Не знаю. Для начала надо идентифицировать модель ВР. В ней могут быть тренды, циклы, шум, причем с разными параметрами - от рабочих до таких, в которых модель не работоспособна. Бокс рассматривает несколько моделей с разным набором параметров. Если взять хотя бы то, что он идентифицировал Бокс и для них посчитать Херста - это будет один и тот же херст или это будут разные, с разными величинами или алгоритмами. Я видел попытки посчитать Херста на нескольких форумах и в литературе. Ни одного работоспособного. Это навело на выше приведенные мысли.
_Forex19_>>: Добрый день!С большим вниманием читала данную ветку, так как интересуюсь данной тематикой, хотя в этих вопросах я еще новичок. В ходе своего исследования показателя Херста интересует реализация следующей задачи: необходимо определить эффективность индикатора iVAR, _hurst_classik для финансового ряда. Мое видение реализации данной задачи следующее: необходимо сделать индикатор, который бы на основе данных индикатора ZigZag, рассчитал расстояние d1 (количество баров) между двумя соседними точками (минимумам и максимумам), а также получить расстояние d2 (количество точек за соответствующий интервал), который дает индикатор iVAR(множество значений меньше 0,5 в случаи индекса вариации) и индикатор _hurst_classik (множество значений больше 0,5 в случаи показателя Херста ). В конечном итоге получить массив отношений d2/d1. Конечный результат представить в виде гистограммы. Надеюсь на этом сайте есть джентльмен - программисты на MQL4,которые помогут девушке в ее исследовании, буду рада любой помощи!За ранее огромное спасибо! PS: хотя индикатор ZigZag является трендовым, возможно какое-то программное решение с флэтом. Если существуют какие-то готовые инструменты для решение данной задачи, прошу их указать. Кроме того повторно выкладываю коды индикаторов iVAR и _hurst_classik.
using System;
using System.Collections.Generic;
using System.Text;
using System.Drawing;
using System.IO;
using WealthLab;
using WealthLab.Indicators;
namespace WealthLab.Strategies
{
publicclass PetersHerst : WealthScript
{
public StrategyParameter Period;
publicstring path = @"c:\Users\Василий\Documents\Wealth-Lab\Reports\Strategys\Herst\herst.csv";
public PetersHerst()
{
//StreamWriter sw = new System.IO.StreamWriter(path);
Period = CreateParameter("Period", 6, 6, 240, 1);
if(File.Exists(path))File.Delete(path);
}
protectedoverridevoid Execute()
{
int N = Period.ValueInt;
// Так как мы преобразуем исходный ряд в доходности, то количество наблюдений у нас будет на 1 меньше, чем баров на графике.// Отслеживаем, что бы количество отброшенных данных не превышало 6 наблюдений.// Если отбрашиваемых данных слишком много,то период выбран неудачно, и расчет R/S статистики для него не производится.int ost = Bars.Count - 1 - (int)Math.Floor((double)(Bars.Count-1)/N)*N;
if(ost > 6)
{
PrintDebug("Слишком много пропущенных данных (" + ost + "). Необходимо выбрать другой период.");
return;
}
//PrintDebug("Пропущенных данных для рассчета");
DataSeries Returns = new DataSeries("Returns");
DataSeries ret2price = new DataSeries("ret2proce");
// Расcчитываем логарифмические доходности// и собираем из них накопленный ряд.
Returns.Add(0.0, Date[0]);
double acum = 0.0;
for(int i = 1; i < Bars.Count; i++)
{
acum += Math.Log(Close[i]/Close[i-1]);
Returns.Add(Math.Log(Close[i]/Close[i-1]), Date[i]);
ret2price.Add(acum, Date[i]);
}
//ret2price.
PrintDebug(ret2price.Count);
if(Returns.Count < 1)return;
if(N > ret2price.Count)N = ret2price.Count;
double logRS = 0.0;
int count=0; //количество периодов
PrintDebug(Bars.Count);
for(int i = 0; i < ret2price.Count; i++)
{
//Делим ряд на K групп по N доходностей в каждойif((i+1)%N == 0)
{
count++;
if(i - N < 0)continue;
//Находим среднее значение sma или математическое ожидание доходностей за период kdouble sma = SMA.Value(i, ret2price, N);
//Находим стандартное отклонение за период kdouble S = StdDev.Value(i, ret2price, N, WealthLab.Indicators.StdDevCalculation.Sample);
//Находим накопленную разницу между текущим значением и средним.double s = 0.0;
DataSeries acum_div = new DataSeries("");
for(int k = i - N+1; k <= i; k++)
{
s += (ret2price[k] - sma);
//Не учитываем последнее значение, т.к. оно всегда будет равно нулю.//if(k!=i)
acum_div.Add(s);
//PrintDebug(Returns.Date[k].ToShortDateString() +"\tret: "+ Returns[k].ToString("F6") + "\tStd: " + S.ToString("F6") + "\t" + s.ToString("F6"));
}
double R = acum_div.MaxValue - acum_div.MinValue;
//Конечная оценка log(R/S)
logRS += Math.Log(R/S, 10);
//PrintDebug(Returns.Date[i].ToShortDateString() + "\t" + "SMA: " + sma.ToString("F6")// + "\tStd: " + S.ToString("F6") + "\tMaxV: " + acum_div.MaxValue.ToString("F6") +// "\tMinV: " + acum_div.MinValue.ToString("F6")// + "\tR: " + R.ToString("F6") + "\tlog(R/S): " + logRS.ToString("F6"));
}
}
logRS /= count;
double logPeriod = Math.Log(N, 10);
PrintDebug(logPeriod + "\t" + logRS + "\tCount:" + count);
if(count >= 2)
File.AppendAllText(@"c:\Users\Василий\Documents\Wealth-Lab\Reports\Strategys\Herst\herst.csv", logPeriod + "\t" + logRS + "\n");
}
}
}
Не знаю. Для начала надо идентифицировать модель ВР. В ней могут быть тренды, циклы, шум, причем с разными параметрами - от рабочих до таких, в которых модель не работоспособна. Бокс рассматривает несколько моделей с разным набором параметров. Если взять хотя бы то, что он идентифицировал Бокс и для них посчитать Херста - это будет один и тот же херст или это будут разные, с разными величинами или алгоритмами.
Я видел попытки посчитать Херста на нескольких форумах и в литературе. Ни одного работоспособного. Это навело на выше приведенные мысли.
という言葉の後に「実行可能なものは一つもない」と書かれていることに困惑しています。と文献にある」。文献にはさまざまなアプローチがあり、それぞれ微妙に異なる結果が得られているが、いずれも推定値であるため、驚くにはあたらない。しかし、サンプルが大きければ大きいほど、これらの推定値はより正確であるべきで、互いに「平等」であることもまた事実である。ただ、実行可能なハーストのアルゴリズムがフォーラムで見つけにくいという点には同意します。
アルゴリズムの入力に何を送り込むかについては、アルゴリズムは気にしない。価格を餌に、1つ前後のものを手に入れる。実際、アルゴリズムの本質については、価格は元の値から比較的離れたところに留まるため、強い長期記憶を持っている。飼料価格の増分は0.5程度で、相対的な変化が大きく、ほとんどランダムであるため、これも正当化されます。トレンドやサイクルを送り込む - 粘りを得る。ノイズは一般に指数を低下させる。なるほど、「我々の価格はノイジーなのか、それとも適正な市場価格なのか」という問いは、ハースト社のアルゴリズムの対象ではなく、別の領域なのですね。
Подскажите пожалуйста, каким образом в RS-анализе выбирается длина анализируемого ВР.
一般に、長ければ長いほど良いとされています。Petersの本のアルゴリズムによると、整数の約数の数が最も多い長さが良いそうです。
Подскажите пожалуйста, каким образом в RS-анализе выбирается длина анализируемого ВР.
2つのモデルが区別されます。
1.このプロセスは "安定した "ハースト指数を持っている。つまり、この指標は一定であり、時間的(プロセスの全存在期間)に変化することはない。この場合、その定義は最低限、統計的に有意なセグメント、すなわちプロセスの分布を確信を持って推定できるセグメントとされる。あるいは気にせず、できるだけ大きなセグメントで。
2.指標は何らかの関数で、非常に複雑な場合もあれば、ランダムな場合もある。この場合、BP長を選択する客観的な基準はない。一般的な場合の指数の推定は、時間領域でも周波数領域でも、超能力者でない限り不可能である。
重要なことは、RS分析は最も荒い手法の一つであり、その推定は常に偏りがあり、サンプルサイズは何の役にも立たないということである。Hurst 指数を正しく計算するには、ウェーブレットベースの推定を使用します(アルゴリズムは、例えば、mathlab で見つけることができます)。
Добрый день!С большим вниманием читала данную ветку, так как интересуюсь данной тематикой, хотя в этих вопросах я еще новичок. В ходе своего исследования показателя Херста интересует реализация следующей задачи: необходимо определить эффективность индикатора iVAR, _hurst_classik для финансового ряда.
Мое видение реализации данной задачи следующее: необходимо сделать индикатор, который бы на основе данных индикатора ZigZag, рассчитал расстояние d1 (количество баров) между двумя соседними точками (минимумам и максимумам), а также получить расстояние d2 (количество точек за соответствующий интервал), который дает индикатор iVAR(множество значений меньше 0,5 в случаи индекса вариации) и индикатор _hurst_classik (множество значений больше 0,5 в случаи показателя Херста ). В конечном итоге получить массив отношений d2/d1. Конечный результат представить в виде гистограммы.
Надеюсь на этом сайте есть джентльмен - программисты на MQL4,которые помогут девушке в ее исследовании, буду рада любой помощи!За ранее огромное спасибо!
PS: хотя индикатор ZigZag является трендовым, возможно какое-то программное решение с флэтом. Если существуют какие-то готовые инструменты для решение данной задачи, прошу их указать. Кроме того повторно выкладываю коды индикаторов iVAR и _hurst_classik.
価格のハーストは〜1ですが、ここでは何ですか?
この場合、私がお手伝いできるのは、_hurst_classikファイルにHearstやR/S解析がないことをご指摘いただくことだけです。R/S」という名前自体、行を再スケールすることがポイントです。しかし、_RS_Analizを気取る_hurst_classikはリマスタリングを行わず、例えば、最大価格と最小価格の差を些細に取っているのです。
さらに、R/S分析では、ハーストに到達するために、曲線の傾きを計算するが、そのためには、平面log(R/S) - log(n)上に1点ではなく、多くの点が必要である。この奇跡の_RS_Analizには、そんなものはない。
私の投稿の主旨は「BPモデルの特定」だったのですが、それが目に留まらなかったのですね。
ARFIMAクラスのモデルとかなら、投資ファンドの資金調達が目的の「ナキウサギ」が育っているので、本当に興味がないんです。このような「科学」は、既知の望ましい結果(通常は価格予測)のために科学的根拠を微調整するためだけに作られるため、アームチェア・サイエンスと呼ばれています。
ARFIMAクラスのモデルとかなら、投資ファンドの資金調達が目的の「ナキウサギ」が育っているので、本当に興味がないんです。このような「科学」は、意図的に望んだ結果(通常は価格予測)に科学的枠組みを当てはめるためだけに作られるため、内閣科学と呼ばれるのである。
試算はやめよう。今、BPモデルを使ったアプローチと、全く使わないアプローチの話があります。ヒアストインジケーターの計算を助けてください!!*。
*小言: ピータースのように
そうですね、尊敬する学者の男性から普通の野次馬までが、ハーストとは何か、それをどうカウントし解釈すべきかについて、それぞれの意見を持っているとは思ってもいませんでした。オリジナルに最も近いのは、論文や 書籍に 登場するエリック・ナイマンだ。でも...Petersの本で紹介されているようなグラフを作成するための適切なツールが、私たち(いわばロシア)にはまだないのです。
そこで私は,ピータースが彼の最初の著書「資本世界のカオスと秩序」で述べた,S&P500のR/S統計を計算する一連の手順をできるだけ忠実に模倣してみたのである。
1. 1950年1月1日から1988年7月1日までのS&P500の月足チャートを取り上げる。
2.それらをテクニカル分析プログラムに読み込ませる(私はWealthLabとC#を使用しています、ここからはWL/C#のコードを使用します)
3.Peters bookにある計算式を使って、価格をリターンに変換する: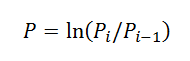
4.ピータース自身は、一度計算されたリターンが再び蓄積された系列に変換されることには触れていない。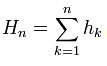 。しかし、これは、彼が持っているR/Sスプレッド値から明らかであり、さらに、ソースも 明確にそれを述べています。"各自然数nについて、値を合成し(上式参照)、得られた部分列の以下の数値特性を計算しよう"。
。しかし、これは、彼が持っているR/Sスプレッド値から明らかであり、さらに、ソースも 明確にそれを述べています。"各自然数nについて、値を合成し(上式参照)、得られた部分列の以下の数値特性を計算しよう"。
5.得られた系列をk個の期間に分割し、各期間の長さを6ヶ月から231ヶ月または観測値のNとする。
6.さて、ここで重要なポイントがあります。整数個の周期が得られない(未使用のデータが残る)場合は、破棄する。ただし、余りが大きすぎる場合(例:462÷232=233、余りに230)には、無効な値が得られる。私の理解では、Petersはシフトを使用していますが、これはプログラミング上非常に面倒なオプションで、私は単に残差が6より大きい場合はピリオドを破棄しています。隣接する期間はほぼ同じR/S値を持つので、これは正しい選択肢です。
7.そして、式によりRを算出する。
8.Rを標準偏差(WL指標で算出)で割り、対数:log10(R/S)とした。
9.現在の周期を対数化したもの:log10(N)。
10.得られた log10(N) に対する log10(R/S) の比率をファイルに書き込む。
オプティマイザーがNを6(Petersのような)から231(最小実験数は2)まで通した場合、両対数スケールの2列の表が得られます:1.期間 2.R/Sの値です。
ここからが一番面白いところです。この表をエクセルでプロットすると、次のようになります。
オリジナルは右のように紹介されています。ご覧のように、似ているところもありますが、やはり同じではありません。特に、最初の数値が若干過大評価されていること(約0.31に対して0.33)、また、本来はそうではないはずの最終値が突然大きく下がり始めていることがわかります。彼のグラフによると、シリーズの終わりには傾斜角だけが変化するはずで、メモリー効果が限定的であることを物語っている。
これまでは、この時点でやめていました。U/V統計は、オリジナルと一部しか重なっていないことを考えると、まだ適用を決めていないんです。
R/Sスコアをハーストに換算すると、やや膨らんだ結果にもなる。もしハーストの数字が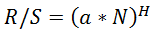 ここで、B1 は現在の R/S スコアです。
ここで、B1 は現在の R/S スコアです。
以下は、R/S統計量を計算するWL/C#のコードです。
p.s. 面白いことに、MQL4にはoverideやusingといったキーワードはありませんが、構文上ではまだハイライトされています:)Matcadでハースト指数を計算する方法はありますか(離散形式の計算式が必要)。
今のところ、これしか見つかっていません。
時系列解析のアプローチを記したファイルを添付。そこから、これらの数式を取り入れたのです。
もちろん、申し訳ありません。
面白いですか?これらの計算式を見る限り、FXに適用する意味はないように思います。
FXを説明するシリーズを描くのは簡単なんです。すでに世の中に出ていて、それでノーベル賞を受賞した人もいます。しかし、その結果は非常に平均的なものです。常に平均を最初に推定する必要がある - 誤差に関連して確率からマイナスを除去しようとする、そしてそれを気にすること。
もちろん、申し訳ありません。
では、面白いかどうか?計算式を見ると......FXに応用する意味が全くないですね。
FXを説明するようなシリーズを自分で投げかける方が簡単です。すでに存在し、人々はそれでノーベル賞を取りました。しかし、結果はとても、平均的なものです。まず、平均-誤差を推定することが常に必要であり、次に誤差に関連して確率からマイナスを取り除くようにし、それを気にすることである。
すみません。しかし、今後、このスレッドにくだらない雑感を書き込まない ことに同意しよう。ある人は「外為列伝」に、ある人はハーストの統計に興味を持つ。みんなに自分のスレッドを持たせてあげてください。
両対数スケールのCSV形式の表:推定R/Sをピリオドに貼っています。