MTS에서 인공 지능 사용
- Using artificial intelligence at MTS
- 가격이 결정된다고 생각하는 4가지 요소를 말하십시오.
- MQL4 및 MQL5에 대한 초보자 질문, 알고리즘 및 코드에 대한 도움말 및 토론
일부 특성이 있는 디지털 필터를 사용하는 AC 평활화와 동일합니다. 평활 계수는 균형이 맞지 않아 구매 버튼의 벽돌과 같습니다. 브릭(+ 예를 들어 스토캐스틱)은 그 자체로 매우 잘 작동하여 언제 구매하고 언제 판매할지 알 수 있습니다. 또한 21bar에 대한 AC가 2번 위아래로 갈 수 있다는 점과 4개의 최적화된 매개변수가 있다는 점을 고려하면 ......)))))
그러나 저에게는 신경망 이 작동하는 방식과 왜 내가 원하는 만큼 효율적이지 않은지에 대해 설명합니다.
한때 취미가 있었습니다. 창작 기간이 시작될 때 - 지난 주의 결과를 기반으로 m1에서 작업하기 위해 Expert Advisors를 작성하는 것(66000개와 대조적으로 7200개 막대) - 주당 최대 300%가 표시되었습니다. 시험 장치.....
최적화 후 성배를 얻으려면 가격을 푸리에 시리즈로 분해해야 하는 고조파의 수는 얼마나 되는지 궁금합니다.
일부 특성이 있는 디지털 필터를 사용하는 AC 평활화와 동일합니다. 평활 계수는 균형이 맞지 않아 구매 버튼의 벽돌과 같습니다. 브릭(+ 예를 들어 스토캐스틱)은 그 자체로 매우 잘 작동합니다. 언제 사야 할지, 언제 팔아야 할지 알 수 있을 뿐입니다. 또한 21bar용 AC가 2번 오르락 내리락 할 수 있다는 점과 4개의 최적화된 매개변수가 있다는 점을 고려하면 ......)))))
그러나 나에게는 신경망이 어떻게 작동하는지, 왜 내가 원하는 만큼 효율적이지 않은지에 대해 설명합니다.
한때 취미가 있었습니다. 창작 기간이 시작될 때 - 지난 주의 결과를 기반으로 m1에서 작업하기 위해 Expert Advisors를 작성하는 것(66000개와 대조적으로 7200개 막대) - 주당 최대 300%가 표시되었습니다. 시험 장치.....
최적화 후 성배를 얻기 위해 가격을 푸리에 시리즈로 분해하는 데 필요한 고조파의 수는 얼마입니까?
AC 오실레이터의 경우 EA는 마지막 값(마지막 값을 기반으로 한 결정은 기술 분석에서 가장 자주 사용됨)뿐만 아니라 이력도 검사합니다. 과거에 지표의 3가지 값이 더 있었습니까? 그는 결정을 내리기 위해 오실레이터의 동작에 관심이 있습니다. 바로 이 동작이 신경망의 입력에도 도달합니다. 그리고 출력에서 우리는 매수 또는 매도를 얻습니다.
또 다른 혁신은 뉴런의 표준 훈련이 아니라 유전 알고리즘을 사용하여 과거 데이터에서 가중치를 선택하는 것입니다. 나는 두 가지 옵션을 모두 시도했지만 유전학은 결과를 조금 더 나쁘고 시간이 느립니다. 그러나 MT4에는 내장된 뉴런 알고리즘과 훈련이 없습니다. 그리고 유전자 최적화가 있습니다. 네, 그리고 이 분야의 많은 연구자들은 상황이 급격하게 변할 경우 동적 학습이 적절하지 않다는 사실에 직면했습니다. 예를 들어 시장이 강세장에 의해 지배된다면 시스템은 강세장 추세를 위해 재훈련하고 약세장을 잊어버릴 것입니다. 그 반대. 사무엘 AL 1959 "검사기 게임을 사용한 기계 학습에 대한 일부 연구" IBM J. Research 및 Devepopmend 3: 210 - 229는 이 수치를 처음 만나 설명하고 설명했습니다. 그는 자신의 프로그램에 프로 상대가 있으면 점차 프로 수준의 게임으로 옮겨가는 것을 알아차렸습니다. 그리고 상대방이 초보자라면 프로그램은 이전 레벨을 "잊고" 원시 게임으로 전환하기 시작했습니다. 따라서 뉴런 자체의 실수와 손실에 대해 동적으로 훈련하는 것은 이치에 맞지 않을 수 있습니다. 시장에 적합한 거래 전략을 개발하기 위해 역사를 통해 실행하는 것이 더 쉽습니다.
그리고 성배 에 관해서는 큰 마음이 필요하지 않습니다. 다음과 같은 여러 조건만 충족하면 됩니다.
1. 시스템은 정지 손실이 전혀 없거나 매우 먼 거리에서 정지 손실이 있는 포지션을 열어야 하므로 작동 확률이 0에 가까울 것입니다.
2. 논리적 AND(&&)로 구분된 트리거 조건이 있는 여러 표시기를 기반으로 하는 강력한 필터를 연결합니다. 그리고 이러한 동일한 표시기의 많은 입력 매개변수를 MTS의 외부 설정으로 가져와 몇 년 동안의 과거 데이터 동안 테스트에서 몇 개의 위치만 열 수 있도록 합니다.
3. 이 모든 자금 관리에 불리한 부분으로 위험을 추가하십시오.
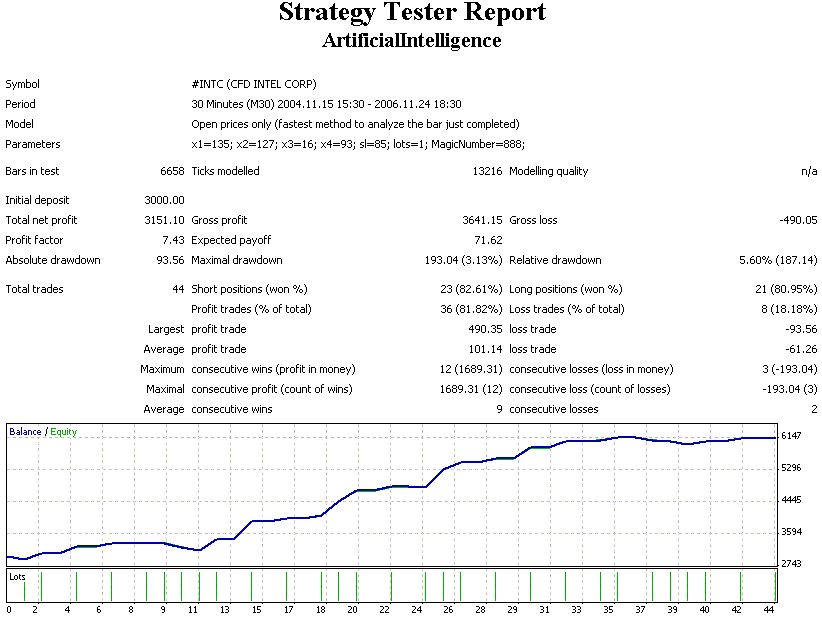
2년 동안 44번의 거래를 제공하는 전략을 어떻게 진지하게 논의할 수 있는지 이해가 되지 않습니다... 통계가 너무 적습니다!
4점에서 값을 취하고 각 값에 계수를 곱하고 합산합니다. 필터로 평활화하지 않는 이유는 무엇입니까?
4점에서 값을 취하고 각 값에 계수를 곱하고 합산합니다. 필터로 평활화하지 않는 이유는 무엇입니까?
선형 가중 이동 평균 에 대해 들어보셨습니까?
그것이 무엇이든 그것은 생명에 대한 권리가 있습니다. 아이디어가 새로운 것은 아니지만 매우 흥미롭고 현명하게 구현되며 ... 이익을 가져올 수 있습니다. "훈련" 후 몇 가지 전방 테스트를 수행한 결과는 고무적입니다. 저자에게 깊은 감사를 드립니다.
그것이 무엇이든 그것은 생명에 대한 권리가 있습니다. 아이디어가 새로운 것은 아니지만 매우 흥미롭고 현명하게 구현되며 ... 이익을 가져올 수 있습니다. "훈련" 후 몇 가지 전방 테스트를 수행한 결과는 고무적입니다. 저자에게 깊은 감사를 드립니다.
그리고 뉴런이 효과적인지 아닌지에 대해 군도와 논쟁하는 것은 시간 낭비일 뿐입니다. 결국, 나는 원칙에 그것을 퍼뜨립니다. 당신이 그것을 가지고 싶지만, 당신이 그것을 원하지 않으면보십시오. 그러나 이 문제에 대해 많이 알고 코드를 개선하거나 문제 해결을 위한 더 흥미로운 아이디어를 제안할 수 있는 사람이 있기를 바랍니다.
4점에서 값을 취하고 각 값에 계수를 곱하고 합산합니다. 필터로 평활화하지 않는 이유는 무엇입니까?
선형 가중 이동 평균 에 대해 들어보셨습니까?