
MQL5 Cookbook: 빠른 데이터 액세스를 위한 연관 배열 또는 사전 구현

목차
소개
이 글에서는 정보의 편리한 저장을 위한 클래스, 즉 연관 배열 또는 사전에 대해 설명합니다. 이 클래스를 사용하면 키를 통해 정보에 액세스할 수 있습니다.
연관 배열은 일반 배열과 유사합니다. 그러나 인덱스 대신 ENUM_TIMEFRAMES 열거 또는 일부 텍스트와 같은 고유 키를 사용합니다. 키를 나타내는 것은 중요하지 않습니다. 중요한 것은 키의 고유성입니다. 이 데이터 저장 알고리즘은 많은 프로그래밍 측면을 크게 단순화합니다.
예를 들어, 오류 코드를 받아 오류에 해당하는 텍스트를 인쇄하는 함수는 다음과 같을 수 있습니다.
//+------------------------------------------------------------------+ //| Displays the error description in the terminal. | //| Displays "Unknown error" if error id is unknown | //+------------------------------------------------------------------+ void PrintError(int error) { Dictionary dict; CStringNode* node = dict.GetObjectByKey(error); if(node != NULL) printf(node.Value()); else printf("Unknown error"); }-->
이 코드의 특정 기능은 나중에 살펴보겠습니다.
연관 배열 내부 논리에 대한 직접적인 설명을 다루기 전에 데이터 저장의 두 가지 주요 방법인 배열과 목록에 대한 세부 사항을 고려할 것입니다. 사전은 이 두 가지 데이터 유형을 기반으로 하므로 특정 기능을 잘 이해해야 합니다. 1장은 데이터 유형에 대한 설명입니다. 두 번째 장은 연관 배열과 그것으로 작업하는 방법에 대한 설명에 전념합니다.
1장. 데이터 조직 이론
1.1. 데이터 구성 알고리즘. 최고의 데이터 저장 컨테이너 검색
정보의 검색, 저장 및 표현은 현대 컴퓨터에 부과된 주요 기능입니다. 인간-컴퓨터 상호 작용에는 일반적으로 일부 정보 검색 또는 추가 사용을 위한 정보 생성 및 저장이 포함됩니다. 정보는 추상적인 개념이 아니다. 실제 의미에서 이 단어 아래에는 특정 개념이 있습니다. 예를 들어, 기호 시세 기록은 이 기호에 대해 거래를 하거나 거래할 거래자에게 정보의 원천입니다. 프로그래밍 언어 문서 또는 일부 프로그램의 소스 코드는 프로그래머를 위한 정보 소스 역할을 할 수 있습니다.
일부 그래픽 파일(예: 디지털 카메라로 만든 사진)은 프로그래밍이나 거래와 관련이 없는 사람들에게 정보 소스가 될 수 있습니다. 이러한 유형의 정보는 구조와 특성이 다릅니다. 결과적으로 이 정보의 저장, 표현 및 처리 알고리즘이 다릅니다.
예를 들어, 그래픽 파일을 2차원 매트릭스(2차원 배열)로 표현하는 것이 더 쉽습니다. 각 요소 또는 셀은 작은 이미지 영역(픽셀)의 색상에 대한 정보를 저장할 것입니다. 인용 데이터에는 또 다른 특성이 있습니다. 기본적으로 OH LCV 형식의 동종 데이터입니다. 이 스트림을 여러 데이터 유형을 결합하는 프로그래밍 언어의 특정 유형 데이터인 구조의 정렬된 시퀀스 또는 배열로 표시하는 것이 좋습니다. 문서 또는 소스 코드는 일반적으로 일반 텍스트로 표시됩니다. 이 데이터 유형은 문자열의 순서가 지정된 시퀀스로 정의 및 저장할 수 있습니다. 여기서 각 문자열은 임의의 기호 시퀀스입니다.
데이터를 저장할 컨테이너 유형은 데이터 유형에 따라 다릅니다. 객체 지향 프로그래밍의 용어를 사용하면 컨테이너를 이러한 데이터를 저장하고 이를 조작하는 특수 알고리즘(메소드)을 갖는 특정 클래스로 정의하는 것이 더 쉽습니다. 이러한 데이터 저장 컨테이너(클래스)에는 여러 유형이 있습니다. 그들은 서로 다른 데이터 구성을 기반으로 합니다. 그러나 일부 데이터 구성 알고리즘을 사용하면 서로 다른 데이터 저장 패러다임을 결합할 수 있습니다. 따라서 모든 스토리지 유형의 이점을 결합할 수 있습니다.
예상되는 조작 방법과 특성에 따라 데이터를 저장, 처리 및 수신할 하나 이상의 컨테이너를 선택합니다. 동등하게 효율적인 데이터 컨테이너는 없다는 것을 인식하는 것이 중요합니다. 하나의 데이터 컨테이너의 약점은 장점의 이면입니다.
예를 들어, 모든 배열 요소에 빠르게 액세스할 수 있습니다. 그러나 임의의 배열 지점에 요소를 삽입하려면 전체 배열 크기 조정이 필요하므로 시간이 많이 걸리는 작업이 필요합니다. 그리고 반대로, 단일 연결 목록에 요소를 삽입하는 것은 효과적이고 빠른 작업이지만 임의의 요소에 액세스하는 데 많은 시간이 걸릴 수 있습니다. 새 요소를 자주 삽입해야 하지만 이러한 요소에 자주 액세스할 필요가 없다면 단일 연결 목록이 올바른 컨테이너가 될 것입니다. 무작위 요소에 자주 액세스해야 하는 경우 데이터 클래스로 배열을 선택합니다.
어떤 데이터 저장 유형이 선호되는지 이해하려면 주어진 컨테이너의 배열에 익숙해야 합니다. 이 글은 연관 배열 또는 사전(배열과 목록의 조합을 기반으로 하는 특정 데이터 저장 컨테이너)에 대해 설명합니다. 그러나 사전은 특정 프로그래밍 언어, 그 수단, 기능 및 허용되는 프로그래밍 규칙에 따라 다른 방식으로 구현될 수 있음을 언급하고 싶습니다.
예를 들어, C# 사전 구현은 C++와 다릅니다. 이 문서에서는 С++용 사전의 적응된 구현에 대해 설명하지 않습니다. 설명된 버전의 연관 배열은 MQL5 프로그래밍 언어용으로 처음부터 생성되었으며 특수 기능과 일반적인 프로그래밍 방식을 고려합니다. 구현 방식은 다르지만 사전의 일반적인 특성과 작동 방식은 비슷해야 합니다. 이러한 맥락에서 설명된 버전은 이러한 모든 특성과 방법을 완전히 보여줍니다.
그 사이에 사전 알고리즘을 점진적으로 만들고 데이터 저장 알고리즘의 특성에 대해 논의할 것입니다. 그리고 글의 끝에서 우리는 알고리즘의 완전한 버전을 갖게 될 것이고 그 작동 원리를 완전히 알게 될 것입니다.
서로 다른 데이터 유형에 대해 동등하게 효율적인 컨테이너는 없습니다. 간단한 예를 생각해 보겠습니다. 가령 종이 공책을 말이죠. 우리의 일상 생활에서 사용되는 컨테이너/클래스로 간주될 수도 있습니다. 모든 메모는 미리 만들어진 목록(이 경우 알파벳)에 따라 입력됩니다. 가입자 이름을 알면 노트북을 열기만 하면 되므로 가입자의 전화번호를 쉽게 찾을 수 있습니다.
1.2. 배열 및 데이터 직접 주소 지정
배열은 정보를 저장하는 가장 단순하면서도 동시에 가장 효과적인 방법입니다. 프로그래밍에서 배열은 동일한 유형 요소의 모음으로, 메모리에서 즉시 차례로 위치합니다. 이러한 속성으로 인해 배열의 각 요소 주소를 계산할 수 있습니다.
실제로 모든 요소의 유형이 동일하면 모두 동일한 크기를 갖습니다. 배열 데이터는 지속적으로 위치하므로 임의의 요소의 주소를 계산하고 기본 요소의 크기를 알면 이 요소를 직접 참조할 수 있습니다. 주소를 계산하는 일반적인 공식은 데이터 유형과 색인에 따라 다릅니다.
예를 들어, 배열 데이터 구성의 속성에서 나오는 다음 일반 공식을 사용하여 uchar 유형 요소의 배열에서 다섯 번째 요소의 주소를 계산할 수 있습니다.
임의 요소 주소 = 첫 번째 요소 주소 + (배열의 임의 요소 인덱스 * 배열 유형 크기)
배열 주소 지정은 0부터 시작하므로 첫 번째 요소의 주소가 인덱스 0을 갖는 배열 요소의 주소에 해당합니다. 결과적으로 다섯 번째 요소는 색인 4를 갖습니다. 배열이 uchar 유형 요소를 저장한다고 가정해 보겠습니다. 이것은 많은 프로그래밍 언어의 기본 데이터 유형입니다. 예를 들어, 모든 C 유형 언어에 있습니다. MQL5도 예외는 아닙니다. uchar 유형 배열의 각 요소는 1바이트 또는 8비트의 메모리를 차지합니다.
예를 들어, 앞서 언급한 공식에 따르면 uchar 배열의 다섯 번째 요소 주소는 다음과 같습니다.
다섯 번째 요소 주소 = 첫 번째 요소 주소 + (4 * 1 바이트);
즉, uchar 배열의 첫 번째 요소는 첫 번째 요소보다 4바이트 높습니다. 프로그램 실행 중에 해당 주소로 각 배열 요소를 직접 참조할 수 있습니다. 이러한 주소 산술을 통해 각 배열 요소에 매우 빠르게 액세스할 수 있습니다. 그러나 이러한 데이터 구성에는 단점이 있습니다.
그 중 하나는 배열에 다른 유형의 요소를 저장할 수 없다는 것입니다. 이러한 제한은 직접 주소 지정의 결과입니다. 확실히 데이터 유형에 따라 크기가 다르므로 위에서 언급한 공식을 사용하여 특정 요소의 주소를 계산하는 것은 불가능합니다. 그러나 배열이 요소가 아닌 포인터를 저장한다면 이 제한을 현명하게 극복할 수 있습니다.
포인터를 링크(Windows의 바로 가기)로 나타내면 가장 쉬운 방법입니다. 포인터는 메모리의 특정 개체를 참조하지만 포인터 자체는 개체가 아닙니다. MQL5에서 포인터는 클래스만 참조할 수 있습니다. 객체 지향 프로그래밍에서 클래스는 임의의 데이터 및 메소드 집합을 포함할 수 있고 효과적인 프로그램 구조화를 위해 사용자가 생성할 수 있는 특정 데이터 유형입니다.
모든 클래스는 고유한 사용자 정의 데이터 유형입니다. 다른 클래스를 참조하는 포인터는 하나의 배열에 있을 수 없습니다. 그러나 참조된 클래스에 관계없이 포인터는 할당된 모든 개체에 공통적인 운영 체제 주소 공간의 개체 주소만 포함하므로 항상 동일한 크기를 갖습니다.
1.3. CObjectCustom 단순 클래스의 예에 의한 노드 개념
이제 우리는 첫 번째 범용 포인터를 디자인할 만큼 충분히 알고 있습니다. 아이디어는 각 포인터가 특정 유형을 참조하는 범용 포인터 배열을 만드는 것입니다. 실제 유형은 다르지만 동일한 포인터에 의해 참조되기 때문에 이러한 유형을 하나의 컨테이너/배열에 저장할 수 있습니다. 포인터의 첫 번째 버전을 만들어 보겠습니다.
이 포인터는 CObjectCustom이라는 가장 단순한 유형으로 표시됩니다.
class CObjectCustom
{
};--> 데이터나 메소드가 포함되어 있지 않기 때문에 CObjectCustom보다 간단한 클래스를 만드는 것은 정말 어렵습니다. 그러나 그러한 구현은 당분간 충분합니다.
이제 우리는 객체 지향 프로그래밍의 주요 개념 중 하나인 상속을 사용할 것입니다. 상속은 개체 간의 ID를 설정하는 특별한 방법을 제공합니다. 예를 들어 컴파일러에게 모든 클래스가 CObjectCustom의 파생물이라고 말할 수 있습니다.
예를 들어, 인간 클래스(СHuman), Expert Advisors 클래스(CExpert) 및 날씨 클래스(CWeather)는 CObjectCustom 클래스의 보다 일반적인 개념을 나타냅니다. 아마도 이러한 개념은 실생활에서 실제로 연결되어 있지 않을 수 있습니다. 날씨는 사람들과 공통점이 없고 Expert Advisors는 날씨와 관련이 없습니다. 그러나 이것은 프로그래밍 세계에서 링크를 설정하는 사람이며 이러한 링크가 알고리즘에 적합하다면 만들지 못할 이유가 없습니다.
자동차 클래스(CCar), 숫자 클래스(CNumber), 가격 표시줄 클래스(CBar), 견적 클래스(CQuotes), MetaQuotes 회사 클래스(CMetaQuotes), 클래스 등 같은 방식으로 클래스를 더 만들어 보겠습니다. 선박(CShip)을 설명합니다. 이전 클래스와 마찬가지로 이러한 클래스는 실제로 연결되어 있지 않지만 모두 CObjectCustom 클래스의 자손입니다.
이러한 모든 클래스를 하나의 파일로 결합하여 이러한 객체에 대한 클래스 라이브러리를 생성해 보겠습니다. ObjectsCustom.mqh:
//+------------------------------------------------------------------+ //| ObjectsCustom.mqh | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" //+------------------------------------------------------------------+ //| Base Class CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing human beings. | //+------------------------------------------------------------------+ class CHuman : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing weather. | //+------------------------------------------------------------------+ class CWeather : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing Expert Advisors. | //+------------------------------------------------------------------+ class CExpert : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing cars. | //+------------------------------------------------------------------+ class CCar : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing numbers. | //+------------------------------------------------------------------+ class CNumber : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing price bars. | //+------------------------------------------------------------------+ class CBar : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing quotations. | //+------------------------------------------------------------------+ class CQuotes : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing the MetaQuotes company. | //+------------------------------------------------------------------+ class CMetaQuotes : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing ships. | //+------------------------------------------------------------------+ class CShip : public CObjectCustom { };-->
이제 이러한 클래스를 하나의 배열로 결합할 때입니다.
1.4. CArrayCustom 클래스의 예에 따른 노드 포인터 배열
클래스를 결합하려면 특별한 배열이 필요합니다.
가장 간단한 경우에는 다음과 같이 작성하는 것으로 충분합니다.
CObjectCustom array[];-->
이 문자열은 CObjectCustom 유형 요소를 저장하는 동적 배열을 만듭니다. 이전 섹션에서 정의한 모든 클래스가 CObjectCustom에서 파생되었기 때문에 이러한 클래스를 이 배열에 저장할 수 있습니다. 예를 들어 사람, 자동차 및 배를 찾을 수 있습니다. 그러나 CObjectCustom 배열의 선언은 이 목적에 충분하지 않습니다.
문제는 일반적인 방법으로 배열을 선언하면 배열 초기화 시점에 모든 요소가 자동으로 채워진다는 것입니다. 따라서 배열을 선언한 후에는 모든 요소가 CObjectCustom 클래스에 의해 점유됩니다.
CObjectCustom을 약간 수정하면 이것을 확인할 수 있습니다.
//+------------------------------------------------------------------+ //| Base class CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { public: void CObjectCustom() { printf("Object #"+(string)(count++)+" - "+typename(this)); } private: static int count; }; static int CObjectCustom::count=0;-->
이 특성을 확인하기 위해 테스트 코드를 스크립트로 실행해 보겠습니다.
//+------------------------------------------------------------------+ //| Test.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2014, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom array[3]; }-->
OnStart() 함수에서 CObjectCustom의 세 가지 요소로 구성된 배열을 초기화했습니다.
컴파일러가 이 배열을 해당 개체로 채웠습니다. 터미널의 로그를 읽으면 확인할 수 있습니다.
2015.02.12 12:26:32.964 Test (USDCHF,H1) Object #2 - CObjectCustom
2015.02.12 12:26:32.964 Test (USDCHF,H1) Object #1 - CObjectCustom
2015.02.12 12:26:32.964 Test (USDCHF,H1) Object #0 - CObjectCustom
이는 배열이 컴파일러에 의해 채워지고 CWeather 또는 CExpert와 같은 다른 요소를 찾을 수 없음을 의미합니다.
이 코드는 컴파일되지 않습니다:
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom array[3]; CWeather weather; array[0] = weather; }-->
컴파일러는 다음과 같은 오류 메시지를 표시합니다.
'=' - structure have objects and cannot be copied Test.mq5 18 13-->
즉, 배열에 이미 개체가 있고 새 개체를 거기에 복사할 수 없습니다.
하지만 우리는 이 난국을 헤쳐나갈 수 있습니다! 위에서 언급했듯이 우리는 객체가 아니라 이러한 객체에 대한 포인터로 작업해야 합니다.
포인터와 함께 작동할 수 있는 방식으로 OnStart() 함수의 코드를 다시 작성합니다.
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* array[3]; CWeather* weather = new CWeather(); array[0] = weather; }-->
이제 코드가 컴파일되고 오류가 발생하지 않습니다. 무슨 일이 일어났나요? 먼저 CObjectCustom 배열 초기화를 CObjectCustom에 대한 포인터 배열 초기화로 대체했습니다.
이 경우 컴파일러는 배열을 초기화할 때 새 CObjectCustom 개체를 만들지 않고 비워 둡니다. 둘째, 이제 개체 자체 대신 CWeather 개체에 대한 포인터를 사용합니다. new 키워드를 사용하여 CWeather 개체를 만들고 포인터 'weather'에 할당한 다음 배열에 'weather' 포인터(객체 제외)를 넣었습니다.
이제 배열의 나머지 개체를 유사한 방식으로 배치해 보겠습니다.
이를 위해 다음 코드를 작성하십시오.
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[8]; arrayObj[0] = new CHuman(); arrayObj[1] = new CWeather(); arrayObj[2] = new CExpert(); arrayObj[3] = new CCar(); arrayObj[4] = new CNumber(); arrayObj[5] = new CBar(); arrayObj[6] = new CMetaQuotes(); arrayObj[7] = new CShip(); }-->
이 코드는 작동하지만 배열의 인덱스를 직접 조작하기 때문에 상당히 위험합니다.
arrayObj 배열의 크기나 잘못된 인덱스로 주소를 잘못 계산하면 프로그램이 심각한 오류로 끝날 것입니다. 그러나 이 코드는 데모 목적에 적합합니다.
이러한 요소를 스키마로 표시해 보겠습니다.
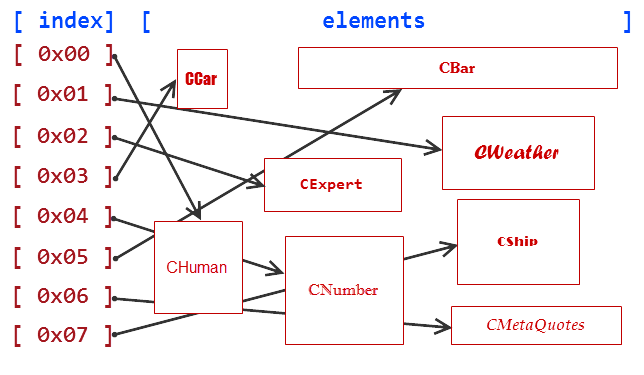
그림 1. 포인터 배열의 데이터 저장 방식
'new' 연산자에 의해 생성된 요소는 힙이라고 하는 랜덤 액세스 메모리의 특정 부분에 저장됩니다. 위의 체계에서 명확하게 볼 수 있듯이 이러한 요소는 순서가 지정되지 않습니다.
arrayObj 포인터 배열은 엄격한 인덱싱을 지원하므로 해당 인덱스를 사용하여 모든 요소에 빠르게 액세스할 수 있습니다. 그러나 포인터 배열은 그것이 가리키는 특정 객체를 알지 못하기 때문에 그러한 요소에 대한 액세스 권한을 얻는 것만으로는 충분하지 않습니다. CObjectCustom 포인터는 모두 CObjectCustom이므로 CWeather, CBar 또는 CMetaQuotes를 가리킬 수 있습니다. 따라서 요소 유형을 가져오려면 실제 유형에 대한 객체의 명시적 캐스트가 필요합니다.
예를 들어 다음과 같이 할 수 있습니다.
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[8]; arrayObj[0] = new CHuman(); CObjectCustom * obj = arrayObj[0]; CHuman* human = obj; }-->
이 코드에서 우리는 CHuman 객체를 생성하여 arrayObj 배열 as CObjectCustom에 배치했습니다. 그런 다음 CObjectCustom을 추출하여 실제로 동일한 CHuman으로 변환했습니다. 예제에서 변환은 유형을 기억했기 때문에 오류가 없었습니다. 실제 프로그래밍 상황에서 모든 개체의 유형을 추적하는 것은 매우 어렵습니다. 이러한 유형이 수백 가지가 될 수 있고 개체의 수가 백만 개가 넘을 수 있기 때문입니다.
그렇기 때문에 ObjectCustom 클래스에 실제 객체 유형의 수정자 (modifier)를 반환하는 추가 Type() 메소드를 제공해야 합니다. 수정자 (modifier)는 이름으로 유형을 참조할 수 있도록 하는 객체를 설명하는 특정 고유 번호입니다. 예를 들어 전처리기 지시문 #define을 사용하여 수정자 (modifier)를 정의할 수 있습니다. 수정자 (modifier)에 의해 지정된 객체 유형을 알고 있으면 항상 해당 유형을 실제 유형으로 안전하게 변환할 수 있습니다. 따라서 우리는 안전한 유형의 생성에 근접했습니다.
1.5. 종류의 확인 및 안전성
한 유형을 다른 유형으로 변환하기 시작하자마자 그러한 변환의 안전성이 프로그래밍의 초석이 됩니다. 우리는 우리 프로그램이 치명적인 오류로 끝나는 것을 원하지 않습니다. 그렇지 않습니까? 그러나 우리는 이미 우리 유형의 안전 기반이 될 특수 수정자 (modifier)를 알고 있습니다. 수정자 (modifier)를 알고 있으면 필수 유형으로 변환할 수 있습니다. 이를 위해 CObjectCustom 클래스를 몇 가지 추가 사항으로 보완해야 합니다.
우선, 이름으로 참조할 유형 식별자를 생성해 보겠습니다. 이를 위해 필요한 열거가 포함된 별도의 파일을 생성합니다.
//+------------------------------------------------------------------+ //| Types.mqh | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #define TYPE_OBJECT 0 // General type CObjectCustom #define TYPE_HUMAN 1 // Class CHuman #define TYPE_WEATHER 2 // Class CWeather #define TYPE_EXPERT 3 // Class CExpert #define TYPE_CAR 4 // Class CCar #define TYPE_NUMBER 5 // Class CNumber #define TYPE_BAR 6 // Class CBar #define TYPE_MQ 7 // Class CMetaQuotes #define TYPE_SHIP 8 // Class CShip-->
이제 개체 유형을 숫자로 저장하는 변수에 CObjectCustom을 추가하여 클래스 코드를 변경합니다. 아무도 변경할 수 없도록 비공개 섹션에 숨깁니다.
그 외에도 CObjectCustom에서 파생된 클래스에 사용할 수 있는 특수 생성자를 추가합니다. 이 생성자는 객체를 생성하는 동안 유형을 지정할 수 있도록 합니다.
공통 코드는 다음과 같습니다.
//+------------------------------------------------------------------+ //| Base Class CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { private: int m_type; protected: CObjectCustom(int type){m_type=type;} public: CObjectCustom(){m_type=TYPE_OBJECT;} int Type(){return m_type;} }; //+------------------------------------------------------------------+ //| Class describing human beings. | //+------------------------------------------------------------------+ class CHuman : public CObjectCustom { public: CHuman() : CObjectCustom(TYPE_HUMAN){;} void Run(void){printf("Human run...");} }; //+------------------------------------------------------------------+ //| Class describing weather. | //+------------------------------------------------------------------+ class CWeather : public CObjectCustom { public: CWeather() : CObjectCustom(TYPE_WEATHER){;} double Temp(void){return 32.0;} }; ...-->
보시다시피, CObjectCustom에서 파생된 모든 형식은 이제 생성하는 동안 생성자에서 고유한 형식을 설정합니다. 유형이 설정되면 유형이 저장되는 필드가 비공개이고 CObjectCustom에서만 사용할 수 있으므로 유형을 변경할 수 없습니다. 그러면 잘못된 유형 조작을 방지할 수 있습니다. 클래스가 보호된 생성자 CObjectCustom을 호출하지 않으면 해당 유형(TYPE_OBJECT)이 기본 유형이 됩니다.
따라서 arrayObj에서 유형을 추출하고 처리하는 방법을 배울 때입니다. 이를 위해 CHuman 및 CWeather 클래스에 해당하는 public Run() 및 Temp() 메소드를 제공합니다. arrayObj에서 클래스를 추출한 후 필요한 유형으로 변환하고 적절한 방식으로 작업을 시작합니다.
CObjectCustom 배열에 저장된 유형을 알 수 없는 경우 "알 수 없는 유형"이라는 메시지를 작성하여 무시합니다.
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[3]; arrayObj[0] = new CHuman(); arrayObj[1] = new CWeather(); arrayObj[2] = new CBar(); for(int i = 0; i < ArraySize(arrayObj); i++) { CObjectCustom* obj = arrayObj[i]; switch(obj.Type()) { case TYPE_HUMAN: { CHuman* human = obj; human.Run(); break; } case TYPE_WEATHER: { CWeather* weather = obj; printf(DoubleToString(weather.Temp(), 1)); break; } default: printf("unknown type."); } } }-->
이 코드는 다음 메시지를 표시합니다:
2015.02.13 15:11:24.703 Tets (USDCHF,H1) 알 수 없는 유형입니다.
2015.02.13 15:11:24.703 Test (USDCHF,H1) 32.0
2015.02.13 15:11:24.703 Test (USDCHF,H1) Human run...
그래서 우리는 찾던 결과를 얻었습니다. 이제 CObjectCustom 배열에 모든 유형의 개체를 저장하고 배열의 인덱스를 통해 이러한 개체에 빠르게 액세스하고 실제 유형으로 올바르게 변환할 수 있습니다. 그러나 우리는 여전히 많은 것이 부족합니다. delete 연산자를 사용하여 힙에 있는 개체를 직접 삭제해야 하므로 프로그램 종료 후 개체를 올바르게 삭제해야 합니다.
또한 배열이 완전히 채워진 경우 안전한 배열 크기 조정 수단이 필요합니다. 그러나 우리는 바퀴를 다시 만들지 않을 것입니다. 표준 MetaTrader 5 도구 세트에는 이러한 모든 기능을 구현하는 클래스가 포함되어 있습니다.
이러한 클래스는 범용 CObject 컨테이너/클래스를 기반으로 합니다. 우리 클래스와 마찬가지로 클래스의 실제 유형을 반환하는 Type() 메소드와 CObject 유형의 두 가지 중요한 포인터인 m_prev 및 m_next가 있습니다. 그 목적은 CObject 컨테이너와 CList 클래스의 예를 통해 데이터 저장의 다른 방법인 이중 연결 목록에 대해 논의하는 다음 섹션에서 설명됩니다.
1.6. 이중 연결 목록의 예인 CList 클래스
임의 유형의 요소가 있는 배열에는 단 하나의 주요 결함이 있습니다. 새 요소를 삽입하려는 경우, 특히 이 요소를 배열의 중간에 삽입해야 하는 경우에는 많은 시간과 노력이 필요합니다. 요소는 순서대로 위치하므로 삽입하려면 배열의 크기를 조정하여 총 요소 수를 1씩 늘린 다음 인덱스가 새 값과 일치하도록 삽입된 개체 다음에 오는 모든 요소를 재정렬해야 합니다.
7개의 요소로 구성된 배열이 있고 네 번째 위치에 하나의 요소를 더 삽입하려고 한다고 가정해 보겠습니다. 대략적인 삽입 방식은 다음과 같습니다.

그림 2. 배열 크기 조정 및 새 요소 삽입
요소의 빠르고 효과적인 삽입 및 삭제를 제공하는 데이터 저장 체계가 있습니다. 이러한 방식을 단일 연결 목록 또는 이중 연결 목록이라고 합니다. 목록은 일반 대기열을 상기시킵니다. 우리가 대기열에 있을 때 우리는 우리가 따르는 사람만 알면 됩니다(그 또는 그녀 앞에 서 있는 사람을 알 필요는 없습니다). 우리는 또한 우리 뒤에 서 있는 사람을 알 필요가 없습니다. 이 사람은 자신의 대기열 포지션을 제어해야 하기 때문입니다.
큐는 단일 연결 목록의 전형적인 예입니다. 그러나 목록은 이중 연결될 수도 있습니다. 이 경우 대기열에 있는 모든 사람은 이전 사람뿐 아니라 뒤에 있는 사람도 알고 있습니다. 그래서 각 사람에게 문의하면 대기열의 양방향으로 이동할 수 있습니다.
표준 라이브러리에서 사용 가능한 표준 CList는 정확히 이 알고리즘을 제공합니다. 이미 알려진 클래스로 대기열을 만들어 보겠습니다. 그러나 이번에는 CObjectCustom이 아닌 표준 CObject에서 파생됩니다.
이것은 다음과 같이 개략적으로 나타낼 수 있습니다.

그림 3. 이중 연결 목록의 체계
따라서 이것은 이러한 체계를 생성하는 소스 코드입니다.
//+------------------------------------------------------------------+ //| TestList.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2014, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Object.mqh> #include <Arrays\List.mqh> class CCar : public CObject{}; class CExpert : public CObject{}; class CWealth : public CObject{}; class CShip : public CObject{}; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CList list; list.Add(new CCar()); list.Add(new CExpert()); list.Add(new CWealth()); list.Add(new CShip()); printf(">>> enumerate from begin to end >>>"); EnumerateAll(list); printf("<<< enumerate from end to begin <<<"); ReverseEnumerateAll(list); }-->
우리 클래스는 이제 CObject에서 두 개의 포인터를 갖게 되었습니다. 하나는 이전 요소를 참조하고 다른 하나는 다음 요소를 참조합니다. 목록에서 첫 번째 요소의 이전 요소에 대한 포인터는 NULL과 같습니다. 목록 끝에 있는 요소에는 NULL과 동일한 다음 요소에 대한 포인터가 있습니다. 따라서 요소를 하나씩 열거하여 전체 대기열을 열거할 수 있습니다.
EnumerateAll() 및 ReverseEnumerateAll() 함수는 목록의 모든 요소를 열거합니다.
첫 번째 항목은 처음부터 끝까지 목록을 열거하고 두 번째 항목은 처음부터 끝까지 목록을 열거합니다. 이러한 함수의 소스 코드는 다음과 같습니다.
//+------------------------------------------------------------------+ //| Enumerates the list from beginning to end displaying a sequence | //| number of each element in the terminal. | //+------------------------------------------------------------------+ void EnumerateAll(CList& list) { CObject* node = list.GetFirstNode(); for(int i = 0; node != NULL; i++, node = node.Next()) printf("Element at " + (string)i); } //+------------------------------------------------------------------+ //| Enumerates the list from end to beginning displaying a sequence | //| number of each element in the terminal | //+------------------------------------------------------------------+ void ReverseEnumerateAll(CList& list) { CObject* node = list.GetLastNode(); for(int i = list.Total()-1; node != NULL; i--, node = node.Prev()) printf("Element at " + (string)i); }-->
이 코드는 어떻게 작동합니까? 사실, 그것은 아주 간단합니다. 처음에 EnumerateAll() 함수의 첫 번째 노드에 대한 참조를 얻습니다. 그런 다음 for 루프에서 이 노드의 시퀀스 번호를 인쇄하고 node = node.Next() 명령을 사용하여 다음 노드로 이동합니다. 요소의 현재 인덱스를 1씩 반복하는 것을 잊지 마십시오(i++). 열거는 현재 노드가 NULL이 될 때까지 계속됩니다. for의 두 번째 블록에 있는 코드는 노드 != NULL을 담당합니다.
이 함수의 역 버전 ReverseEnumerateAll()은 처음에 목록 CObject* 노드의 마지막 요소를 가져오는 유일한 차이점을 제외하고 유사하게 동작합니다. 노드 = list.GetLastNode(). for 루프에서는 다음이 아니라 목록 노드의 이전 요소 = node.Prev()를 가져옵니다.
코드를 실행하면 다음 메시지가 표시됩니다.
2015.02.13 17:52:02.974 TestList (USDCHF,D1) 열기 완료.
2015.02.13 17:52:02.974 TestList (USDCHF,D1) 0의 요소
2015.02.13 17:52:02.974 TestList (USDCHF,D1) 1의 요소
2015.02.13 17:52:02.974 TestList (USDCHF,D1) 2의 요소
2015.02.13 17:52:02.974 TestList (USDCHF,D1) 3의 요소
2015.02.13 17:52:02.974 TestList (USDCHF,D1) <<< 처음부터 끝까지 열거 <<<
2015.02.13 17:52:02.974 TestList (USDCHF,D1) 3의 요소
2015.02.13 17:52:02.974 TestList (USDCHF,D1) 2의 요소
2015.02.13 17:52:02.974 TestList (USDCHF,D1) 1의 요소
2015.02.13 17:52:02.974 TestList (USDCHF,D1) 0의 요소
2015.02.13 17:52:02.974 TestList (USDCHF,D1) >>> 처음부터 끝까지 열거 >>>
목록에 새 요소를 쉽게 삽입할 수 있습니다. 새 요소를 참조하도록 이전 및 다음 요소의 포인터를 변경하면 이 새 요소가 이전 및 다음 개체를 참조하게 됩니다.
이 계획은 생각보다 쉬워 보입니다.

그림 4. 이중 연결 목록에 새 요소 삽입
목록의 주요 단점은 색인으로 각 요소를 참조할 수 없다는 것입니다.
예를 들어, 그림 4와 같이 CExpert를 참조하려면 먼저 CCar에 대한 접근 권한을 얻어야 하고, 이후 CExpert로 이동할 수 있습니다. CWeather의 경우도 마찬가지입니다. 목록의 맨 끝에 가까우므로 맨 끝에서 액세스하기가 더 쉬울 것입니다. 이를 위해 먼저 CShip을 참조한 다음 CWeather를 참조해야 합니다.
포인터로 이동하는 것은 직접 인덱싱에 비해 느린 작업입니다. 최신 중앙 처리 장치는 특히 배열 작업에 최적화되어 있습니다. 그렇기 때문에 목록이 잠재적으로 더 빨리 작동하더라도 실제로 배열이 더 선호될 수 있습니다.
제 2 장. 연관 배열 조직 이론
2.1. 일상 생활의 연관 배열
우리는 일상 생활에서 연관 배열에 영구적으로 직면합니다. 그러나 그것들은 우리에게 너무나 명백해서 우리가 그것들을 당연한 것으로 인식합니다. 연관 배열 또는 사전의 가장 간단한 예는 일반적인 전화 번호부입니다. 책에 있는 각 전화번호는 특정 사람의 이름과 연결되어 있습니다. 그런 책에 나오는 사람의 이름은 고유키이고, 전화번호는 단순한 숫자값이다. 전화번호부에 있는 모든 사람은 둘 이상의 전화번호를 가질 수 있습니다. 예를 들어, 사람은 집, 휴대폰 및 회사 전화번호를 가질 수 있습니다.
일반적으로 숫자는 무제한일 수 있지만 사람의 이름은 고유합니다. 예를 들어, 전화번호부에 Alexander라는 두 사람이 있으면 혼란스러울 것입니다. 때때로 우리는 잘못된 번호로 전화를 걸 수 있습니다. 그렇기 때문에 이러한 상황을 피하기 위해 키(이 경우 이름)는 고유해야 합니다. 그러나 동시에 사전은 충돌을 해결하고 이에 저항하는 방법을 알고 있어야 합니다. 두 개의 동일한 이름은 전화번호부를 파괴하지 않습니다. 따라서 우리의 알고리즘은 이러한 상황을 처리하는 방법을 알아야 합니다.
우리는 실생활에서 여러 종류의 사전을 사용합니다. 예를 들어 전화번호부는 고유 회선(가입자 이름)이 키이고 숫자가 값인 사전입니다. 외국어 사전은 또 다른 구조를 가지고 있습니다. 영어 단어가 키가 되고 그 번역이 값이 됩니다. 이 두 연관 배열은 동일한 데이터 처리 방법을 기반으로 하므로 사전은 다목적이어야 하고 모든 유형을 저장하고 비교할 수 있어야 합니다
프로그래밍에서 자신만의 사전과 "공책 (notebooks)"을 만드는 것도 편리할 수 있습니다.
2.2. switch-case 연산자 또는 단순 배열을 기반으로 하는 기본 연관 배열
간단한 연관 배열을 쉽게 만들 수 있습니다. MQL5 언어의 표준 도구(예: switch 연산자 또는 배열)를 사용하기만 하면 됩니다.
이러한 코드를 자세히 살펴보겠습니다.
//+------------------------------------------------------------------+ //| Returns string representation of the period depending on | //| a passed timeframe value. | //+------------------------------------------------------------------+ string PeriodToString(ENUM_TIMEFRAMES tf) { switch(tf) { case PERIOD_M1: return "M1"; case PERIOD_M5: return "M5"; case PERIOD_M15: return "M15"; case PERIOD_M30: return "M30"; case PERIOD_H1: return "H1"; case PERIOD_H4: return "H4"; case PERIOD_D1: return "D1"; case PERIOD_W1: return "W1"; case PERIOD_MN1: return "MN1"; } return "unknown"; }-->
이 경우 switch-case 연산자는 사전처럼 작동합니다. ENUM_TIMEFRAMES의 각 값에는 이 기간을 설명하는 문자열 값이 있습니다. 스위치 연산자가 전환된 통로(러시아어)라는 사실 때문에 필요한 변형 케이스에 즉시 액세스할 수 있으며 다른 변형 케이스는 열거되지 않습니다. 이것이 이 코드가 매우 효율적인 이유입니다.
그러나 단점은 먼저 모든 값을 수동으로 채워야 하며, 하나 또는 다른 값 ENUM_TIMEFRAMES으로 반환되어야 한다는 것입니다. 둘째, 스위치는 정수 값으로만 작동할 수 있습니다. 그러나 전송된 문자열에 따라 시간 프레임 유형을 반환할 수 있는 역함수를 작성하는 것이 더 어려울 것입니다. 이러한 접근 방식의 세 번째 단점은 이 방법이 충분히 유연하지 않다는 것입니다. 가능한 모든 변형을 미리 지정해야 합니다. 그러나 새 데이터를 사용할 수 있게 되면 사전의 값을 동적으로 채워야 하는 경우가 많습니다.
'키-값' 쌍 저장의 두 번째 "전면" 방법은 키를 인덱스로 사용하고 값이 배열 요소인 배열을 만드는 것입니다.
예를 들어, 유사한 작업, 즉 시간 프레임 문자열 표현을 반환하는 문제를 해결해 보겠습니다.
//+------------------------------------------------------------------+ //| String values corresponding to the | //| time frame. | //+------------------------------------------------------------------+ string tf_values[]; //+------------------------------------------------------------------+ //| Adding associative values to the array. | //+------------------------------------------------------------------+ void InitTimeframes() { ArrayResize(tf_values, PERIOD_MN1+1); tf_values[PERIOD_M1] = "M1"; tf_values[PERIOD_M5] = "M5"; tf_values[PERIOD_M15] = "M15"; tf_values[PERIOD_M30] = "M30"; tf_values[PERIOD_H1] = "H1"; tf_values[PERIOD_H4] = "H4"; tf_values[PERIOD_D1] = "D1"; tf_values[PERIOD_W1] = "W1"; tf_values[PERIOD_MN1] = "MN1"; } //+------------------------------------------------------------------+ //| Returns string representation of the period depending on | //| a passed timeframe value. | //+------------------------------------------------------------------+ void PeriodToStringArray(ENUM_TIMEFRAMES tf) { if(ArraySize(tf_values) < PERIOD_MN1+1) InitTimeframes(); return tf_values[tf]; }-->
이 코드는 ENUM_TIMFRAMES가 인덱스로 지정된 인덱스별 참조를 나타냅니다. 값을 반환하기 전에 함수는 배열이 필수 요소로 채워져 있는지 확인합니다. 그렇지 않은 경우 함수는 채우기를 특수 함수인 InitTimeframes()에 위임합니다. 스위치 연산자와 동일한 단점이 있습니다.
또한 이러한 사전 구조는 큰 값으로 배열을 초기화해야 합니다. 따라서 PERIOD_MN1 수정자 (modifier)의 값은 49153입니다. 즉, 9개의 시간 프레임만 저장하려면 49153개의 셀이 필요합니다. 다른 셀은 채워지지 않은 상태로 유지됩니다. 이 데이터 할당 방법은 간결한 방법이 아니지만 열거가 작고 연속적인 숫자 범위로 구성된 경우 적절할 수 있습니다.
2.3. 기본 유형을 고유 키로 변환
딕셔너리에 사용되는 알고리즘은 키와 값의 종류에 관계없이 유사하므로 데이터 정렬을 수행해야 하나의 알고리즘으로 다양한 데이터 유형을 처리할 수 있습니다. 사전 알고리즘은 보편적이며 모든 기본 유형을 키로 지정할 수 있는 값을 저장할 수 있습니다(예: int, enum, double). 또는 문자열.
실제로 MQL5에서 모든 기본 데이터 유형은 부호 없는 ulong 숫자로 표시될 수 있습니다. 예를 들어, short 또는 ushort 데이터 유형은 ulong의 "짧은" 버전입니다.
ulong 유형이 ushort 값을 저장한다는 것을 명확히 이해하면 항상 안전한 명시적 유형 변환을 수행할 수 있습니다.
ulong ln = (ushort)103; // Save the ushort value in the ulong type (103) ushort us = (ushort)ln; // Get the ushort value from the ulong type (103)-->
char 및 int 유형과 서명되지 않은 유사체의 경우도 마찬가지입니다. ulong은 크기가 작거나 같은 모든 유형을 저장할 수 있기 때문입니다. 울롱합니다. Datetime, enum 및 color 유형은 정수 32비트 uint 숫자를 기반으로 하므로 ulong으로 안전하게 변환할 수 있습니다. bool 유형은 거짓을 의미하는 0과 참을 의미하는 1의 두 가지 값만 갖습니다. 따라서 bool 유형의 값은 ulong 유형 변수에도 저장할 수 있습니다. 그 외에도 많은 MQL5 시스템 기능이 이 기능을 기반으로 합니다.
예를 들어, AccountInfoInteger() 함수는 long 유형의 정수 값을 반환하며, 이는 ulong 유형의 계정 번호와 거래 권한의 부울 값(ACCOUNT_TRADE_ALLOWED)일 수도 있습니다.
그러나 MQL5에는 정수 유형과 구별되는 세 가지 기본 유형이 있습니다. 정수 ulong 유형으로 직접 변환할 수 없습니다. 이러한 유형 중에는 double 및 float 및 문자열과 같은 부동 소수점 유형이 있습니다. 그러나 몇 가지 간단한 작업으로 고유한 정수 키/값으로 변환할 수 있습니다.
각 부동 소수점 값은 밑수와 거듭제곱이 모두 정수 값으로 별도로 저장되는 임의의 거듭제곱으로 거듭난 일부 밑수로 설정될 수 있습니다. 이러한 종류의 저장 방법은 double 및 float 값에 사용됩니다. float 유형은 가수와 거듭제곱을 저장하기 위해 32자리를 사용하고, double 유형은 64자리를 사용합니다.
ulong 유형으로 직접 변환하려고 하면 값이 단순히 반올림됩니다. 이 경우 3.0과 3.14159는 동일한 ulong 값인 3을 제공합니다. 이 두 가지 다른 값에 대해 다른 키가 필요하기 때문에 이것은 부적절합니다. C 유형 언어에서 사용할 수 있는 드문 기능 중 하나가 구출됩니다. 이를 구조 변환이라고 합니다. 크기가 하나인 경우 두 개의 다른 구조를 변환할 수 있습니다(한 구조를 다른 구조로 변환).
하나는 ulong 유형 값을 저장하고 다른 하나는 double 유형 값을 저장하는 두 구조에서 이 예를 분석해 보겠습니다.
struct DoubleValue{ double value;} dValue; struct ULongValue { ulong value; } lValue; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- dValue.value = 3.14159; lValue = (ULongValue)dValue; printf((string)lValue.value); dValue.value = 3.14160; lValue = (ULongValue)dValue; printf((string)lValue.value); }-->
이 코드는 ULongValue 구조의 DoubleValue 구조를 바이트 단위로 복사합니다. 변수의 크기와 순서가 같기 때문에 dValue.value의 double 값은 lValue.value의 ulong 변수에 바이트 단위로 복사됩니다.
그 후 이 변수 값이 출력됩니다. dValue.value를 3.14160으로 변경하면 lValue.value도 변경됩니다.
다음은 printf() 함수에 의해 표시될 결과입니다.
2015.02.16 15:37:50.646 TestList (USDCHF,H1) 4614256673094690983
2015.02.16 15:37:50.646 TestList (USDCHF,H1) 4614256650576692846
float 유형은 double 유형의 짧은 버전입니다. 따라서 float 유형을 ulong 유형으로 변환하기 전에 float 유형을 double로 안전하게 확장할 수 있습니다.
float fl = 3.14159f; double dbl = fl;-->
그런 다음 구조 변환을 통해 double을 ulong 유형으로 변환합니다.
2.4. 문자열 해싱 및 해시를 키로 사용
위의 예에서 키는 문자열이라는 하나의 데이터 유형으로 표현되었습니다. 그러나 상황이 다를 수 있습니다. 예를 들어 전화 번호의 처음 세 자리는 전화 공급자를 나타냅니다. 이 경우 특히 이 세 자리 숫자는 키를 나타냅니다. 다른 한편으로, 각 문자열은 각 자리가 알파벳 문자의 시퀀스 번호를 의미하는 고유한 숫자로 표현될 수 있습니다. 따라서 문자열을 고유 숫자로 변환하고 이 숫자를 관련 값에 대한 정수 키로 사용할 수 있습니다.
이 방법은 좋지만 다목적은 아닙니다. 수백 개의 기호가 포함된 문자열을 키로 사용하면 숫자가 엄청나게 커질 것입니다. 모든 유형의 단순 변수로 캡처하는 것은 불가능합니다. 해시 함수는 이 문제를 해결하는 데 도움이 됩니다. 해시 함수는 모든 데이터 유형(예: 문자열)을 허용하고 이 문자열을 특징짓는 고유한 숫자를 반환하는 특정 알고리즘입니다.
입력 데이터의 한 기호가 변경되어도 숫자가 완전히 달라집니다. 이 함수에서 반환된 숫자는 고정된 범위를 갖습니다. 예를 들어, Adler32() 해시 함수는 매개변수를 임의의 문자열 형식으로 받아들이고 0에서 2까지 32의 거듭제곱으로 제곱한 숫자를 반환합니다. 이 기능은 매우 간단하지만 우리 작업에 잘 맞습니다.
MQL5에 소스 코드가 있습니다.
//+------------------------------------------------------------------+ //| Accepts a string and returns hashing 32-bit value, | //| which characterizes this string. | //+------------------------------------------------------------------+ uint Adler32(string line) { ulong s1 = 1; ulong s2 = 0; uint buflength=StringLen(line); uchar char_array[]; ArrayResize(char_array, buflength,0); StringToCharArray(line, char_array, 0, -1, CP_ACP); for (uint n=0; n<buflength; n++) { s1 = (s1 + char_array[n]) % 65521; s2 = (s2 + s1) % 65521; } return ((s2 << 16) + s1); }-->
전송된 문자열에 따라 반환되는 숫자를 살펴보겠습니다.
이를 위해 우리는 이 함수를 호출하고 다른 문자열을 전송하는 간단한 스크립트를 작성할 것입니다.
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- printf("Hello world - " + (string)Adler32("Hello world")); printf("Hello world! - " + (string)Adler32("Hello world!")); printf("Peace - " + (string)Adler32("Peace")); printf("MetaTrader - " + (string)Adler32("MetaTrader")); }-->
이 스크립트 출력은 다음을 나타냅니다.
2015.02.16 13:29:12.576 TestList (USDCHF,H1) MetaTrader - 352191466
2015.02.16 13:29:12.576 TestList (USDCHF,H1) Peace - 91685343
2015.02.16 13:29:12.576 TestList (USDCHF,H1) Hello world! - 487130206
2015.02.16 13:29:12.576 TestList (USDCHF,H1) Hello world - 413860925
보시다시피 각 문자열에는 해당하는 고유 번호가 있습니다. "Hello world" 및 "Hello world!" 문자열에 주의를 기울이십시오. - 거의 동일합니다. 유일한 차이점은 두 번째 문자열 끝에 있는 느낌표입니다.
그러나 Adler32()가 제공한 숫자는 두 경우 모두 절대적으로 다릅니다.
이제 문자열 유형을 서명되지 않은 uint 값으로 변환하는 방법을 알고 문자열 유형 키 대신 정수 해시를 저장할 수 있습니다. 두 문자열에 하나의 해시가 있는 경우 동일한 문자열일 가능성이 가장 높습니다. 따라서 값에 대한 키는 문자열이 아니라 이 문자열을 기반으로 생성된 정수 해시입니다.
2.5. 키로 인덱스를 파악합니다. 목록 배열
이제 우리는 MQL5의 기본 유형을 ulong 부호 없는 유형으로 변환하는 방법을 알고 있습니다. 정확히 이 유형은 우리의 값이 대응할 실제 키가 될 것입니다. 하지만 ulong 타입의 유니크한 키만으로는 부족하다. 물론 각 객체의 고유 키를 알고 있다면 switch-case 연산자 또는 임의 길이의 배열을 기반으로 하는 몇 가지 기본 저장 방법을 발명할 수 있습니다.
이러한 방법은 현재 장의 섹션 2.2에 설명되어 있습니다. 그러나 그것들은 충분히 유연하고 효율적이지 않습니다. switch-case의 경우 이 연산자의 모든 변형을 설명할 수 없는 것 같습니다.
수십만 개의 객체가 있는 것처럼 수십만 개의 키로 구성된 스위치 연산자를 컴파일 단계에서 설명해야 하는데 이는 불가능하다. 두 번째 방법은 요소의 키가 인덱스이기도 한 배열을 사용하는 것입니다. 필요한 요소를 추가하여 동적 방식으로 배열의 크기를 조정할 수 있습니다. 따라서 요소의 키가 될 인덱스로 지속적으로 참조할 수 있습니다.
이 솔루션의 초안을 작성해 보겠습니다.
//+------------------------------------------------------------------+ //| Array to store strings by a key. | //+------------------------------------------------------------------+ string array[]; //+------------------------------------------------------------------+ //| Adds a string to the associative array. | //| RESULTS: | //| Returns true, if the string has been added, otherwise | //| returns false. | //+------------------------------------------------------------------+ bool AddString(string str) { ulong key=Adler32(str); if(key>=ArraySize(array) && ArrayResize(array,key+1)<=key) return false; array[key]=str; return true; }-->
그러나 실생활에서 이 코드는 오히려 문제를 제기하지만 해결하지는 못합니다. 해시 함수가 큰 해시를 출력한다고 가정해 보겠습니다. 주어진 예에서 배열 인덱스는 해시와 같으므로 배열 크기를 조정해야 배열이 거대해집니다. 그리고 그것이 반드시 우리가 성공할 것이라는 의미는 아닙니다. 몇 기가바이트에 달하는 크기의 컨테이너에 하나의 문자열을 저장하시겠습니까?
두 번째 문제는 충돌의 경우 이전 값이 새 값으로 대체된다는 것입니다. 결국 Adler32() 함수가 두 개의 서로 다른 문자열에 대해 하나의 해시 키를 반환할 가능성은 없습니다. 키를 사용하여 빠르게 참조하기 위해 데이터의 일부를 잃고 싶습니까? 이러한 질문에 대한 대답은 분명합니다. 아니요, 그렇지 않습니다. 이러한 상황을 피하기 위해서는 저장 알고리즘을 수정하고 목록 배열을 기반으로 특수 목적의 하이브리드 컨테이너를 개발해야 합니다.
목록 배열은 배열과 목록의 장점을 결합한 것입니다. 이 두 클래스는 표준 라이브러리에 표시됩니다. 배열은 정의되지 않은 요소를 매우 빠르게 참조할 수 있지만 배열 자체의 크기는 느린 속도로 조정된다는 점을 상기해야 합니다. 그러나 목록을 사용하면 짧은 시간 내에 새 요소를 추가하고 제거할 수 있지만 목록의 각 요소에 대한 액세스는 다소 느린 작업입니다.
목록 배열은 다음과 같이 나타낼 수 있습니다.

그림 5. 목록 배열의 체계
목록 배열은 각 요소가 목록 형식을 갖는 배열이라는 스키마에서 분명합니다. 어떤 이점을 제공하는지 봅시다. 무엇보다도 색인으로 모든 목록을 빠르게 참조할 수 있습니다. 또 다른 예로, 각 데이터 요소를 목록에 저장하면 배열의 크기를 조정하지 않고 목록에서 요소를 즉시 추가 및 제거할 수 있습니다. 배열 인덱스는 비어 있거나 NULL과 같을 수 있습니다. 이는 이 인덱스에 해당하는 요소가 아직 추가되지 않았음을 의미합니다.
배열과 목록의 조합은 흔하지 않은 기회를 한 번 더 제공합니다. 하나의 인덱스를 사용하여 두 개 이상의 요소를 저장할 수 있습니다. 그 필요성을 이해하기 위해 3개의 요소가 있는 배열에 10개의 숫자를 저장해야 한다고 가정할 수 있습니다. 보시다시피 배열의 요소보다 숫자가 더 많습니다. 우리는 배열에 목록을 저장하는 이 문제를 해결할 것입니다. 하나 또는 다른 숫자를 저장하기 위해 3개의 배열 인덱스 중 하나에 연결된 3개의 목록 중 하나가 필요하다고 가정해 보겠습니다.
목록 인덱스를 결정하려면 배열의 요소 수로 숫자를 나눈 나머지를 찾아야 합니다.
배열 인덱스 = 배열의 % 요소 수;
예를 들어 2번의 목록 색인은 다음과 같습니다. 2%3 = 2. 즉, 인덱스 2는 인덱스별로 목록에 저장됩니다. 숫자 3은 인덱스 3%3 = 0에 의해 저장됩니다. 숫자 7은 인덱스 7%3 = 1에 의해 저장됩니다. 목록 인덱스를 결정한 후에는 목록 끝에 이 숫자를 추가하기만 하면 됩니다.
목록에서 번호를 추출하려면 유사한 작업이 필요합니다. 컨테이너에서 숫자 7을 추출한다고 가정해 보겠습니다. 이를 위해 우리는 그것이 어떤 컨테이너에 있는지 알아내야 합니다: 7%3=1. 인덱스 1에 의해 목록에서 숫자 7을 찾을 수 있다고 결정한 후 전체 목록을 정렬하고 요소 중 하나가 7과 같으면 이 값을 반환해야 합니다.
하나의 인덱스를 사용하여 여러 요소를 저장할 수 있다면 적은 양의 데이터를 저장하기 위해 거대한 배열을 만들 필요가 없습니다. 숫자 232,547,879를 0-10자리로 구성되고 3개의 요소로 구성된 배열에 저장해야 한다고 가정해 보겠습니다. 이 숫자의 목록 인덱스는 (232,547,879 % 3 = 2)와 같습니다.
숫자를 해시로 바꾸면 사전에 있어야 하는 모든 요소의 인덱스를 찾을 수 있습니다. 해시는 숫자이기 때문입니다. 또한 하나의 목록에 여러 요소를 저장할 수 있으므로 해시가 고유할 필요가 없습니다. 동일한 해시를 가진 요소는 하나의 목록에 있습니다. 키로 요소를 추출해야 하는 경우 이러한 요소를 비교하고 키에 해당하는 요소를 추출합니다.
동일한 해시를 가진 두 요소에 두 개의 고유 키가 있기 때문에 가능합니다. 키의 고유성은 사전에 요소를 추가하는 기능으로 제어할 수 있습니다. 해당 키가 이미 사전에 있는 경우 단순히 새 요소를 추가하지 않습니다. 이것은 하나의 전화번호에만 가입자의 통신을 제어하는 것과 같습니다.
2.6. 배열 크기 조정, 목록 길이 최소화
목록 배열이 작을수록 더 많은 요소를 추가할수록 알고리즘에 의해 더 긴 목록 체인이 형성됩니다. 첫 번째 장에서 말했듯이 이 체인의 요소에 액세스하는 것은 비효율적인 작업입니다. 목록이 짧을수록 컨테이너는 인덱스로 각 요소에 대한 액세스를 제공하는 배열처럼 보일 것입니다. 짧은 목록과 긴 배열을 목표로 해야 합니다. 10개의 요소에 대한 완벽한 배열은 각각 하나의 요소를 갖는 10개의 목록으로 구성된 배열입니다.
최악의 변형은 하나의 목록으로 구성된 길이가 10개 요소인 배열입니다. 프로그램의 흐름 동안 모든 요소가 컨테이너에 동적으로 추가되기 때문에 얼마나 많은 요소가 추가될지 예측할 수 없습니다. 이것이 배열의 동적 크기 조정에 대해 생각해야 하는 이유입니다. 또한 목록의 체인 수는 하나의 요소가 되어야 합니다. 이 목적을 위해 배열 크기는 요소의 총 수와 동일하게 유지되어야 합니다. 요소를 영구적으로 추가하려면 배열의 영구적인 크기 조정이 필요합니다.
배열 크기 조정과 함께 요소가 속할 수 있는 목록 인덱스가 크기 조정 후에 변경될 수 있으므로 모든 목록의 크기를 조정해야 하기 때문에 상황이 복잡합니다. 예를 들어 배열에 3개의 요소가 있는 경우 숫자 5는 두 번째 인덱스(5%3 = 2)에 저장됩니다. 요소가 6개일 경우 다섯 번째 인덱스(5%6=5)에 5번이 저장됩니다. 따라서 사전 크기 조정은 느린 작업입니다. 가능한 한 드물게 수행되어야 합니다. 반면에 우리가 그것을 전혀 수행하지 않으면 새로운 요소마다 사슬이 늘어나고 각 요소에 대한 액세스는 점점 덜 효율적이 될 것입니다.
배열 크기 조정의 양과 체인의 평균 길이 사이에 합리적인 절충안을 구현하는 알고리즘을 만들 수 있습니다. 다음에 크기를 조정할 때마다 배열의 현재 크기가 두 배로 증가한다는 사실을 기반으로 합니다. 따라서 사전에 처음에 두 개의 요소가 있는 경우 첫 번째 크기 조정은 크기를 4(2^2), 두 번째 크기는 8(2^3), 세 번째 크기는 16(2^3)만큼 크기를 늘립니다. 16번째 크기 조정 후에는 65,536개의 체인(2^16)을 위한 공간이 생깁니다. 추가된 요소의 양이 순환 2의 거듭제곱과 일치하면 각 크기 조정이 수행됩니다. 따라서 실제 필요한 총 메인 메모리는 모든 요소를 두 번 이상 저장하는 데 필요한 메모리를 초과하지 않습니다. 반면에 로그 법칙은 배열의 빈번한 크기 조정을 방지하는 데 도움이 됩니다.
마찬가지로 목록에서 요소를 제거하면 배열의 크기를 줄이고 할당된 주 메모리를 절약할 수 있습니다.
3 장. 연관 배열의 실제 개발
3.1. 템플릿 CDictionary 클래스, AddObject 및 DeleteObjectByKey 메소드 및 KeyValuePair 컨테이너
연관 배열은 다목적이어야 하며 모든 유형의 키와 함께 작동할 수 있어야 합니다. 동시에 표준 CObject를 기반으로 하는 개체를 값으로 사용합니다. 클래스에서 모든 기본 변수를 찾을 수 있으므로 사전은 원스톱 솔루션이 될 것입니다. 물론 여러 클래스의 사전을 만들 수 있습니다. 각 기본 유형에 대해 별도의 클래스 유형을 사용할 수 있습니다.
예를 들어 다음 클래스를 만들 수 있습니다.
CDictionaryLongObj // For storing pairs <ulong, CObject*> CDictionaryCharObj // For storing pairs <char, CObject*> CDictionaryUcharObj // For storing pairs <uchar, CObject*> CDictionaryStringObj // For storing pairs <string, CObject*> CDictionaryDoubleObj // For storing pairs <double, CObject*> ...-->
그러나 MQL5에는 기본 유형이 너무 많습니다. 또한 모든 유형에 하나의 핵심 코드가 있기 때문에 모든 코드 오류를 여러 번 수정해야 합니다. 중복을 피하기 위해 템플릿을 사용합니다. 하나의 클래스가 있지만 여러 데이터 유형을 동시에 처리합니다. 이것이 클래스의 주요 메소드가 템플릿이 될 이유입니다.
우선 첫 번째 템플릿 메소드인 Add()를 만들어 보겠습니다. 이 방법은 임의의 키가 있는 요소를 사전에 추가합니다. 사전 클래스의 이름은 CDictionary입니다. 요소와 함께 사전에는 CList 목록에 대한 포인터 배열이 포함됩니다. 그리고 우리는 다음 체인에 요소를 저장할 것입니다:
//+------------------------------------------------------------------+ //| An associative array or a dictionary storing elements as | //| <key - value>, where a key may be represented by any base type, | //| and a value may be represented be a CObject type object. | //+------------------------------------------------------------------+ class CDictionary { private: CList *m_array[]; // List array. template<typename T> bool AddObject(T key,CObject *value); }; //+------------------------------------------------------------------+ //| Adds a CObject type element with a T key to the dictionary | //| INPUT PARAMETRS: | //| T key - any base type, for instance int, double or string. | //| value - a class that derives from CObject. | //| RETURNS: | //| true, if the element has been added, otherwise - false. | //+------------------------------------------------------------------+ template<typename T> bool CDictionary::AddObject(T key,CObject *value) { if(ContainsKey(key)) return false; if(m_total==m_array_size){ printf("Resize" + m_total); Resize(); } if(CheckPointer(m_array[m_index])==POINTER_INVALID) { m_array[m_index]=new CList(); m_array[m_index].FreeMode(m_free_mode); } KeyValuePair *kv=new KeyValuePair(key, m_hash, value); if(m_array[m_index].Add(kv)!=-1) m_total++; if(CheckPointer(m_current_kvp)==POINTER_INVALID) { m_first_kvp=kv; m_current_kvp=kv; m_last_kvp=kv; } else { m_current_kvp.next_kvp=kv; kv.prev_kvp=m_current_kvp; m_current_kvp=kv; m_last_kvp=kv; } return true; }-->
AddObject() 메소드는 다음과 같이 작동합니다. 먼저 사전에 추가해야 하는 키가 있는 요소가 있는지 확인합니다. ContainsKey() 메소드가 이 검사를 수행합니다. 사전에 이미 키가 있는 경우 두 요소가 하나의 키에 해당한다는 점에서 불확실성이 발생하므로 새 요소가 추가되지 않습니다.
그런 다음 메소드는 CList 체인이 저장된 배열의 크기를 학습합니다. 배열 크기가 요소 수와 같으면 크기를 조정할 때입니다. 이 작업은 Resize() 메소드에 위임됩니다.
다음 단계는 간단합니다. 결정된 인덱스에 따라 CList 체인이 아직 존재하지 않으면 이 체인을 생성해야 합니다. 인덱스는 ContainsKey() 메소드에 의해 미리 결정됩니다. 결정된 인덱스를 m_index 변수에 저장합니다. 그런 다음 메소드는 목록 끝에 새 요소를 추가합니다. 그러나 그 전에 요소는 특수 컨테이너인 KeyValuePair에 포장됩니다. 표준 CObject를 기반으로 하며 추가 포인터와 데이터로 후자를 확장합니다. 컨테이너 클래스 배열은 잠시 후에 설명합니다. 추가 포인터와 함께 컨테이너는 개체의 원래 키와 해당 해시도 저장합니다.
AddObject() 메소드는 템플릿 메소드입니다.
template<typename T> bool CDictionary::AddObject(T key,CObject *value);-->
이 레코드는 키 인수 유형이 대체이고 실제 유형이 컴파일 시간에 결정됨을 의미합니다.
예를 들어 AddObject() 메소드는 코드에서 다음과 같이 활성화할 수 있습니다.
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { CObject* obj = new CObject(); dictionary.AddObject(124, obj); dictionary.AddObject("simple object", obj); dictionary.AddObject(PERIOD_D1, obj); }-->
이러한 활성화는 템플릿으로 인해 완벽하게 작동합니다.
AddObject() 메소드와 반대되는 DeleteObjectByKey() 메소드도 있습니다. 이 메소드는 키로 사전에서 객체를 삭제합니다.
예를 들어 "Car" 키가 있는 개체가 있는 경우 삭제할 수 있습니다.
if(dict.ContainsKey("Car")) dict.DeleteObjectByKey("Car");-->
코드는 AddObject() 메소드 코드와 매우 유사하므로 여기서는 설명하지 않습니다.
AddObject() 및 DeleteObjectByKey() 메소드는 개체와 직접 작동하지 않습니다. 대신 표준 CObject 클래스를 기반으로 각 개체를 KeyValuePair 컨테이너에 포장합니다. 이 컨테이너에는 요소를 연결할 수 있는 추가 포인터가 있으며 개체에 대해 결정된 원래 키와 해시도 있습니다. 컨테이너는 또한 충돌을 피할 수 있도록 전달된 키가 동일한지 테스트합니다. 이 내용은 ContainsKey() 메소드 전용 섹션에서 논의할 것입니다.
이제 이 클래스의 내용을 설명합니다.
//+------------------------------------------------------------------+ //| Container to store CObject elements | //+------------------------------------------------------------------+ class KeyValuePair : public CObject { private: string m_string_key; // Stores a string key double m_double_key; // Stores a floating-point key ulong m_ulong_key; // Stores an unsigned integer key ulong m_hash; public: CObject *object; KeyValuePair *next_kvp; KeyValuePair *prev_kvp; template<typename T> KeyValuePair(T key, ulong hash, CObject *obj); ~KeyValuePair(); template<typename T> bool EqualKey(T key); ulong GetHash(){return m_hash;} }; template<typename T> KeyValuePair::KeyValuePair(T key, ulong hash, CObject *obj) { m_hash = hash; string name=typename(key); if(name=="string") m_string_key = (string)key; else if(name=="double" || name=="float") m_double_key = (double)key; else m_ulong_key = (ulong)key; object=obj; } KeyValuePair::~KeyValuePair() { delete object; } template<typename T> bool KeyValuePair::EqualKey(T key) { string name=typename(key); if(name=="string") return key == m_string_key; if(name=="double" || name=="float") return m_double_key == (double)key; else return m_ulong_key == (ulong)key; }-->
3.2. 유형명 기반 런타임 유형 식별, 해시 샘플링
이제 메소드에서 정의되지 않은 유형을 사용하는 방법을 알았을 때 해시를 결정해야 합니다. 모든 정수 유형에 대해 해시는 ulong 유형으로 확장된 이 유형의 값과 같습니다.
double 및 float 유형의 해시를 계산하려면 "기본 유형을 고유 키로 변환" 섹션에 설명된 구조를 통한 캐스팅을 사용해야 합니다. 문자열에는 해시 함수를 사용해야 합니다. 어쨌든 모든 데이터 유형에는 고유한 해시 샘플링 방법이 필요합니다. 따라서 전송된 유형을 결정하고 이 유형에 따라 해시 샘플링 방법을 활성화하기만 하면 됩니다. 이를 위해 특별한 지시어 typename이 필요합니다.
키를 기반으로 해시를 결정하는 메소드를 GetHashByKey()라고 합니다.
여기에는 다음이 포함됩니다.
//+------------------------------------------------------------------+ //| Calculates a hash basing on a transferred key. The key may be | //| represented by any base MQL type. | //+------------------------------------------------------------------+ template<typename T> ulong CDictionary::GetHashByKey(T key) { string name=typename(key); if(name=="string") return Adler32((string)key); if(name=="double" || name=="float") { dValue.value=(double)key; lValue=(ULongValue)dValue; ukey=lValue.value; } else ukey=(ulong)key; return ukey; }-->
그 논리는 간단합니다. typename 지시문을 사용하여 메소드는 전송된 유형의 문자열 이름을 가져옵니다. 문자열이 키로 전송되면 typename은 "문자열" 값을 반환하고 int 값의 경우 "int"를 반환합니다. 다른 유형에서도 마찬가지입니다. 따라서 반환된 값을 필요한 문자열 상수와 비교하고 이 값이 상수 중 하나와 일치하는 경우 해당 핸들러를 활성화하기만 하면 됩니다.
키가 문자열 유형이면 해당 해시는 Adler32() 함수에 의해 계산됩니다. 키가 실제 유형으로 표시되는 경우 구조 변환으로 인해 해시로 변환됩니다. 다른 모든 유형은 해시가 될 ulong 유형으로 명시적으로 변환됩니다.
3.3. The ContainsKey() 메소드. 해시 충돌에 대한 반응
모든 해싱 함수의 주요 문제는 충돌에 있습니다. 다른 키가 동일한 해시를 제공하는 상황입니다. 이러한 경우 해시가 일치하면 모호성이 발생합니다(두 객체는 사전 논리 측면에서 유사함). 이러한 상황을 피하기 위해 실제 및 요청된 키 유형을 확인하고 실제 키가 일치하는 경우에만 양수 값을 반환해야 합니다. 이것이 ContainsKey() 메소드가 작동하는 방식입니다. 요청한 키가 있는 객체가 있으면 true를 반환하고, 그렇지 않으면 false를 반환합니다.
아마도 이것은 전체 사전에서 가장 유용하고 편리한 방법입니다. 명확한 키를 가진 객체가 존재하는지 여부를 알 수 있습니다.
#include <Dictionary.mqh> CDictionary dict; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { if(dict.ContainsKey("Car")) printf("Car always exists."); else dict.AddObject("Car", new CCar()); }-->
예를 들어 위의 코드는 CCar 유형 객체의 가용성을 확인하고 해당 객체가 없는 경우 CCar를 추가합니다. 이 방법을 사용하면 추가되는 각각의 새 개체의 키 고유성을 확인할 수도 있습니다.
객체 키가 이미 사용된 경우 AddObject() 메소드는 이 새 객체를 사전에 추가하지 않습니다.
template<typename T> bool CDictionary::AddObject(T key,CObject *value) { if(ContainsKey(key)) return false; ... }-->
이것은 사용자와 다른 클래스 메소드 모두에서 많이 사용되는 보편적인 방법입니다.
내용:
//+------------------------------------------------------------------+ //| Checks whether the dictionary contains a key of T arbitrary type.| //| RETURNS: | //| Returns true, if an object having this key exists, | //| otherwise returns false. | //+------------------------------------------------------------------+ template<typename T> bool CDictionary::ContainsKey(T key) { m_hash=GetHashByKey(key); m_index=GetIndexByHash(m_hash); if(CheckPointer(m_array[m_index])==POINTER_INVALID) return false; CList *list=m_array[m_index]; m_current_kvp=list.GetCurrentNode(); if(m_current_kvp == NULL)return false; if(m_current_kvp.EqualKey(key)) return true; m_current_kvp=list.GetFirstNode(); while(true) { if(m_current_kvp.EqualKey(key)) return true; m_current_kvp=list.GetNextNode(); if(m_current_kvp==NULL) return false; } return false; }-->
먼저 메소드는 GetHashByKey()를 사용하여 해시를 찾습니다. 해시를 기반으로 하는 것보다 CList 체인의 인덱스를 가져옵니다. 여기서 주어진 해시가 있는 개체가 있을 수 있습니다. 이러한 체인이 없으면 해당 키가 있는 객체도 존재하지 않습니다. 이 경우 작업을 조기에 종료하고 false를 반환합니다(이러한 키가 있는 개체는 존재하지 않음). 체인이 존재하면 열거가 시작됩니다.
이 체인의 각 요소는 KeyValuePair 유형 개체로 표시되며 실제 전송된 키와 요소에 저장된 키를 비교하기 위해 제공됩니다. 키가 같으면 메소드는 true를 반환합니다(해당 키가 있는 개체가 있음). 키가 같은지 테스트하는 코드는 KeyValuePair 클래스 목록에 나와 있습니다.
3.4. 메모리의 동적 할당 및 할당 해제
Resize() 메소드는 연관 배열에서 메모리의 동적 할당 및 할당 해제를 담당합니다. 이 메소드는 요소의 수가 m_array 크기와 같을 때마다 활성화됩니다. 목록에서 요소가 삭제될 때도 활성화됩니다. 이 방법은 모든 요소에 대한 저장소 인덱스를 재정의하므로 매우 느리게 작동합니다.
Resize() 메소드의 빈번한 활성화를 방지하기 위해 할당된 메모리의 볼륨은 이전 볼륨에 비해 매번 2배씩 증가합니다. 즉, 사전에 65,536개의 요소를 저장하려면 Resize() 메소드가 16번(2^16) 활성화됩니다. 20번의 활성화 후에 사전은 백만 개 이상의 요소(1,048,576개)를 포함할 수 있습니다. FindNextLevel() 메소드는 필요한 요소의 기하급수적인 증가를 담당합니다.
다음은 Resize() 메소드의 소스 코드입니다.
//+------------------------------------------------------------------+ //| Resizes data storage container | //+------------------------------------------------------------------+ void CDictionary::Resize(void) { int level=FindNextLevel(); int n=level; CList *temp_array[]; ArrayCopy(temp_array,m_array); ArrayFree(m_array); m_array_size=ArrayResize(m_array,n); int total=ArraySize(temp_array); KeyValuePair *kv=NULL; for(int i=0; i<total; i++) { if(temp_array[i]==NULL)continue; CList *list=temp_array[i]; int count=list.Total(); list.FreeMode(false); kv=list.GetFirstNode(); while(kv!=NULL) { int index=GetIndexByHash(kv.GetHash()); if(CheckPointer(m_array[index])==POINTER_INVALID) m_array[index]=new CList(); list.DetachCurrent(); m_array[index].Add(kv); kv=list.GetCurrentNode(); } delete list; } int size=ArraySize(temp_array); ArrayFree(temp_array); }-->
이 방법은 위쪽과 아래쪽 모두에서 작동합니다. 실제 배열이 포함할 수 있는 것보다 적은 요소가 있는 경우 요소 축소 코드가 시작됩니다. 반대로 현재 배열이 충분하지 않으면 배열의 크기가 더 많은 요소에 맞게 조정됩니다. 이 코드에는 많은 컴퓨팅 리소스가 필요합니다.
전체 배열의 크기를 조정해야 하지만 배열의 모든 요소는 이전에 배열의 임시 복사본으로 제거되어야 합니다. 그런 다음 모든 요소에 대한 새 인덱스를 결정해야 하며 그 후에야 새 지점에서 이러한 요소를 찾을 수 있습니다.
3.5. 마무리 스트로크: 개체 검색 및 편리한 인덱서
따라서 CDictionary 클래스에는 이미 작업을 위한 주요 메소드가 있습니다. 특정 키를 가진 객체가 존재하는지 알고 싶다면 ContainsKey() 메소드를 사용할 수 있습니다. AddObject() 메소드를 사용하여 사전에 객체를 추가할 수 있습니다. DeleteObjectByKey() 메소드를 사용하여 사전에서 객체를 삭제할 수도 있습니다.
이제 컨테이너에 있는 모든 객체를 편리하게 열거하기만 하면 됩니다. 이미 알고 있듯이 모든 요소는 키에 따라 특정 순서로 저장됩니다. 그러나 연관 배열에 추가한 것과 동일한 순서로 모든 요소를 열거하는 것이 편리할 것입니다. 이를 위해 KeyValuePair 컨테이너에는 KeyValuePair 유형의 이전 및 다음에 추가된 요소에 대한 두 개의 추가 포인터가 있습니다. 이러한 포인터 덕분에 순차적인 열거를 수행할 수 있습니다.
예를 들어 다음과 같이 연관 배열에 요소를 추가한 경우:
CNumber --> CShip --> CWeather --> CHuman --> CExpert --> CCar
그림 6과 같이 KeyValuePair에 대한 참조를 사용하여 수행되므로 이러한 요소의 열거도 순차적입니다.

그림 6. 순차 배열 열거 방식
이러한 열거를 수행하는 데 다섯 가지 방법이 사용됩니다.
다음은 내용과 간략한 설명입니다.
//+------------------------------------------------------------------+ //| Returns the current object. Returns NULL if an object was not | //| chosen | //+------------------------------------------------------------------+ CObject *CDictionary::GetCurrentNode(void) { if(m_current_kvp==NULL) return NULL; return m_current_kvp.object; } //+------------------------------------------------------------------+ //| Returns the previous object. The current object becomes the | //| previous one after call of the method. Returns NULL if an object | //| was not chosen. | //+------------------------------------------------------------------+ CObject *CDictionary:: GetPrevNode(void) { if(m_current_kvp==NULL) return NULL; if(m_current_kvp.prev_kvp==NULL) return NULL; KeyValuePair *kvp=m_current_kvp.prev_kvp; m_current_kvp=kvp; return kvp.object; } //+------------------------------------------------------------------+ //| Returns the next object. The current object becomes the next one | //| after call of the method. Returns NULL if an object was not | //| chosen. | //+------------------------------------------------------------------+ CObject *CDictionary::GetNextNode(void) { if(m_current_kvp==NULL) return NULL; if(m_current_kvp.next_kvp==NULL) return NULL; KeyValuePair *kvp=m_current_kvp.next_kvp; m_current_kvp=kvp; return kvp.object; } //+------------------------------------------------------------------+ //| Returns the first node from the node list. Returns NULL if the | //| dictionary does not have nodes. | //+------------------------------------------------------------------+ CObject *CDictionary::GetFirstNode(void) { if(m_first_kvp==NULL) return NULL; m_current_kvp=m_first_kvp; return m_first_kvp.object; } //+------------------------------------------------------------------+ //| Returns the last node in the list. Returns NULL if the | //| dictionary does not have nodes. | //+------------------------------------------------------------------+ CObject *CDictionary::GetLastNode(void) { if(m_last_kvp==NULL) return NULL; m_current_kvp=m_last_kvp; return m_last_kvp.object; }-->
이 간단한 반복자 덕분에 추가된 요소를 순차적으로 열거할 수 있습니다.
class CStringValue : public CObject { public: string Value; CStringValue(); CStringValue(string value){Value = value;} }; CDictionary dict; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { dict.AddObject("CNumber", new CStringValue("CNumber")); dict.AddObject("CShip", new CStringValue("CShip")); dict.AddObject("CWeather", new CStringValue("CWeather")); dict.AddObject("CHuman", new CStringValue("CHuman")); dict.AddObject("CExpert", new CStringValue("CExpert")); dict.AddObject("CCar", new CStringValue("CCar")); CStringValue* currString = dict.GetFirstNode(); for(int i = 1; currString != NULL; i++) { printf((string)i + ":\t" + currString.Value); currString = dict.GetNextNode(); } }-->
이 코드는 사전에 추가된 것과 동일한 순서로 객체의 문자열 값을 출력합니다.
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 6: CCar
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 5: CExpert
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 4: CHuman
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 3: CWeather
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 2: CShip
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 1: CNumber
OnStart() 함수에서 코드의 두 문자열을 변경하여 모든 요소를 거꾸로 출력합니다.
CStringValue* currString = dict.GetLastNode(); for(int i = 1; currString != NULL; i++) { printf((string)i + ":\t" + currString.Value); currString = dict.GetPrevNode(); }-->
따라서 출력된 값이 반전됩니다.
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 6: CNumber
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 5: CShip
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 4: CWeather
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 3: CHuman
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 2: CExpert
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 1: CCar
4장. 성능 테스트 및 평가
4.1. 테스트 작성 및 성능 평가
성능 평가는 특히 데이터 저장을 위한 클래스에 대해 이야기하는 경우 클래스 설계의 핵심 요소입니다. 결국 가장 다양한 프로그램이 이 클래스를 활용할 수 있습니다. 이러한 프로그램의 알고리즘은 속도를 높이는 데 중요할 수 있으며 고성능이 필요합니다. 그렇기 때문에 이러한 알고리즘의 성능 및 검색 약점을 평가하는 방법을 아는 것이 중요합니다.
먼저 사전에서 요소를 추가하고 추출하는 속도를 측정하는 간단한 테스트를 작성합니다. 이 테스트는 스크립트처럼 보일 것입니다.
소스 코드는 아래에 첨부되어 있습니다.
//+------------------------------------------------------------------+ //| TestSpeed.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Dictionary.mqh> #define BEGIN 50000 #define STEP 50000 #define END 1000000 //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CDictionary dict(END+1); for(int j=BEGIN; j<=END; j+=STEP) { uint tiks_begin=GetTickCount(); for(int i=0; i<j; i++) dict.AddObject(i,new CObject()); uint tiks_add=GetTickCount()-tiks_begin; tiks_begin=GetTickCount(); CObject *value=NULL; for(int i= 0; i<j; i++) value = dict.GetObjectByKey(i); uint tiks_get=GetTickCount()-tiks_begin; printf((string)j+" elements. Add: "+(string)tiks_add+"; Get: "+(string)tiks_get); dict.Clear(); } }-->
이 코드는 사전에 요소를 순차적으로 추가한 다음 해당 요소를 참조하여 속도를 측정합니다. 그런 다음 DeleteObjectByKey() 메소드를 사용하여 각 요소를 삭제합니다. GetTickCount() 시스템 함수는 속도를 측정합니다.
이 스크립트를 사용하여 다음 세 가지 주요 방법의 시간 종속성을 나타내는 다이어그램을 만들었습니다.
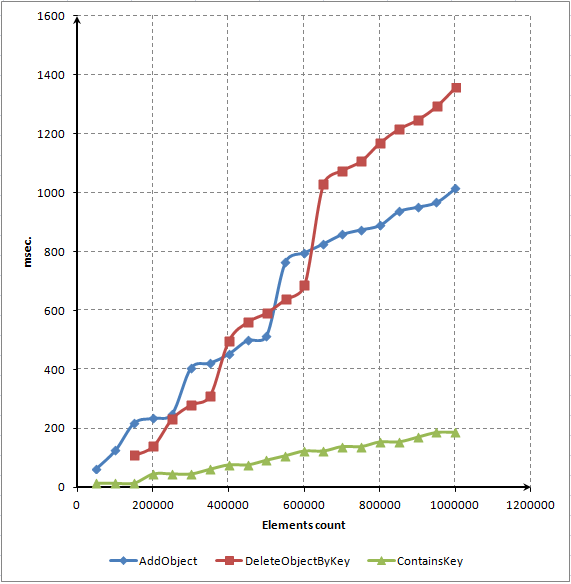
그림 7. 요소 수와 메소드의 작동 시간(밀리초) 간의 종속성에 대한 도트 다이어그램
보시다시피 사전에서 요소를 찾고 삭제하는 데 대부분의 시간이 소요됩니다. 그럼에도 불구하고 요소가 훨씬 빨리 삭제될 것으로 예상했습니다. 코드 프로파일러를 사용하여 메소드의 성능을 향상시키도록 노력할 것입니다. 이 절차는 다음 섹션에서 설명합니다.
ContainsKey() 메소드 다이어그램에 주의하십시오. 선형입니다. 즉, 임의의 요소에 액세스하려면 배열에 있는 이러한 요소의 수에 관계없이 약 한 시간이 필요합니다. 이것은 실제 연관 배열의 필수 기능입니다.
이 기능을 설명하기 위해 하나의 요소에 대한 평균 액세스 시간과 배열의 여러 요소 사이의 종속성 다이어그램을 보여줍니다.
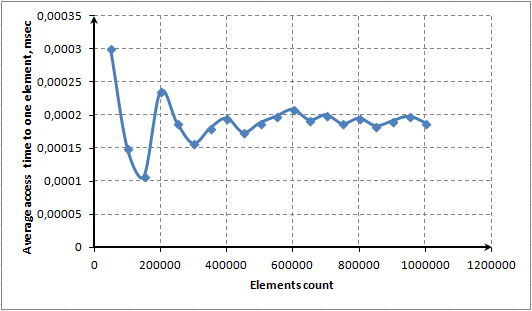
그림 8. ContainsKey() 메소드를 사용하여 한 요소에 대한 평균 액세스 시간
4.2. 코드 프로파일링. 자동 메모리 관리를 향한 속도
코드 프로파일링은 모든 기능의 시간 소비를 측정하는 특수 기술입니다. MetaEditor에서 ![]() 를 클릭하여 MQL5 프로그램을 실행하기만 하면 됩니다.
를 클릭하여 MQL5 프로그램을 실행하기만 하면 됩니다.
우리도 똑같이 하고 프로파일링을 위해 스크립트를 보낼 것입니다. 잠시 후 스크립트가 수행되고 스크립트 작업 중에 수행된 모든 메소드의 시간 프로필을 얻습니다. 아래 스크린샷은 AddObject()(시간의 40%), GetObjectByKey()(시간의 7%) 및 DeleteObjectByKey()(시간의 53%)의 세 가지 방법을 수행하는 데 대부분의 시간이 소요되었음을 보여줍니다.
 함수의 코드 프로파일링")
그림 9. OnStart() 함수의 코드 프로파일링
그리고 DeleteObjectByKey() 호출의 60% 이상이 Compress() 메소드를 호출하는 데 사용되었습니다.
그러나 이 메소드는 거의 비어 있으며 Resize() 메소드를 호출하는 데 주요 시간이 소요됩니다.
여기에는 다음이 포함됩니다.
CDictionary::Compress(void) { double koeff = m_array_size/(double)(m_total+1); if(koeff < 2.0 || m_total <= 4)return; Resize(); }-->
문제는 분명합니다. 모든 요소를 삭제할 때 Resize() 메소드가 때때로 실행됩니다. 이 방법은 스토리지를 동적으로 해제하는 배열 크기를 줄입니다.
요소를 더 빨리 삭제하려면 이 방법을 비활성화하십시오. 예를 들어 압축 플래그를 설정하는 특별한 AutoFreeMemory() 메소드를 클래스에 도입할 수 있습니다. 기본값으로 설정되며 이 경우 압축이 자동으로 수행됩니다. 그러나 추가 속도가 필요한 경우 잘 선택한 순간에 수동으로 압축을 수행합니다. 이를 위해 우리는 Compress() 메소드를 공개할 것입니다.
압축이 비활성화되면 요소가 3배 더 빨리 삭제됩니다.
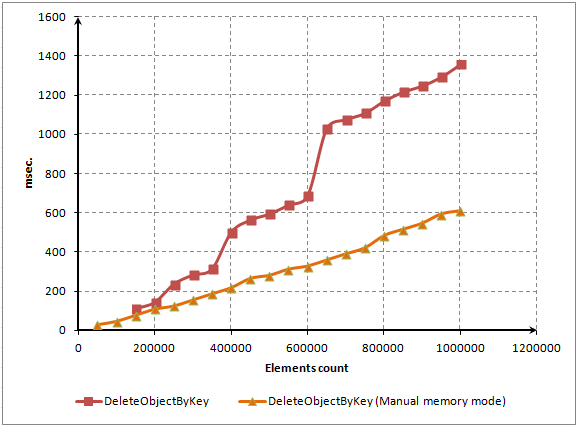
그림 10. 점유 스토리지를 사람이 모니터링하는 요소 삭제 시간(비교)
Resize() 메소드는 데이터 압축뿐만 아니라 요소가 너무 많고 더 큰 배열이 필요한 경우에도 호출됩니다. 이 경우 Resize() 메소드 호출을 피할 수 없습니다. 앞으로 길고 느린 CList 체인을 생성하지 않도록 호출해야 합니다. 그러나 사전에 필요한 양을 사전에 지정할 수 있습니다.
예를 들어, 추가된 요소의 수는 종종 사전에 알려져 있습니다. 요소의 수를 알면 사전은 필요한 크기의 배열을 미리 생성하므로 배열을 채우는 동안 추가 크기 조정이 필요하지 않습니다.
이를 위해 필수 요소를 허용하는 생성자를 하나 더 추가합니다.
//+------------------------------------------------------------------+ //| Creates a dictionary with predefined capacity | //+------------------------------------------------------------------+ CDictionary::CDictionary(int capacity) { m_auto_free = true; Init(capacity); }-->
private Init() 메소드는 주요 작업을 수행합니다.
//+------------------------------------------------------------------+ //| Initializes the dictionary | //+------------------------------------------------------------------+ void CDictionary::Init(int capacity) { m_free_mode=true; int n=FindNextSimpleNumber(capacity); m_array_size=ArrayResize(m_array,n); m_index = 0; m_hash = 0; m_total=0; }-->
개선이 완료되었습니다. 이제 처음에 지정된 배열 크기로 AddObject() 메소드의 성능을 평가할 시간입니다. 이를 위해 스크립트의 OnStart() 함수의 첫 번째 두 문자열을 변경합니다.
void OnStart() { //--- CDictionary dict(END+1); dict.AutoFreeMemory(false); ... }-->
이 경우 END는 1,000,000개 요소에 해당하는 큰 숫자로 표시됩니다.
이러한 혁신은 AddObject() 메소드 성능을 크게 향상시켰습니다.

그림 11. 미리 설정된 배열 크기로 요소를 추가하는 시간
실제 프로그래밍 문제를 해결하려면 항상 메모리 공간과 성능 속도 사이에서 선택해야 합니다. 메모리를 해제하는 데 상당한 시간이 걸립니다. 하지만 이 경우 더 많은 메모리를 사용할 수 있습니다. 모든 것을 있는 그대로 유지하면 CPU 시간은 추가적인 복잡한 계산 문제에 소비되지 않지만 정상적인 시간에는 사용 가능한 메모리가 줄어듭니다. 컨테이너를 사용하여 객체 지향 프로그래밍을 통해 각 특정 문제에 대한 특정 실행 정책을 선택하는 유연한 방식으로 CPU 메모리와 CPU 시간 사이에 리소스를 할당할 수 있습니다.
대체로 CPU 성능은 메모리 용량보다 훨씬 나쁘게 확장됩니다. 그렇기 때문에 대부분의 경우 메모리 공간보다 실행 속도를 우선시합니다. 게다가, 사용자 수준의 메모리 제어는 일반적으로 작업의 유한 상태를 모르기 때문에 자동화된 제어보다 더 효율적입니다.
예를 들어 스크립트의 경우 DeleteObjectByKey() 메소드가 작업이 끝날 때까지 요소를 모두 삭제하기 때문에 열거가 끝나면 총 요소 수가 null이 될 것임을 미리 알고 있습니다. 이것이 배열을 자동으로 압축할 필요가 없는 이유입니다. Compress() 메소드를 호출하여 맨 마지막에 지우는 것으로 충분합니다.
이제 배열에서 요소를 추가 및 삭제하는 좋은 선형 메트릭이 있으면 총 요소 수에 따라 요소를 추가 및 삭제하는 평균 시간을 분석합니다.
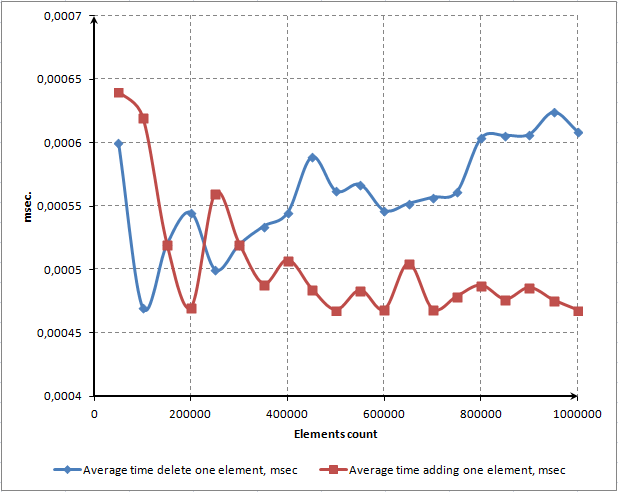
그림 12. 하나의 요소를 추가하고 삭제하는 평균 시간
하나의 요소를 추가하는 평균 시간은 매우 안정적이며 배열의 총 요소 수에 의존하지 않는다는 것을 알 수 있습니다. 하나의 요소를 삭제하는 평균 시간이 약간 위쪽으로 이동하여 바람직하지 않습니다. 그러나 오류율 내에서 결과를 처리하는지 또는 이것이 일반적인 경향인지 정확하게 말할 수는 없습니다.
4.3. 표준 CArrayObj와 비교한 CDictionary의 성능
가장 흥미로운 테스트 시간입니다. CDictionary를 표준 CArrayObj 클래스와 비교할 것입니다. CArrayObj에는 구성 단계에서 가정 크기 표시와 같은 수동 메모리 할당 메커니즘이 없으므로 CDictionary에서 수동 메모리 제어를 비활성화하고 AutoFreeMemory() 메커니즘을 활성화합니다.
각 클래스의 강점과 약점은 첫 번째 장에서 설명되었습니다. CDictionary를 사용하면 정의되지 않은 위치에 요소를 추가하고 사전에서 매우 빠르게 추출할 수 있습니다. 그러나 CArrayObj를 사용하면 모든 요소를 매우 빠르게 열거할 수 있습니다. CDictionary의 열거는 포인터에 의해 이동하여 수행되기 때문에 더 느릴 것이며 이 작업은 직접 인덱싱보다 느립니다.
자 이제 시작하겠습니다. 먼저 테스트의 새 버전을 만들어 보겠습니다.
//+------------------------------------------------------------------+ //| TestSpeed.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Dictionary.mqh> #include <Arrays\ArrayObj.mqh> #define TEST_ARRAY #define BEGIN 50000 #define STEP 50000 #define END 1000000 //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CDictionary dict(END+1); dict.AutoFreeMemory(false); CArrayObj objects; for(int j=BEGIN; j<=END; j+=STEP) { //---------- ADD --------------// uint tiks_begin=GetTickCount(); for(int i=0; i<j; i++) { #ifndef TEST_ARRAY dict.AddObject(i,new CObject()); #else objects.Add(new CObject()); #endif } uint tiks_add=GetTickCount()-tiks_begin; //---------- GET --------------// tiks_begin=GetTickCount(); CObject *value=NULL; for(int i= 0; i<j; i++) { #ifndef TEST_ARRAY value = dict.GetObjectByKey(i); #else ulong hash = rand()*rand()*rand()*rand(); value = objects.At((int)(hash%objects.Total())); #endif } uint tiks_get=GetTickCount()-tiks_begin; //---------- FOR --------------// tiks_begin = GetTickCount(); #ifndef TEST_ARRAY for(CObject* node = dict.GetFirstElement(); node != NULL; node = dict.GetNextNode()); #else int total = objects.Total(); CObject* node = NULL; for(int i = 0; i < total; i++) node = objects.At(i); #endif uint tiks_for = GetTickCount() - tiks_begin; //---------- DEL --------------// tiks_begin = GetTickCount(); for(int i= 0; i<j; i++) { #ifndef TEST_ARRAY dict.DeleteObjectByKey(i); #else objects.Delete(objects.Total()-1); #endif } uint tiks_del = GetTickCount() - tiks_begin; //---------- SUMMARY --------------// printf((string)j+" elements. Add: "+(string)tiks_add+"; Get: "+(string)tiks_get + "; Del: "+(string)tiks_del + "; for: " + (string)tiks_for); #ifndef TEST_ARRAY dict.Clear(); #else objects.Clear(); #endif } }-->
TEST_ARRAY 매크로를 사용합니다. 식별되면 테스트는 CArrayObj에서 작업을 수행하고, 그렇지 않으면 CDictionary에서 작업을 수행합니다. 새로운 요소를 추가하기 위한 첫 번째 테스트는 CDictionary가 이겼습니다.
이 특별한 경우에 메모리 재할당 방식이 더 나은 것으로 보입니다.
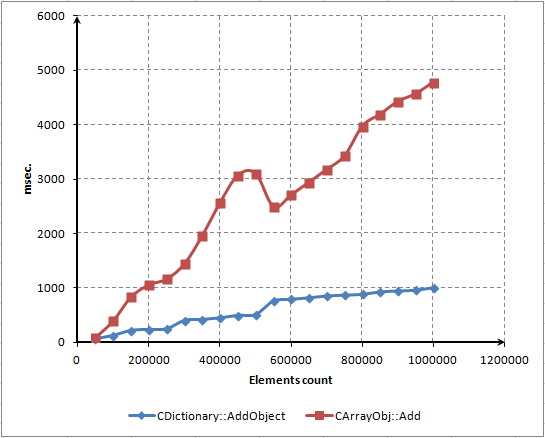
그림 13. CArrayObj 및 CDictionary에 새 요소를 추가하는 데 소요된 시간(비교)
느린 작업이 CArrayObj의 특정 메모리 재할당 방식으로 인해 발생했음을 강조하는 것이 중요합니다.
소스 코드의 단 하나의 문자열로 설명됩니다.
new_size=m_data_max+m_step_resize*(1+(size-Available())/m_step_resize);--> 이것은 메모리 할당의 선형 알고리즘입니다. 16개의 요소를 채운 후 기본적으로 호출됩니다. CDictionary는 지수 알고리즘을 사용합니다. 모든 다음 메모리 재할당은 이전 호출보다 두 배 많은 메모리를 할당합니다. 이 다이어그램은 성능과 사용된 메모리 사이의 딜레마를 완벽하게 보여줍니다. CArrayObj 클래스의 Reserve() 메소드는 더 경제적이고 더 적은 메모리를 필요로 하지만 더 느리게 작동합니다. CDictionary 클래스의 Resize() 메소드는 더 빠르게 작동하지만 더 많은 메모리가 필요하며 이 메모리의 절반은 전혀 사용되지 않을 수 있습니다.
마지막 테스트를 해보자. CArrayObj 및 CDictionary 컨테이너의 전체 열거에 대한 시간을 계산합니다. CArrayObj는 직접 인덱싱을 사용하고 CDictionary는 참조를 사용합니다. CArrayObj는 인덱스로 모든 요소를 참조할 수 있지만 CDictionary에서는 인덱스로 모든 요소를 참조하는 것이 방해를 받습니다. 순차 열거형은 직접 인덱싱과 경쟁이 매우 치열합니다.
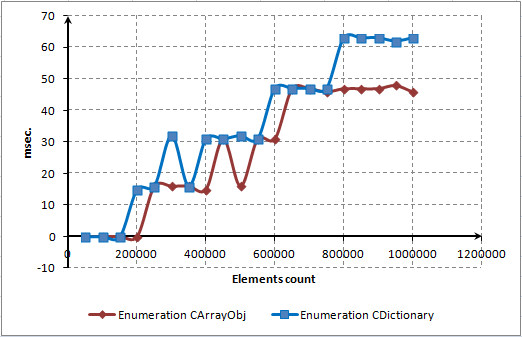
그림 14. CArrayObj 및 CDictionary의 완전한 열거를 위한 시간
MQL5 언어 개발자는 훌륭한 일을 했고 참조를 최적화했습니다. 다이어그램에 나와 있는 직접 인덱싱을 통해 속도 면에서 경쟁이 치열합니다.
요소 열거는 GetTickCount() 함수의 해결 직전에 있을 정도로 짧은 시간이 걸린다는 점을 인식하는 것이 중요합니다. 15밀리초 미만의 시간 간격을 측정하는 데 사용하기 어렵습니다.
4.4. CArrayObj, CList 및 CDictionary를 사용할 때의 일반 권장 사항
프로그래밍에서 발생할 수 있는 주요 작업과 이러한 작업을 해결하기 위해 알아야 하는 컨테이너의 기능을 설명하는 표를 만들 것입니다.
작업 성과가 좋은 기능은 녹색으로, 작업을 효율적으로 완료할 수 없는 기능은 빨간색으로 표시합니다.
| 목적 | CArrayObj | CList | CDictionary |
|---|---|---|---|
| 컨테이너 끝에 새 요소를 순차적으로 추가합니다. | 컨테이너는 새 요소에 대해 새 메모리를 할당해야 합니다. 기존 요소를 새 인덱스로 전송할 필요가 없습니다. CArrayObj는 이 작업을 매우 빠르게 수행합니다. | 컨테이너는 첫 번째, 현재 및 마지막 요소를 기억합니다. 이 사실 때문에 새로운 요소가 목록의 끝에(마지막으로 기억된 요소) 매우 빠르게 첨부됩니다. | 사전에는 "끝" 또는 "시작"과 같은 개념이 없습니다. 새로운 요소는 매우 빠르게 부착되며 요소의 수에 의존하지 않습니다. |
| 인덱스로 임의의 요소에 액세스합니다. | 직접 인덱싱으로 인해 액세스가 매우 빠르게 획득되고 O(1)의 시간이 걸립니다. | 각 요소에 대한 액세스는 모든 이전 요소의 열거를 통해 얻습니다. 이 작업은 O(n)의 시간이 걸립니다. | 각 요소에 대한 액세스는 모든 이전 요소의 열거를 통해 얻습니다. 이 작업은 O(n)의 시간이 걸립니다. |
| 키로 임의의 요소에 액세스합니다. | 사용할 수 없습니다 | 사용할 수 없습니다 | 키로 해시와 인덱스를 파악하는 것은 효율적이고 빠른 작업입니다. 해싱 함수 효율성은 문자열 키에 매우 중요합니다. 이 작업은 O(1)의 시간이 걸립니다. |
| 정의되지 않은 인덱스에 의해 새 요소가 추가/삭제됩니다. | CArrayObj는 새 요소에 대한 메모리를 할당할 뿐만 아니라 삽입된 요소의 인덱스보다 높은 인덱스의 모든 요소를 제거합니다. 이것이 CArrayObj가 느린 작업인 이유입니다. | 요소는 CList에서 매우 빠르게 추가 또는 삭제되지만 O(n)에 필요한 인덱스에 액세스할 수 있습니다. 이것은 느린 작업입니다. | CDictionary에서 인덱스에 의한 요소 접근은 CList 목록을 기반으로 수행되며 많은 시간이 걸립니다. 그러나 추가 및 삭제는 매우 빠르게 수행됩니다. |
| 정의되지 않은 키로 새 요소를 추가/삭제합니다. | 사용할 수 없습니다 | 사용할 수 없습니다 | 모든 새 요소가 CList에 삽입됨에 따라 각 추가/삭제 후에 배열의 크기를 조정할 필요가 없기 때문에 새 요소가 매우 빠르게 추가 및 삭제됩니다. |
| 사용량 및 메모리 관리. | 동적 배열 크기 조정이 필요합니다. 이것은 리소스 집약적인 작업으로 많은 시간 또는 많은 메모리가 필요합니다. | 메모리 관리는 사용되지 않습니다. 각 요소는 적절한 양의 메모리를 사용합니다. | 동적 배열 크기 조정이 필요합니다. 이것은 리소스 집약적인 작업으로 많은 시간 또는 많은 메모리가 필요합니다. |
| 요소의 열거. 벡터의 각 요소에 대해 수행해야 하는 작업입니다. | 직접 요소 인덱싱으로 인해 매우 빠르게 수행됩니다. 그러나 경우에 따라 열거를 역순으로 수행해야 합니다(예: 마지막 요소를 순차적으로 삭제할 때). | 모든 요소를 한 번만 열거해야 하므로 직접 참조는 빠른 작업입니다. | 모든 요소를 한 번만 열거해야 하므로 직접 참조는 빠른 작업입니다. |
5장. CDDictionary 클래스 문서
5.1. 요소를 추가, 삭제 및 액세스하는 주요 방법
5.1.1. AddObject() 메소드
T 키를 사용하여 CObject 유형의 새 요소를 추가합니다. 모든 기본 유형을 키로 사용할 수 있습니다.
template<typename T> bool AddObject(T key,CObject *value);-->
매개변수
- [in] key – 기본 유형(string, ulong, char, enum 등) 중 하나로 표시되는 고유 키입니다.
- [in] 값 - CObject를 기본 유형으로 사용하는 개체입니다.
반환된 값
개체가 컨테이너에 추가되었으면 true를 반환하고 그렇지 않으면 false를 반환합니다. 추가된 개체의 키가 이미 컨테이너에 있는 경우 메소드는 음수 값을 반환하고 개체는 추가되지 않습니다.
5.1.2. ContainsKey() 메소드
컨테이너에 T Key와 동일한 키를 가진 개체가 있는지 확인합니다. 모든 기본 유형을 키로 사용할 수 있습니다.
template<typename T> bool ContainsKey(T key);-->
매개변수
- [in] key – 기본 유형(string, ulong, char, enum 등) 중 하나로 표시되는 고유 키입니다.
체크된 키가 있는 객체가 컨테이너에 존재하는 경우 true를 반환합니다. 그렇지 않으면 false를 반환합니다.
5.1.3. DeleteObjectByKey() 메소드
미리 설정된 T Key로 개체를 삭제합니다. 모든 기본 유형을 키로 사용할 수 있습니다.
template<typename T> bool DeleteObjectByKey(T key);-->
매개변수
- [in] key – 기본 유형(string, ulong, char, enum 등) 중 하나로 표시되는 고유 키입니다.
반환된 값
프리셋 키가 있는 객체가 삭제된 경우 true를 반환합니다. 프리셋 키가 있는 객체가 존재하지 않거나 삭제에 실패한 경우 false를 반환합니다.
5.1.4. GetObjectByKey() 메소드
미리 설정된 T 키에 의해 개체를 반환합니다. 모든 기본 유형을 키로 사용할 수 있습니다.
template<typename T> CObject* GetObjectByKey(T key);-->
매개변수
- [in] key – 기본 유형(string, ulong, char, enum 등) 중 하나로 표시되는 고유 키입니다.
반환된 값
프리셋 키에 해당하는 객체를 반환합니다. 사전 설정 키를 가진 개체가 존재하지 않는 경우 NULL을 반환합니다.
5.2. 메모리 관리 방법
5.2.1. CDictionary() 생성자
기본 생성자는 기본 배열의 초기 크기가 3개 요소와 같은 CDictionary 개체를 만듭니다.
배열은 사전을 채우거나 요소를 삭제할 때 자동으로 증가하거나 압축됩니다.
CDictionary();-->
5.2.2. CDictionary(int 용량) 생성자
생성자는 기본 배열의 초기 크기가 '용량'인 CDictionary 개체를 만듭니다.
배열은 사전을 채우거나 요소를 삭제할 때 자동으로 증가하거나 압축됩니다.
CDictionary(int capacity);-->
매개변수
- [in] 용량 – 초기 요소의 수입니다.
메모
초기화 직후 배열 크기 제한을 설정하면 Resize() 메소드 호출을 방지하고 새 요소를 삽입할 때 효율성을 높이는 데 도움이 됩니다.
단, 활성화(AutoMemoryFree(true))한 상태에서 요소를 삭제하면 용량 설정에도 불구하고 컨테이너가 자동으로 압축된다는 점에 유의해야 합니다. 조기 압축을 방지하려면 컨테이너가 완전히 채워진 후 객체 삭제의 첫 번째 작업을 수행하거나 수행할 수 없는 경우 비활성화(AutoMemoryFree(false))합니다.
5.2.3. FreeMode(bool mode) 메소드
컨테이너에 존재하는 객체를 삭제하는 모드를 설정합니다.
삭제 모드가 활성화된 경우 개체가 삭제된 후 컨테이너도 '삭제' 절차를 따릅니다. 소멸자가 활성화되고 사용할 수 없게 됩니다. 삭제 모드가 비활성화되면 개체의 소멸자가 활성화되지 않고 프로그램의 다른 지점에서 계속 사용할 수 있습니다.
void FreeMode(bool free_mode);-->
매개변수
- [in] free_mode – 객체 삭제 모드 표시기.
5.2.4. FreeMode() 메소드
컨테이너에 있는 개체 삭제 표시기를 반환합니다(FreeMode(bool mode) 참조)
bool FreeMode(void);-->
반환된 값
개체가 컨테이너에서 삭제된 후 delete 연산자에 의해 삭제되면 true를 반환합니다. 그렇지 않으면 false를 반환합니다.
5.2.5. AutoFreeMemory(bool autoFree) 메소드
자동 메모리 관리 표시기를 설정합니다. 자동 메모리 관리는 기본적으로 활성화되어 있습니다. 이러한 경우 배열은 자동으로 압축됩니다(큰 크기에서 작은 크기로 크기 조정). 비활성화된 경우 배열이 압축되지 않습니다. 리소스를 많이 사용하는 Resize() 메소드를 호출할 필요가 없으므로 프로그램 실행 속도가 크게 향상됩니다. 그러나 이 경우 배열 크기를 확인하고 Compress() 메소드를 사용하여 수동으로 압축해야 합니다.
void AutoFreeMemory(bool auto_free);-->
매개변수
- [in] auto_free – 메모리 관리 모드 표시기.
반환된 값
메모리 관리를 활성화하고 Compress() 메소드를 자동으로 호출해야 하는 경우 true를 반환합니다. 그렇지 않으면 false를 반환합니다.
5.2.6. AutoFreeMemory() 메소드
자동 메모리 관리 모드가 사용되는지 여부를 지정하는 표시기를 반환합니다(FreeMode(bool free_mode) 메소드 참조).
bool AutoFreeMemory(void);-->
반환된 값
메모리 관리 모드를 사용하는 경우 true를 반환합니다. 그렇지 않으면 false를 반환합니다.
5.2.7. Compress() 메소드
사전을 압축하고 요소의 크기를 조정합니다. 배열은 가능한 경우에만 압축됩니다.
이 메소드는 자동 메모리 관리 모드가 비활성화된 경우에만 호출해야 합니다.
void Compress(void);-->
5.2.8. Clear() 메소드
사전의 모든 요소를 삭제합니다. 메모리 관리 표시기가 활성화되면 삭제되는 각 요소에 대해 소멸자가 호출됩니다.
void Clear(void);-->
5.3. 사전 검색 방법
모든 사전의 요소는 서로 연결되어 있습니다. 각각의 새로운 요소는 이전 요소와 연결됩니다. 따라서 사전의 모든 요소에 대한 순차 검색이 가능합니다. 이러한 경우 참조는 연결 목록에 의해 수행됩니다. 이 섹션의 방법은 검색을 용이하게 하고 사전 반복을 더 편리하게 만듭니다.
사전을 검색하는 동안 다음 구성을 사용할 수 있습니다.
for(CObject* node = dict.GetFirstNode(); node != NULL; node = dict.GetNextNode()) { // node means the current element of the dictionary. }-->
5.3.1. GetFirstNode() 메소드
사전에 추가된 맨 처음 요소를 반환합니다.
CObject* GetFirstNode(void);--> 반환된 값
주로 사전에 추가된 CObject 유형 개체에 대한 포인터를 반환합니다.
5.3.2. GetLastNode() 메소드
사전의 마지막 요소를 반환합니다.
CObject* GetLastNode(void);--> 반환된 값
맨 끝에 사전에 추가된 CObject 유형 개체에 대한 포인터를 반환합니다.
5.3.3. GetCurrentNode() 메소드
현재 선택된 요소를 반환합니다. 요소는 사전을 통해 요소를 검색하는 방법 중 하나 또는 사전의 요소에 대한 액세스 방법(ContainsKey(), GetObjectByKey()) 중 하나를 사용하여 미리 선택해야 합니다.
CObject* GetLastNode(void);--> 반환된 값
맨 끝에 사전에 추가된 CObject 유형 개체에 대한 포인터를 반환합니다.
5.3.4. GetNextNode() 메소드
현재 요소 다음에 오는 요소를 반환합니다. 현재 요소가 마지막 요소이거나 선택되지 않은 경우 NULL을 반환합니다.
CObject* GetLastNode(void);--> 반환된 값
현재 개체 다음에 오는 CObject 유형 개체에 대한 포인터를 반환합니다. 현재 요소가 마지막 요소이거나 선택되지 않은 경우 NULL을 반환합니다.
5.3.5. GetPrevNode() 메소드
현재 요소보다 이전 요소를 반환합니다. 현재 요소가 첫 번째 요소이거나 선택되지 않은 경우 NULL을 반환합니다.
CObject* GetPrevNode(void);--> 반환된 값
현재 개체보다 이전에 있는 CObject 유형 개체에 대한 포인터를 반환합니다. 현재 요소가 첫 번째 요소이거나 선택되지 않은 경우 NULL을 반환합니다.
결론
우리는 널리 보급된 데이터 컨테이너의 주요 기능을 고려했습니다. 각 데이터 컨테이너는 해당 기능이 가장 효율적인 방식으로 문제를 해결할 수 있는 곳에서 사용해야 합니다.
요소에 대한 순차 액세스가 문제를 해결하기에 충분한 경우 일반 배열을 사용해야 합니다. 고유 키로 요소에 액세스해야 하는 경우 사전 및 관련 배열을 사용하는 것이 좋습니다. 삭제, 삽입, 새 요소 추가와 같이 자주 요소를 교체하는 경우 목록을 사용하는 것이 좋습니다.
사전을 사용하면 훌륭하고 간단한 방식으로 어려운 알고리즘 문제를 해결할 수 있습니다. 다른 데이터 컨테이너에 추가 처리 기능이 필요한 경우 사전을 통해 가장 효과적인 방법으로 기존 요소에 대한 액세스를 정렬할 수 있습니다. 예를 들어 사전을 기반으로 OnChartEvent() 유형의 각 이벤트가 하나 또는 다른 그래픽 요소를 관리하는 클래스에 전달되는 이벤트 모델을 만들 수 있습니다. 이를 위해 모든 클래스 인스턴스를 이 클래스에서 관리하는 개체의 이름과 연결하기만 하면 됩니다.
사전은 보편적인 알고리즘이므로 가장 다양한 분야에 적용할 수 있습니다. 이 글은 그 작업이 애플리케이션을 편리하고 효과적으로 만드는 매우 간단하지만 강력한 알고리즘을 기반으로 한다는 것을 분명히 합니다.
MetaQuotes 소프트웨어 사를 통해 러시아어가 번역됨.
원본 기고글: https://www.mql5.com/ru/articles/1334
 CCanvas 클래스 공부하기. 투명 개체를 그리는 방법
CCanvas 클래스 공부하기. 투명 개체를 그리는 방법
 HedgeTerminal API를 사용한 MetaTrader 5의 양방향 거래 및 포지션 헤지, 파트 2
HedgeTerminal API를 사용한 MetaTrader 5의 양방향 거래 및 포지션 헤지, 파트 2
 Expert Advisor 매개변수 선택을 위한 테스트(최적화) 기술 및 일부 기준
Expert Advisor 매개변수 선택을 위한 테스트(최적화) 기술 및 일부 기준
 HedgeTerminal 패널을 이용하여 MetaTrader 5로 양방향 매매와 포지션 헤징하기, 파트 1
HedgeTerminal 패널을 이용하여 MetaTrader 5로 양방향 매매와 포지션 헤징하기, 파트 1