Index de Hearst - page 22
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
Не знаю. Для начала надо идентифицировать модель ВР. В ней могут быть тренды, циклы, шум, причем с разными параметрами - от рабочих до таких, в которых модель не работоспособна. Бокс рассматривает несколько моделей с разным набором параметров. Если взять хотя бы то, что он идентифицировал Бокс и для них посчитать Херста - это будет один и тот же херст или это будут разные, с разными величинами или алгоритмами.
Я видел попытки посчитать Херста на нескольких форумах и в литературе. Ни одного работоспособного. Это навело на выше приведенные мысли.
Je suis confus par votre "Pas un seul qui fonctionne." après les mots "...". et dans la littérature". Il existe de nombreuses approches différentes dans la littérature qui donnent des résultats légèrement différents les uns des autres, ce qui n'est pas surprenant puisqu'il s'agit d'estimations. Cependant, il est également vrai que plus l'échantillon est grand, plus ces estimations devraient être précises et plus elles sont "égales" les unes aux autres. Je suis seulement d'accord pour dire qu'il est difficile de trouver un algorithme Hurst fonctionnel sur les forums.
Quant à ce qu'il faut introduire à l'entrée de l'algorithme, l'algorithme s'en moque. Nourrissez le prix et vous obtiendrez quelque chose autour de un. En effet, pour l'essentiel de l'algorithme, le prix a une forte mémoire à long terme, car il reste relativement éloigné des valeurs d'origine. Les incréments de prix des aliments pour animaux - vous obtenez quelque chose comme 0,5, ce qui est à nouveau justifié, car leurs variations relatives sont importantes et presque aléatoires. Alimentez les tendances et/ou les cycles - obtenez la persistance. Le bruit réduit généralement l'indice. Je constate que la question "notre prix est-il bruyant ou un prix de marché équitable ?" n'est pas le sujet de l'algorithme de Hearst, c'est un autre domaine.
Подскажите пожалуйста, каким образом в RS-анализе выбирается длина анализируемого ВР.
En général, plus c'est long, mieux c'est. Selon l'algorithme du livre de Peters, la longueur qui a le plus grand nombre de diviseurs entiers est la meilleure.
Подскажите пожалуйста, каким образом в RS-анализе выбирается длина анализируемого ВР.
On distingue deux modèles :
1. Le processus a un indice de Hurst "stable". C'est-à-dire que l'indice est une constante et ne change pas dans le temps (pendant toute l'existence du processus). Dans ce cas, sa définition est prise comme un minimum - un segment statistiquement significatif - c'est-à-dire un segment qui permet de faire une estimation fiable de la distribution du processus. Ou sans s'en préoccuper - un segment aussi large que possible.
2. L'indicateur est une fonction quelconque, éventuellement très complexe, éventuellement aléatoire. Dans ce cas, il n'y a pas de critères objectifs pour sélectionner la longueur de la BP. L'estimation de l'indice pour le cas général est impossible dans le domaine temporel ou fréquentiel, à moins d'être un médium.
Il est important de noter que l'analyse RS est l'une des méthodes les plus grossières, son estimation est toujours biaisée et la taille de l'échantillon ne sera d'aucune aide. Pour obtenir un calcul correct de l'indice de Hurst, utilisez l'estimation basée sur les ondelettes (l'algorithme peut être trouvé dans mathlab, par exemple).
Добрый день!С большим вниманием читала данную ветку, так как интересуюсь данной тематикой, хотя в этих вопросах я еще новичок. В ходе своего исследования показателя Херста интересует реализация следующей задачи: необходимо определить эффективность индикатора iVAR, _hurst_classik для финансового ряда.
Мое видение реализации данной задачи следующее: необходимо сделать индикатор, который бы на основе данных индикатора ZigZag, рассчитал расстояние d1 (количество баров) между двумя соседними точками (минимумам и максимумам), а также получить расстояние d2 (количество точек за соответствующий интервал), который дает индикатор iVAR(множество значений меньше 0,5 в случаи индекса вариации) и индикатор _hurst_classik (множество значений больше 0,5 в случаи показателя Херста ). В конечном итоге получить массив отношений d2/d1. Конечный результат представить в виде гистограммы.
Надеюсь на этом сайте есть джентльмен - программисты на MQL4,которые помогут девушке в ее исследовании, буду рада любой помощи!За ранее огромное спасибо!
PS: хотя индикатор ZigZag является трендовым, возможно какое-то программное решение с флэтом. Если существуют какие-то готовые инструменты для решение данной задачи, прошу их указать. Кроме того повторно выкладываю коды индикаторов iVAR и _hurst_classik.
Hearst pour le prix est ~1, mais ici quoi ?
La seule chose que je puisse faire dans ce cas est de signaler qu'il n'y a pas d'analyse Hearst ou R/S dans le fichier _hurst_classik. Le nom "R/S" lui-même sert à redimensionner la ligne. Mais le _hurst_classique qui a une prétention de _RS_Analiz ne fait pas de re-mastering, mais, par exemple, prend trivialement la différence entre les prix maximum et minimum.
De plus, l'analyse R/S, pour atteindre Hearst, calcule la pente de la courbe et pour cela elle a besoin de nombreux points sur le plan log(R/S) - log(n) au lieu d'un seul. Dans ce miracle _RS_Analiz il n'y a rien de tel.
Le point principal de mon post était "identifier le modèle BP", mais cela n'a pas retenu votre attention.
Si nous parlons de modèles de classe ARFIMA ou de quelque chose comme ça, cela ne m'intéresse vraiment pas, car ces modèles sont des "nakuya" en pleine croissance, dont le but est de lever des fonds pour des fonds d'investissement. Une telle "science" est appelée science de cabinet parce qu'elle est créée uniquement dans le but de modifier la base scientifique pour un résultat souhaité connu, généralement une prédiction de prix.
Si nous parlons de modèles de classe ARFIMA ou de quelque chose de ce genre, cela ne m'intéresse vraiment pas, car ces modèles sont de plus en plus "naqui", dont le but est de lever des fonds pour des fonds d'investissement. Cette "science" est appelée "science de cabinet" parce qu'elle est créée uniquement dans le but d'adapter un cadre scientifique à un résultat délibérément souhaité, généralement une prédiction de prix.
Ne faisons pas d'estimations. Nous parlons maintenant d'approches utilisant le modèle BP et de celles qui ne l'utilisent pas du tout.AIDE À CALCULER L'INDICATEUR HEARST !!!*
*petite remarque : comme Peters
J'ai lu tout le fil de discussion du début à la fin : oui, je ne m'attendais pas à ce que tout le monde, des universitaires respectés aux simples badauds, ait sa propre opinion sur ce qu'est Hirst, et comment il doit être compté et interprété. Le plus proche de l'original est Eric Nyman dans son article et son livre. Mais... nous (en Russie pour ainsi dire) ne disposons toujours pas d'un outil adéquat pour générer des graphiques, qui sont présentés dans le livre de Peters.
J'ai donc essayé d'imiter aussi fidèlement que possible la séquence d'étapes que Peters a décrite dans son premier livre : "Chaos and Order in the Capital World", pour calculer les statistiques R/S du S&P 500.
1. Nous prenons les graphiques mensuels du S&P 500 du 01.01.1950 au 01.07.1988.
2. Nous les chargeons dans le programme d'analyse technique (j'utilise WealthLab et C#, ici et plus loin j'utiliserai le code WL/C#)
3. Convertir les prix en rendement en utilisant la formule du livre de Peters :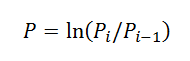 .
.
4. Peters lui-même ne mentionne pas qu'une fois les rendements calculés, ils sont reconvertis en une série accumulée :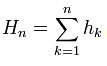 . Pourtant, c'est évident, sur la base de ces valeurs d'écart R/S qu'il a, d'ailleurs la source le dit aussi explicitement, je cite : "Pour chaque n naturel, composons les valeurs (voir la formule ci-dessus) et calculons les caractéristiques numériques suivantes de la sous-séquence résultante".
. Pourtant, c'est évident, sur la base de ces valeurs d'écart R/S qu'il a, d'ailleurs la source le dit aussi explicitement, je cite : "Pour chaque n naturel, composons les valeurs (voir la formule ci-dessus) et calculons les caractéristiques numériques suivantes de la sous-séquence résultante".
5. Nous divisons la série résultante en k périodes, la longueur de chaque période étant N de 6 à 231 mois ou observations.
6. Voici un point important. Si le nombre entier de périodes n'est pas obtenu (il reste des données inutilisées), elles sont rejetées. Cependant, si le reste est trop grand (par exemple 462 / 232 = 233 et 230 dans le reste), on obtient une valeur incorrecte. Si j'ai bien compris, Peters utilise les décalages, mais c'est une option très compliquée en termes de programmation et je me contente de rejeter la période si son résidu est supérieur à 6. Puisque les périodes adjacentes ont presque la même valeur R/S, c'est l'option correcte.
7. R est ensuite calculé à l'aide de la formule :
8. R est divisé par l'écart-type (calculé par l'indicateur WL) et logarithmique : log10(R/S).
9. La période actuelle est logarithmée : log10(N) ;
10. Le rapport obtenu log10(R/S) sur log10(N) est écrit dans le fichier.
Si l'optimiseur passe par N de 6 (comme Peters) à 231 (le nombre minimum d'expériences est de 2), alors nous obtenons un tableau de deux colonnes en double échelle logarithmique : 1. période 2. valeur de R/S.
Maintenant commence la partie la plus intéressante. Si vous tracez ce tableau dans Excel, vous obtiendrez le résultat suivant :
L'original est présenté à droite. Comme vous pouvez le constater, il y a une certaine similitude, mais ce n'est toujours pas la même chose. En particulier, le chiffre initial s'avère être légèrement surestimé (0,33 contre environ 0,31), et deuxièmement, les valeurs finales commencent soudainement à chuter de manière drastique, ce qui ne devrait pas être le cas en principe. D'après son graphique, seul l'angle de pente devrait changer à la fin de la série, ce qui nous indique que l'effet mémoire est limité.
Jusqu'à présent, je me suis arrêté à ce stade. Je n'ai pas encore décidé d'appliquer les statistiques U/V, étant donné que le chevauchement avec l'original n'est que partiel.
La conversion des scores R/S en Hearst donne également des résultats quelque peu gonflés. Si le chiffre de Hearst est :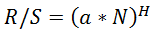 En utilisant la formule Excel, nous obtenons LOG(HERST(10;B1);C1*0.5), où B1 est le score R/S actuel.
En utilisant la formule Excel, nous obtenons LOG(HERST(10;B1);C1*0.5), où B1 est le score R/S actuel.
Vous trouverez ci-dessous le code WL/C# qui calcule les statistiques R/S :
p.s. C'est drôle, MQL4 n'a pas de mots-clés comme overide et using, mais la syntaxe les met quand même en évidence :)Existe-t-il un calcul de l'indice de Hurst dans Matcad (besoin de formules sous forme discrète) ?
Jusqu'à présent, je n'ai trouvé que ceci
Fichier avec les approches de l'analyse des séries temporelles joint. J'ai pris ces formules à partir de là.
Désolé, bien sûr.
Est-ce intéressant ? En regardant ces formules, je ne vois pas l'intérêt de les appliquer au Forex.
Il est plus facile d'établir une série qui décrit le forex. Ça existe déjà, des gens ont gagné des prix Nobel pour ça. Mais le résultat est très moyen. Il faut toujours estimer d'abord la moyenne - l'erreur, et ensuite essayer d'enlever les moins de la probabilité en rapport avec les erreurs, et ensuite s'en occuper.
Désolé, bien sûr.
Alors, c'est intéressant ? En regardant les formules - je ne vois pas du tout l'intérêt de les appliquer au forex.
Il est plus facile de créer soi-même une série qui décrira le forex. Cela existe déjà, des gens ont reçu un prix Nobel pour cela. Mais le résultat est très, très moyen. D'abord il faut toujours estimer la moyenne - l'erreur, et ensuite essayer d'enlever les moins de la probabilité en rapport avec les erreurs, et ensuite s'en occuper.
Désolé. Mais à l'avenir, mettons-nous d'accord pour ne pas poster de réflexions oiseuses dans ce fil. Certains s'intéressent au "rang des forex", d'autres aux statistiques de Hearst. Que chacun ait son propre fil de discussion.
J'affiche un tableau de type CSV en double échelle logarithmique : estimation R/S à la période.