Index de Hearst - page 20
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
Il est également possible de diviser le segment en deux de façon permanente.
Hm, et les points pour lesquels la différence Close[i+1]-Close[i] = 0 et l'écart-type 0, ne sont tout simplement pas pris en compte lors de la construction d'une ligne droite ?
Certains pensent également qu'il faudrait utiliser la méthode RANSAC (http://en.wikipedia.org/wiki/RANSAC) au lieu de l'ISC habituel pour calculer le coefficient de Hurst, car les points "hors du nombre total", c'est-à-dire les plus éloignés de la masse totale, peuvent influencer le coefficient de pente de la ligne droite avec l'ISC habituel.
понял. Я брал среднее геометрическое из High и Low. Сейчас посмотрю что будет на разнице. Я пока не могу решить что целесообразнее - брать код для MT4 и переделывать под Си или искать ошибки у себя ;) У меня данные это дневные бары(5ти минутки), всего их 78. Я точки стоил по значениям для 3,4...78и. - МТ4 моментально обсчитает 78 баров, даже до десятка тысяч считает быстро. А вот для каждого бара расчитывать Херста на многотысячной выборке - это уже долго, если баров тоже тыщи.
Есть еще вроде вариант постоянного деления отрезка пополам. - не совсем представляю о чем вы, но если длина выборки - степень двойки, то да, работает. В любом случае предпочтительнее иметь выборку с длиной имеющей как можно больше делителей.
Хм, а точки для которых разница Close[i+1]-Close[i] = 0 и среднеквадратичное отклонение 0, просто не рассматриваются при построении прямой? - (Close[i+1]-Close[i]) - это входные данные, прямая строится не по ним, а по коэффициентам, которые получаются из этих данных при R/S анализе.
Еще есть мнение что подсчета коэффициента Херста нужно использовать не обычный МНК, а т.н. RANSAC( http://en.wikipedia.org/wiki/RANSAC ), т.к. при обычном МНК на коэффициент наклона прямой могут влиять точки, "выбивающиеся из общего числа", т.е. наиболее удаленные от общей массы. - Не представляю на основании какой модели, можно решить, что некоторые возвраты подлежат выбросу из выборки?
(Close[i+1]-Close[i]) = 0 => log(d[i]/d[i-1]) = INF - Je ne comprends pas quoi faire avec ceci. RS = R/S - et comment calculer quand S = 0, en supposant que R = 0 aussi ? puis encore log(R) = INF et encore une fois je ne comprends pas ce qu'il faut faire. OK. Voici un exemple simple : quel est le coefficient H
et si (Close[i+1]-Close[i]) = const pour tous les i sur un intervalle donné ?
Je n'ai aucune idée sur la base de quel modèle, il peut être décidé que certains retours sont à écarter de l'échantillon ? -Si, par exemple, il y avait une erreur dans plusieurs valeurs du flux de données du stock (54,5 au lieu de 14,4)
La fonction RS prend en entrée un tableau de Close[i]-Close[i-1] et le nombre d'éléments du tableau
.
1. S[i-1] = Close[i]-Close[i-1] Pour tous les i de 0 à N
2. h[i] = log(S[i]/S[i-1])
3. hn = Somme de h[i] h_cp = arith. Hn
4. R = max(h[i] - h_cp) - min( h[i] - h_cp ) S = 1/n * (h[i] - h_cp) RS = R / S
5. Ensuite, je place m-n points avec la valeur de log RS(i) et log i pour i de n_min à un certain N et les MNCs sont en ligne droite.
В общем давайте я расскажу свой алгоритм обсчета словами, а вы мне скажете пж где ошибка, а то мы так долго друг друга чуствую не поймем.
функция RS на вход принимает массив из Close[i]-Close[i-1] и число элементов массива
1. S[i-1] = Close[i]-Close[i-1] Для всех i от 0 до N
2. h[i] = log(S[i]/S[i-1]) - не стоит так делать, т.к. п.1 и п.2 в принципе одно и тоже в смысле подготовки данных для алгоритма. Действительно, вместо возвратов на вход можно подавать log(Close[i]/Close[i-1]), но подавать на вход логарифм отношения возвратов - это перебор, по-моему. Достаточно подавать что-нибудь одно - либо разницу цен, либо логарифм их отношений.
3. Hn = Сумма h[i] h_cp = ср.ариф. Hn
4. R = max(h[i] - h_cp) - min( h[i] - h_cp ) S = 1/n * (h[i] - h_cp) RS = R / S
5. Далее стою м-во точек со значением log RS(i) и log i для i от n_min до некоторого N и МНК стоют прямую
в п.3-5 для начала не вижу оператора или описания, что вся выборка делится на N кусков размером M, что для каждого этого куска считается rs = (максимум наращиваемой суммы отклонений от среднего - минимум наращиваемой суммы отклонений от среднего) / сумму квадратов отклонений от среднего, и все они, эти rs, складываются, а потом делятся на N. Теперь Log(RS) и log(N) - это одна точка для МНК, которых надо насобирать побольше, подбирая разные N и М так, чтобы N*M=длина выборки всегда. На мой взгляд, запись п.4 полностью неверна.
Si je comprends bien, cela n'a pas de sens de calculer le coefficient pour 78 valeurs - c'est-à-dire pour une barre d'un jour ? Je ne comprends toujours pas non plus ce qu'il faut faire si certaines valeurs sont égales à zéro. Par exemple, si je saisis la différence de prix, il est clair que la différence dans 5 minutes peut être inférieure ou égale à 0, mais alors le journal n'est pas pris. J'ai une idée pour prendre le modulus de la valeur dans le cas où elle est négative (i.e. différence absolue) et dans le cas de 0 ne pas entrer cette valeur dans la série h.
Le fichier de test lui-même. H~0.72
Votre indicateur zHursttExponent.mq4 donne 0.1647 sur votre fichier de test brown72.txt. De quoi s'agit-il ?
D'après ce que j'ai compris, cet indicateur calcule la valeur de Hurst pour chaque tick des 2520 dernières barres et l'imprime. C'est vrai ?
Que signifient alors les 4 bins de cet indicateur et pourquoi sont-ils nécessaires dans une fenêtre séparée ?
Et une dernière question.
for(int i=0; i<limit; i++)
{
}
//---- done
Quelle est la signification de cette pièce dans le code de l'indicateur ?
Ваш индикатор zHursttExponent.mq4 на вашем же тестовом файле brown72.txt выдает 0.1647. К чему бы это ?
Насколько я понял, этот индикатор считает показатель Херста на каждом тике для последних 2520 баров и выдает значение на печать. Так ?
А что тогда означают 4 буфера этого индикатора и зачем они нужны в отдельном окне ?
И еще один вопрос.
for(int i=0; i<limit; i++)
{
}
//---- done
Какой смысл имеет этот кусок в коде индикатора ?
1. Je ne peux pas répéter votre résultat = 0.1647. Le mien est comme ça (=0.7241) :
2) Oui, cet indicateur considère l'indice de Hurst sur chaque tick pour les 2520 dernières barres et imprime la valeur et dessine des points r/s (ligne blanche), sur lesquels est dessinée la ligne droite d'approximation (ligne rouge), dont la pente est l'indice recherché - pour la clarté, mais pour moi - pour une estimation visuelle qualitative de la correction de l'algorithme. Tout ceci est vrai lorsque cRSGraphic = true, sinon l'indicateur considère l'indice de Hurst pour les 250 dernières barres.
3. 4 tampons est une redondance apparente, une relique de l'époque du débogage et des tests.
4. Boucle vide - le même problème qu'au point 3.
Подниму ка тему) Спасибо Vita - написал win32api под c++ и все пашет как надо. Вопрос к людям которые часто применяли этот метод - есть какие-нибудь оценки погрешностей от числа входящих данных, дисперсии, корреляции и мб других стат.величин.
Как я понял вообще смысла особого нет считать коэффициент для 78 величин - т.е для однодневного бара? Так же по прежнему не понимаю что делать если какие-то величины равны нулю. Ну например если на вход подаю разность цен - понятное дело что разность за 5ть минут мб меньше или равны 0, но log тогда не берется. У меня есть идея брать модуль величины в случае если она отрицательна(т.е абсолютную разницу) а в случае 0 не заносить это значение в ряд h.
Voici une variante dans laquelle l'erreur est comptée. Malheureusement, je ne peux pas trouver où j'ai volé la source C de cette merveille, mais il prétend compter par Feder E. Fractals. Pour lui, le test H=0.6807 pour le même fichier. On dirait que c'est pas mal.
Pour 78 valeurs, c'est le plus difficile. De nombreux travaux sont consacrés à la manière d'estimer Hurst sur une demi-centaine d'observations. Même sans comprendre les calculs, on obtient des résultats très différents d'un auteur à l'autre. Il n'y a rien de surprenant à cela. Autant d'algorithmes que d'indicateurs :). Oh, et un autre problème - dans la version jointe sur 1000 observations avec l'erreur prise en compte nous ne pouvons rien dire sur le prix - est-il cohérent ou non pour le moment, parce que 0.5 se trouve juste entre le canal d'erreur (lignes rouges à cRSGraphic=false).
L'entrée doit être soit la différence de prix, soit le logarithme du rapport de prix.
1. Je ne peux pas répéter votre résultat = 0.1647. Le mien est comme ça (=0.7241) :
Vous avez joint le fichier brown72.txt. Cependant, votre indicateur teste sur le fichier brown72.csv. Faute d'autres instructions, je l'ai simplement renommé et placé dans le dossier \experts\files. Voici le résultat :
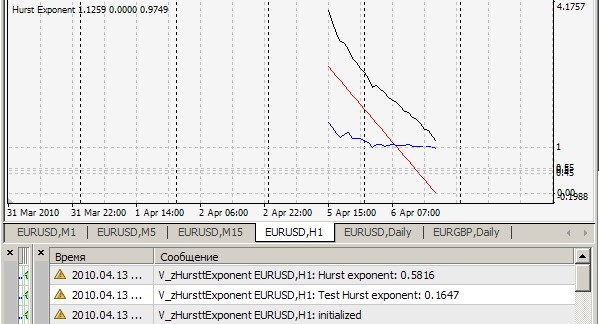
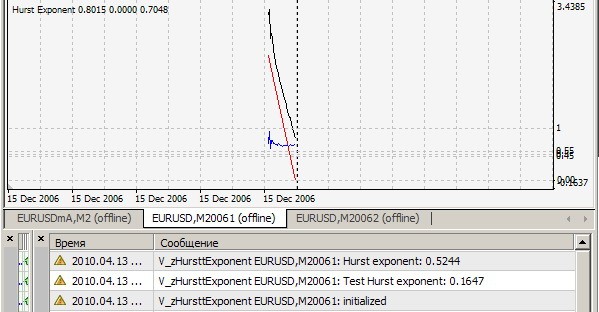
Sur H1 :
Sur les tiques :
Votre fichier contient 1024 valeurs. Voici les 4 premiers d'entre eux :
45.47422
42.55601
46.5188
41.61502