혼돈에 패턴이 있을까요? 찾아보겠습니다! 특정 샘플의 예에 대한 머신 러닝.
실제로 링크에서 파일을 다운로드하는 것이 좋습니다. 아카이브에는 3개의 CSV 파일이 있습니다:
- train.csv - 훈련해야 하는 샘플입니다.
- test.csv - 보조 샘플로, train과 병합하는 것을 포함하여 훈련 중에 사용할 수 있습니다.
- exam.csv - 어떤 식으로든 교육에 참여하지 않는 샘플입니다.
샘플 자체에는 예측자가 있는 5581 열, 5583 열 "Target_100"의 대상, 5581, 5582, 5584, 5585 열이 보조적이며 다음을 포함합니다:
- 5581 열 "시간" - 신호의 날짜
- 5582 열 "Target_P" - 거래 방향 "+1" - 매수 / "-1" - 매도
- 5584 열 "Target_100_Buy" - 구매로 인한 재무 결과
- 5585 열 "Target_100_Sell" - 판매로 인한 재무 결과.
목표는 exam.csv 샘플에서 3000점 이상을 "획득"하는 모델을 만드는 것입니다.
이 솔루션은 시험을 들여다보지 않고, 즉 이 샘플의 데이터를 사용하지 않고 만들어야 합니다.
관심을 유지하기 위해 - 그러한 결과를 얻을 수있는 방법에 대해 이야기하는 것이 바람직합니다.
샘플은 대상 변경을 포함하여 원하는 방식으로 변환 할 수 있지만 변환의 본질을 설명해야하므로 시험 샘플에 순수한 피팅이 아닙니다.
아래 설정을 사용하여 CatBoost로 즉시 호출되는 것을 훈련하고 시드 무차별 대입으로 이 확률 분포를 제공합니다.
FOR %%a IN (*.) DO ( catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_8\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 8 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_16\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 16 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_24\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 24 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_32\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 32 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_40\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 40 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_48\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 48 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_56\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 56 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_64\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 64 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_72\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 72 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_80\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 80 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 )
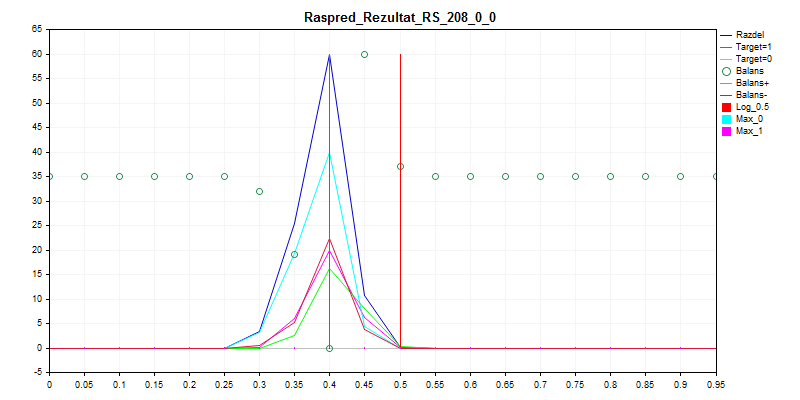
1. 샘플링 기차

2. 샘플 테스트
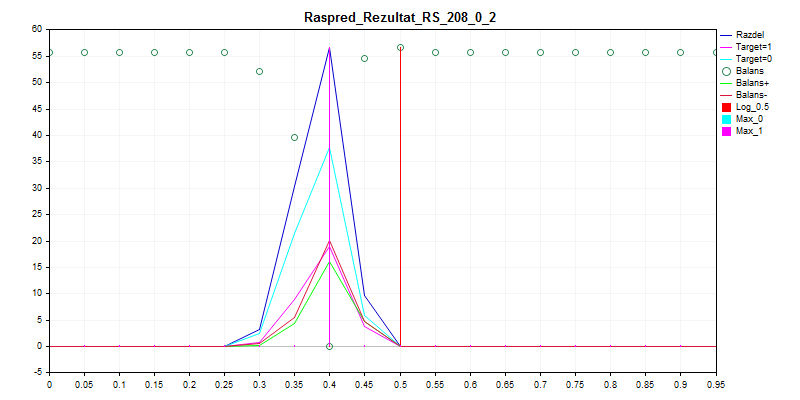
3. 시험 샘플
보시다시피 이 모델은 거의 모든 것을 0으로 분류하는 것을 선호하므로 실수할 가능성이 적습니다.
마지막 4개의 열
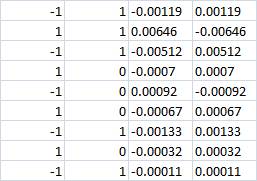
0 클래스를 사용하면 두 경우 모두 손실이 발생해야 하나요? 즉, 두 경우 모두 -0.0007입니다. 아니면 매수|매도 베팅이 여전히 이루어진다면 올바른 방향으로 수익을 낼 수 있을까요?
마지막 4개의 칼럼
0 클래스를 사용하면 두 경우 모두 손실이 발생해야 하나요? 즉, 두 경우 모두 -0.0007입니다. 아니면 매수|매도 베팅이 여전히 이루어진다면 올바른 방향으로 이익을 얻을 수 있을까요?
0 등급으로 - 거래를 시작하지 마십시오.
저는 3개의 타겟을 사용했었기 때문에 마지막 두 열에 핀 결과가 하나가 아닌 두 개로 표시되었지만 CatBoost를 사용하면 두 개의 타겟으로 전환해야 했습니다.
1/-1 방향은 다른 로직에 의해 선택됩니다. 즉, MO가 방향 선택에 관여하지 않습니까? 0/1 거래/거래 없음(방향이 엄격하게 선택된 경우)만 학습하면 되는 건가요?
예, 모델은 진입 여부만 결정합니다. 그러나 이 실험의 틀 내에서 세 가지 목표가 있는 모델을 학습하는 것은 금지되지 않으며, 이를 위해 진입 방향을 고려하여 목표를 변형하는 것으로 충분합니다.
그러면 재무 결과 열의 의미가 거의 없습니다. 또한 0 클래스 예측의 오류도 있을 것입니다(0 대신 1을 예측할 것입니다). 그리고 오류의 가격은 알 수 없습니다. 즉, 균형 선이 만들어지지 않습니다. 특히 클래스 0의 70%가 있기 때문에 더욱 그렇습니다. 즉, 재무 결과를 알 수없는 오류의 70 %.
약 3000 포인트를 잊을 수 있습니다. 그렇게하면 신뢰할 수 없습니다.
실제로 링크에서 파일을 다운로드하는 것이 좋습니다. 아카이브에는 3개의 CSV 파일이 있습니다:
샘플 자체에는 예측자가 있는 5581 열, 5583 열 "Target_100"의 대상, 5581, 5582, 5584, 5585 열이 보조적이며 다음을 포함합니다:
목표는 exam.csv 샘플에서 3000점 이상을 "획득"하는 모델을 만드는 것입니다.
이 솔루션은 시험을 들여다보지 않고, 즉 이 샘플의 데이터를 사용하지 않고 만들어야 합니다.
관심을 유지하기 위해 - 그러한 결과를 얻을 수있는 방법에 대해 이야기하는 것이 바람직합니다.
샘플은 대상 샘플 변경을 포함하여 원하는 방식으로 변형할 수 있지만, 시험 샘플에 순수하게 적합하지 않도록 변형의 특성을 설명해야 합니다.