L'apprentissage automatique dans la négociation : théorie, modèles, pratique et algo-trading - page 851
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
2 classes
chargées 1 noyau
Setting , rfeControl = rfeControl(number = 1,repeats = 1) - temps réduit à 10-15 minutes. Changements dans les résultats - 2 paires de prédicteurs échangés, mais globalement similaire à ce que la valeur par défaut était.
Eh bien, voilà, tes 10 minutes sur un noyau, c'est mes 2 sur 4 et deux minutes dont je ne me souviens plus.
Je n'attends jamais quelque chose pendant des heures, si 10-15 minutes n'ont pas fonctionné, c'est que quelque chose ne va pas, alors passer plus de temps ne servira à rien. Toute optimisation lors de la construction d'un modèle qui dure des heures est un manque total de compréhension de l'idéologie de la modélisation, qui dit que le modèle doit être aussi grossier que possible et en aucun cas aussi précis que possible.
Maintenant, parlons de la sélection des prédicteurs.
Pourquoi faites-vous cela et pourquoi ? Quel problème essayez-vous de résoudre ?
La chose la plus importante dans la sélection est d'essayer de résoudre le problème du recyclage. Si votre modèle est surentraîné, la sélection peut accélérer l'apprentissage en réduisant le nombre de prédicteurs. Mais il est beaucoup plus efficace de réduire ce nombre en isolant les composantes principales. Ils n'ont aucune incidence, mais peuvent réduire le nombre de prédicteurs d'un ordre de grandeur et, par conséquent, augmenter la vitesse d'ajustement du modèle.
Pour commencer, pourquoi en avez-vous besoin ?
J'ai trouvé un autre paquet intéressant pour trier les prédicteurs. Il s'agit de FSelector. Il propose une douzaine de méthodes pour éliminer les prédicteurs, dont l'entropie.
J'ai obtenu le fichier avec les prédicteurs et la cible surhttps://www.mql5.com/ru/forum/86386/page6#comment_2534058.
L'évaluation du prédicteur par chaque méthode est présentée dans le graphique à la fin.
Le bleu est bon, le rouge est mauvais (pour le corrplot, les résultats ont été mis à l'échelle [-1:1], pour l'évaluation exacte, voir les résultats de cfs(targetFormula, trainTable), chi.squared(targetFormula, trainTable), etc.)
Vous pouvez voir que X3, X4, X5, X19, X20 sont bien évalués par presque toutes les méthodes, vous pouvez commencer par eux, puis essayer d'en ajouter/supprimer d'autres.
Cependant, les modèles dans rattle n'ont pas passé le test avec ces 5 prédicteurs sur Rat_DF2, encore une fois le miracle ne s'est pas produit. C'est-à-dire que même avec les prédicteurs restants, vous devez ajuster les paramètres du modèle, faire de la validation croisée, ajouter/supprimer des prédicteurs vous-même.
J'ai fait la même chose avec CORElearn en utilisant les données des articles de Vladimir.
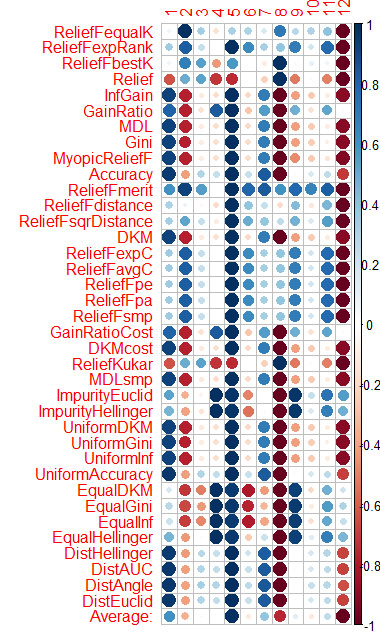
J'ai calculé la moyenne des colonnes (la ligne du bas est Moyenne) et je l'ai triée. Il est plus facile de percevoir l'importance totale de cette façon.
Il a fallu 1,6 minute - et cela pour 37 algorithmes travaillés. Cette vitesse est bien meilleure que celle de Caret (16 minutes), avec des résultats similaires.
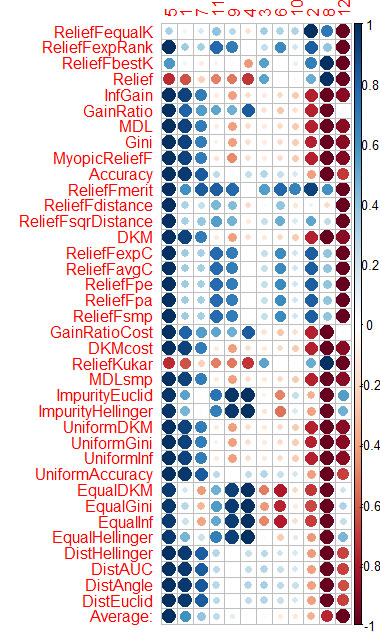
J'ai fait la même chose avec CORElearn en utilisant les données des articles de Vladimir.
J'ai calculé la moyenne par colonnes (la moyenne de la ligne inférieure) et je l'ai triée. Il est plus facile de percevoir l'importance totale de cette façon.
Il a fallu 1,6 minutes et 37 algorithmes.
Alors, quel est le résultat final ??? Avez-vous répondu à la question sur l'importance des prédicteurs ou non, car je ne comprends pas bien ces images.
Pour moi maintenant, il n'y a aucun problème lors de la construction et de la sélection d'un modèle, je sélectionne des prédicteurs, puis je construis 10 modèles sur eux, puis l'information mutuelle sélectionne celui qui fonctionne le mieux. Savez-vous comment faire ? C'est un défi mental ! !! Très bien, celui qui le résout est le meilleur ! !!!!
J'ai réussi à obtenir un ensemble de modèles. Et en fait vporez : Lequel des modèles fonctionne et pourquoi ??????
Ou plutôt, ils fonctionnent tous, mais un seul d'entre eux peut composer un numéro. Et expliquez pourquoi ?
Alors, quel est le résultat final ??? Avez-vous répondu à la question sur l'importance des prédicteurs ou non, car je ne comprends pas bien ces images.
Pour moi maintenant, il n'y a aucun problème lors de la construction et de la sélection d'un modèle, je sélectionne des prédicteurs, puis je construis 10 modèles sur eux, puis l'information mutuelle sélectionne celui qui fonctionne le mieux. Savez-vous comment faire ? C'est un défi mental ! !! Très bien, celui qui le résout est le meilleur ! !!!!
J'ai réussi à obtenir un ensemble de modèles. Et en fait vporez : Lequel des modèles fonctionne et pourquoi ??????
Ou plutôt, ils fonctionnent tous, mais un seul d'entre eux peut composer un numéro. Et expliquez pourquoi ?
Vtreat trie les prédicteurs de manière très similaire (important en premier)
5 1 7 11 4 10 3 9 6 2 12 8
Et voici le tri par moyenne dans CORElearn
5 1 7 11 9 4 3 6 10 2 8 12
Je ne pense pas que je vais m'embêter avec d'autres paquets de sélection de prédicteurs.
Donc Vtreat est suffisant. Sauf que l'interaction des prédicteurs n'est pas prise en compte. Probablement aussi.
Je suis en larmes quand je vois que vous ne cessez de souligner l'importance des prédicteurs pour certains éléments de l'histoire du marché. Pourquoi ? C'est une profanation des méthodes statistiques.
Nous avons vérifié dans la pratique que si le prédicteur numéro 2 est introduit dans le NS, l'erreur passe de 30% à presque 50%.
et sur l'OOS, comment l'erreur change-t-elle ?
Comment l'erreur change-t-elle sur l'OOS ?
de la même manière. Comme dans les articles de Vladimir - les données proviennent de là.
Et si c'est sur un autre OOS ?
En pratique, j'ai vérifié que si l'on alimente le SN avec le prédicteur numéro 2, l'erreur passe de 30% à presque 50%.
Cracher sur les prédicteurs, et alimenter la série temporelle normalisée au NS. Le NS trouvera les prédicteurs lui-même - +1-2 couches, et voilà...