Y a-t-il un modèle dans ce chaos ? Essayons de le trouver ! Apprentissage automatique sur l'exemple d'un échantillon spécifique.
En fait, je suggère de télécharger le fichier à partir du lien. Il y a 3 fichiers csv dans l'archive :
- train.csv - l'échantillon sur lequel vous devez vous entraîner.
- test.csv - échantillon auxiliaire, il peut être utilisé pendant la formation, y compris fusionné avec train.
- exam.csv - un échantillon qui ne participe en aucune façon à la formation.
L'échantillon lui-même contient 5581 colonnes avec des prédicteurs, la cible dans 5583 colonne "Target_100", les colonnes 5581, 5582, 5584, 5585 sont auxiliaires et contiennent :
- 5581 colonne "Time" - date du signal
- 5582 colonne "Target_P" - direction de l'opération "+1" - achat / "-1" - vente
- 5584 colonne "Target_100_Buy" - résultat financier de l'achat
- 5585 colonne "Target_100_Sell" - résultat financier de la vente.
L'objectif est de créer un modèle qui "gagnera" plus de 3000 points sur l'échantillon exam.csv.
La solution doit être trouvée sans avoir recours à l'examen, c'est-à-dire sans utiliser les données de cet échantillon.
Pour maintenir l'intérêt, il est souhaitable d'expliquer la méthode qui a permis d'obtenir un tel résultat.
Les échantillons peuvent être transformés comme vous le souhaitez, y compris en changeant la cible, mais vous devez expliquer l'essence de la transformation, afin qu'il ne s'agisse pas d'un ajustement pur et simple à l'échantillon de l'examen.
L'entraînement de ce qui est appelé out of the box avec CatBoost, avec les paramètres ci-dessous - avec Seed brute force donne cette distribution de probabilité.
FOR %%a IN (*.) DO ( catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_8\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 8 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_16\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 16 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_24\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 24 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_32\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 32 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_40\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 40 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_48\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 48 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_56\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 56 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_64\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 64 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_72\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 72 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_80\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 80 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 )
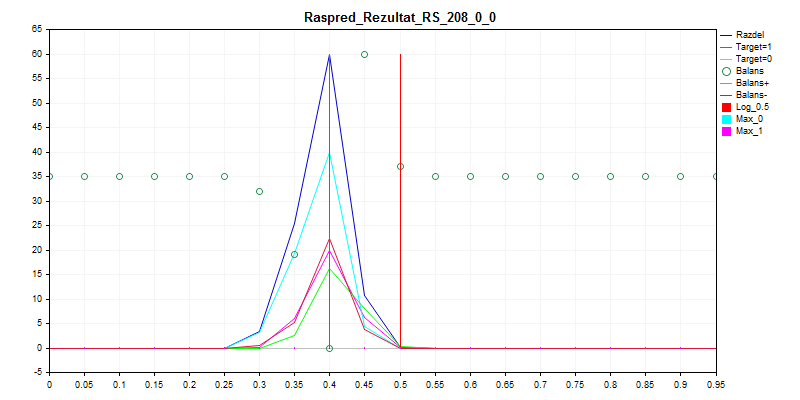
1. Train d'échantillonnage

2. Test d'échantillonnage
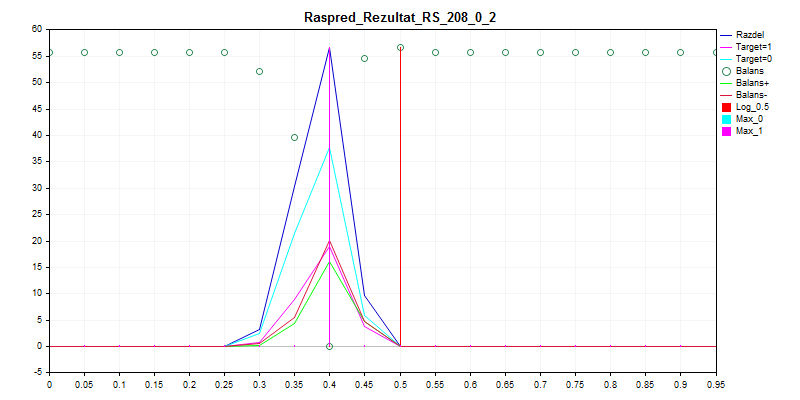
3. Échantillon d'examen
Comme vous pouvez le constater, le modèle préfère classer tout ou presque par zéro - il y a donc moins de risques de se tromper.
Les 4 dernières colonnes
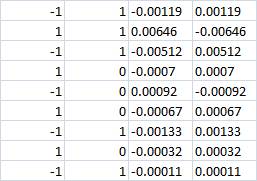
Avec 0 classe apparemment la perte devrait être dans les deux cas ? C'est-à-dire -0,0007 dans les deux cas. Ou si le pari achat|vente est toujours fait, ferons-nous un profit dans la bonne direction ?
Les 4 dernières colonnes
Avec 0 classe apparemment la perte devrait être dans les deux cas ? C'est-à-dire -0,0007 dans les deux cas. Ou si le pari achat|vente est toujours fait, ferons-nous un profit dans la bonne direction ?
Avec un grade zéro, il ne faut pas entrer dans la transaction.
J'avais l'habitude d'utiliser 3 cibles - c'est pourquoi les deux dernières colonnes ont des résultats fin au lieu d'un, mais avec CatBoost j'ai dû passer à deux cibles.
La direction 1/-1 est sélectionnée par une logique différente, c'est-à-dire que le MO n'est pas impliqué dans la sélection de la direction ? Il suffit d'apprendre le 0/1 trade/no trade (lorsque la direction est choisie de manière rigide) ?
Oui, le modèle ne fait que décider d'entrer ou de ne pas entrer. Cependant, dans le cadre de cette expérience, il n'est pas interdit d'apprendre un modèle avec trois cibles, pour cela il suffit de transformer la cible en tenant compte de la direction d'entrée.
Si la classe est égale à zéro, ne saisissez pas la transaction.
Auparavant, j'utilisais 3 cibles - c'est pourquoi les deux dernières colonnes contiennent un résultat financier au lieu d'un seul, mais avec CatBoost, j'ai dû passer à deux cibles.
Oui, le modèle ne fait que décider d'entrer ou non dans la transaction. Cependant, dans le cadre de cette expérience il n'est pas interdit d'enseigner le modèle avec trois cibles, pour cela il suffit de transformer la cible en tenant compte de la direction d'entrée.
Si la classe est égale à zéro, ne saisissez pas la transaction.
Auparavant, j'utilisais 3 cibles - c'est pourquoi les deux dernières colonnes contiennent un résultat financier au lieu d'un seul, mais avec CatBoost, j'ai dû passer à deux cibles.
Oui, le modèle ne fait que décider d'entrer ou non dans la transaction. Cependant, dans le cadre de cette expérience il n'est pas interdit d'enseigner le modèle avec trois cibles, pour cela il suffit de transformer la cible en tenant compte de la direction d'entrée.
Catbusta est multiclasse, il est étrange d'abandonner 3 classes
Par exemple, si à la classe 0 (ne pas entrer) la direction correcte de la transaction est choisie, il y aura un bénéfice ou non ?
Il n'y aura pas de profit (si vous procédez à une réévaluation, il y aura un petit pourcentage de profit à zéro).
Il est possible de refaire l'objectif correctement uniquement en divisant "1" en "-1" et "1", sinon il s'agit d'une stratégie différente.
C'est le cas, mais il n'y a pas d'intégration dans MQL5.
Il n'y a pas de déchargement de modèle dans aucun langage.
Il est probablement possible d'ajouter une bibliothèque dll, mais je n'arrive pas à le découvrir par moi-même.
Il n'y aura pas de bénéfice (si vous procédez à une réévaluation, il y aura un petit pourcentage de bénéfice à zéro).
Les colonnes de résultats financiers n'ont donc que peu d'intérêt. Il y aura également des erreurs de prévision de classe 0 (au lieu de 0, nous prévoyons 1). Et le prix de l'erreur est inconnu. C'est-à-dire que la ligne d'équilibre ne sera pas construite. D'autant plus que vous avez 70% de classe 0. C'est-à-dire 70% d'erreurs avec un résultat financier inconnu.
Vous pouvez oublier les 3000 points. Si c'est le cas, ce ne sera pas fiable.
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation
En fait, je suggère de télécharger le fichier à partir du lien. Il y a 3 fichiers csv dans l'archive :
L'échantillon lui-même contient 5581 colonnes avec des prédicteurs, la cible dans 5583 colonne "Target_100", les colonnes 5581, 5582, 5584, 5585 sont auxiliaires et contiennent :
L'objectif est de créer un modèle qui "gagnera" plus de 3000 points sur l'échantillon exam.csv.
La solution doit être trouvée sans avoir recours à l'examen, c'est-à-dire sans utiliser les données de cet échantillon.
Pour maintenir l'intérêt, il est souhaitable d'expliquer la méthode qui a permis d'obtenir un tel résultat.
Les échantillons peuvent être transformés comme vous le souhaitez, y compris en changeant l'échantillon cible, mais vous devez expliquer la nature de la transformation afin qu'il ne s'agisse pas d'une adaptation pure à l'échantillon de l'examen.