
MQL5 クックブック: 連想配列またはクイック データアクセスのための辞書の実装

目次
- 第1章データ構成論
- 1.1. データ構成アルゴリズム最良のデータストレージコンテナの検索
- 1.2. 配列およびデータの直接アドレッシング
- 1.3. CObjectCustom シンプルクラス例によるノード コンセプト
- 1.4. CArrayCustom クラス例によるノードポインター配列
- 1.5. 確認とタイプの安全性
- 1.6. 二重リンクリスト例としての CList クラス
- 第2章連想配列構成論
- 2.1. 日常生活における連想配列
- 2.2. スイッチケースオペレータまたはシンプル配列を基にした主な連想配列
- 2.3. ベースタイプからユニークキーへの変換
- 2.4. 文字列のハッシュおよびキーとしてのハッシュ使用
- 2.5. キーによるインデックスの表現リスト配列
- 第3章連想配列の実用的作成
- 3.1. CDictionary クラス、メソッド AddObject() および DeleteObjectByKey()、KeyValuePair コンテナのテンプレート
- 3.2. typename を基にしたruntime タイプの特定;ハッシュ サンプリング
- 3.3. ContainsKey() メソッドハッシュ コリジョンへの対処
- 3.4. メモリの動的割り当てと割り当て解除
- 3.5. ストロークの終了:オブジェクト検索と便利なインデクサ
- 第4章 パフォーマンスの検証と評価
- 4.1. 検証のコード作成とパフォーマンス評価
- 4.2. コードプロファイル自動メモリ管理に向けたスピード
- 4.3. CDictionary のパフォーマンスと標準的な CArrayObj との比較
- 4.4. CArrayObj、CList、 CDictionary 使用に際する一般的推奨事項
- 第5章 辞書クラスのドキュメンテーション
- 5.1. エレメントへの追加、削除、アクセスの主要メソッド
- 5.1.1. AddObject() メソッド
- 5.1.2. ContainsKey() メソッド
- 5.1.3. DeleteObjectByKey() メソッド
- 5.1.4. GetObjectByKey() メソッド
- 5.2. メモリ管理メソッド
- 5.2.1. CDictionary() メソッド
- 5.2.2. CDictionary(int capacity) メソッド
- 5.2.3. FreeMode() メソッド
- 5.2.4. FreeMode(bool mode) メソッド
- 5.2.5. AutoFreeMemory(bool auto) メソッド
- 5.2.6. AutoFreeMemory() メソッド
- 5.2.7. Compress() メソッド
- 5.2.8. Clear() メソッド
- 5.3. 辞書を検索するメソッド
- 5.3.1. GetFirstNode() メソッド
- 5.3.2. GetLastNode() メソッド
- 5.3.3. GetCurrentNode() メソッド
- 5.3.4. GetNextNode() メソッド
- 5.3.5. GetPrevNode() メソッド
- 5.1. エレメントへの追加、削除、アクセスの主要メソッド
- おわりに
はじめに
本稿は情報を便利に格納するためのクラスについて説明します。すなわち連想配列または辞書です。このクラスによりキーによってエレメントへのアクセスが可能となります。
連想配列は通常の配列に似ています。ただインデックスの代わりに連想配列はいくつか独自のキーを使用します。たとえば列挙 ENUM_TIMEFRAMES やテキストなどです。キーが何を表すかは問題ではありません。重要なのはキーのユニークさです。このデータ格納アルゴリズムは多くのプログラミング側面を大幅にシンプル化します。
たとえば、エラーコードを取りエラーに相当するテキストを出力する関数は以下のようなものとなるでしょう。
//+------------------------------------------------------------------+ //| Displays the error description in the terminal. | //| Displays "Unknown error" if error id is unknown | //+------------------------------------------------------------------+ void PrintError(int error) { Dictionary dict; CStringNode* node = dict.GetObjectByKey(error); if(node != NULL) printf(node.Value()); else printf("Unknown error"); }
あとでこのコードの特別な機能について詳しくみていきます。
連想配列の内部ロジックを直接説明する前に、データ格納の主要な2とおりの方法を考察しようと思います。すなわち配列とリストです。われわれの辞書はこの2とおりのデータタイプを基にしています。それがそれらの特定の機能をよく理解しなければならない理由です。第1章はデータタイプについて説明します。第2章では連想配列とそれと連携するメソッドについて説明します。
第1章 データ構成論
1.1. データ構成アルゴリズム最良のデータストレージコンテナの検索
情報の検索、格納、表示が現代のコンピュータに課せられる主な機能です。人間とコンピュータの相互作用は通常なんらかの情報検索、または将来利用する情報の作成および格納を行うものです。情報は抽象概念ではありません。本当の意味でこの言葉には特定の概念が存在します。たとえばあるシンボル引用履歴は、このシンボルについてディールを行っている、またはこれから行おうとしているトレーダーにtっては誰もに対する情報源です。プログラム言語ドキュメンテーションまたはプログラムのソースコードはプログラマーにとっての情報源としての役割を果たすのです。
グラフィックファイル(たとえばデジカメで撮った写真)はプログラミングやトレーディングに関係ない人々にとっては情報源です。こういった情報タイプは異なるストラクチャと独自の性質を持つことは明らかです。その結果、この情報の格納、表現、処理のアルゴリズムは異なるはずです。
たとえば、グラフィックファイルを、各エレメントまたはセルが小さな画像エリア- ピクセル、の色に関する情報を格納する二次元行列(二次元配列)として提示するのが簡単です。引用データには別の性質があります。基本的にこれは OHLCV 形式の均質なデータのストリームです。配列または複数のデータタイプを結合したプログラム言語によるデータの特定タイプ整列したストラクチャのシーケンスとしてこのストリームを提示する方が良いでしょう。ドキュメンテーションあるいはソースコードは通常プレーンテキストとして表現されます。このデータタイプは整列した文字列のシーケンスとして定義され格納されます。そこでは各文字列はシンボルの任意のシーケンスです。
データを格納するコンテナタイプはデータタイプに依存します。オブジェクト指向プログラミングという語を用いると、コンテナをデータを格納しそのデータを操作する特殊なアルゴリズム(方法)を持つ、ある クラスとして定義するのがより簡単です。そのようなデータ格納コンテナ(クラス)には複数タイプがあります。それらは異なるデータ構成を基にしています。ただしデータ構成アルゴリズムの中には異なるデータ格納パラダイムを組合せられるようにするものもあります。よってすべての格納タイプのリットを組み合わせを活用することができます。
データ操作の想定方法とデータの性質に応じてデータを格納、処理、受け取る一つまたは別のコンテナを選択します。同じように効率的なデータコンテナはひとつもないことを理解することが重要です。あるデータコンテナの弱点はその裏側では利点となります。
たとえば、任意の配列エレメントに迅速にアクセスできます。ですが、ランダムな配列スポットにエレメントを追加するのには時間のかかる処理が必要です。そのような場合には 配列サイズ全体が必要とされるためです。逆に、一重リンクリストへのエレメント追加は効率的で高速な処理ですが、ランダムなエレメントにアクセスすることには時間がかかります。頻繁に新規エレメントを挿入する必要があり、これらエレメントには頻繁にアクセスする必要がなければ、一重リンクリストが適切なコンテナということになります。そしてランダムなエレメントに頻繁にアクセスする必要があれば、データクラスとしての配列を選択します。
どのデータ格納タイプが好ましいか理解するためには、既存のコンテナの仕組みに精通する必要があります。本稿は連想配列または辞書-配列とリストの組合せを基にした特定のデータ格納コンテナ、についてお話します。ですが、辞書は特定のプログラム言語:能力および許容されるプログラムルール、に応じて異なる方法で実装することが可能であることをお伝えしておきたいと思います。
たとえば、C# 辞書の実装は C++とは異なります。本稿は С++ 用辞書の適応実装は説明しません。説明している連想配列バージョンは MQL5 プログラム言語のために一から作成されたもので、その特殊な機能と一般的プログラム実践に配慮しているものです。実装はことなりますが、辞書の一般的特性と処理方法は類似しています。このコンテキストでは説明されているバージョンはこれら促成と方法をすべて示しています。
徐々に辞書アルゴリズムを作成し、その間、データ格納アルゴリズムの性質についてお話していきます。本稿の終わりにはアルゴリズムの完成バージョンを手にし、処理原理を十分に理解していることでしょう。
異なるデータタイプに対して同じように効率的なデータコンテナはひとつもありません。シンプルな例を考察します。紙でできたノートです。それは日常生活で使用するコンテナ/クラスとも考えられます。メモはすべて事前に作成されたリスト(この場合はアルファベット)に従って書き込まれます。定期購買者名がわかっていれば、その人の電話番号を見つけるのはたやすいことです。ノートを開けばよいだけですから。
1.2. 配列およびデータの直接アドレッシング
配列はもっともシンプルで同時に情報格納にはもっとも効果的な方法です。プログラミングにおいて配列はメモリ内にすぐさま次々と入れられていく同じタイプのエレメントの集積です。そういった特性のため、配列エレメントそれぞれのアドレスを計算することができるのです。
確かにエレメントすべてが同じタイプであればすべて同じサイズを持つことになります。配列データは連続して配置されているため、ランダムなエレメントのアドレスを計算し、基本のエレメントサイズがわかっていれば、このエレメントを直接参照することができるのです。アドレスを計算する一般的な式はデータタイプとインデックスによります。
たとえば、配列データ構成のプロパティから出てくる次のような一般的な式を使う uchar タイプのエレメント配列内の5番目のエレメントのアドレスを計算することができます。
ランダムなエレメントアドレス = 1番目のエレメントアドレス + (配列内のランダムなエレメントのインデックス×配列タイプサイズ)
配列のアドレッシングはゼロから始まります。1番目のエレメントのアドレスがインデックス 0 の配列エレメントのアドレスに対応するのはそのためです。その結果、5番目のエレメントはインデックス4となります。uchar タイプエレメントを格納する配列を仮定します。これは多くのプログラム言語における基本のデータタイプです。たとえば、C タイプ言語すべてに存在します。MQL5 も例外ではありません。uchar タイプ配列の各エレメントは1バイトまたは8バイトのメモリを占めます。
たとえば前にお話しした式に従い5番目のエレメントのアドレスは uchar 配列では次のようになります。
5番目のエレメントアドレス = 1番目のエレメントのアドレス + (4 × 1 バイト)。
すなわち、uchar 配列の5番目のエレメントは1番目のエレメントよりも4バイト分高くなるのです。プログラム実行中、アドレスから各配列エレメントを直接参照することが可能です。そのようなアドレス算術により各配列エレメントへひじょうに速くアクセスできるようになります。ただそのようなデータ構成にはデメリットもあります。
その一つは配列内に異なるタイプのエレメントを格納することができないことです。そのような制限は直接アドレッシングのために生じるものです。異なるデータタイプでは確実にサイズも異なります。それは前述の式を使って特定のエレメントのアドレスを計算することはできないということです。ただし、配列がエレメントではなくエレメントに対するポインターを格納するのであれば、この制限はスマートに克服することができます。
ポインターをリンクとして表せばそれが最も簡単な方法です(Windows のショートカットのように)。ポインターはメモリ内の特定のオブジェクトを参照しますが、それ自体はオブジェクトではありません。MQL5 ではポインターが参照できるのはクラスのみです。オブジェクト指向プログラミングではクラスは 任意のデータセットやメソッドをインクルードすることのできる特殊なデータタイプで、効果的なプログラム構成のためにユーザーによって作成されるものです。
クラスはそれぞれ独自のユーザー定義データタイプです。異なるクラスを参照するポインターは1つの配列に入れることはできません。ただし参照されるクラスにかかわらず、ポインターは常に同一サイズです。それは、割り当てられるオブジェクトすべてに共通のオペレートシステムアドレススペース内では、ポインターはオブジェクトアドレスを1つしか持たないためです
1.3. CObjectCustom シンプルクラス例によるノード コンセプト
これで最初の汎用ポインターを作成については十分な知識を得ました。考え方は、各ポインターが特別なタイプを参照する汎用的なポインター配列を作成する、ということです。実タイプは異なりますが、それらが同じポインターによって参照されることでこういったタイプは1つのコンテナ/配列に格納されるのでしょう。それではわれわれのポインターの初回バージョンを作成します。
このポインターは、CObjectCustomと名づけるもっともシンプルなタイプで表現されます。
class CObjectCustom
{
};
CObjectCustom よりもシンプルなクラスを作り出すことはひじょうに難しいはずです。なぜならこのクラスはデータもメソッドも持たないからです。等分の間そのような実装で十分です。
ここでオブジェクト指向プログラミングの主要コンセプトの一つを利用します。継承です。継承によりオブジェクト間のアイデンティティを確立する特殊な方法がもたらされます。たとえば、コンパイラに任意のクラスが CObjectCustom の派生クラスであると告げることができます。
たとえば、人間のあるクラス(СHuman)、Expert Advisors のあるクラス(CExpert)、天気のあるクラス(CWeather)が CObjectCustom クラスのより一般的なコンセプトを表します。たぶん、これらコンセプトは実際には実生活で関連はしていません。天気は人と共通点がなく、Expert Advisors は天気に関連がありません。しかしプログラム世界でリンクを設定するのはわれわれで、これらリンクがわれわれのアルゴリズムに適しているなら、それらを作成しない理由はありません。
同じ要領でもういくつかクラスを作成します。クルマクラス(CCar)、番号クラス(CNumber)、価格バークラス(CBar)、引用クラス(CQuotes)、MetaQuotes 社クラス(CMetaQuotes)、船を説明するクラス(CShip)です。前のクラス同様、これらは実際には関連がありませんが。すべて CObjectCustom クラスの継承です。
これらオブジェクトについて、クラスをすべて1件のファイルにまとめてクラスライブラリを作成します。ファイルは ObjectsCustom.mqh です。
//+------------------------------------------------------------------+ //| ObjectsCustom.mqh | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" //+------------------------------------------------------------------+ //| Base Class CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing human beings. | //+------------------------------------------------------------------+ class CHuman : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing weather. | //+------------------------------------------------------------------+ class CWeather : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing Expert Advisors. | //+------------------------------------------------------------------+ class CExpert : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing cars. | //+------------------------------------------------------------------+ class CCar : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing numbers. | //+------------------------------------------------------------------+ class CNumber : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing price bars. | //+------------------------------------------------------------------+ class CBar : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing quotations. | //+------------------------------------------------------------------+ class CQuotes : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing the MetaQuotes company. | //+------------------------------------------------------------------+ class CMetaQuotes : public CObjectCustom { }; //+------------------------------------------------------------------+ //| Class describing ships. | //+------------------------------------------------------------------+ class CShip : public CObjectCustom { };
そして今度はクラスを1つの配列にまとめます。
1.4. CArrayCustom クラス例によるノードポインター配列
クラスをまとめるには特別な配列が必要となります。
一番シンプルな場合、それは以下を書くだけで十分です。
CObjectCustom array[];
この文字列は CObjectCustom タイプエレメントを格納する動的配列を作成します。前項で定義したクラスすべてが CObjectCustom から派生していることにより、これらクラスのどれもをこの配列に格納することができるのです。たとえば人、クルマ、船をそこに入れることができます。しかし CObjectCustom 配列の宣言はこのために十分ではありません。
問題は通常の方法で配列を宣言する場合、そのエレメントはすべて配列初期化時に自動で埋められます。そのため、配列宣言後、そのエレメントはすべて CObjectCustom クラスで占領されるのです。.
CObjectCustom をわずかばかり変更すると、このことを確認することができます。
//+------------------------------------------------------------------+ //| Base class CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { public: void CObjectCustom() { printf("Object #"+(string)(count++)+" - "+typename(this)); } private: static int count; }; static int CObjectCustom::count=0;
この特殊性を確認するために文字列として検証コードを実行します。
//+------------------------------------------------------------------+ //| Test.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2014, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom array[3]; }
OnStart() 関数では CObjectCustom の3つのエレメントで構成される配列を初期化しました。
コンパイラはこの配列を対応するオブジェクトで埋めました。ターミナルのログを読めばそれが確認できます。
2015.02.12 12:26:32.964 Test (USDCHF,H1) Object #2 - CObjectCustom
2015.02.12 12:26:32.964 Test (USDCHF,H1) Object #1 - CObjectCustom
2015.02.12 12:26:32.964 Test (USDCHF,H1) Object #0 - CObjectCustom
配列はコンパイラで埋められ、そこにはそれ以外のエレメント、たとえばCWeather や CExpert を入れることはできないということです。
このコードはコンパイルされません。
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom array[3]; CWeather weather; array[0] = weather; }
コンパイラはエラーメッセージを出します。
'=' - structure have objects and cannot be copied Test.mq5 18 13
それは配列がすでにオブジェクトを持ち、新しいオブジェクトはそこにコピーされないことを意味します。
しかしこの行き詰まりは打破することができます。上述のようにわれわれはオブジェクトではなくオブジェクトに対するポインターと連携するのです。
OnStart() 関数内のコードをポインターと連携する方法に書き直します。
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* array[3]; CWeather* weather = new CWeather(); array[0] = weather; }
これでコードはコンパイルされエラーは出ません。何が起こったのでしょうか?まず、CObjectCustom 配列の初期化を CObjectCustom に対するポインターの配列初期化と置き換えました。
この場合、コンパイラは配列を初期化するとき新しいCObjectCustom オブジェクトは作成せず、それは空のまま残しておきます。次に、オブジェクト自体の代わりに CWeather オブジェクトに対するポインターを使用しています。gキーワード 新規 を使い、CWeather オブジェクトを作成し、それをわれわれのポインター「天気」に割り当て、それからポインター「天気」(オブジェクトではない)を配列に入れたのです。
ここで同様にして残りのオブジェクトを配列に入れます。
そのために以下のコードを書きます。
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[8]; arrayObj[0] = new CHuman(); arrayObj[1] = new CWeather(); arrayObj[2] = new CExpert(); arrayObj[3] = new CCar(); arrayObj[4] = new CNumber(); arrayObj[5] = new CBar(); arrayObj[6] = new CMetaQuotes(); arrayObj[7] = new CShip(); }
このコードは役に立ちますが、配列のインデックスを直接操作するので高リスクです。
arrayObj 配列のサイズ計算を誤ったり、間違ったインデックスでアドレスを付けたら、プログラムは重大なエラーを持つこととなります。ただこのコードはここでのデモ目的には適しています。
これらエレメントをスキームとして提示します。
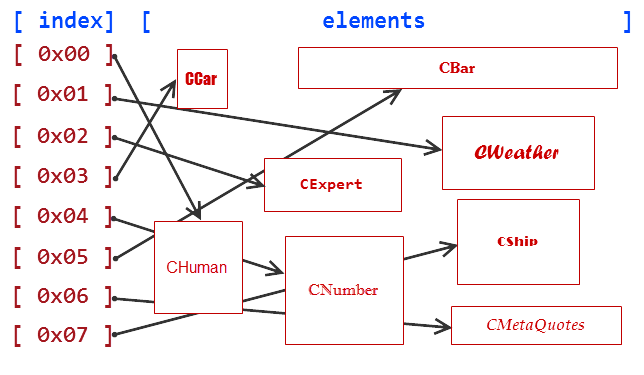
図1 ポインター配列内のデータ格納スキーム
オペレータ 'new' によって作成されるエレメントはヒープと呼ばれるRAMの特別な部分に格納されます。こういったエレメントは上記スキームであきらかにみられるように順序づけられていません。
われわれの arrayObj ポインター配列は厳格にインデックスが付けられています。それでそのインデックスを使用しているあらゆるエレメントに迅速にアクセスできるのです。ただそのようなエレメントに対するアクセスは十分ではありません。ポインター配列はそれが特定のオブジェクトを指すのか知らないからです。すべてが CObjectCustom であるため、CObjectCustom ポインターは CWeather または CBar、あるいは CMetaQuotes を指定します。, よってその実際のタイプに対するオブジェクトの明確な キャストはエレメントタイプを取得するのに必要です。
たとえば以下のように行うことができます。
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[8]; arrayObj[0] = new CHuman(); CObjectCustom * obj = arrayObj[0]; CHuman* human = obj; }
このコードでは CHuman オブジェクトを作成し、それを CObjectCustom としての arrayObj 配列に入れました。それから CObjectCustom を抽出し、それを CHuman に変換しました。それは実は同じものです。例では、タイプを覚えていたため変換にはエラーがありません。実際のプログラム状況では、何百というタイプがありオブジェクト数は100万件以上になるためオブジェクトそれぞれのタイプを追跡することは困難です。
実オブジェクトタイプのモディファイアを返す追加の Type() メソッドを持 ObjectCustom クラスを備えるのはそのためです。モディファイアは名前からタイプを参照することのできるオブジェクトを記述する特定のユニークな番号です。たとえば、事前処理命令 #define によりモディファイアを定義することができます。モディファイアによって指定されるオブジェクトタイプがわかれば、つねに安全にそのタイプを実タイプに変換することができるのです。これで 安全タイプの作成に近づきました。
1.5. 確認とタイプの安全性
あるタイプを別のタイプに変換しはじめるとすぐに、そのような変換の安全性がプログラミングの礎石となります。プログラムが重大なエラーをもつようなことにはなりたくないですよね?われわれのタイプにとって何が安全規準かすでにわかっています。それは特殊モディファイアです。モディファイアを理解していれば、それを必要なタイプに変換することができます。このためには CObjectCustom に複数の補足が必要です。
まず最初に名前でタイプが参照できるように識別子を作成します。このためには必要な列挙を持つファイルを別に作成します。
//+------------------------------------------------------------------+ //| Types.mqh | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #define TYPE_OBJECT 0 // General type CObjectCustom #define TYPE_HUMAN 1 // Class CHuman #define TYPE_WEATHER 2 // Class CWeather #define TYPE_EXPERT 3 // Class CExpert #define TYPE_CAR 4 // Class CCar #define TYPE_NUMBER 5 // Class CNumber #define TYPE_BAR 6 // Class CBar #define TYPE_MQ 7 // Class CMetaQuotes #define TYPE_SHIP 8 // Class CShip
これでオブジェクトタイプを番号として格納する変数にCObjectCustom を追加し、クラスコードを変更します。だれも変更できないように、それをプライベートなセクションに隠します。
その上 CObjectCustom から派生したクラスが利用できる特別なコンストラクタを追加します。このコンストラクタはオブジェクトが作成中自分のタイプを指定できるようにするものです。
以下が一般的なコードです。
//+------------------------------------------------------------------+ //| Base Class CObjectCustom | //+------------------------------------------------------------------+ class CObjectCustom { private: int m_type; protected: CObjectCustom(int type){m_type=type;} public: CObjectCustom(){m_type=TYPE_OBJECT;} int Type(){return m_type;} }; //+------------------------------------------------------------------+ //| Class describing human beings. | //+------------------------------------------------------------------+ class CHuman : public CObjectCustom { public: CHuman() : CObjectCustom(TYPE_HUMAN){;} void Run(void){printf("Human run...");} }; //+------------------------------------------------------------------+ //| Class describing weather. | //+------------------------------------------------------------------+ class CWeather : public CObjectCustom { public: CWeather() : CObjectCustom(TYPE_WEATHER){;} double Temp(void){return 32.0;} }; ...
見てのとおり、これで CObjectCustom から派生したタイプはすべて作成中にコンストラクタ内に自らのタイプを設定します。タイプは一度設定されると変更できません。格納されるフィールドがウpらいべーとで CObjectCustom に対してのみ利用されるためです。それで誤ったタイプ操作を防ぎます。クラスが保護されたコンストラクタCObjectCustom を呼ばなければ、そのタイプ- TYPE_OBJECT はデフォルトタイプです。
そこで、arrayObj からタイプを抽出しそれを処理する方法を学習する時間がきました。これには、それぞれにパブリックなメソッド Run() および Temp() を持つクラス CHuman と CWeather を備えます。arrayObj からクラスを抽出したのち、それを必要なタイプに変換し適切な方法でそれと連携します。
CObjectCustom 配列に格納されているタイプがわからない場合は、メッセージ『知らないタイプです』のメッセージを書いてそれを無視します。
#include "ObjectsCustom.mqh" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CObjectCustom* arrayObj[3]; arrayObj[0] = new CHuman(); arrayObj[1] = new CWeather(); arrayObj[2] = new CBar(); for(int i = 0; i < ArraySize(arrayObj); i++) { CObjectCustom* obj = arrayObj[i]; switch(obj.Type()) { case TYPE_HUMAN: { CHuman* human = obj; human.Run(); break; } case TYPE_WEATHER: { CWeather* weather = obj; printf(DoubleToString(weather.Temp(), 1)); break; } default: printf("unknown type."); } } }
このコードは次のメッセージを表示します。
2015.02.13 15:11:24.703 Test (USDCHF,H1) unknown type.
2015.02.13 15:11:24.703 Test (USDCHF,H1) 32.0
2015.02.13 15:11:24.703 Test (USDCHF,H1) Human run...
これで探していた結果を得ました。CObjectCustom 配列にどのようなタイプのオブジェクトも格納し、配列内でインデックスによりこれらオブジェクトにすばやくアクセスし、実タイプに正しく変換することができるのです。ですが、まだ多くのことが欠けています。:プログラム停止後オブジェクトを正しく削除する必要があります。これは削除オペレータによって自分でヒープにあるオブジェクトを削除しなければならないためです。
その上、配列が完全に埋められていれば安全配列サイズ変更の方法が必要です。しかしそれを一からすることはしません。標準的な MetaTrader 5 のツールセットにはこういった機能を実装するクラスが含まれています。
これらクラスは汎用的 CObject コンテナ/クラスを基にしています。同様にわれわれのクラスに対してもそれは Type() メソッドを持ちます。これはクラスの実タイプ CObject type: m_prev and m_next の重要なポインターをもう2個返します。その目的は、データ格納の別の方法、すなわち二重リンクリストについての次のセクションで、CObject コンテナと CList クラスの例を用いて説明します。
1.6. 二重リンクリスト例としての CList クラス
任意タイプのエレメントを持つ配列にはただ一つ大きな欠点があります。それは新しいエレメントを追加したい場合に時間と労力が撮られることです。特にこのエレメントを配列の真ん中に挿入する必要がある場合です。エレメントはシーケンス内にあるため挿入するためにはエレメントのトータル数を1増やすために配列サイズを変更して挿入されたオブジェクトに続くエレメントをすべて整列しなおしそのインデックスが新しい値に対応するようにする必要があります。
7エレメントで構成される配列があり、4番目のポジションにもう一つエレメントを追加したいとします。以下がおおよその挿入スキームです。

図2 配列のサイズ変更と新規エレメントの追加
エレメントを迅速に追加、また削除するデータ格納スキームがあります。そのようなスキームは一重リンクリストまたは二重リンクリストと呼ばれます。リストは日常の列を思い出させます。列に並んでいるとき、前にいる人を知れはいいだけです(そのさらに前にいる人を知る必要はありません)。また後ろに立っている人を知る必要もありません。その人は自分で自分がいる列の位置が解るからです。
列は一重リンクリストの古典的な例です。ですがリストは二重リンクもありえます。この場合、列にいるそれぞれの人は前にいる人だけでなく後ろに並んでいる人も知ります。ですからそれぞれの人に問い合わせれば、列のどの方向にも移動することができます。
「標準ライブラリ」で利用可能な標準的な CList はこのアルゴリズムを正確に提供します。既知のクラスからキューを作成してみます。ただし今回はそれは CObjectCustom ではなく、標準 CObject から派生します。
これはスキームとして以下のように表せます。

図3 二重リンクリストスキーム
以下がそのようなスキームを作成するソースコードです。
//+------------------------------------------------------------------+ //| TestList.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2014, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Object.mqh> #include <Arrays\List.mqh> class CCar : public CObject{}; class CExpert : public CObject{}; class CWealth : public CObject{}; class CShip : public CObject{}; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CList list; list.Add(new CCar()); list.Add(new CExpert()); list.Add(new CWealth()); list.Add(new CShip()); printf(">>> enumerate from begin to end >>>"); EnumerateAll(list); printf("<<< enumerate from end to begin <<<"); ReverseEnumerateAll(list); }
これでわれわれのクラスは CObject からポインターを2つ取得しました。一つは前エレメントを参照するもの。もう一つは次のエレメントを参照するものです。リスト上最初のエレメントの前のエレメントに対するポインターは NULL と等しくなります。リスト末尾のエレメントはまたもや NULL に等しい次のエレメントのポインターを持ちます。よってエレメントを1ずつ数え上げ、それによって列全体を列挙することができます。
関数 EnumerateAll() および ReverseEnumerateAll() はリスト上のエレメントすべてを列挙します。
最初の関数はリストを始めから終わりまで列挙し、次の関数は終わりから始めまで列挙します。以下がこれら関数のソースコードです。
//+------------------------------------------------------------------+ //| Enumerates the list from beginning to end displaying a sequence | //| number of each element in the terminal. | //+------------------------------------------------------------------+ void EnumerateAll(CList& list) { CObject* node = list.GetFirstNode(); for(int i = 0; node != NULL; i++, node = node.Next()) printf("Element at " + (string)i); } //+------------------------------------------------------------------+ //| Enumerates the list from end to beginning displaying a sequence | //| number of each element in the terminal | //+------------------------------------------------------------------+ void ReverseEnumerateAll(CList& list) { CObject* node = list.GetLastNode(); for(int i = list.Total()-1; node != NULL; i--, node = node.Prev()) printf("Element at " + (string)i); }
ではこのコードはどのように動作するのでしょうか?実際それはひじょうにシンプルです。コードの冒頭で EnumerateAll() 関数の最初のノードを参照しています。それから for ループ内にこのノードのシーケンスナンバーを表示し、コマンド command node = node.Next() によって次のノードに移動します。エレメントの現インデックスを1(i++)ずつ反復するのを忘れないようにします。列挙は現ノードが NULL となるまで続きます。 for の2番目のブロックのコードはそれを行うものです。node != NULL がそれです。
この関数の逆バージョン ReverseEnumerateAll() は、唯一最初にリスト CObject* node = list.GetLastNode() の最終エレメントを取得する以外は同様に動作します。In the for ループではリスト node = node.Prev() の次ではなく前のエレメントを取得します。
コード開始後、以下のようなメッセージを受け取ります。
2015.02.13 17:52:02.974 TestList (USDCHF,D1) enumerate complete.
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 0
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 1
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 2
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 3
2015.02.13 17:52:02.974 TestList (USDCHF,D1) <<< enumerate from end to begin <<<
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 3
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 2
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 1
2015.02.13 17:52:02.974 TestList (USDCHF,D1) Element at 0
2015.02.13 17:52:02.974 TestList (USDCHF,D1) >>> enumerate from begin to end >>>
リスト内に新規エレメントを簡単に追加することができます。新規エレメントを参照する方法で前のまたは次のエレメントポインターを変更すると、この新規エレメントが前のまたは次のオブジェクトを参照するのです。
スキームは聞くより簡単そうに見えます。

図4 二重リンクリストへの新規エレメント追加
リストの主なデメリットはインデックスによってエレメント同士が参照できないことです。
たとえば、図4にあるように CExpert を参照したい場合、まず CCar にアクセスし、その後 CExpert に移動することができます。同じことが CWeather の場合にも言えます。それはリストの終わりに近いので最後からアクセスする方が簡単でしょう。このためにはまず CShip を参照しそれから CWeather を参照します。
ポインターによる移動は直接インデックスを付けることに比べると速度の遅い処理です。最新の中央処理装置は特に配列処理に対しては最適化されています。それが、リストが潜在的により速く動作するとしても、実践で配列が好まれる理由です。
第2章 連想配列構成論
2.1. 日常生活における連想配列
われわれは日常生活で常に連想配列に直面しています。ただあまりにも明らかなため当然のこととして感じているのです。連想配列または辞書に関連するシンプルな例は普通の電話帳です。電話帳に載っている電話番号はそれぞれ特定の人の名前に関連づいています。電話帳に載っている人の名前はユニークキーで電話番号はシンプルな数値です。電話帳に載っている人はみな複数の電話番号を持つ可能性があります。たとえば、自宅の電話番号、携帯電話番号、仕事の電話番号です。
一般的に番号は無制限の数量ですが人の名前は一つです。たとえば、アレクサンダーという人が2人電話帳に載っていたら混乱してしまいます。間違い電話をかけることもあるでしょう。そのようなことを避けるためにキー(この場合は名前)はユニークである必要があるのです。ただし同時に辞書は衝突を解決し、それに耐える方法を知っています。 同じ名前が2つあると電話帳は成り立たなくなります。そのためわれわれのアルゴリズムはその状況を処理する方法を備える必要があります。
実生活では複数タイプの辞書を使用します。たとえば、電話帳はユニークでない行(人名)がキーとなっている辞書で、電話番号が値です。外国語辞書は別の構成をしています。英語がキーでその訳語が値です。どちらの連想配列も同じデータ処理方法を基にしています。それが、われわれの辞書が多用途でどんなタイプも格納し比較することのできるものでなければならない理由です。
プログラミングにおいても独自の辞書や『ノート』を作成するのが好都合かもしれません。
2.2. スイッチケースオペレータまたはシンプル配列を基にした主な連想配列
みなさんは簡単にシンプルな連想配列を作成することができます。MQL5 言語の標準ツール、たとえスイッチオペレータまたは配列を使うだけです。.
そのコードを詳しく見ます。
//+------------------------------------------------------------------+ //| Returns string representation of the period depending on | //| a passed timeframe value. | //+------------------------------------------------------------------+ string PeriodToString(ENUM_TIMEFRAMES tf) { switch(tf) { case PERIOD_M1: return "M1"; case PERIOD_M5: return "M5"; case PERIOD_M15: return "M15"; case PERIOD_M30: return "M30"; case PERIOD_H1: return "H1"; case PERIOD_H4: return "H4"; case PERIOD_D1: return "D1"; case PERIOD_W1: return "W1"; case PERIOD_MN1: return "MN1"; } return "unknown"; }
この場合、スイッチケースオペレータは辞書のような役割をします。ENUM_TIMEFRAMES の値はそれぞれこの期間を説明する文字列値を持ちます。スイッチオペレータが切り替えパッセージ(ロシア語で)であるため、必要なケースバリアント へのアクセスは瞬時に行われ、その他のケースバリアントは列挙されていません。このコードが高効率なのはその理由によります。
ただしデメリットはまずすべての値を書き込む必要があることです。これはマニュアルでENUM_TIMEFRAMESの一つまたは別の値を変える必要があるものです。次に、スイッチは整数値でしか処理できないことです。しかし転送される文字列に応じてタイムフレームタイプを返すリバース関数を書くのは大変なことでしょう。そのような方法のもう一つのデメリットは、この方法がいまひとつ柔軟性に欠ける点です。可能性のあるバリアントはすべて事前に指定する必要があります。が、新規データが利用可能になると、頻繁に辞書の中に動的に値を書き込む必要があります。
「キー-値」ペア格納方法の第二の「前部」方法にはキーがインデックスとして使用され、値が配列エレメントである配列を作成する必要があります。
たとえば、類似したタスクを行ってみます。すなわちタイムフレーム文字列表示を返すのです。
//+------------------------------------------------------------------+ //| String values corresponding to the | //| time frame. | //+------------------------------------------------------------------+ string tf_values[]; //+------------------------------------------------------------------+ //| Adding associative values to the array. | //+------------------------------------------------------------------+ void InitTimeframes() { ArrayResize(tf_values, PERIOD_MN1+1); tf_values[PERIOD_M1] = "M1"; tf_values[PERIOD_M5] = "M5"; tf_values[PERIOD_M15] = "M15"; tf_values[PERIOD_M30] = "M30"; tf_values[PERIOD_H1] = "H1"; tf_values[PERIOD_H4] = "H4"; tf_values[PERIOD_D1] = "D1"; tf_values[PERIOD_W1] = "W1"; tf_values[PERIOD_MN1] = "MN1"; } //+------------------------------------------------------------------+ //| Returns string representation of the period depending on | //| a passed timeframe value. | //+------------------------------------------------------------------+ void PeriodToStringArray(ENUM_TIMEFRAMES tf) { if(ArraySize(tf_values) < PERIOD_MN1+1) InitTimeframes(); return tf_values[tf]; }
このコードは ENUM_TIMFRAMES がインデックスとして指定されるインデックスによる参照を示しています。値を返す前に関数は配列が必要なエレメントで埋められているか確認します。埋められていなければ、関数は特別な関数-InitTimeframes()、に書き込みを委託します。これにはスイッチ オペレータと同じデメリットがあります。
それ以上にそのような辞書構成には大きな値の配列を初期化する必要があります。よって PERIOD_MN1 モディファイアの値は 49153 となります。それはたった9とおりのタイムフレームを格納するのにセルが 49153 個必要であるということです。その他のセルは書き込みなしのままです。データ割り当てのこの方法は簡易な方法からはほど遠いものですが、列挙が小さく数字の連続した範囲で構成されているなら適しているかもしれません。
2.3. ベースタイプからユニークキーへの変換
辞書で使用されるアルゴリズムはキーや値のタイプに限らず似ているため、異なるデータタイプを1つのアルゴリズムで処理できるようにデータ調整を行う必要があります。われわれの辞書アルゴリズムは汎用的で、任意の基本タイプがキーとして指定される場合値を格納することのできるものです。たとえば、タイプ int、enum、double、それにstringさえもです。
実際Actually, in MQL5 ではあらゆる基本データタイプは記号なしの ulong 数値として表すことができます。たとえばデータタイプ short または ushort は ulongの『短縮』バージョンです。
ulong タイプは ushort 値を格納することを速く理解すると、つねに安全な明示的型変換が可能です。
ulong ln = (ushort)103; // Save the ushort value in the ulong type (103) ushort us = (ushort)ln; // Get the ushort value from the ulong type (103)
同じことがタイプ char および int とその記号なし類似体にも言えます。ulong はどんなタイプ、 ulong以下のサイズも格納することができるためです。Datetime、enum、color タイプは整数 32 ビット uint ナンバーを基にしています。それはそれらが安全に ulong に変換できることを意味しています。bool タイプには値は 2 つしかありません。偽を意味する 0 と真を意味する 1 です。よって bool タイプの値は ulong タイプの値にも格納することが可能です。その上 MQL5 システム関数の多くはこの性質に基づいています。
たえおえば、AccountInfoInteger() 関数は long タイプの整数値を返します。それはまた ulong タイプのアカウントナンバーでもありえ、トレード-ACCOUNT_TRADE_ALLOWEDに対する許可のブール値でもありえます。
しかし MQL5 には整数タイプと異なる基本の3タイプがあります。それらは直接制す ulong タイプに変換することができません。その中には double および float、またstringsのような浮動小数点タイプがあります。ただいくつかシンプルな処理でそれらをユニークな整数キー/値に変換することが可能です。
浮動小数点値はそれぞれ任意の累乗に対して発生するベースとして設定することができます。そおではベースと累乗は整数値として個別に格納されます。その種の格納方法はダブル値 および 浮動小数点値で使用されます。浮動小数点タイプは仮数部と累乗を格納するのに32桁を使い、ダブルタイプは64桁を使います。
それらを直接 ulong タイプに変換しようとしたら、値は単純に四捨五入されます。この場合、3.0 と 3.14159 は同じ ulong 値 3 となります。これはわれわれには適していません。われわれは 2 個の異なる値に対しては異なるキーが必要だからです。一つ共通していない特徴、これは C タイプ言語で使用されるものですが、が救いとなります。おsれは構造変換と呼ばれます。サイズが同じであれば、2つの異なるストラクチャを変換することができるのです(あるストラクチャから別のストラクチャへ)。
一方が ulong タイプ値を、他方が double タイプ値を格納する2つのストラクチャ例を分析します。
struct DoubleValue{ double value;} dValue; struct ULongValue { ulong value; } lValue; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- dValue.value = 3.14159; lValue = (ULongValue)dValue; printf((string)lValue.value); dValue.value = 3.14160; lValue = (ULongValue)dValue; printf((string)lValue.value); }
このコードは DoubleValue ストラクチャを1バイトずつ ULongValue ストラクチャへコピーします。それらは同じサイズで変数の順番も同じであるため、 dValue.value の double 値は1バイトずつ lValue.valueの ulong変数にコピーされます。
その後、この変数値が出力されます。dValue.value を 3.14160 に変更すると、lValue.value もまた変更されます。
以下が printf() 関数によって表示される結果です。
2015.02.16 15:37:50.646 TestList (USDCHF,H1) 4614256673094690983
2015.02.16 15:37:50.646 TestList (USDCHF,H1) 4614256650576692846
浮動小数点タイプは double タイプの短縮バージョンです。それに応じて浮動小数点タイプ ulong タイプに変換する前に、浮動小数タイプを安全 double タイプに拡張することができます。
float fl = 3.14159f; double dbl = fl;
その後、構造変換によって double タイプを ulong タイプに変換します。
2.4. 文字列のハッシュおよびキーとしてのハッシュ使用
上記例ではキーは1つのデータタイプ-文字列、で表されていました。ですが異なる状況もあり得ます。たとえば電話番号の最初の3桁が電話提供企業を示す場合などです。この場合は特にこれら3桁はキーを表現します。一方、各文字列はその各桁がアルファベット文字のシーケンスナンバーを意味するユニークナンバーとして表されることもあります。よって文字列をユニーク ナンバーに変換し、このナンバーをそれに関連する値の整数キーとして使用することが可能です。
この方法は優れていますが十分多目的ではありません。キーとして何百というシンボルを持つ文字列を使用する場合、その数はひじょうに大きなものとなります。どんなタイプであれシンプルな変数にそれを当てはめるのは不可能です。ハッシュ関数がこの課題を解決するのに役立ってくれます。ハッシュ関数はどんなデータタイプ(たとえば文字列)も受け取り、この文字列を特徴すけるユニークなナンバーを返す特定のアルゴリズムです。
入力データのシンボルが1個変更しただけでもその数字はまったく異なります。この関数によって返される数字は固定された幅を持ちます。たとえば、ハッシュ関数 Adler32() は任意の文字列の形式をしたパラメータを受け取り、32乗された0~2の範囲の数字を返します。この関数はひじょうにシンプルですがわれわれのタスクには実に適しています。
以下のように MQL5 でのソースコードがあります。
//+------------------------------------------------------------------+ //| Accepts a string and returns hashing 32-bit value, | //| which characterizes this string. | //+------------------------------------------------------------------+ uint Adler32(string line) { ulong s1 = 1; ulong s2 = 0; uint buflength=StringLen(line); uchar char_array[]; ArrayResize(char_array, buflength,0); StringToCharArray(line, char_array, 0, -1, CP_ACP); for (uint n=0; n<buflength; n++) { s1 = (s1 + char_array[n]) % 65521; s2 = (s2 + s1) % 65521; } return ((s2 << 16) + s1); }
変換された文字列によってどんな数値を返すか確認します。
このため、この関数を呼び異なる文字列を変換するシンプルなスクリプトを書きます。
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- printf("Hello world - " + (string)Adler32("Hello world")); printf("Hello world! - " + (string)Adler32("Hello world!")); printf("Peace - " + (string)Adler32("Peace")); printf("MetaTrader - " + (string)Adler32("MetaTrader")); }
このスクリプトのアウトプットは次のようなものです。
2015.02.16 13:29:12.576 TestList (USDCHF,H1) MetaTrader - 352191466
2015.02.16 13:29:12.576 TestList (USDCHF,H1) Peace - 91685343
2015.02.16 13:29:12.576 TestList (USDCHF,H1) Hello world! - 487130206
2015.02.16 13:29:12.576 TestList (USDCHF,H1) Hello world - 413860925
見てのとおり、各文字列には対応するユニークナンバーがあります。文字列 "Hello world" と "Hello world!" に着目します。両者はほぼ同じです。唯一の違いは二番目の文字列の最後にある感嘆符です。
ですがこの二つで Adler32() によって与えられる数値はまったく異なっています。
ここで文字列タイプを記号なしの uint 値に変える方法を学びます。そして 文字列 タイプキーの代わりにその整数ハッシュを格納します。2つの文字列が1つのハッシュを持つならそれは同じ文字列である可能性が高くなります。値に対するキーは文字列ではありませんが、この文字列を基に生成された整数ハッシュなのです。
2.5. キーによるインデックスの表現リスト配列
これから MQL5 の基本タイプを記号なしの ulong タイプに変換する方法を学習します。このタイプがまさに値が対応する先の実際のキーとなります。ですが ulong タイプのユニークキーを持つだけでは十分ではありません。もちろん各オブジェクトのユニークキーを知っている場合は、スイッチケースオペレータか任意の長さの配列を基にした簡単なストレージを作成することができるでしょう。
その方法は前章のセクション2.2で説明済みです。ただそれらは柔軟性を欠き、十分に効率的でもありません。スイッチケースについては、このオペレータのバリアントをすべて説明するのは不可能に思えます。
何千というオブジェクトがあるかのように、スイッチオペレータを記述する必要があります。コンパイルの段階で何千というキーで構成されており、それは不可能です。2番目の方法はエレメントのキーもインデックスを付けられる配列を使用することです。それにより必要なエレメントを追加して動的に配列のサイズを変更することが可能となります。そのためエレメントのキーとなるインデックスを常に参照することができます。
このソリューションの原案を作成します。
//+------------------------------------------------------------------+ //| Array to store strings by a key. | //+------------------------------------------------------------------+ string array[]; //+------------------------------------------------------------------+ //| Adds a string to the associative array. | //| RESULTS: | //| Returns true, if the string has been added, otherwise | //| returns false. | //+------------------------------------------------------------------+ bool AddString(string str) { ulong key=Adler32(str); if(key>=ArraySize(array) && ArrayResize(array,key+1)<=key) return false; array[key]=str; return true; }
ただ、実際にはこのコードはかえって問題を起こしますが、それは解決しません。ハッシュ関数が大きなハッシュを出力すると仮定します。既出の例では配列インデックスはそのハッシュと等しいため、配列を巨大にするようサイズ変更をする必要があります。そしてそれは必ずしもうまくいくということではありません。数ギガバイトにおよぶサイズのコンテナに文字列を格納したいと思いますか?
二番目の問題はコリジョンのとき前の値が新しい値に置き換えられてしまうことです。 結局 Adler32() 関数が2つの異なる文字列に対して1つのハッシュキーを返す可能性はあるのです。キーを用いて速く参照したいがためにデータの一部を失いたいと思いますか?こういった質問のこたえは明らかです。-いいえ、そうなりたくない、です。そういった状況を避けるには、ストレージのアルゴリズムを変更し、リスト配列に基づく専用のハイブリッドコンテナを作成する必要があります。
リスト配列は配列とリストの 一番の性質を兼ね備えます。これら2つのクラスは標準ライブラリで表されます。配列は未定義のエレメントを迅速に参照することを可能としますが、配列自体はゆっくりとサイズ変更することを思い出します。一方、リストは新規エレメントの追加と削除をすぐに行いますが、リストのエレメントへのアクセスはかなり遅いものです。
以下はリスト配列の記述です。

図5 リスト配列図
図から明確なことは、リスト配列はそのエレメントがリスト形式を持つ配列であることです。そのメリットを確認します。まず第一に、そのインデックスによってどんなリストも迅速に参照することができます。また、リストにデータエレメントを格納する場合、配列のサイズを変更することなく速やかにリストにエレメントを追加、およびリストからのエレメント削除を行うことができます。配列インデックスは空または NULL である可能性があります。このインデックスに対応しているエレメントはまだ追加されていないということです。
配列とリストの組合せはもう一つ珍しい機会を提供します。1つのインデックスにより2個以上のエレメントを格納することができるのです。それの必要性を理解するには、エレメントを3個もつ配列に数字を10個格納する必要があると仮定します。見てのとおり、配列のエレメント以上の数値があることになります。リストを配列に格納することでこの問題を解決します。2個以上の数字を格納するために、3つの配列インデックスの一つにアタッチされている3つのリストの内の一つが必要になると仮定します。
リストのインデックスを決めるためには、配列内のエレメント数でここにある数字を割った余りを得る必要があります。
配列インデックス = 数字 % 配列内エレメント
たとえば、数字2に対するリストインデックスは次のようになります: 2%3 = 2。インデックス2はインデックスによってリストに格納されるということです。数字 3 はインデックス 3%3 = 0 によって格納されます。数字 7 はインデックス 7%3 = 1 によって格納されます。リストインデックスを決めたあとはこの数値をリスト末尾に追加すればよいだけです。
リストから数字を抽出するのにも同様の処理が必要です。コンテナから数字7を取り出したいとします。それにはその数字がどのコンテナにあるのか探す必要があります。:7%3=1 というふうに。数字7はインデックス1のリストにあることを判断したら、リスト全体をソートし、エレメントの一つが7であればこの値を返します。
1つのインデックスにより複数エレメントを格納することができるなら、少量のデータを格納するためにひじょうに大きい配列を作成する必要はありません。0~10 桁で構成され、エレメントを3個持つ配列に数字 232,547,879 を格納する必要があるとします。この数字は(232,547,879 % 3 = 2)に等しいそれ自体のリストインデックスを持ちます。
数字をハッシュに置き換えるなら、辞書にあるべき任意のエレメントのインデックスを見つけることができるようになります。ハッシュは数字だからです。その上、1つのリストに複数エレメントを格納できるため、ハッシュはユニークである必要はありません。同じハッシュを持つエレメントは1つのリスト内に存在するのです。キーによってエレメントを抽出する必要があるなら、これらエレメント同士を比較し、キーに対応するものを抽出します。
これは同じハッシュの2個のエレメントがユニークキーを2つ持つため可能です。キーのユニークさは辞書にエレメントを追加する関数によって制御することができます。それは辞書内にすでに対応するキーがあれば、新規エレメントを追加しません。これは電話番号1件に使用者が1人という対応を制御するようなものです。
2.6. 配列のサイズ変更、リスト長の最小化
リスト配列がより小さく、より多くのエレメントを追加すれば、アルゴリズムにより形成されるリスト連鎖は長くなります。第1章でお話したように、この連鎖のエレメントへのアクセスは非効率的なものです。リストが短いほど、コンテナはインデックスにより各エレメントにアクセスできる配列のように見えます。われわれは短いリストと長い配列目標を目標にする必要があります。エレメント10個に対する完璧な配列は10件のリストで構成されている配列で、そのリストがそれぞれエレメントを1個もつことです。
最悪のバリアントは1件のリストの長瀬にエレメントが10個入った配列です。エレメントはすべてプログラムフロー中コンテナに動的に追加されるため、いくつエレメントが追加されるか予測がつきません。そのため配列を動的にサイズ変更することを考慮する必要があるのです。そしてその上、リスト内の連鎖数はエレメント1個であるべきです。このため配列サイズがエレメント数合計に等しく保たれる必要があるのは明らかです。エレメントの追加には常に配列のサイズ変更がついてまわります。
配列のサイズ変更に伴いリストをすべてサイズ変更する必要があることで状況は複雑になります。これはエレメントが属するリストインデックスがサイズ変更後変わる可能性があるためです。たとえば、配列がエレメントを3個もっている場合、数字5は2番目のインデックスに格納されます(5%3 = 2)。エレメントが6個あれば、数字5は5番目のインデックスに格納されます(5%6=5)。よって辞書のサイズ変更は速度のおそい処理なのです。それはできるだけ頻度を低く行う必要があります。一方、それをまったく行わなければ、新規エレメントに伴い連鎖が大きくなり、エレメントへのアクセスはどんどん効率が落ちます。
配列のサイズ変更と連鎖の平均長の間の合理的な妥協を実装するアルゴリズムを作成することは可能です。次のサイズ変更のたびに配列の現サイズを2倍に増やすことを基にします。辞書が最初にエレメントを2個持ち、最初のサイズ変更で4増加し(2^2)、二番目のサイズ変更で8(2^3)、三番目で16(2^3)です。16回目のサイズ変更後、スペースは 65 536 連鎖(2^16)分です。追加されるエレメント量が2の累乗に一致する場合は、サイズ変更が行われます。このため必要な実主要メモリトータルはエレメントを2回以上格納するためにメモリを越えることはありません。一方、対数法則は配列が頻繁にサイズ変更しなくてよいようにします。
同様にリストからエレメント を消去して配列サイズを減らし、そうすることで割り当てられたメインメモリを節約します。
第3章連想配列の実用的作成
3.1. CDictionary クラス、メソッド AddObject および DeleteObjectByKey、 KeyValuePair コンテナのテンプレートcontainer
われわれの連想配列は多目的でどんなタイプのキーとも連携できるものである必要があります。同時に値として標準的 CObject に基づくオブジェクトを使用します。クラスには任意の基本変数を入れることができるので、われわれの辞書はワンストップソリューションとなります。もちろん辞書のクラスを複数作成することもできるでしょう。各基本タイプに個別のクラスを使用することもできるでしょう。
たとえば次のようなクラスを作成することもできます。
CDictionaryLongObj // For storing pairs <ulong, CObject*> CDictionaryCharObj // For storing pairs <char, CObject*> CDictionaryUcharObj // For storing pairs <uchar, CObject*> CDictionaryStringObj // For storing pairs <string, CObject*> CDictionaryDoubleObj // For storing pairs <double, CObject*> ...
ただ MQL5 にはひじょうに多くの基本タプがあります。その上、コードエラーをそれぞれ数多くの解す修正する必要があります。というのもすべてのタイプには核となるコードがあるためです。われわれは重複を避けるためにテンプレートを使用します。クラスは一つですが、それは同時に複数のデータタイプを処理するのです。主要なクラスのメソッドがテンプレートとなるのはそのためです。
まず、第一のテンプレートメソッド-Add() を作成します。このメソッドはわれわれの辞書に任意のキーを持つエレメントを追加します。その辞書クラスは CDictionary と呼ばれます。エレメントと共に辞書は CList リストに対するポインター配列を持ちます。そしてこれら連鎖にエレメントを格納するのです。
//+------------------------------------------------------------------+ //| An associative array or a dictionary storing elements as | //| <key - value>, where a key may be represented by any base type, | //| and a value may be represented be a CObject type object. | //+------------------------------------------------------------------+ class CDictionary { private: CList *m_array[]; // List array. template<typename T> bool AddObject(T key,CObject *value); }; //+------------------------------------------------------------------+ //| Adds a CObject type element with a T key to the dictionary | //| INPUT PARAMETRS: | //| T key - any base type, for instance int, double or string. | //| value - a class that derives from CObject. | //| RETURNS: | //| true, if the element has been added, otherwise - false. | //+------------------------------------------------------------------+ template<typename T> bool CDictionary::AddObject(T key,CObject *value) { if(ContainsKey(key)) return false; if(m_total==m_array_size){ printf("Resize" + m_total); Resize(); } if(CheckPointer(m_array[m_index])==POINTER_INVALID) { m_array[m_index]=new CList(); m_array[m_index].FreeMode(m_free_mode); } KeyValuePair *kv=new KeyValuePair(key, m_hash, value); if(m_array[m_index].Add(kv)!=-1) m_total++; if(CheckPointer(m_current_kvp)==POINTER_INVALID) { m_first_kvp=kv; m_current_kvp=kv; m_last_kvp=kv; } else { m_current_kvp.next_kvp=kv; kv.prev_kvp=m_current_kvp; m_current_kvp=kv; m_last_kvp=kv; } return true; }
AddObject() メソッドは以下のように動作します。まず辞書に追加されるキーを持つエレメントがあるか確認します。ContainsKey() メソッドはこの確認を行います。辞書がすでにキーを持つ場合は新規エレメントは追加されません。2個のエレメントが1個のキーに対応するとしたらそれは不確実を生じるためです。
それからこのメソッドは CList 連鎖が格納される配列サイズを知ります。配列サイズがエレメント数に等しければ、サイズ変更を行います。このタスクは Resize() が担います。
次のステップはシンプルです。決められたインデックスに従い CList 連鎖がまだ存在していなければ、この連鎖は作成される必要があります。インデックスは ContainsKey() メソッドによってまえもって決められます。それは決められたインデックスを m_index 変数内に保存します。それからこのメソッドはリストの末尾に新規エレメントを追加します。ただこの前にエレメントは特別なコンテナ — KeyValuePair にパックされます。それは標準 CObject に基づき、追加のポインターとデータで後者を拡張します。コンテナクラス作成はもう少し後で説明します。追加ポインターと共に、コンテナはオブジェクトのオリジナルのキーとハッシュも格納します。
AddObject() メソッドはテンプレートメソッドです。
template<typename T> bool CDictionary::AddObject(T key,CObject *value);
このレコードはキー引数タイプが代用で、実際のタイプはコンパイル時に決定されることを意味します。
たとえば AddObject() メソッドは以下のようにコード内でアクティブ化されます。
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { CObject* obj = new CObject(); dictionary.AddObject(124, obj); dictionary.AddObject("simple object", obj); dictionary.AddObject(PERIOD_D1, obj); }
こういったアクティブ化はテンプレートのおかげで完璧に動作するのです。
また AddObject() メソッドとは逆の DeleteObjectByKey() があります。このメソッドはキーによって辞書からオブジェクトを削除します。
たとえば、『クルマ』というキーが存在していれば、それでオブジェクトを削除することができるのです。
if(dict.ContainsKey("Car")) dict.DeleteObjectByKey("Car");
コードは AddObject() メソッドのコードにひじょうに似ています。よってここではそれを説明しません。
メソッドAddObject() および DeleteObjectByKey() はオブジェクトに直接作用しません。この代わりにそれらは標準 CObject クラスを基にKeyValuePair コンテナに対して各オブジェクトをパックします。このコンテナは追加のポインターを持ち、それはエレメントを関連づけることができます。また、オブジェクト用に決められるオリジナルのキーとハッシュを持ちます。このコンテナはコリジョンを回避することのできる渡されるキーの質の検証もします。これについてはContainsKey() メソッドについて述べる次のセクションでお話します。
ここではこのクラスの内容を記述します。
//+------------------------------------------------------------------+ //| Container to store CObject elements | //+------------------------------------------------------------------+ class KeyValuePair : public CObject { private: string m_string_key; // Stores a string key double m_double_key; // Stores a floating-point key ulong m_ulong_key; // Stores an unsigned integer key ulong m_hash; public: CObject *object; KeyValuePair *next_kvp; KeyValuePair *prev_kvp; template<typename T> KeyValuePair(T key, ulong hash, CObject *obj); ~KeyValuePair(); template<typename T> bool EqualKey(T key); ulong GetHash(){return m_hash;} }; template<typename T> KeyValuePair::KeyValuePair(T key, ulong hash, CObject *obj) { m_hash = hash; string name=typename(key); if(name=="string") m_string_key = (string)key; else if(name=="double" || name=="float") m_double_key = (double)key; else m_ulong_key = (ulong)key; object=obj; } KeyValuePair::~KeyValuePair() { delete object; } template<typename T> bool KeyValuePair::EqualKey(T key) { string name=typename(key); if(name=="string") return key == m_string_key; if(name=="double" || name=="float") return m_double_key == (double)key; else return m_ulong_key == (ulong)key; }
3.2. typename に基づくランタイムタイプ特定、ハッシュサンプリング
われわれのタイプで未定義のメソッドの取り込み方がわかっている場合、そのハッシュを決定する必要があります。整数タイプすべてについては、ハッシュは ulong タイプに拡張されているこのタイプの値に等しくなります。
double および浮動小数点 タイプいnついてハッシュを計算するためには『ベースタイプからユニークキーへの変換』セクションに述べられているストラクチャを介したキャストが必要です。ハッシュ関数は文字列に対して使用します。とにかくとのデータタイプも独自のハッシュサンプリング方法を必要とします。変換タイプを決定し、このタイプに応じたハッシュサンプリング方法をアクティブ化することがすべてです。このためには特殊な命令 typename が必要となります。
キーを基にしてハッシュを決定するメソッドは GetHashByKey() と呼ばれます。
それは以下をインクルードします。
//+------------------------------------------------------------------+ //| Calculates a hash basing on a transferred key. The key may be | //| represented by any base MQL type. | //+------------------------------------------------------------------+ template<typename T> ulong CDictionary::GetHashByKey(T key) { string name=typename(key); if(name=="string") return Adler32((string)key); if(name=="double" || name=="float") { dValue.value=(double)key; lValue=(ULongValue)dValue; ukey=lValue.value; } else ukey=(ulong)key; return ukey; }
そのロジックはシンプルです。typename 命令を用い、メソッドは変換タイプの文字列名を取得します。文字列がキーとして変換される場合、typename は『文字列』値を、int 値の場合は"int"を返します。その他のあらゆるタイプでも同じことが起こります。そこで返された値を必要な文字列の定数と比較し、この値が定数の一つと一致していれば対応するハンドラを返すようにすればよいだけです。
キーが文字列タイプであれば、そのハッシュは Adler32() 関数によって計算されます。キーが実タイプによって表わされる場合、それらはストラクチャ変換によるハッシュに変換されます。その他タイプはすべてハッシュとなる ulong タイプに明示的に変換されます。
3.3. ContainsKey() メソッドハッシュ コリジョンへの対処
コリジョンにあるハッシュの主な問題-異なるキーが同一ハッシュを出す状況そのような場合には、ハッシュが一致すると曖昧さがおこります(辞書ロジックに関して2つのオブジェクトが類似します)。そういった状況を避けるには、現キータイプと依頼されているキータイプを確認し、現キーが一致していればプラスの値を返します。それが ContainsKey() メソッドの役割です。このメソッドは依頼のキーを持つオブジェクトが存在すれば真を、それ以外は偽を返します。
おそらくこれは全辞書内でもっとも有用で便利なメソッドです。それにより一定のキーが存在するかどうかわかるのです。
#include <Dictionary.mqh> CDictionary dict; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { if(dict.ContainsKey("Car")) printf("Car always exists."); else dict.AddObject("Car", new CCar()); }
たとえば、上記のコードは CCar タイプオブジェクトが利用可能であるか確認し、そのようなオブジェクトが存在しなければ CCar を追加します。このメソッドいよりまた、新規にオブジェクトが追加されるたびにキーがユニークであるか確認することができます。
オブジェクトキーがすでに使用されていると、AddObject() メソッドは辞書にこの新規オブジェクトを追加しません。
template<typename T> bool CDictionary::AddObject(T key,CObject *value) { if(ContainsKey(key)) return false; ... }
これはユーザー、別のクラスメソッド双方によって頻繁に使用される一般的なメソッドです。
以下がその内容です。
//+------------------------------------------------------------------+ //| Checks whether the dictionary contains a key of T arbitrary type.| //| RETURNS: | //| Returns true, if an object having this key exists, | //| otherwise returns false. | //+------------------------------------------------------------------+ template<typename T> bool CDictionary::ContainsKey(T key) { m_hash=GetHashByKey(key); m_index=GetIndexByHash(m_hash); if(CheckPointer(m_array[m_index])==POINTER_INVALID) return false; CList *list=m_array[m_index]; m_current_kvp=list.GetCurrentNode(); if(m_current_kvp == NULL)return false; if(m_current_kvp.EqualKey(key)) return true; m_current_kvp=list.GetFirstNode(); while(true) { if(m_current_kvp.EqualKey(key)) return true; m_current_kvp=list.GetNextNode(); if(m_current_kvp==NULL) return false; } return false; }
まずメソッドが GetHashByKey() を使用するハッシュを検索します。ハッシュに基づき、CList 連鎖のインデックスを取得します。ここで与えられるハッシュを持つオブジェクトが配置されます。そのような連鎖がなければ、そのキーを持つオブジェクトも存在しません。この場合、処理を早期終了し、偽(そのようなキーを持つオブジェクトが存在しません)を返します。連鎖が存在しれば、列挙が開始されます。
この連鎖の各エレメント KeyValuePair タイプオブジェクトによって表されます。これは今変換されたキーとエレメントによって格納されているキーを比較するものです。キーば同一であれば、メソッドは真(そのキーを持つオブジェクトが存在します)を返します。キーの同一性を検証するコードは KeyValuePair クラスのリスト内で与えられます。
3.4. メモリの動的割り当てと割り当て解除
Resize() メソッドは動的割り当てと連想配列内への割当てをします。このメソッドはエレメント数が m_array サイズに一致するたびにアクティブ化されます。またエレメントがリストから削除されるときにもアクティブ化されます。このメソッドはすべてのエレメントに対する格納インデックスをオーバーライドするため、動作スピードはひじょうに遅いものです。
Resize() メソッドが頻繁にアクティブ化されないように、割当てメモリのボリュームは前回ボリュームと比較し、毎回2度増加されます。すなわち、辞書に 65,536 エレメント格納したければ、Resize() メソッドは 16 回 (2^16) アクティブ化されるのです。20回アクティブ化された後、辞書は100万エレメント(1,048,576)以上持つことになるでしょう。FindNextLevel() メソッドは依頼エレメント指数関数的に増やします。
以下は Resize() メソッドのソースコードです。
//+------------------------------------------------------------------+ //| Resizes data storage container | //+------------------------------------------------------------------+ void CDictionary::Resize(void) { int level=FindNextLevel(); int n=level; CList *temp_array[]; ArrayCopy(temp_array,m_array); ArrayFree(m_array); m_array_size=ArrayResize(m_array,n); int total=ArraySize(temp_array); KeyValuePair *kv=NULL; for(int i=0; i<total; i++) { if(temp_array[i]==NULL)continue; CList *list=temp_array[i]; int count=list.Total(); list.FreeMode(false); kv=list.GetFirstNode(); while(kv!=NULL) { int index=GetIndexByHash(kv.GetHash()); if(CheckPointer(m_array[index])==POINTER_INVALID) m_array[index]=new CList(); list.DetachCurrent(); m_array[index].Add(kv); kv=list.GetCurrentNode(); } delete list; } int size=ArraySize(temp_array); ArrayFree(temp_array); }
このメソッドは高い方にも低い方にも両方に動作します。現配列が持つことのできるエレメントよりも少ないエレメントしかない場合、エレメント減少コードが開始されます。そして逆に現配列が十分でなければ、配列はより多くエレメントを持つためにサイズ変更されます。このコードは多量の計算リソースを必要とします。
配列全体はサイズ変更されてもエレメントすべては事前に配列の一時的コピーに移動される必要があります。それからすべてのエレメントに対して新しいインデックスを決め、こののち初めてエレメントを新しい地点に配置することができます。
3.5. ストロークの終了:オブジェクト検索と便利なインデクサ
われわれの CDictionary クラスはすでに連動する主要なメソッドを取得しました。一定のキーを持つオブジェクトが存在するか知りたければ、ContainsKey() メソッドを使用することができます。AddObject() メソッドを使用して辞書にオブジェクトを追加することができるのです。また DeleteObjectByKey() メソッドによって辞書からオブジェクトを削除することもできます。
ここでコンテナ内のオブジェクトすべての便利な列挙を作成する必要があります。すでにご存じのように、エレメントはすべてキーに従い特定の順序でそこに格納されます。ただ、連想配列にエレメントを追加したのと同じ順序で列挙するのが便利でしょう。このために KeyValuePair コンテナは KeyValuePair タイプの前回と次のエレメントに追加されるポインターをもうふたつ持ちます。このポインターによって連続列挙を行うことができるのです。
たとえば、次のように連想配列にエレメントを追加する場合、
CNumber --> CShip --> CWeather --> CHuman --> CExpert --> CCar
このエレメントの列挙も連続的なものとなります。これは図6にあるように KeyValuePair に対する参照キーを用いて行われるためです。

図6 連続配列列挙のスキーム図
その列挙を行うために5個のメソッドが使用されています。
以下がその内容と簡単な説明です。
//+------------------------------------------------------------------+ //| Returns the current object. Returns NULL if an object was not | //| chosen | //+------------------------------------------------------------------+ CObject *CDictionary::GetCurrentNode(void) { if(m_current_kvp==NULL) return NULL; return m_current_kvp.object; } //+------------------------------------------------------------------+ //| Returns the previous object. The current object becomes the | //| previous one after call of the method. Returns NULL if an object | //| was not chosen. | //+------------------------------------------------------------------+ CObject *CDictionary:: GetPrevNode(void) { if(m_current_kvp==NULL) return NULL; if(m_current_kvp.prev_kvp==NULL) return NULL; KeyValuePair *kvp=m_current_kvp.prev_kvp; m_current_kvp=kvp; return kvp.object; } //+------------------------------------------------------------------+ //| Returns the next object. The current object becomes the next one | //| after call of the method. Returns NULL if an object was not | //| chosen. | //+------------------------------------------------------------------+ CObject *CDictionary::GetNextNode(void) { if(m_current_kvp==NULL) return NULL; if(m_current_kvp.next_kvp==NULL) return NULL; KeyValuePair *kvp=m_current_kvp.next_kvp; m_current_kvp=kvp; return kvp.object; } //+------------------------------------------------------------------+ //| Returns the first node from the node list. Returns NULL if the | //| dictionary does not have nodes. | //+------------------------------------------------------------------+ CObject *CDictionary::GetFirstNode(void) { if(m_first_kvp==NULL) return NULL; m_current_kvp=m_first_kvp; return m_first_kvp.object; } //+------------------------------------------------------------------+ //| Returns the last node in the list. Returns NULL if the | //| dictionary does not have nodes. | //+------------------------------------------------------------------+ CObject *CDictionary::GetLastNode(void) { if(m_last_kvp==NULL) return NULL; m_current_kvp=m_last_kvp; return m_last_kvp.object; }
シンプルな反復により追加エレメントの連続的な列挙を行うことができます。
class CStringValue : public CObject { public: string Value; CStringValue(); CStringValue(string value){Value = value;} }; CDictionary dict; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { dict.AddObject("CNumber", new CStringValue("CNumber")); dict.AddObject("CShip", new CStringValue("CShip")); dict.AddObject("CWeather", new CStringValue("CWeather")); dict.AddObject("CHuman", new CStringValue("CHuman")); dict.AddObject("CExpert", new CStringValue("CExpert")); dict.AddObject("CCar", new CStringValue("CCar")); CStringValue* currString = dict.GetFirstNode(); for(int i = 1; currString != NULL; i++) { printf((string)i + ":\t" + currString.Value); currString = dict.GetNextNode(); } }
このコードは辞書にオブジェクトが追加されたと同じ順所でオブジェクトの文字列値を出力します。
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 6: CCar
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 5: CExpert
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 4: CHuman
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 3: CWeather
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 2: CShip
2015.02.24 14:08:29.537 TestDict (USDCHF,H1) 1: CNumber
OnStart() 関数内のコードの文字列にを2個変更し、エレメントをすべて後ろから出力するようにします。
CStringValue* currString = dict.GetLastNode(); for(int i = 1; currString != NULL; i++) { printf((string)i + ":\t" + currString.Value); currString = dict.GetPrevNode(); }
従って出力される値は反転しています。
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 6: CNumber
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 5: CShip
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 4: CWeather
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 3: CHuman
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 2: CExpert
2015.02.24 14:11:01.021 TestDict (USDCHF,H1) 1: CCar
第4章 パフォーマンスの検証と評価
4.1. 検証のコード作成とパフォーマンス評価
パフォーマンス評価はクラスを作成するうえでのコア成分で、特にデータ格納のためのクラスについてそれが言えます。結局もっとも多様性に富んだプログラムはこのクラスを利用するものです。こういったプログラムのアルゴリズムはスピードに厳しく、高いパフォーマンスを要求します。それがパフォーマンス評価方法を知り、アルゴリズムの弱点を検索することが重要な理由です。
まず、辞書にエレメントを追加したり辞書からエレメントを抽出するスピードを測定するシンプルなテストを書きます。このテストは文字列のな見かけをしています。
以下にそのソースコードをアタッチしています。
//+------------------------------------------------------------------+ //| TestSpeed.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Dictionary.mqh> #define BEGIN 50000 #define STEP 50000 #define END 1000000 //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CDictionary dict(END+1); for(int j=BEGIN; j<=END; j+=STEP) { uint tiks_begin=GetTickCount(); for(int i=0; i<j; i++) dict.AddObject(i,new CObject()); uint tiks_add=GetTickCount()-tiks_begin; tiks_begin=GetTickCount(); CObject *value=NULL; for(int i= 0; i<j; i++) value = dict.GetObjectByKey(i); uint tiks_get=GetTickCount()-tiks_begin; printf((string)j+" elements. Add: "+(string)tiks_add+"; Get: "+(string)tiks_get); dict.Clear(); } }
このコードは連続的に辞書にエレメントを追加し、そのスピード測定を参照します。その後、各エレメントは DeleteObjectByKey() メソッドによって削除されます。GetTickCount() システム関数がスピードを測定します。
このスクリプトによって主要な3メソッドの時間依存性を表す図を作成します。
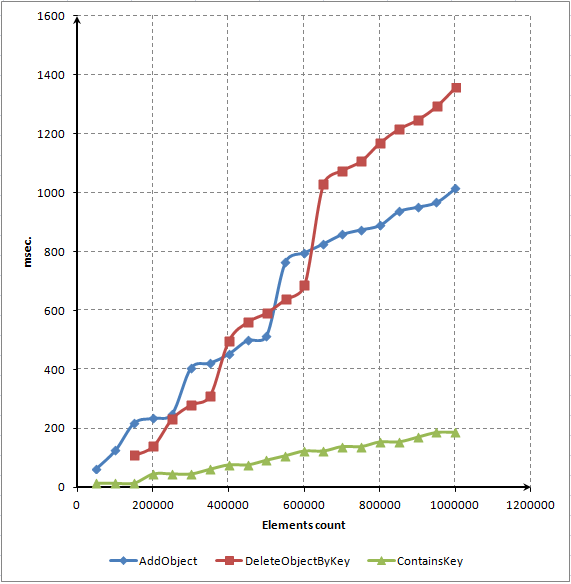
図7 エレメント数とメソッドの処理時間の依存関係を表すドット図(単位:ミリ秒)
ご覧のように、時間のほとんどはエレメント配置と辞書からの削除に費やされています。それでもなお、エレメントがもっと速く削除されると予想していました。コードプロファイラを用いてメソッドのパフォーマンスを改善してみようと思います。この手順については次のセクションで説明します。
ContainsKey() メソッドの図に着目します。これは線形です。それはランダムなエレメントへのアクセスは、配列内のエレメント数によらずおおよそ時間のある量を必要とすることを意味しています。これは実連想配列になくてはならない機能です。
あるエレメントへの平均アクセス時間と配列内エレメント数の依存性に関する図によってこの機能を説明します。
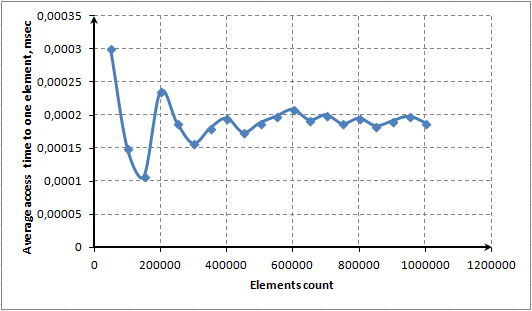
図8 ContainsKey() メソッドによる1エレメントへの平均アクセス時間
4.2. コードプロファイル自動メモリ管理に向けたスピード
コードプロファイリングはすべての関数の時間支出を計測する特殊な技術です。![]() in MetaEditor でクリックし いずれからのMQL5 プログラムを起動します。
in MetaEditor でクリックし いずれからのMQL5 プログラムを起動します。
同じことを行い、スクリプトをプロファイリングに送信します。しばらくすると、スクリプトが実行され、その間実行しているメソッドすべての時間プロファイルを取得します。下のスクリーンショットは時間のほとんどは3個のメソッド実行に費やされたことを示しています。それは、 AddObject()(時間の40%)、GetObjectByKey()(時間の7%)、DeleteObjectByKey()(時間の53%)です。
 関数内でのコードプロファイリング")
図9 OnStart() 関数内でのコードプロファイリング
DeleteObjectByKey() 呼び出しの 60% 以上が Compress() メソッドの呼び出しに費やされました。
ただこのメソッドはほとんど空で、主な時間は Resize() メソッドの呼び出しに遣われています。
それは以下をインクルードします。
CDictionary::Compress(void) { double koeff = m_array_size/(double)(m_total+1); if(koeff < 2.0 || m_total <= 4)return; Resize(); }
課題は明らかです。エレメントをすべて削除する際、Resize() メソッドが時々起動されます。このメソッドはストレージを動的に解放し配列サイズを減らします。
エレメントを迅速に削除したければこのメソッドを無効にします。たとえば、圧縮フラグを設定してクラスに殊なメソッド AutoFreeMemory() を取り入れることができます。それはデフォルトで設定されますが、その場合圧縮は自動的に行われます。もっとスピードを出したければ、適切に選択されたタイミングでマニュアルで圧縮を行います。このためには Compress() メソッドをパブリックにします。
圧縮が無効であれば、エレメントは3倍速く削除されます。
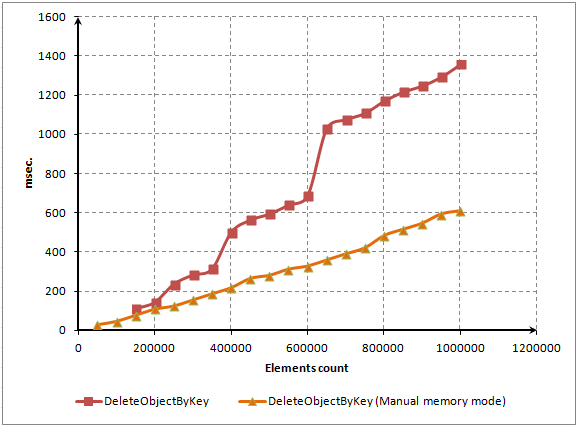
図10 占有ストレージの人的監視によるエレメント削除時間(比較)
Resize() メソッドはデータ圧縮だけでなくエレメントがありすぎてより大きな配列が必要な場合にも呼ばれます。 このときResize() メソッドの呼び出しは避けられません。それは将来長くスピードの遅い CList 連鎖を作成しなくてよいように呼び出す必要があります。ただし事前に必要な辞書ボリュームを指定することはできます。
たとえば、追加エレメント数は事前に知られていることがよくあります。エレメント数がわかっていると、辞書はまえもって必要なサイズの配列を作成し、配列に書き込んでいる最中にサイズ変更をする必要はなくなります。
このために必要なエレメントを受け入れるコンストラクタをもうひとつ追加します。
//+------------------------------------------------------------------+ //| Creates a dictionary with predefined capacity | //+------------------------------------------------------------------+ CDictionary::CDictionary(int capacity) { m_auto_free = true; Init(capacity); }
private Init() メソッドは主な処理を行います。
//+------------------------------------------------------------------+ //| Initializes the dictionary | //+------------------------------------------------------------------+ void CDictionary::Init(int capacity) { m_free_mode=true; int n=FindNextSimpleNumber(capacity); m_array_size=ArrayResize(m_array,n); m_index = 0; m_hash = 0; m_total=0; }
改良は行われました。ここでは最初に指定した配列サイズで AddObject() メソッドの評価を行います。このためにスクリプトの OnStart() 関数の最初の2つの文字列に変更を加えます。
void OnStart() { //--- CDictionary dict(END+1); dict.AutoFreeMemory(false); ... }
この場合、END は 1,000,000 エレメントという大きな数で表されます。
この改良は AddObject() メソッドのパフォーマンスを著しくはやめました。

図11 現在の配列サイズでエレメントを追加する時間
現実のプログラミングの課題を解決には、つねにメモリのフットプリントと実行スピードの間で選択が必要となります。メモリを解放するのにはひじょうに時間がかかります。しかしこの場合はもっと利用できるメモリがあります。すべてをそのままにするならCPU 時間は余分で複雑な計算課題に使用されることはありませんが、同時に使用できるメモリは少なくなります。コンテナを使用することで オブジェクト指向 プログラミングは特定の問題それぞれに対して特定の実行ポリシーを選択し、柔軟に CPU メモリとCPU 時間の間のリソースに割り当てることができます。
概してAll in all, CPU のパフォーマンスはメモリ容量よりもずっと悪いスケーリングとなります。ほとんどの場合メモリフットプリントよりも実行スピードを優先する理由はそれです。また通常タスクの有限状態を知らないため、ユーザーレベルでのメモリ管理は自動制御よりも効率的です。
たとえば、われわれのスクリプトでは、DeleteObjectByKey() メソッドはタスクの最後までにそれらをすべて削除するため、列挙の最後でトータルエレメント数がF null であるとあらかじめ分かっています。配列を自動で圧縮する必要がないのはそのためです。Compress() を呼んで一番最後に消去するので十分なのです。
そこで配列にエレメントを追加したり、配列からエレメントを削除する良好な直線目トリックがあれば、エレメント数に応じてエレメントを追加したり削除したりする平均時間を解析します。
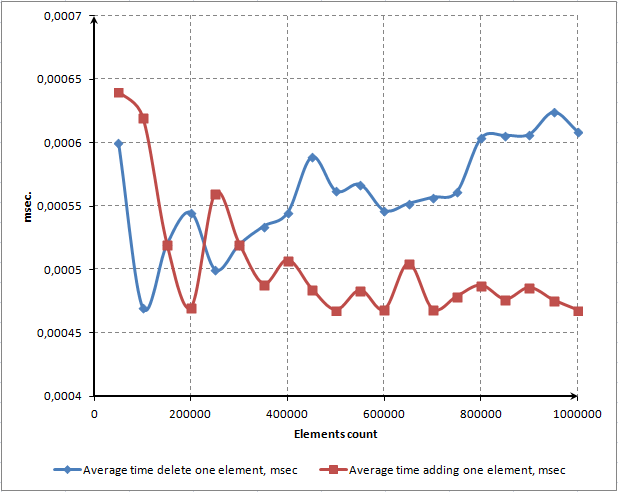
図12 1エレメントを追加または削除する平均時間
1エレメントを追加する平均時間はかなり定常で、配列内のトータルエレメント数に依存しないことが解ります。1エレメントの平均削除時間はわずかに上向きになり、それは好ましいものではありません。この結果をエラーの範疇として、また通常の傾向として扱うのか正確に言うことはできません。
4.3. CDictionary のパフォーマンスと標準的な CArrayObj との比較
もっとも興味深い検証を行う時がやってきました。われわれの CDictionary を標準的な CArrayObj クラスと比較するのです。構築段階における仮定サイズの指示のようなマニュアルでのメモリ割り当てについてのメカニズムは CArrayObj にはありません。それが CDictionary でのマニュアルのメモリ管理を無効にし、AutoFreeMemory() メカニズムを有効にする理由です。
各クラスのメリットとデメリットは第1章で述べています。CDictionary により未定義スポットにエレメントを追加することおよびひじょうに迅速に辞書からそのエレメントを抽出することができます。CArrayObj はエレメントすべての列挙をひじょうに速く行うことができます。ポインターによる移動という手段で行われるため CDictionary での列挙は遅く、この処理は直接のインデックス貼付よりも遅いものです。
ではやってみます。まず検証の新しいバージョンを作成します。
//+------------------------------------------------------------------+ //| TestSpeed.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Dictionary.mqh> #include <Arrays\ArrayObj.mqh> #define TEST_ARRAY #define BEGIN 50000 #define STEP 50000 #define END 1000000 //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CDictionary dict(END+1); dict.AutoFreeMemory(false); CArrayObj objects; for(int j=BEGIN; j<=END; j+=STEP) { //---------- ADD --------------// uint tiks_begin=GetTickCount(); for(int i=0; i<j; i++) { #ifndef TEST_ARRAY dict.AddObject(i,new CObject()); #else objects.Add(new CObject()); #endif } uint tiks_add=GetTickCount()-tiks_begin; //---------- GET --------------// tiks_begin=GetTickCount(); CObject *value=NULL; for(int i= 0; i<j; i++) { #ifndef TEST_ARRAY value = dict.GetObjectByKey(i); #else ulong hash = rand()*rand()*rand()*rand(); value = objects.At((int)(hash%objects.Total())); #endif } uint tiks_get=GetTickCount()-tiks_begin; //---------- FOR --------------// tiks_begin = GetTickCount(); #ifndef TEST_ARRAY for(CObject* node = dict.GetFirstElement(); node != NULL; node = dict.GetNextNode()); #else int total = objects.Total(); CObject* node = NULL; for(int i = 0; i < total; i++) node = objects.At(i); #endif uint tiks_for = GetTickCount() - tiks_begin; //---------- DEL --------------// tiks_begin = GetTickCount(); for(int i= 0; i<j; i++) { #ifndef TEST_ARRAY dict.DeleteObjectByKey(i); #else objects.Delete(objects.Total()-1); #endif } uint tiks_del = GetTickCount() - tiks_begin; //---------- SUMMARY --------------// printf((string)j+" elements. Add: "+(string)tiks_add+"; Get: "+(string)tiks_get + "; Del: "+(string)tiks_del + "; for: " + (string)tiks_for); #ifndef TEST_ARRAY dict.Clear(); #else objects.Clear(); #endif } }
これにはTEST_ARRAY マクロが使用されます。特定されると検証は CArrayObj で行われ、それ以外は CDictionary で行われます。新規エレメント追加に対する最初の検証は CDictionary の勝ちです。
この特定ケースではそれのメモリ割り当ての方法がより優れています。
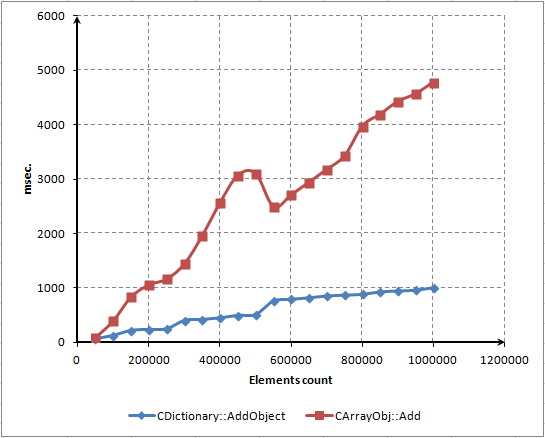
図13 CArrayObj および CDictionary に新規エレメント追加に費やす時間(比較)
CArrayObj での特定のメモリ割り当て方法によって処理速度が落ちているとあえて強調します。
それはソースコードの文字列1つでのみ説明されています。
new_size=m_data_max+m_step_resize*(1+(size-Available())/m_step_resize);
これはメモリ割り当ての線形アルゴリズムです。それは 16 エレメント書き込みごとにデフォルトで呼び出されます。CDictionary は指数関数的アルゴリズムを使用します。次のメモリ再割り当てごとに前回の呼び出しの二倍のメモリが割り当てられるというものです。この図は処理と使用メモリ間のジレンマを完璧に示しています。CArrayObj クラスのReserve() メソッドはより経済的でメモリは少なくてすみますが動作速度は遅くなります。CDictionary クラスの Resize() メソッドの速度はもっと速いですが、メモリを多く使います。そしてそのメモリの半分はまったく使われないままの可能性があります。
最終検証を行います。CArrayObj および CDictionary コンテナの完全列挙時間を計算します。CArrayObj は直接のインデクシングを、CDictionary は参照を使用します。CArrayObj によりそのインデックスによるどんなエレメントも参照することができますが、CDictionary ではインデックスによるあらゆるエレメントに対する参照は妨げられます。連続列挙は直接インデクシングと強く競合します。
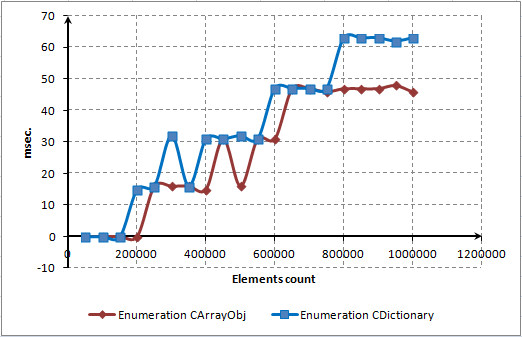
図14 CArrayObj および CDictionary の完全列挙時間
MQL5 言語開発者はすばらしい仕事をし参照を最適化しました。図で示されている直接インデクシングのスピードでひじょうに競争力があります。
エレメントの列挙にはそのくらいの時間しかかからず、ほとんど GetTickCount() 関数は必要ないくらいであることを理解することが重要です。それは15ミリ秒未満の時間間隔を計測するのには使いにくいものです。
4.4. CArrayObj、CList、 CDictionary 使用に際する一般的推奨事項
プログラム中に発生する主要なタスクとこれらタスクを経血するために知られるコンテナの機能を説明する表を作成します。
すぐれたタスク処理機能はグリーンで記載され、タスクを効率的に達成しない機能は赤で記載されています。
| 目的 | CArrayObj | CList | CDictionary |
|---|---|---|---|
| コンテナの末尾に新規エレメントを連続的に追加します。 | コンテナは新規エレメントのために新しいメモリを割り当てる必要があります。既存エレメントの新規インデックスへの転送は不要です。CArrayObj はこの処理をひじょうに迅速に行います。 | コンテナは1番目、現在、最終エレメントを記憶します。このため、新規エレメントはリスト末尾(記憶されている最終エレメント)にひじょうに速く追加されます。 | 辞書にはそのような『最初』や『最後』といったコンセプトがありません。新規エレメントはすばやく添付され、エレメント数には依存しません。 |
| インデックスによる任意のエレメントへのアクセス | 直接のインデクシングが行われるため、アクセスはひじょうに迅速で時間は O(1) しかかかりません。 | 各エレメントへのアクセスは前回エレメントすべての列挙を介して行われます。この処理にかかる時間は O(n) です。 | 各エレメントへのアクセスは前回エレメントすべての列挙を介して行われます。この処理にかかる時間は O(n) です。 |
| キーによる任意のエレメントへのアクセス | 不可 | 不可 | キーによりハッシュとインデックスを計算するのは効率的で速い処理です。ハッシュ関数の効率は文字列キーに対してはひじょうに重要です。この処理にかかる時間は O(n) です。 |
| 新規エレメントは未定義インデックスによって追加/削除されます。 | CArrayObj は新規エレメントのためにメモリを割り当てるだけでなく、挿入される追加されるエレメントのインデックスよりも高いエレメントのインデックスをすべて消去します。CArrayObj の処理が遅いのはこのためです。 | エレメントはひじょうに迅速にCList に追加またはから削除されますが、必要なインデックスには O(n) の間にアクセスします。これはスピードの遅い処理です。 |
CDictionary では、インデックスによるエレメントへのアクセスは CList list をもとに行われ、長い時間がかかります。ただ追加および削除はひじょうに高速です。 |
| 新規エレメントは未定義キーによって追加/削除されます。 | 不可 | 不可 | 新規エレメントはすべてCList に追加されるため、配列が追加/削除のたびにサイズ変更される必要がないので新規エレメントの追加と削除はひじょうに高速に行われます。 |
| 使用とメモリ管理 | 動的な配列のサイズ変更が必要です。これはリソースを大量に消費する処理で、長い時間 または 大量のメモリ のどちらかが必要となります。 | メモリ管理は行われません。各エレメントは適切なメモリ量を取ります。 | 動的な配列のサイズ変更が必要です。これはリソースを大量に消費する処理で、長い時間 または 大量のメモリ のどちらかが必要となります。 |
| エレメントの列挙ベクターの各メモリに対する処理 | エレメントへの直接インデクシングによるひじょうに高速な処理ただし列挙が逆順で行う必要が生じることもあります(たとえば最終エレメントを連続して削除する場合)。 | エレメントはすべて一度限り列挙するので、直接の参照は迅速な処理となるのです。 | エレメントはすべて一度限り列挙するので、直接の参照は迅速な処理となるのです。 |
第5章 辞書クラスのドキュメンテーション
5.1. エレメントへの追加、削除、アクセスの主要メソッド
5.1.1. AddObject() メソッド
は T Key により CObject type の新規エレメントを追加します。キーとして任意のベースタイプが使用可能です。
template<typename T> bool AddObject(T key,CObject *value);
パラメータ
- [in] key -ベースタイプ(string、ulong、char、enumなど)の一つによって表されるユニークキー
- [in] value -ベースタイプとして CObject を持つオブジェクト
戻り値
オブジェクトがコンテナに追加済みであれば真を、それ以外は偽を返します。追加されたオブジェクトのキーがすでにコンテナ内に存在すれば、メソッドは負の値を返し、オブジェクトは追加されません。
5.1.2. ContainsKey() メソッド
コンテナ内に T Key と同じキーを持つオブジェクトが存在するかどうか確認します。キーとして任意のベースタイプが使用可能です。
template<typename T> bool ContainsKey(T key);
パラメータ
- [in] key -ベースタイプ(string、ulong、char、enumなど)の一つによって表されるユニークキー
確認済みキーを持つオブジェクトがコンテナ内に存在すれば真を返します。それ以外は偽を返します。
5.1.3. DeleteObjectByKey() メソッド
現在のT Key によりオブジェクトを削除します。キーとして任意のベースタイプが使用可能です。
template<typename T> bool DeleteObjectByKey(T key);
パラメータ
- [in] key -ベースタイプ(string、ulong、char、enumなど)の一つによって表されるユニークキー
戻り値
現キーを持つオブジェクトが削除されていれば真を返します。現キーを持つオブジェクトが存在しない、または削除が失敗すれば、偽を返します。
5.1.4. GetObjectByKey() メソッド
現在のT Key によりオブジェクトを返します。キーとして任意のベースタイプが使用可能です。
template<typename T> CObject* GetObjectByKey(T key);
パラメータ
- [in] key -ベースタイプ(string、ulong、char、enumなど)の一つによって表されるユニークキー
戻り値
現キーに対応するオブジェクトを返します。現キーを持つオブジェクトが存在しなければ NULL を返します。
5.2. メモリ管理メソッド
5.2.1. CDictionary() コンストラクタ
ベースのコンストラクタは3エレメントのベース配列の初期サイズを持つオブジェクト CDictionary を作成します。
配列は辞書に書き込む、または辞書からエレメントを削除することで自動的に増加または圧縮されます。
CDictionary();
5.2.2. CDictionary(int capacity) コンストラクタ
このコンストラクタは 'capacity' に等しいベース配列の初期サイズを持つオブジェクト CDictionary を作成します。
配列は辞書に書き込む、または辞書からエレメントを削除することで自動的に増加または圧縮されます。
CDictionary(int capacity);
パラメータ
- [in] capacity -初期エレメント数
注意
初期化直後の配列サイズ限度を設定することで Resize() を呼ぶばなくてすみ、このため新規エレメント追加時の効率を高めます。
ただし、(AutoMemoryFree(true))を有効にしてエレメントを削除すると、コンテナは容量設定にかかわらず自動的に圧縮されることに注意が必要です。早期圧縮を避けるには、コンテナが完全に書き込まれたあと最初にオブジェクトを削除するか、それができなければ(AutoMemoryFree(false)) を無効にします。
5.2.3. FreeMode(bool mode) メソッド
コンテナ内のオブジェクト削除モードを設定します。
削除モードが有効であれば、オブジェクトが削除されたあと、「削除」コンテナも手順の対象となります。デストラクタがアクティブ化されそれは利用不可となります。削除モードが無効化されれば、オブジェクトのデストラクタがアクティブ化されず、プログラムのその他の地点から使用可能なままとなります。
void FreeMode(bool free_mode);
パラメータ
- [in] free_mode – object deletion mode indicator.
5.2.4. FreeMode() メソッド
コンテナ内オブジェクト削除インディケータを返します(FreeMode(bool mode)を参照ください)。
bool FreeMode(void);
戻り値
オブジェクトがコンテナから削除されたあと削除オペレータによって削除されると真を返します。それ以外は偽を返します。
5.2.5. AutoFreeMemory(bool autoFree) メソッド
は自動メモリ管理インディケータを設定します。自動メモリ管理はデフォルトで有効となっています。その場合、配列は自動で圧縮されます(大きなサイズから小さいサイズに変更されます)。無効であれば、配列は圧縮されません。それはプログラム実行スピードを飛躍的に高めます。リソースを大量に消費する Resize() メソッドが呼ばれる必要がないためです。ただしこの場合、配列サイズに目を配り、Compress() メソッドによりマニュアルで配列サイズを圧縮する必要があります。
void AutoFreeMemory(bool auto_free);
パラメータ
- [in] auto_free メモリ管理インディケータ-
戻り値
メモリ管理を有効にする必要があれば真を返し、自動で Compress() メソッドを呼びます。それ以外は偽を返します。
5.2.6. AutoFreeMemory() メソッド
自動メモリ管理モードが使用されているか特定し、インディケータを返します(FreeMode(bool free_mode) を参照ください)。
bool AutoFreeMemory(void);
戻り値
メモリ管理モードが使用されていると真を返します。それ以外は偽を返します。
5.2.7. Compress() メソッド
辞書を圧縮し、エレメントのサイズ変更を行います。配列は可能な場合のみ圧縮されます。
このメソッドは自動メモリ管理モードが無効な場合にのみ呼ばれます。
void Compress(void);
5.2.8. Clear() メソッド
辞書内のエレメントをすべて削除します。メモリ管理インディケータが有効であれば、削除されているエレメントそれぞれに対してデストラクタが呼ばれます。
void Clear(void);
5.3. 辞書を検索するメソッド
インディケータエレメントはすべて相互連携しています。新規エレメントはそれぞれ前のエレメントに連携しています。よって辞書内エレメントすべての連続的検索が可能となります。その場合、リンクリストによる参照が行われます。このセクションのメソッドは検索を促進し、辞書の反復をより便利なものとします。
辞書の検索中、次のようなコンストラクションを利用することが可能です。
for(CObject* node = dict.GetFirstNode(); node != NULL; node = dict.GetNextNode()) { // node means the current element of the dictionary. }
5.3.1. GetFirstNode() メソッド
辞書に追加される一番最初のエレメントを返します。
CObject* GetFirstNode(void);
戻り値
CObject タイプのオブジェクトに対してポインターを返します。それは当初辞書に追加されたものです。
5.3.2. GetLastNode() メソッド
辞書の最終エレメントを返します。
CObject* GetLastNode(void);
戻り値
CObject タイプのオブジェクトに対してポインターを返します。それは一番最後に辞書に追加されたものです。
5.3.3. GetCurrentNode() メソッド
現選択エレメントを返します。エレメントは事前に選択された辞書内で検索されるエレメントのメソッドの一つか、または辞書エレメント(ContainsKey()、GetObjectByKey())にアクセスするメソッドの一つです。
CObject* GetLastNode(void);
戻り値
CObject タイプのオブジェクトに対してポインターを返します。それは一番最後に辞書に追加されたものです。
5.3.4. GetNextNode() メソッド
現エレメントに続くエレメントを返します。現エレメントが最終または選択されたものでなければ NULL を返します。
CObject* GetLastNode(void);
戻り値
CObject タイプのオブジェクトに対してポインターを返します。それは現ポンターに続くものです。現エレメントが最終または選択されたものでなければ NULL を返します。
5.3.5. GetPrevNode() メソッド
現エレメントの前のエレメントを返します。現エレメントが最初または選択されたものでなければ NULL を返します。
CObject* GetPrevNode(void);
戻り値
CObject タイプのオブジェクトに対してポインターを返し ます。それは現ポンターの前のものです。現エレメントが最初または選択されたものでなければ NULL を返します。
おわりに
広範なデータコンテナの主な木城について考察してきました。各データコンテナはもっとも効率的な方法でその機能が問題を解決する場面で使用される必要があります。
通常の配列はエレメントに対する連続アクセスが問題解決に十分な場面で使用されます。辞書および関連する配列はエレメントアクセスにユニークキーが必要な場合に使用するのをお薦めします。リストは頻繁にエレメントの置換が行われる場合により適しています。:削除、挿入、新規エレメント追加です。
辞書によりすばらしいシンプルな方法で難しいアルゴリズム問題を解決することができます。その他のデータコンテナが追加の処理機能を必要とする場面では、辞書機能によりもっとも効率的な方法で既存のエレメントにアクセスすることができるようになります。たとえば、辞書を基に、OnChartEvent() タイプの各イベントが1~2個のグラフィカルエレメントを管理するクラスに配布されるイベントイベントモデルを作成することができます。このためには、各クラスインスタンスをこのクラスによって管理されるオブジェクト名に関連づければよいだけです。
辞書は汎用的なアルゴリズムであるため、ほとんどさまざまなフィールドで適用可能なのです。本稿ではその処理がアプリケーションを便利で効果的なものとするひじょうにシンプルで堅牢なアルゴリズムに基づいていることを明らかにしました。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/1334
 CCanvas クラスを知る透明なオブジェクトの描画方法
CCanvas クラスを知る透明なオブジェクトの描画方法
 HedgeTerminalAPIを利用して MetaTrader 5 で双方向トレードとポジションヘッジを行う - パート2
HedgeTerminalAPIを利用して MetaTrader 5 で双方向トレードとポジションヘッジを行う - パート2
 MQL5 クックブック:ОСО オーダー
MQL5 クックブック:ОСО オーダー
 HedgeTerminalパネルを利用して MetaTrader 5 で双方向トレードとポジションヘッジを行う - パート1
HedgeTerminalパネルを利用して MetaTrader 5 で双方向トレードとポジションヘッジを行う - パート1
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
一般的に正しく機能する必要はない。
連想配列から複数回削除を実行する正しい方法は、削除するキーの配列を収集し、キーごとに削除することです。
そこが問題で、この方法でも突然おかしなバグが発生する。明らかにエラーだ。調べてみます。
とりあえず、新しい辞書を作り、そこに削除する必要のない値を追加してください。それから古い辞書を消去してください。これで100%うまくいくでしょう。
さあ、始めよう:
1. 辞書バージョンをこの投稿に添付されているものに更新する。
2.要素を削除するテストスクリプトを実行する。
削除は2回に分けて行う:
DeleteCurrentObject() メソッドについて:
このメソッドは、ContainsKey() 関数と組み合わせてのみ使用する必要があります。このメソッドがパブリックとして利用可能な唯一の理由は、この場合、メソッド呼び出しによってポインタを再配置する時間を節約できるからです。つまり、典型的かつ唯一の使用例は、1.キーがあるかどうかをチェックする。
それは理解できるが、やはり不必要なボディワークだ。
技術的には、あなたが期待するようにワンパスで取り外すことは可能です。しかし、それは複雑でしょう。そのため、まだ2パスしかしていない。分散データ構造としての ディクショナリーの観点からは、2パス削除の方がより正統的なソリューションである。削除が逐次的であるように見えるのはユーザー・レベルだけで、実際にはすべてが異なる。パフォーマンスという点では、シングルパス削除は何のメリットももたらさない。利便性という点では、そうかもしれない。
技術的には、あなたが期待するようなワンパス除去は可能です。しかし、それは複雑です。そのため、まだ2パスしか行っていない。分散データ構造としての 辞書の観点からは、2パス削除の方がより正統的である。削除が逐次的であるように見えるのはユーザー・レベルだけで、実際にはすべてが異なる。パフォーマンスという点では、シングルパス削除は何のメリットももたらさない。利便性という点では、そうかもしれない。
ありがとう。
要素を削除して最後の要素に行こうとしたときにバグを見つけたようだ:
CDictionary.mqhのエラーになります:
'Dictionary.mqh'の無効なポインタ・ アクセス (463,9)
どなたか確認できますか?修正方法があれば教えてください。
500行目と501行目のポインタチェックの実装のバグでした。
内蔵のCheckPointer()を使って修正しました。