Disa>>: понял. Я брал среднее геометрическое из High и Low. Сейчас посмотрю что будет на разнице. Я пока не могу решить что целесообразнее - брать код для MT4 и переделывать под Си или искать ошибки у себя ;) У меня данные это дневные бары(5ти минутки), всего их 78. Я точки стоил по значениям для 3,4...78и. - МТ4 моментально обсчитает 78 баров, даже до десятка тысяч считает быстро. А вот для каждого бара расчитывать Херста на многотысячной выборке - это уже долго, если баров тоже тыщи. Есть еще вроде вариант постоянного деления отрезка пополам. - не совсем представляю о чем вы, но если длина выборки - степень двойки, то да, работает. В любом случае предпочтительнее иметь выборку с длиной имеющей как можно больше делителей. Хм, а точки для которых разница Close[i+1]-Close[i] = 0 и среднеквадратичное отклонение 0, просто не рассматриваются при построении прямой? - (Close[i+1]-Close[i]) - это входные данные, прямая строится не по ним, а по коэффициентам, которые получаются из этих данных при R/S анализе. Еще есть мнение что подсчета коэффициента Херста нужно использовать не обычный МНК, а т.н. RANSAC( http://en.wikipedia.org/wiki/RANSAC ), т.к. при обычном МНК на коэффициент наклона прямой могут влиять точки, "выбивающиеся из общего числа", т.е. наиболее удаленные от общей массы. - Не представляю на основании какой модели, можно решить, что некоторые возвраты подлежат выбросу из выборки?
Disa>>: В общем давайте я расскажу свой алгоритм обсчета словами, а вы мне скажете пж где ошибка, а то мы так долго друг друга чуствую не поймем.
функция RS на вход принимает массив из Close[i]-Close[i-1] и число элементов массива 1. S[i-1] = Close[i]-Close[i-1] Для всех i от 0 до N 2. h[i] = log(S[i]/S[i-1]) - не стоит так делать, т.к. п.1 и п.2 в принципе одно и тоже в смысле подготовки данных для алгоритма. Действительно, вместо возвратов на вход можно подавать log(Close[i]/Close[i-1]), но подавать на вход логарифм отношения возвратов - это перебор, по-моему. Достаточно подавать что-нибудь одно - либо разницу цен, либо логарифм их отношений. 3. Hn = Сумма h[i] h_cp = ср.ариф. Hn 4. R = max(h[i] - h_cp) - min( h[i] - h_cp ) S = 1/n * (h[i] - h_cp) RS = R / S 5. Далее стою м-во точек со значением log RS(i) и log i для i от n_min до некоторого N и МНК стоют прямую
в п.3-5 для начала не вижу оператора или описания, что вся выборка делится на N кусков размером M, что для каждого этого куска считается rs = (максимум наращиваемой суммы отклонений от среднего - минимум наращиваемой суммы отклонений от среднего) / сумму квадратов отклонений от среднего, и все они, эти rs, складываются, а потом делятся на N. Теперь Log(RS) и log(N) - это одна точка для МНК, которых надо насобирать побольше, подбирая разные N и М так, чтобы N*M=длина выборки всегда. На мой взгляд, запись п.4 полностью неверна.
Ваш индикатор zHursttExponent.mq4 на вашем же тестовом файле brown72.txt выдает 0.1647. К чему бы это ? Насколько я понял, этот индикатор считает показатель Херста на каждом тике для последних 2520 баров и выдает значение на печать. Так ? А что тогда означают 4 буфера этого индикатора и зачем они нужны в отдельном окне ? И еще один вопрос.
Disa>>: Подниму ка тему) Спасибо Vita - написал win32api под c++ и все пашет как надо. Вопрос к людям которые часто применяли этот метод - есть какие-нибудь оценки погрешностей от числа входящих данных, дисперсии, корреляции и мб других стат.величин. Как я понял вообще смысла особого нет считать коэффициент для 78 величин - т.е для однодневного бара? Так же по прежнему не понимаю что делать если какие-то величины равны нулю. Ну например если на вход подаю разность цен - понятное дело что разность за 5ть минут мб меньше или равны 0, но log тогда не берется. У меня есть идея брать модуль величины в случае если она отрицательна(т.е абсолютную разницу) а в случае 0 не заносить это значение в ряд h.
また、セグメントを永久に半分に分割するオプションもあります。
ふむ、差分Close[i+1]-Close[i]=0、標準偏差0となる点は、単に直線を引くときに考慮しないだけなのか。
また、「総数のうち」、つまり総質量から最も離れた点が、通常のISCによる直線の傾き係数に影響を与える可能性があるため、通常のISCではなく、いわゆるRANSAC( http://en.wikipedia.org/wiki/RANSAC )でハースト係数を 算出すべきという意見もある。
понял. Я брал среднее геометрическое из High и Low. Сейчас посмотрю что будет на разнице. Я пока не могу решить что целесообразнее - брать код для MT4 и переделывать под Си или искать ошибки у себя ;) У меня данные это дневные бары(5ти минутки), всего их 78. Я точки стоил по значениям для 3,4...78и. - МТ4 моментально обсчитает 78 баров, даже до десятка тысяч считает быстро. А вот для каждого бара расчитывать Херста на многотысячной выборке - это уже долго, если баров тоже тыщи.
Есть еще вроде вариант постоянного деления отрезка пополам. - не совсем представляю о чем вы, но если длина выборки - степень двойки, то да, работает. В любом случае предпочтительнее иметь выборку с длиной имеющей как можно больше делителей.
Хм, а точки для которых разница Close[i+1]-Close[i] = 0 и среднеквадратичное отклонение 0, просто не рассматриваются при построении прямой? - (Close[i+1]-Close[i]) - это входные данные, прямая строится не по ним, а по коэффициентам, которые получаются из этих данных при R/S анализе.
Еще есть мнение что подсчета коэффициента Херста нужно использовать не обычный МНК, а т.н. RANSAC( http://en.wikipedia.org/wiki/RANSAC ), т.к. при обычном МНК на коэффициент наклона прямой могут влиять точки, "выбивающиеся из общего числа", т.е. наиболее удаленные от общей массы. - Не представляю на основании какой модели, можно решить, что некоторые возвраты подлежат выбросу из выборки?
(Close[i+1]-Close[i]) = 0 => log(d[i]/d[i-1]) = INF - これをどうすればいいのか理解できない。 RS = R/S - で、S = 0 のとき、R = 0 も想定してどう計算するのか? となると、また log(R) = INF で、またまたよくわからなくなる。オッケーです。以下は簡単な例です - 係数 H
と、与えられた区間上のすべての i に対して (Close[i+1]-Close[i]) = const とした場合、どのようになりますか?
どのモデルに基づいて、いくつかのリターンをサンプルから除外することを決定できるのか、まったくわかりません。- 例えば、在庫データストリームのいくつかの値に誤りがあった場合(14.4ではなく54.5 )。
関数 RS は、入力として Close[i]-Close[i-1] の配列と配列の要素 数を受け取ります。
1.S[i-1] = Close[i]-Close[i-1] For all i from 0 to N
2. h[i] = log(S[i]/S[i-1])
3. hn = h[i] の総和 h_cp = 算術。Hn
4. R = max(h[i] - h_cp) - min( h[i] - h_cp ) S = 1/n * (h[i] - h_cp) RS = R / S
、5.そして、n_minからあるNまでのiについて、log RS(i)とlog iの値を持つm-n個の点を立て、MNCは直線を立てる。
В общем давайте я расскажу свой алгоритм обсчета словами, а вы мне скажете пж где ошибка, а то мы так долго друг друга чуствую не поймем.
функция RS на вход принимает массив из Close[i]-Close[i-1] и число элементов массива
1. S[i-1] = Close[i]-Close[i-1] Для всех i от 0 до N
2. h[i] = log(S[i]/S[i-1]) - не стоит так делать, т.к. п.1 и п.2 в принципе одно и тоже в смысле подготовки данных для алгоритма. Действительно, вместо возвратов на вход можно подавать log(Close[i]/Close[i-1]), но подавать на вход логарифм отношения возвратов - это перебор, по-моему. Достаточно подавать что-нибудь одно - либо разницу цен, либо логарифм их отношений.
3. Hn = Сумма h[i] h_cp = ср.ариф. Hn
4. R = max(h[i] - h_cp) - min( h[i] - h_cp ) S = 1/n * (h[i] - h_cp) RS = R / S
5. Далее стою м-во точек со значением log RS(i) и log i для i от n_min до некоторого N и МНК стоют прямую
в п.3-5 для начала не вижу оператора или описания, что вся выборка делится на N кусков размером M, что для каждого этого куска считается rs = (максимум наращиваемой суммы отклонений от среднего - минимум наращиваемой суммы отклонений от среднего) / сумму квадратов отклонений от среднего, и все они, эти rs, складываются, а потом делятся на N. Теперь Log(RS) и log(N) - это одна точка для МНК, которых надо насобирать побольше, подбирая разные N и М так, чтобы N*M=длина выборки всегда. На мой взгляд, запись п.4 полностью неверна.
私の理解では、78の値に対して係数を計算することは意味がありません - すなわち、1日の棒のために?また、いくつかの値がゼロに等しい場合の処理もまだ理解していない。例えば、価格差を入力すると、5分後の差が0以下になる可能性があることは明らかですが、その場合はログが取られないのです。負の値(差の絶対値)の場合はそのモジュラスを取り、0の場合は系列hにこの値を入力しないというアイデアがあるのです。
テストファイルそのもの。H~0.72
テストファイルbrown72.txtで、zHursttExponent.mq4が 0.1647と表示されています。これはどういうことですか?
私が理解した限りでは、このインジケータは過去2520本のバーの各ティックについてハースト値を計算し、それをプリントアウトするものです。そうなんですか?
では、この指標の4ビンは何を意味し、何のために別ウィンドウで表示する必要があるのでしょうか?
そしてもう一つ質問です。
for(int i=0; i<limit; i++)
{
}
//---- done
インジケーターのコードにあるこの部分は何を意味するのでしょうか?
Ваш индикатор zHursttExponent.mq4 на вашем же тестовом файле brown72.txt выдает 0.1647. К чему бы это ?
Насколько я понял, этот индикатор считает показатель Херста на каждом тике для последних 2520 баров и выдает значение на печать. Так ?
А что тогда означают 4 буфера этого индикатора и зачем они нужны в отдельном окне ?
И еще один вопрос.
for(int i=0; i<limit; i++)
{
}
//---- done
Какой смысл имеет этот кусок в коде индикатора ?
1.あなたの結果=0.1647を繰り返すことはできません。私のはこんな感じ(=0.7241)です。
2) そうです、このインディケータは過去2,520本のティック毎にハースト指数を考慮し、値を表示し、r/sポイント(白線)を引き、その上に近似直線(赤線)を引き、その傾きが求めた指数となります-分かりやすくするため、しかし私にとっては-アルゴリズムの正確さを定性的に視覚的に見積もるためです。cRSGraphic = true の場合はすべて当てはまり、それ以外の場合は過去 250 本のバーのハースト指数を考慮します。
3. 4つのバッファは見かけ上の冗長性で、デバッグやテストをしていた頃の名残りです。
4.空のループ - 項目 3 と同じ問題です。
Подниму ка тему) Спасибо Vita - написал win32api под c++ и все пашет как надо. Вопрос к людям которые часто применяли этот метод - есть какие-нибудь оценки погрешностей от числа входящих данных, дисперсии, корреляции и мб других стат.величин.
Как я понял вообще смысла особого нет считать коэффициент для 78 величин - т.е для однодневного бара? Так же по прежнему не понимаю что делать если какие-то величины равны нулю. Ну например если на вход подаю разность цен - понятное дело что разность за 5ть минут мб меньше или равны 0, но log тогда не берется. У меня есть идея брать модуль величины в случае если она отрицательна(т.е абсолютную разницу) а в случае 0 не заносить это значение в ряд h.
ここでは、その誤差をカウントしたバリエーションを紹介します。残念ながら、私はこの不思議のCソースを盗んだ場所を見つけることができませんが、それはフェダーE.フラクタルによってカウントすることを主張している。彼の場合、同じファイルに対してTest H=0.6807。悪くはないように思えるが。
78の価値観の場合、それが一番難しい。半端な観測値でHurstを推定する方法については、多くの研究がなされています。計算を理解しなくても、著者によって非常に異なる結果が得られるのです。何も驚くことはない。インジケーターの数だけアルゴリズムがある :)0.5はエラーチャネル(cRSGraphic=falseの赤い線)のちょうど中間に位置しているので、現時点では一貫性があるのかないのか。
入力は価格差か価格比の対数のどちらかであること。
1.あなたの結果=0.1647を繰り返すことはできません。私のはこんな感じ(=0.7241)です。
brown72.txtというファイルが添付されていますね。しかし、あなたのインジケータは、ファイルbrown72.csvでテストしています。他に方法がなかったので、ただ名前を変えて \expertsfiles フォルダに入れました。その結果がこちらです。
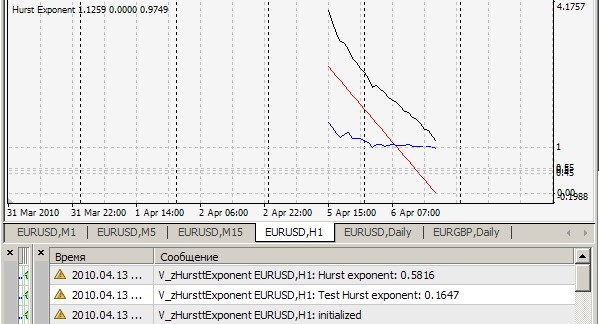
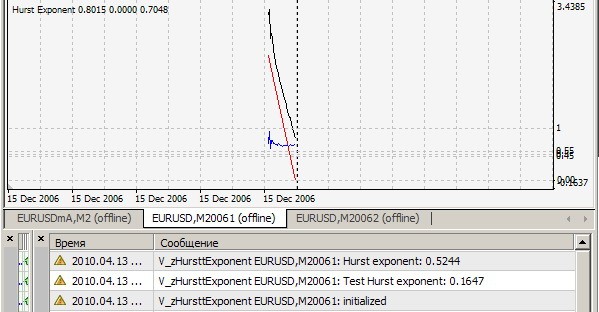
H1について。
ダニについて。
ファイルには1024個の値が含まれています。そのうちの最初の4つを紹介します。
45.47422
42.55601
46.5188
41.61502