トレーディングにおける機械学習:理論、モデル、実践、アルゴトレーディング - ページ 851 1...844845846847848849850851852853854855856857858...3399 新しいコメント СанСаныч Фоменко 2018.04.21 17:16 #8501 elibrarius: 2 クラス ロード 1 コア 設定 , rfeControl = rfeControl(number = 1,repeats = 1) - 10-15 分に短縮されました。結果の変化 - 2組の予測変数が入れ替わったが、全体的にはデフォルトのものと同様である。そうですね、あなたの10分1芯は私の2分4芯、2分は思い出せませんね。 私は何時間も待つことはありません。10~15分待ってもダメなら、何かが間違っているのですから、それ以上時間をかけても意味がないのです。何時間もかかるモデルを作るときに最適化を行うのは、モデルはできるだけ粗く、どんな場合でもできるだけ正確であるべきだというモデリングの思想を完全に理解していないことになる。 さて、予測変数の選択について です。 なぜ、このようなことをするのか、その理由は?どのような問題を解決しようとしているのですか? 選考で最も重要なのは、再教育の問題を解決しようとすることです。もしそうでなければ、予測変数の数を減らすことによって、学習速度を上げることができます。しかし、数を減らすには、主成分を分離する方がはるかに効果的です。これらは何も影響を与えませんが、予測変数の数を1桁減らすことができ、結果的にモデルフィッティングの速度を上げることができます。 では、そもそも:なぜ必要なのか? Forester 2018.04.21 17:22 #8502 Dr.トレーダーもう一つ、予測因子を選別するための面白いパッケージを見つけました。FSelectorと呼ばれるものです。予測因子を選別する方法として、エントロピーを含む約12種類の方法が用意されています。 予測因子とターゲットのファイルをここから持ってきました -https://www.mql5.com/ru/forum/86386/page6#comment_2534058 それぞれの方法で予測器を評価した結果を、最後にグラフで示しました。 青が良い、赤が悪い(corrplotの結果は[-1:1]にスケーリングされ、正確な評価はcfs(targetFormula, trainTable), chi.squared(targetFormula, trainTable) などの結果を見てください)。 X3、X4、X5、X19、X20は、ほぼすべての手法で良好な評価を受けていることがわかりますので、まずはこれらから始めて、さらに追加・削除を試みてください。 しかし、RattleのモデルはRat_DF2上でこれら5つの予測変数のテストに合格せず、再び奇跡は起きなかった。つまり、残りの予測変数の場合でも、モデルのパラメータを調整し、クロスバリデーションを行い、予測変数の追加や削除を自分で行う必要があります。ウラジミールさんの記事のデータを使って、CORElearnで同じことをやってみたんです。 列の平均を計算し(最下段はAverage)、それでソートしています。その方が、トータルの重要性を認識しやすいのです。 1.6分で、37個のアルゴリズムが動作しました。 このスピードは、Caret(16分)よりもはるかに優れており、同様の結果が得られました。 Mihail Marchukajtes 2018.04.21 17:50 #8503 エリブラリウスウラジミールさんの記事のデータを使って、CORElearnで同じことをやってみたんです。 列ごとの平均(最下段のAverage)を計算し、それでソートしています。その方が、トータルの重要性を認識しやすいのです。 1.6分で、37のアルゴリズムが必要でした。で、肝心の中身はというと......。予測因子の重要性についての質問に答えたかどうか、この絵がちょっと理解できないので。 私の場合は、予測因子を選んで、その上で10個のモデルを作り、相互情報によって最もよく機能するものを選ぶという方法で、モデルの構築と選択には全く問題がないのです。どうすればいいか知っていますか?精神的な挑戦です!!!よし、解けた人は最高だ!!!! なんとかモデル一式を手に入れることができました。そして、実際にvporez:どのモデルがうまくいっているのか、その理由は? というか、全部動くんだけど、1つしかダイヤルできないんです。その理由は? Forester 2018.04.21 18:08 #8504 Mihail Marchukajtes: で、肝心の中身はというと......。予測因子の重要性についての質問に答えたかどうか、この絵がちょっと理解できないので。私の場合は、予測因子を選んで、その上で10個のモデルを作り、相互情報によって最もよく機能するものを選ぶという方法で、モデルの構築と選択には全く問題がないのです。どうすればいいか知っていますか?精神的な挑戦です!!!よし、解けた人は最高だ!!!!なんとかモデル一式を手に入れることができました。そして、実際にvporez:どのモデルがうまくいっているのか、その理由は?というか、全部動くんだけど、1個だけダイヤルできる。その理由は?Vtreat は予測因子を非常に類似してソートする(最初に重要) 5 1 7 11 4 10 3 9 6 2 12 8 そして、CORElearnでの平均値による並べ替えは以下の通りです。 5 1 7 11 9 4 3 6 10 2 8 12 わざわざ予測因子選択 パッケージを増やすことはないと思います。 だからVtreatで十分なんです。ただし、予測変数の交互作用は考慮されていない。おそらくそうでしょう。 Maxim Dmitrievsky 2018.04.21 18:16 #8505 相場の歴史の一部分に対して、プレディクターの重要性を何度も取り上げているのを見ると、涙が出そうになりますね。なぜかというと、統計手法を冒涜しているからです。 Forester 2018.04.21 18:22 #8506 マキシム・ドミトリエフスキー 相場の歴史の一部について、予測器の重要性を取り上げ続けているのを見ると、涙が出そうになりますね。なぜかというと、統計手法を冒涜しているからです。 実際に確認したところ、予測値2をNSに投入すると、誤差が30%から50%近くまで上昇することがわかりました。 Maxim Dmitrievsky 2018.04.21 18:23 #8507 エリブラリウス 実際に確認したところ、予測値2をNSに投入した場合、誤差が30%から50%近くまで上昇することが確認されたとOOSでは、エラーはどのように変化するのでしょうか? Forester 2018.04.21 18:30 #8508 マキシム・ドミトリエフスキーOOSでのエラーはどのように変化するのでしょうか? と同様です。ウラジミールの記事と同じように、データはそちらからです。 Maxim Dmitrievsky 2018.04.21 18:31 #8509 エリブラリウス と同様です。ウラジミールの記事と同じように、データはそちらからです。別のOOSにある場合はどうするのですか? Yuriy Asaulenko 2018.04.21 18:32 #8510 elibrarius: 実際に確認してみると、2番の予測器をNSに投入すると、誤差が30%から50%近くまで上昇することがわかりました。予測因子を吐き出し、正規化した時系列を NSに供給する。NSは予測因子そのものを見つける - +1-2層、そしてここにある。 1...844845846847848849850851852853854855856857858...3399 新しいコメント 取引の機会を逃しています。 無料取引アプリ 8千を超えるシグナルをコピー 金融ニュースで金融マーケットを探索 新規登録 ログイン スペースを含まないラテン文字 このメールにパスワードが送信されます エラーが発生しました Googleでログイン WebサイトポリシーおよびMQL5.COM利用規約に同意します。 新規登録 MQL5.com WebサイトへのログインにCookieの使用を許可します。 ログインするには、ブラウザで必要な設定を有効にしてください。 ログイン/パスワードをお忘れですか? Googleでログイン
2 クラス
ロード 1 コア
設定 , rfeControl = rfeControl(number = 1,repeats = 1) - 10-15 分に短縮されました。結果の変化 - 2組の予測変数が入れ替わったが、全体的にはデフォルトのものと同様である。
そうですね、あなたの10分1芯は私の2分4芯、2分は思い出せませんね。
私は何時間も待つことはありません。10~15分待ってもダメなら、何かが間違っているのですから、それ以上時間をかけても意味がないのです。何時間もかかるモデルを作るときに最適化を行うのは、モデルはできるだけ粗く、どんな場合でもできるだけ正確であるべきだというモデリングの思想を完全に理解していないことになる。
さて、予測変数の選択について です。
なぜ、このようなことをするのか、その理由は?どのような問題を解決しようとしているのですか?
選考で最も重要なのは、再教育の問題を解決しようとすることです。もしそうでなければ、予測変数の数を減らすことによって、学習速度を上げることができます。しかし、数を減らすには、主成分を分離する方がはるかに効果的です。これらは何も影響を与えませんが、予測変数の数を1桁減らすことができ、結果的にモデルフィッティングの速度を上げることができます。
では、そもそも:なぜ必要なのか?
もう一つ、予測因子を選別するための面白いパッケージを見つけました。FSelectorと呼ばれるものです。予測因子を選別する方法として、エントロピーを含む約12種類の方法が用意されています。
予測因子とターゲットのファイルをここから持ってきました -https://www.mql5.com/ru/forum/86386/page6#comment_2534058
それぞれの方法で予測器を評価した結果を、最後にグラフで示しました。
青が良い、赤が悪い(corrplotの結果は[-1:1]にスケーリングされ、正確な評価はcfs(targetFormula, trainTable), chi.squared(targetFormula, trainTable) などの結果を見てください)。
X3、X4、X5、X19、X20は、ほぼすべての手法で良好な評価を受けていることがわかりますので、まずはこれらから始めて、さらに追加・削除を試みてください。
しかし、RattleのモデルはRat_DF2上でこれら5つの予測変数のテストに合格せず、再び奇跡は起きなかった。つまり、残りの予測変数の場合でも、モデルのパラメータを調整し、クロスバリデーションを行い、予測変数の追加や削除を自分で行う必要があります。
ウラジミールさんの記事のデータを使って、CORElearnで同じことをやってみたんです。
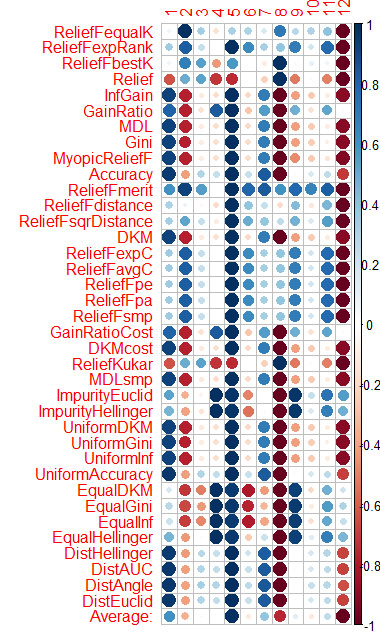
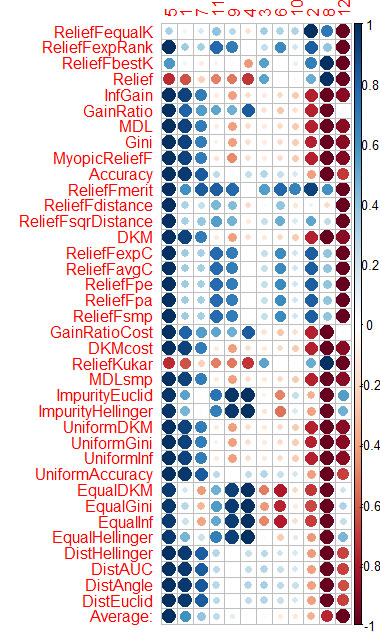
列の平均を計算し(最下段はAverage)、それでソートしています。その方が、トータルの重要性を認識しやすいのです。
1.6分で、37個のアルゴリズムが動作しました。 このスピードは、Caret(16分)よりもはるかに優れており、同様の結果が得られました。
ウラジミールさんの記事のデータを使って、CORElearnで同じことをやってみたんです。
列ごとの平均(最下段のAverage)を計算し、それでソートしています。その方が、トータルの重要性を認識しやすいのです。
1.6分で、37のアルゴリズムが必要でした。
で、肝心の中身はというと......。予測因子の重要性についての質問に答えたかどうか、この絵がちょっと理解できないので。
私の場合は、予測因子を選んで、その上で10個のモデルを作り、相互情報によって最もよく機能するものを選ぶという方法で、モデルの構築と選択には全く問題がないのです。どうすればいいか知っていますか?精神的な挑戦です!!!よし、解けた人は最高だ!!!!
なんとかモデル一式を手に入れることができました。そして、実際にvporez:どのモデルがうまくいっているのか、その理由は?
というか、全部動くんだけど、1つしかダイヤルできないんです。その理由は?
で、肝心の中身はというと......。予測因子の重要性についての質問に答えたかどうか、この絵がちょっと理解できないので。
私の場合は、予測因子を選んで、その上で10個のモデルを作り、相互情報によって最もよく機能するものを選ぶという方法で、モデルの構築と選択には全く問題がないのです。どうすればいいか知っていますか?精神的な挑戦です!!!よし、解けた人は最高だ!!!!
なんとかモデル一式を手に入れることができました。そして、実際にvporez:どのモデルがうまくいっているのか、その理由は?
というか、全部動くんだけど、1個だけダイヤルできる。その理由は?
Vtreat は予測因子を非常に類似してソートする(最初に重要)
5 1 7 11 4 10 3 9 6 2 12 8
そして、CORElearnでの平均値による並べ替えは以下の通りです。
5 1 7 11 9 4 3 6 10 2 8 12
わざわざ予測因子選択 パッケージを増やすことはないと思います。
だからVtreatで十分なんです。ただし、予測変数の交互作用は考慮されていない。おそらくそうでしょう。
相場の歴史の一部について、予測器の重要性を取り上げ続けているのを見ると、涙が出そうになりますね。なぜかというと、統計手法を冒涜しているからです。
実際に確認したところ、予測値2をNSに投入した場合、誤差が30%から50%近くまで上昇することが確認された
とOOSでは、エラーはどのように変化するのでしょうか?
OOSでのエラーはどのように変化するのでしょうか?
と同様です。ウラジミールの記事と同じように、データはそちらからです。
別のOOSにある場合はどうするのですか?
実際に確認してみると、2番の予測器をNSに投入すると、誤差が30%から50%近くまで上昇することがわかりました。
予測因子を吐き出し、正規化した時系列を NSに供給する。NSは予測因子そのものを見つける - +1-2層、そしてここにある。