, the sting IS NOT BEING ACCESSED as a traditional string, but rather as an array.
Due to how indexing works, element counting always begins at zero. However, this zero does not represent the size of the string - it represents the first character in it. If the string is empty, its length will be zero. If there is content, the length will be greater than zero. Nonetheless, the index will still start at zero.
I understand that, at first, this may seem confusing and entirely illogical. But as you become more familiar with using arrays, this type of logic will start to feel more and more natural, dear reader.
That said, there's still one element missing in this code snippet 02: handling decimal values. To properly deal with decimal values, we need a feature that I haven't yet explained - how to work with it, specifically. But to avoid leaving you without a proper explanation, let's make a simple assumption for now. There's no sense in needlessly complicating the code just to ensure the perfect representation of data. Besides, the way it's currently implemented - though missing a feature that will be covered later - we're already able to convert any integer value up to 64 bits in width with almost complete accuracy. Once we explore the missing feature, which involves the creation of templates and the use of typename, we'll be able to convert any value effortlessly. Until then, let’s focus only on the simpler aspects.
Now take note that the type declared in line six is a signed integer. Because of this, we would need to check whether the value is negative or not. However, to keep things from getting unnecessarily complicated, let's assume for now that all values will be unsigned integers. In other words, negative values will not be represented. With this assumption in place, we can modify the code and check whether the values are displayed correctly. This is accomplished using the implementation shown just below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. long value = 0xFEDAF3F4F5F6F7F8; 07. 08. PrintFormat("Translation via standard library.\n" + 09. "Decimal: %I64u\n" + 10. "Octal : %I64o\n" + 11. "Hex : %I64X", 12. value, value, value 13. ); 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s\n" + 18. "Binary : %s", 19. ValueToString(value, 0), 20. ValueToString(value, 1), 21. ValueToString(value, 2), 22. ValueToString(value, 3) 23. ); 24. } 25. //+------------------------------------------------------------------+ 26. string ValueToString(ulong arg, char format) 27. { 28. const string szChars = "0123456789ABCDEF"; 29. string sz0 = ""; 30. 31. while (arg) 32. switch (format) 33. { 34. case 0: 35. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 36. arg /= 10; 37. break; 38. case 1: 39. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 40. arg >>= 3; 41. break; 42. case 2: 43. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 44. arg >>= 4; 45. break; 46. case 3: 47. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 48. arg >>= 1; 49. break; 50. default: 51. return "Format not implemented."; 52. } 53. 54. return sz0; 55. } 56. //+------------------------------------------------------------------+
Code 03
As an extra bonus, in code snippet 03, I’ve also added the conversion of the value into its binary representation. It's just as simple as in the previous cases. In any event, once executed, the output of code 03 is shown below.
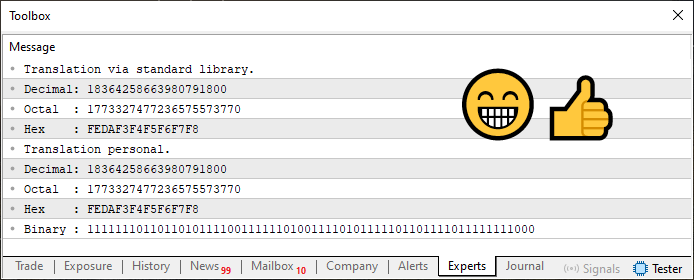
Figure 04
Now, dear reader, pay very close attention to something happening here. This might be the most important point discussed and demonstrated in this entire article. Between code 03 and code 02, there is almost no difference. However, if you compare Figure 03 and Figure 04, you'll notice something different.
The difference lies in the value shown for the translation using the standard library. Look closely at the DECIMAL value. You'll see that it differs. However, this doesn't quite make sense, since line six is exactly the same in both code 03 and code 04. So where is the discrepancy that caused the value to be printed in such an unexpected way?
Well, dear reader, the difference is found precisely in line nine. Examine line nine of code 03 and then code 04 very carefully. That tiny change alone is enough to flip the value, which, according to the type declared in line six, should have been negative, into a positive one. There is a way to fix this kind of issue. But as previously mentioned, it requires a concept that has not yet been explained.
Until then, be cautious when printing values to the terminal. A small oversight may lead you to misinterpret the calculated values. That's why it's essential to study and practice what is being shown. Simply reading documentation or articles like these is not enough to make you a skilled programmer. You must actively practice and internalize everything being presented.
That said, despite this minor discrepancy, you can see that the translation of the value into its decimal representation is absolutely correct. And note that the math needed for this conversion is quite straightforward. In line 35, we use the modulus operator % to obtain the remainder of the division by 10, which indicates which character from szChars should be used. Then, in line 36, we update the value of arg. To do this, we simply divide arg by 10. The resulting value is what will be used in the next step. And this is how we convert a binary value into one that is human-readable.
Based on this explanation, I believe that the code examples shown in the previous article can now be understood much more clearly. However, we can still improve on what was previously shown. To do that, we'll use the last code snippet provided in the previous article - the code that made more direct use of arrays. But to proceed properly, let's start a new topic.
Setting the Password Length
To begin discussing something we can modify in code 06 (as shown in the previous article), we first need to take a look at that piece of code here. It is shown below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg) 12. { 13. const string szCodePhrase = "The quick brown fox jumps over the lazy dog"; 14. 15. uchar psw[], 16. pos; 17. 18. ArrayResize(psw, StringLen(szArg)); 19. for (int c = 0; szArg[c]; c++) 20. { 21. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 22. psw[c] = (uchar)szCodePhrase[pos]; 23. } 24. return CharArrayToString(psw); 25. } 26. //+------------------------------------------------------------------+
Code 04
Now let's start with the following fact. There are two types of arrays that we can use: a static array and a dynamic array. What determines whether an array is static or dynamic is how it is declared. This has nothing to do with using the static keyword in the declaration. Since this topic is a bit complex to explain all at once, I'll give a brief summary just so you can understand code 04.
A dynamic array is declared as shown in line 15. Notice that we have the variable name, which in this case is 'psw', followed by an opening and closing bracket [] with nothing inside. This is a dynamic array. Being dynamic means that we can define its size at runtime. In fact, we must do so, because trying to access any element of an unallocated dynamic array is considered an error and will cause your code to terminate immediately. Because of this, we have in line 18 the point where we allocate enough memory to store data in the array.
Keep in mind: a string is a special kind of array. And unless it's declared as constant, a string is a dynamic array that does not require manual memory allocation. The compiler itself adds the necessary routines to handle this automatically, without our direct involvement. But since here we're not using a string but a regular array, we need to explicitly tell how much memory we want or need. And this is where a small but important detail lies.
During the execution of line 18 in code 04, if we specify the length of the password we want to generate, we can control things in a very effective way. At the same time, we can better manage the password that will be created. With that, we need a few small changes to code 04. These changes can be seen below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = "The quick brown fox jumps over the lazy dog"; 14. 15. uchar psw[], 16. pos; 17. 18. ArrayResize(psw, SizePsw); 19. for (int c = 0; szArg[c]; c++) 20. { 21. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 22. psw[c] = (uchar)szCodePhrase[pos]; 23. } 24. return CharArrayToString(psw); 25. } 26. //+------------------------------------------------------------------+
Code 05
Now pay close attention to the following fact. In line 8 of code 05, we're passing a new argument to the function on line 11. This same argument is being used on line 18 to determine how many characters the password will contain: in this case, eight characters. However, if you try to run code 05, it will fail. And the reason lies in line 22. This is because, in line 6, we're defining a secret phrase that contains more than eight characters. Since the loop on line 19 will only stop when it finds a NULL symbol in the string szArg, which is the string declared on line 6, we will eventually hit line 22, where we try to access an invalid memory position. This is an error, and the program will crash.
But this isn't actually a real problem. All we need to do is decide whether we want to use the entire phrase defined in line 6, or just a part of it to complete the eight-character password we want. Depending on our decision, we get a slightly different direction in how the final code will behave. That's why it is important to learn how to program. One programmer might propose a certain solution, but that might not be the best one for you. However, through communication, mutual understanding can be achieved. Being able to code lets you decide what works best in your case, instead of being completely dependent on someone else's decisions.
Alright, so let's make the following decision: we will use the entire secret phrase. But at the same time, we will modify the string from line 13 to a different one - the one that was shown in a previous article. This way we get something more interesting.
However, before we actually write the code, I want you to go back to Figure 02, shown in the previous section, and take a close look at each value in that table that appears in the string declared in line 6. Do you notice anything interesting in this data? The point is that if we decide to use the entire phrase from line 6, we will have to use some other trick here. Because if we make the change as shown in the code below, we will encounter some issues...
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. for (int c = 0; szArg[c]; c++) 21. { 22. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 23. psw[i++] = (uchar)szCodePhrase[pos]; 24. i = (i == SizePsw ? 0 : i); 25. } 26. return CharArrayToString(psw); 27. } 28. //+------------------------------------------------------------------+
Code 06
We are not actually using the entire phrase, but only a portion of it. In fact, we're using just the last eight characters of the secret phrase defined on line six. This can be confirmed by running code 06 and comparing the results with those shown in the previous article, where the same phrase was used as in code 06.
However, even without executing code 06, simply analyzing it reveals that although line 23 no longer causes the code to fail, it has little effect. That's because line 24 is forcing us to constantly overwrite the value of the password at the exact position defined as the password limit. As a result, even though the phrase on line six contains all those characters, in the end, it is as if only eight of them actually exist. This gives us a false sense of security when creating a secret phrase.
Now, as we know from Figure 02, each symbol is defined by a value, so we can use this array to calculate a sum of these values. That way, all symbols are effectively used. But pay close attention to one important detail here, dear reader. The maximum value we can assign in the array is determined by the type used in the array itself. I will go into more detail about this in the next article. For now, we can make a few more adjustments to the code, as shown below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. ArrayInitialize(psw, 0); 21. for (int c = 0; szArg[c]; c++) 22. { 23. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 24. psw[i++] += (uchar)szCodePhrase[pos]; 25. i = (i == SizePsw ? 0 : i); 26. } 27. return CharArrayToString(psw); 28. } 29. //+------------------------------------------------------------------+
Code 07
Now we finally have something that makes full use of the secret phrase. Note that only minimal changes were needed in the code. Among the changes, in line 20, we indicate that the array should be initialized with a specific value, which in this case is zero. You can choose a different initial value if you prefer. Doing so will make a difference later on, especially if your secret phrase contains repeated characters.
There are several different methods to avoid the same symbol being assigned the same value at different positions. This will be covered more in the next article. But the key detail here lies in line 24. Now we're summing the values, which means we're fully utilizing both phrases. However, there's a problem. This becomes clear when we run the code.
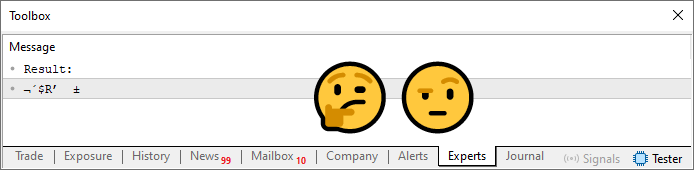
Figure 05
So how would you go about using this password? It's not easy, right? What's happening here is that the array contains values calculated by the sum, but they're restricted. We need to ensure that these calculated values actually map to one of the characters in the string declared on line 13. To achieve this, we need to add another loop. The final version of the code is shown below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. ArrayInitialize(psw, 0); 21. for (int c = 0; szArg[c]; c++) 22. { 23. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 24. psw[i++] += (uchar)szCodePhrase[pos]; 25. i = (i == SizePsw ? 0 : i); 26. } 27. 28. for (uchar c = 0; c < SizePsw; c++) 29. psw[c] = (uchar)(szCodePhrase[psw[c] % StringLen(szCodePhrase)]); 30. 31. return CharArrayToString(psw); 32. } 33. //+------------------------------------------------------------------+
Code 08
Now, after passing through the loop at line 28 of code 08, we get a result that you can see in the figure below.
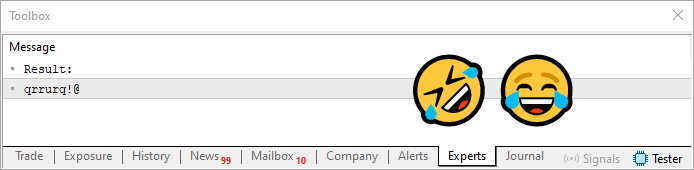
Figure 06
Now that is what I call a lucky coincidence. I had just been talking about how a password might include repeated characters, and how we might address that. And to our delight, the result turned out to have repeated characters. That's some serious luck! (laughs)
Final conclusions
In this article, we partially explored how binary values are translated into other formats. We also took our first steps toward understanding how a string can be treated like an array. In addition, we learned how to avoid a very common error when working with arrays in our code. However, what we saw here ended on a happy accident, which we'll explore in more detail in the next article. There, we will also see how to prevent situations like this from happening in the future. We will also continue expanding our understanding of data types in arrays. See you soon!
Translated from Portuguese by MetaQuotes Ltd.
Original article: https://www.mql5.com/pt/articles/15461
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use