elibrarius #: 두 번째 상반기 샘플은요? 점점 나아지고 있습니다. 그리고 첫 번째 샘플에서도 지고 있습니다.
네, H1 샘플에 대해 이야기하고 있습니다. 처음에는 train.csv에서 훈련하고, test.csv에서 중지하고, exam.csv에서 독립적으로 확인하므로 열이 두 개인 변형은 test.csv에서 실패합니다. 어제의 변형도 손실이 있었지만 약간의 수익을 낸 변형도 있었습니다.
그리고 이것이 10000 라인에서 20000 라인에 대한 교육을 통해 앞으로 나아가는 방법입니다. 즉, 차트는 2 년이 아니라 5 년을 보여줍니다. 그 중 2 년은 드로 다운에 앉아 있어야하고, 그 후 1 년은 이익없이 평균 상금이 다시 거래 당 0.00002로 떨어졌습니다. 2 회 열에서만.
5000 개 이상의 모든 열에서 동일한 설정. 약간 나아졌습니다. 거래 당 0.00003.
모든 열에서 0.00002 이상이지만 앞서 말했듯이 " 스프레드, 슬리피지 등이 모든 이익을 먹어 치울 것입니다". Teriminal은 바당 최소 스프레드를 표시하지만 (즉, 전체 시간 동안) 거래 순간에는 5 ~ 10 포인트가 될 수 있으며 뉴스에서는 20 이상이 될 수 있습니다.
그래서 내가 가진 마크 업은 분 막대에서 취해지며 스프레드는 일반적으로 일정 기간에 걸쳐 넓어집니다. 즉, 1 분 이내에 항상 큰 스프레드가있을 수 있습니까, 아니면 지금은 그렇지 않습니까? 5에서 스프레드가 어떻게 작동하는지조차 파악하지 못했습니다. 4에서 테스트하는 것이 더 편리하다는 것을 알았습니다.
다음은 10000개의 행에서 20000개의 행을 훈련하는 롤포워드 방식입니다. 즉, 그래프에서 2 년이 아니라 5 년이 아닙니다. 2 년은 드로 다운에 앉아 있어야하고, 이로 인해 평균 상금이 다시 거래 당 0.00002로 떨어졌기 때문에 이익없이 또 다른 1 년을 보내야합니다. 2 회 열에만 해당됩니다.
5000 개 이상의 모든 열에서 동일한 설정. 약간 나아졌습니다. 거래 당 0.00003.
그래도 다른 예측 변수도 유용할 수 있습니다. 그룹으로 추가하려고 시도 할 수 있으며 먼저 상관 관계를 선별하고 약간 줄일 수 있습니다.
기대 행렬과 관련하여이 전략에서는 캔들 개시가 아니라 시초가에서 동일한 30 핍으로 입력하는 것이 더 유리할 수 있습니다. 꼬리가없는 캔들은 드뭅니다.
그래서 내가 가진 마크 업은 분 막대에서 가져오고 스프레드는 일반적으로 일정 시간에 걸쳐 넓어집니다. 즉, 1 분 이내에 항상 큰 스프레드가있을 수 있습니까? 5에서 스프레드가 어떻게 작동하는지조차 파악하지 못했습니다. 저에게는 4에서 테스트하는 것이 더 편리합니다.
그리고 M1에서도 바 시간에 대한 최소 스프레드가 유지됩니다. ECH 계정에서 거의 모든 M1 바는 0.00001...0.00002이며 그 이상은 거의 없습니다. 모든 시니어 바는 M1로 만들어지며, 즉 최소 스프레드가 동일합니다. 라운드당 4포인트의 수수료를 추가해야 합니다(다른 중개 센터는 다른 수수료가 있을 수 있습니다).
그러나 다른 예측 인자들도 유용 할 수 있습니다. 그룹으로 추가하려고 시도 할 수 있으며 먼저 상관 관계를 찾아서 약간 줄일 수 있습니다.
아마도 우리는 그것들을 선택해야 할 것입니다. 하지만 5000개 이상을 2개로 추가해도 약간의 개선이 있다면 모델 학습을 통해 전체 무차별 대입으로 10개씩 선택하는 것이 더 빠를 수 있습니다. 24시간 동안 상관관계를 기다리는 것보다 더 빠를 것 같습니다. 터미널에서 직접 루프에서 재학습을 자동화하는 것만 필요합니다.
Так уж сложилось, что сейчас мало кто из разработчиков помнит, как написать простую DLL библиотеку и в чем особенности связывания разнородных систем. Я постараюсь за 10 минут на примерах продемонстрировать весь процесс создания простых DLL библиотек и раскрою некоторые технические детали нашей реализации связывания. Покажу пошаговый процесс создания DLL библиотеки в Visual Studio с примерами передачи разных типов переменных (числа, массивы, строки и т.д.) и защиту клиентского терминала от падений в пользовательских DLL.
선택해야 할 수도 있습니다. 하지만 2초에 5000개 이상을 추가해도 약간의 개선이 있다면 모델 훈련을 통해 완전 무차별 대입으로 10개를 선택하는 것이 더 빠를 수 있습니다. 24시간 동안 상관관계를 기다리는 것보다 더 빠를 것 같습니다.
예, 처음에는 그룹으로 수행하는 것이 좋습니다. 예를 들어 10 개의 그룹을 만들고 그 조합으로 훈련하고 모델을 평가하고 가장 실패한 그룹을 제거하고 나머지 그룹을 다시 그룹화하는 것, 즉 그룹의 예측자 수를 줄이고 다시 훈련 할 수 있습니다. 이전에 이 방법을 사용한 적이 있는데 효과는 있지만 빠르지는 않습니다.
터미널을 통해 완전한 학습 제어를 할 수 있으면 좋겠지만 제가 알기로는 준비된 솔루션이 없습니다. 모델만 적용하는 catboostmodel.dll 라이브러리가 있지만 MQL5에서 구현하는 방법을 모르겠습니다. 물론 이론적으로는 교육용 라이브러리 형태의 인터페이스를 만들 수 있습니다. 코드는 공개되어 있지만 감당할 수 없습니다.
예를 들어 10 개의 그룹을 만들고 조합하여 훈련하고 모델을 평가하고 가장 실패한 그룹을 제거하고 나머지 그룹을 다시 그룹화하여 그룹의 예측 변수 수를 줄이고 다시 훈련 할 수 있습니다. 이전에 이 방법을 사용한 적이 있는데 효과는 있지만 빠르지는 않습니다.
저는 다른 방법을 제안합니다. 모델에 기능을 하나씩 추가합니다. 그리고 가장 좋은 것을 선택합니다. 1) 하나의 기능에 대해 5000 개 이상의 모델을 훈련합니다. 2) 2개의 특징에 대해 (5000+-1) 모델을 훈련합니다: 첫 번째 가장 좋은 특징과 (5000+-1) 나머지 특징. 두 번째로 좋은 것을 찾습니다. 3) 3개의 특징에 대해 (5000+-2) 모델을 훈련합니다: 첫 번째, 두 번째 가장 좋은 특징과 (5000+-2) 나머지 특징에 대해. 세 번째로 좋은 것을 찾습니다. 모델이 개선될 때까지 반복합니다. 저는 보통 6~10개의 기능을 추가한 후 모델 개선을 중단합니다. 10~20개까지 또는 추가하고 싶은 만큼의 기능을 추가할 수도 있습니다.
하지만 테스트별로 기능을 선택하는 것이 데이터의 테스트 섹션에 모델을 맞추는 것이라고 생각합니다. 가중치가 0.3인 트레이닝과 가중치가 0.7인 테스트별로 선택하는 변형이 있습니다. 하지만 그것도 적합하다고 생각합니다.
나는 롤 포워드를하고 싶었고, 피팅은 많은 테스트 섹션에 대한 피팅이 될 것이고, 계산하는 데 더 오래 걸리지 만 이것이 최선의 선택 인 것 같습니다.
캣버스터를 실행하기위한 자동화가 없지만.... 5만 번 이상 수동으로 모델을 재훈련하여 10개의 기능을 얻기는 어려울 것입니다. 이것이 제가 캣버스터보다 제 기술을 선호하는 이유입니다. 비록 캣버스트보다 5~10배 느리게 작동하지만요. 당신은 3분 동안 모델 하나를 만들었지만 저는 22개를 만들었죠.
제가 제안하는 것은 그런 것이 아닙니다. 모델에 기능을 하나씩 추가합니다. 그리고 가장 좋은 것을 선택합니다. 1) 하나의 기능에 대해 5000개 이상의 모델 훈련: 5000개 이상의 기능 각각. 2) 2개의 기능에 대해 (5000+-1) 모델을 훈련시킵니다: 첫 번째 가장 좋은 기능과 (5000+-1) 나머지 기능. 두 번째로 좋은 것을 찾습니다. 3) 3개의 특징에 대해 (5000+-2) 모델을 훈련합니다: 첫 번째, 두 번째 가장 좋은 특징과 (5000+-2) 나머지 특징에 대해. 세 번째로 좋은 것을 찾습니다. 모델이 개선될 때까지 반복합니다. 저는 보통 6~10개의 기능을 추가한 후 모델 개선을 중단합니다. 10~20개까지 또는 추가하고 싶은 만큼의 기능을 추가할 수도 있습니다.
접근 방식은 다를 수 있습니다. 본질은 일반적으로 동일하지만 단점은 물론 계산 비용이 너무 높다는 것입니다.
그러나 테스트에 의한 기능 선택은 데이터의 테스트 섹션에 모델을 맞추는 것이라고 생각합니다. 가중치 0.3의 트레이닝에 의한 선택과 가중치 0.7의 테스트에 의한 선택의 변형이 있습니다. 하지만 그것도 적합하다고 생각합니다.
나는 밸브를 앞으로 만들고 싶고, 피팅은 많은 테스트 섹션에 대한 피팅이 될 것이며 계산하는 데 더 오래 걸리지 만 이것이 최선의 선택 인 것 같습니다.
그렇기 때문에 기능 선택을 정당화하기 위해 기능 내부에서 합리적인 곡물을 찾고 있습니다. 지금까지는 이벤트의 반복 빈도와 클래스 확률을 변경하기로 결정했습니다. 평균적으로 그 효과는 양수이지만 이 방법은 상관관계가 있는 예측 변수를 고려하지 않고 실제로 첫 번째 분할로 평가합니다. 그러나 두 번째 분할에 대해서도 동일한 방법을 시도하여 샘플에서 강한 부정적 성향이 있는 예측자 점수의 행을 제거해야 한다고 생각합니다.
elibrarius #: catbusters를 실행하는 자동화가 없지만.... 5만 번 이상 수동으로 모델을 재학습하여 10개의 특성을 얻는 것은 어려울 것입니다. 이것이 제가 캣버스터보다 제 크래프트를 선호하는 대략적인 이유입니다. 비록 컷버스트보다 5~10배 느리게 작동하지만요. 당신은 모델 하나를 세는 데 3분이 걸렸지만 저는 22개를 세웠어요.
그래도 제 기사를 읽어보세요.... 이제 모든 것이 반자동 형태로 작동합니다. 작업이 생성되고 부트 닉이 시작됩니다 (교육에 사용할 기능 수에 대한 작업 포함, 즉 모든 변형을 한 번에 생성하고 실행할 수 있음). 본질적으로 터미널에 박쥐 파일을 실행하도록 가르치고 훈련의 끝을 제어 한 다음 결과를 분석하고 결과를 기반으로 다른 작업을 실행하는 것이 필요하다고 생각합니다.
이것이 바로 5000개 이상의 기능보다 2 배 더 낫다는 점입니다.
다른 모든 5000 개 이상의 칩은 결과를 악화시킬뿐입니다.
이 두 가지 모델에서 표시되는 것을 비교하는 것은 흥미 롭습니다.
나는 매트가 있습니다. 기대치는 하나 이상, 이익은 5 천 이내, 정확도는 51 %를 기록합니다. 즉, 결과는 분명히 더 나쁩니다.
예, 테스트 샘플에서 100 개 모델 모두에서 손실이 발생했습니다.나는 매트가 있습니다. 기대치가 조금 더 많고 5 천 이내의 이익, 정확도는 51 %-즉, 결과가 분명히 더 나쁩니다.
예, 테스트 샘플에서 100 개 모델 모두에서 손실이 발생했습니다.하지만 첫 번째 샘플에서도 손실이 발생했습니다.
두 번째 상반기 샘플은요? 점점 나아지고 있습니다.
그리고 첫 번째 샘플에서도 지고 있습니다.
네, H1 샘플에 대해 이야기하고 있습니다. 처음에는 train.csv에서 훈련하고, test.csv에서 중지하고, exam.csv에서 독립적으로 확인하므로 열이 두 개인 변형은 test.csv에서 실패합니다. 어제의 변형도 손실이 있었지만 약간의 수익을 낸 변형도 있었습니다.
그렇다면 여러분은 어떤 기적의 차트를 가지고 계신가요?그리고 이것이 10000 라인에서 20000 라인에 대한 교육을 통해 앞으로 나아가는 방법입니다. 즉, 차트는 2 년이 아니라 5 년을 보여줍니다. 그 중 2 년은 드로 다운에 앉아 있어야하고, 그 후 1 년은 이익없이 평균 상금이 다시 거래 당 0.00002로 떨어졌습니다.
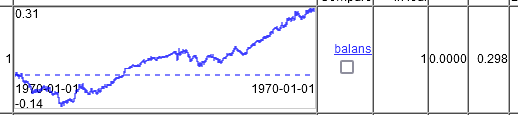
2 회 열에서만.
5000 개 이상의 모든 열에서 동일한 설정. 약간 나아졌습니다. 거래 당 0.00003.
수익 0.20600, 거래당 평균 0.00004. 스프레드에 비례
예, 수치는 이미 인상적입니다. 그러나 목표는 판매로 표시되어 있고 대규모 TF의 전체 기간이 판매되고 있으며 인위적으로 결과를 향상 시킨다고 생각합니다.
모든 열에서 0.00002 이상이지만 앞서 말했듯이 " 스프레드, 슬리피지 등이 모든 이익을 먹어 치울 것입니다". Teriminal은 바당 최소 스프레드를 표시하지만 (즉, 전체 시간 동안) 거래 순간에는 5 ~ 10 포인트가 될 수 있으며 뉴스에서는 20 이상이 될 수 있습니다.
그래서 내가 가진 마크 업은 분 막대에서 취해지며 스프레드는 일반적으로 일정 기간에 걸쳐 넓어집니다. 즉, 1 분 이내에 항상 큰 스프레드가있을 수 있습니까, 아니면 지금은 그렇지 않습니까? 5에서 스프레드가 어떻게 작동하는지조차 파악하지 못했습니다. 4에서 테스트하는 것이 더 편리하다는 것을 알았습니다.
거래 당 평균 상금이 최소 0.00020 인 모델을 찾아야합니다. 그러면 실제 거래에서 0.00010을 얻을 수 있습니다. 이것은 EURUSD의 경우이며 AUD NZD와 같은 다른 쌍에서는 50 포인트도 충분하지 않으며 스프레드는 20-30 포인트입니다.
동의합니다. 이 스레드의 첫 번째 샘플은 30 핍의 매트 기대치를 제공합니다. 그래서 저는 여전히 마크 업이 똑똑해야한다는 의견을 고수합니다.
다시 한 번 이것은 시험 샘플에서 가장 좋은 차트입니다. 트레이인이 시험에서 최상의 균형을 제공하는 설정을 선택하는 방법은 해결책이없는 질문입니다. 시험별로 선택합니다. 저는 트레이닝+테스트로 훈련했습니다. 기본적으로 여러분이 시험이 있으면 저도 시험이 있습니다.
샘플의 과반수가 선발 기준을 통과하는 것부터 시작해야 한다고 생각합니다. 또한, 가장 훈련이 덜 된 모델을 선택하는 것이 적합도가 낮을 수 있습니다.
다음은 10000개의 행에서 20000개의 행을 훈련하는 롤포워드 방식입니다. 즉, 그래프에서 2 년이 아니라 5 년이 아닙니다. 2 년은 드로 다운에 앉아 있어야하고, 이로 인해 평균 상금이 다시 거래 당 0.00002로 떨어졌기 때문에 이익없이 또 다른 1 년을 보내야합니다.
2 회 열에만 해당됩니다.
5000 개 이상의 모든 열에서 동일한 설정. 약간 나아졌습니다. 거래 당 0.00003.
그래도 다른 예측 변수도 유용할 수 있습니다. 그룹으로 추가하려고 시도 할 수 있으며 먼저 상관 관계를 선별하고 약간 줄일 수 있습니다.
기대 행렬과 관련하여이 전략에서는 캔들 개시가 아니라 시초가에서 동일한 30 핍으로 입력하는 것이 더 유리할 수 있습니다. 꼬리가없는 캔들은 드뭅니다.
그래서 내가 가진 마크 업은 분 막대에서 가져오고 스프레드는 일반적으로 일정 시간에 걸쳐 넓어집니다. 즉, 1 분 이내에 항상 큰 스프레드가있을 수 있습니까? 5에서 스프레드가 어떻게 작동하는지조차 파악하지 못했습니다. 저에게는 4에서 테스트하는 것이 더 편리합니다.
그리고 M1에서도 바 시간에 대한 최소 스프레드가 유지됩니다. ECH 계정에서 거의 모든 M1 바는 0.00001...0.00002이며 그 이상은 거의 없습니다. 모든 시니어 바는 M1로 만들어지며, 즉 최소 스프레드가 동일합니다. 라운드당 4포인트의 수수료를 추가해야 합니다(다른 중개 센터는 다른 수수료가 있을 수 있습니다).
그러나 다른 예측 인자들도 유용 할 수 있습니다. 그룹으로 추가하려고 시도 할 수 있으며 먼저 상관 관계를 찾아서 약간 줄일 수 있습니다.
아마도 우리는 그것들을 선택해야 할 것입니다. 하지만 5000개 이상을 2개로 추가해도 약간의 개선이 있다면 모델 학습을 통해 전체 무차별 대입으로 10개씩 선택하는 것이 더 빠를 수 있습니다. 24시간 동안 상관관계를 기다리는 것보다 더 빠를 것 같습니다. 터미널에서 직접 루프에서 재학습을 자동화하는 것만 필요합니다.
캣버스타에는 DLL 버전이 없나요? DLL은 터미널에서 직접 호출할 수 있습니다. 여기에 예제가 있는 문서가 있습니다. https://www. mql5.com/ru/articles/18 및 https://www.mql5.com/ru/articles/5798.
선택해야 할 수도 있습니다. 하지만 2초에 5000개 이상을 추가해도 약간의 개선이 있다면 모델 훈련을 통해 완전 무차별 대입으로 10개를 선택하는 것이 더 빠를 수 있습니다. 24시간 동안 상관관계를 기다리는 것보다 더 빠를 것 같습니다.
예, 처음에는 그룹으로 수행하는 것이 좋습니다. 예를 들어 10 개의 그룹을 만들고 그 조합으로 훈련하고 모델을 평가하고 가장 실패한 그룹을 제거하고 나머지 그룹을 다시 그룹화하는 것, 즉 그룹의 예측자 수를 줄이고 다시 훈련 할 수 있습니다. 이전에 이 방법을 사용한 적이 있는데 효과는 있지만 빠르지는 않습니다.
터미널에서 직접 루프에서 재교육을 자동화하면됩니다.
catbust에는 DLL 버전이 없나요? DLL은 터미널에서 직접 호출할 수 있습니다. 여기에 예제가 포함된 문서가 있습니다. https://www. mql5.com/ru/articles/18 및 https://www.mql5.com/ru/articles/5798.
터미널을 통해 완전한 학습 제어를 할 수 있으면 좋겠지만 제가 알기로는 준비된 솔루션이 없습니다. 모델만 적용하는 catboostmodel.dll 라이브러리가 있지만 MQL5에서 구현하는 방법을 모르겠습니다. 물론 이론적으로는 교육용 라이브러리 형태의 인터페이스를 만들 수 있습니다. 코드는 공개되어 있지만 감당할 수 없습니다.
예를 들어 10 개의 그룹을 만들고 조합하여 훈련하고 모델을 평가하고 가장 실패한 그룹을 제거하고 나머지 그룹을 다시 그룹화하여 그룹의 예측 변수 수를 줄이고 다시 훈련 할 수 있습니다. 이전에 이 방법을 사용한 적이 있는데 효과는 있지만 빠르지는 않습니다.
저는 다른 방법을 제안합니다. 모델에 기능을 하나씩 추가합니다. 그리고 가장 좋은 것을 선택합니다.
1) 하나의 기능에 대해 5000 개 이상의 모델을 훈련합니다.
2) 2개의 특징에 대해 (5000+-1) 모델을 훈련합니다: 첫 번째 가장 좋은 특징과 (5000+-1) 나머지 특징. 두 번째로 좋은 것을 찾습니다.
3) 3개의 특징에 대해 (5000+-2) 모델을 훈련합니다: 첫 번째, 두 번째 가장 좋은 특징과 (5000+-2) 나머지 특징에 대해. 세 번째로 좋은 것을 찾습니다.
모델이 개선될 때까지 반복합니다.
저는 보통 6~10개의 기능을 추가한 후 모델 개선을 중단합니다. 10~20개까지 또는 추가하고 싶은 만큼의 기능을 추가할 수도 있습니다.
하지만 테스트별로 기능을 선택하는 것이 데이터의 테스트 섹션에 모델을 맞추는 것이라고 생각합니다. 가중치가 0.3인 트레이닝과 가중치가 0.7인 테스트별로 선택하는 변형이 있습니다. 하지만 그것도 적합하다고 생각합니다.
나는 롤 포워드를하고 싶었고, 피팅은 많은 테스트 섹션에 대한 피팅이 될 것이고, 계산하는 데 더 오래 걸리지 만 이것이 최선의 선택 인 것 같습니다.
캣버스터를 실행하기위한 자동화가 없지만.... 5만 번 이상 수동으로 모델을 재훈련하여 10개의 기능을 얻기는 어려울 것입니다.이것이 제가 캣버스터보다 제 기술을 선호하는 이유입니다. 비록 캣버스트보다 5~10배 느리게 작동하지만요. 당신은 3분 동안 모델 하나를 만들었지만 저는 22개를 만들었죠.
제가 제안하는 것은 그런 것이 아닙니다. 모델에 기능을 하나씩 추가합니다. 그리고 가장 좋은 것을 선택합니다.
1) 하나의 기능에 대해 5000개 이상의 모델 훈련: 5000개 이상의 기능 각각.
2) 2개의 기능에 대해 (5000+-1) 모델을 훈련시킵니다: 첫 번째 가장 좋은 기능과 (5000+-1) 나머지 기능. 두 번째로 좋은 것을 찾습니다.
3) 3개의 특징에 대해 (5000+-2) 모델을 훈련합니다: 첫 번째, 두 번째 가장 좋은 특징과 (5000+-2) 나머지 특징에 대해. 세 번째로 좋은 것을 찾습니다.
모델이 개선될 때까지 반복합니다.
저는 보통 6~10개의 기능을 추가한 후 모델 개선을 중단합니다. 10~20개까지 또는 추가하고 싶은 만큼의 기능을 추가할 수도 있습니다.
접근 방식은 다를 수 있습니다. 본질은 일반적으로 동일하지만 단점은 물론 계산 비용이 너무 높다는 것입니다.
그러나 테스트에 의한 기능 선택은 데이터의 테스트 섹션에 모델을 맞추는 것이라고 생각합니다. 가중치 0.3의 트레이닝에 의한 선택과 가중치 0.7의 테스트에 의한 선택의 변형이 있습니다. 하지만 그것도 적합하다고 생각합니다.
나는 밸브를 앞으로 만들고 싶고, 피팅은 많은 테스트 섹션에 대한 피팅이 될 것이며 계산하는 데 더 오래 걸리지 만 이것이 최선의 선택 인 것 같습니다.
그렇기 때문에 기능 선택을 정당화하기 위해 기능 내부에서 합리적인 곡물을 찾고 있습니다. 지금까지는 이벤트의 반복 빈도와 클래스 확률을 변경하기로 결정했습니다. 평균적으로 그 효과는 양수이지만 이 방법은 상관관계가 있는 예측 변수를 고려하지 않고 실제로 첫 번째 분할로 평가합니다. 그러나 두 번째 분할에 대해서도 동일한 방법을 시도하여 샘플에서 강한 부정적 성향이 있는 예측자 점수의 행을 제거해야 한다고 생각합니다.
catbusters를 실행하는 자동화가 없지만.... 5만 번 이상 수동으로 모델을 재학습하여 10개의 특성을 얻는 것은 어려울 것입니다.
이것이 제가 캣버스터보다 제 크래프트를 선호하는 대략적인 이유입니다. 비록 컷버스트보다 5~10배 느리게 작동하지만요. 당신은 모델 하나를 세는 데 3분이 걸렸지만 저는 22개를 세웠어요.
그래도 제 기사를 읽어보세요.... 이제 모든 것이 반자동 형태로 작동합니다. 작업이 생성되고 부트 닉이 시작됩니다 (교육에 사용할 기능 수에 대한 작업 포함, 즉 모든 변형을 한 번에 생성하고 실행할 수 있음). 본질적으로 터미널에 박쥐 파일을 실행하도록 가르치고 훈련의 끝을 제어 한 다음 결과를 분석하고 결과를 기반으로 다른 작업을 실행하는 것이 필요하다고 생각합니다.
학습 속도를 변경해야만 100개 중 두 개의 모델이 기준 설정에 부합하는 결과를 얻을 수 있었습니다.
첫 번째 모델입니다.
두 번째.
예, CatBoost는 많은 일을 할 수 있지만 설정을 더 적극적으로 조정할 필요가있는 것으로 보입니다.
테스트에서 최고를 기준으로 이러한 모델을 선택합니까?
아니면 테스트에서 최고인 세트 중에서 최고를 선택하시나요?