¿Hay algún patrón en el caos? ¡Intentemos encontrarlo! Aprendizaje automático a partir de una muestra concreta.
En realidad, sugiero descargar el archivo desde el enlace. Hay 3 archivos csv en el archivo:
- train.csv - la muestra en la que necesita entrenar.
- test.csv - muestra auxiliar, puede ser utilizada durante el entrenamiento, incluso fusionada con train.
- exam.csv - muestra que no participa de ninguna manera en el entrenamiento.
La muestra en sí contiene 5581 columnas con predictores, el objetivo en 5583 columna "Target_100", las columnas 5581, 5582, 5584, 5585 son auxiliares, y contienen:
- 5581 columna "Hora" - fecha de la señal
- 5582 columna "Target_P" - dirección de la operación "+1" - compra / "-1" - venta
- 5584 columna "Target_100_Buy" - resultado financiero de la compra
- 5585 columna "Objetivo_100_Vender" - resultado financiero de la venta.
El objetivo es crear un modelo que "ganar" más de 3000 puntos en exam.csv muestra.
La solución debe ser sin mirar en el examen, es decir, sin utilizar los datos de esta muestra.
Para mantener el interés - es deseable contar sobre el método que permitió alcanzar tal resultado.
Las muestras se pueden transformar como se quiera, incluso cambiando el objetivo, pero hay que explicar la esencia de la transformación, para que no sea un puro ajuste a la muestra del examen.
Entrenando lo que se llama out of the box con CatBoost, con los ajustes de abajo - con Seed brute force da esta distribución de probabilidad.
FOR %%a IN (*.) DO ( catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_8\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 8 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_16\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 16 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_24\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 24 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_32\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 32 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_40\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 40 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_48\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 48 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_56\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 56 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_64\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 64 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_72\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 72 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_80\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 80 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type Median --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 )
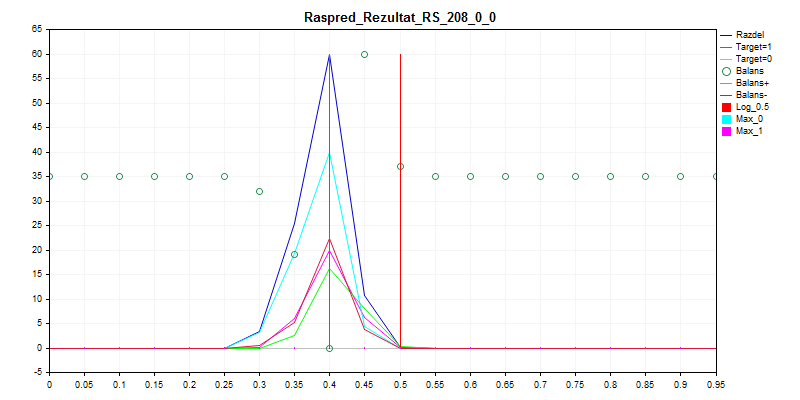
1. Tren de muestreo

2. Prueba de muestreo
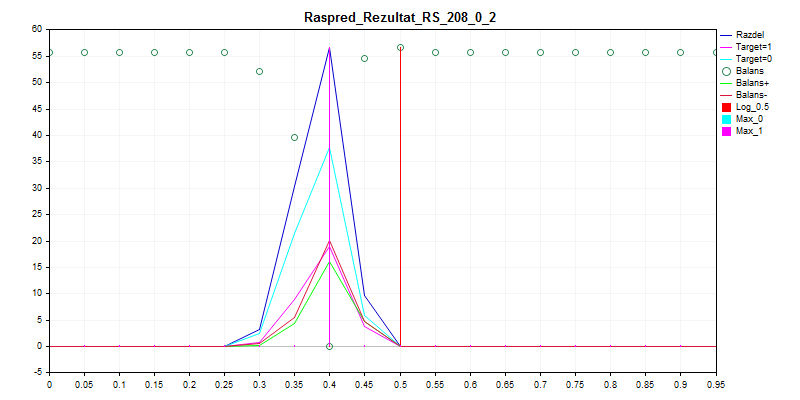
3. Muestra de examen
Como puede ver, el modelo prefiere clasificar casi todo por cero, por lo que hay menos posibilidades de equivocarse.
Las últimas 4 columnas
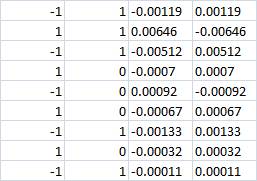
¿Con clase 0 aparentemente la pérdida debería ser en ambos casos? Es decir -0,0007 en ambos casos. O si se sigue haciendo la apuesta de compra|venta, ¿tendremos beneficios en la dirección correcta?
Últimas 4 columnas
Con 0 clase aparentemente la pérdida debe ser en ambos casos? Es decir -0.0007 en ambos casos. O si se sigue haciendo la apuesta de compra|venta, ¿tendremos beneficios en la dirección correcta?
Con grado cero - no entrar en el comercio.
Solía utilizar 3 objetivos - por eso las dos últimas columnas con resultados de aleta en lugar de uno, pero con CatBoost tuve que cambiar a dos objetivos.
¿La dirección 1/-1 se selecciona por una lógica diferente, es decir, el MO no interviene en la selección de la dirección? ¿Sólo tiene que aprender 0/1 trade/no trade (cuando la dirección se elige rígidamente)?
Sí, el modelo sólo decide si entrar o no. Sin embargo, en el marco de este experimento no está prohibido aprender un modelo con tres objetivos, para ello basta con transformar el objetivo teniendo en cuenta la dirección de entrada.
Si la clase es cero - no introduzca la transacción.
Anteriormente solía utilizar 3 objetivos - por eso las dos últimas columnas con resultado financiero en lugar de una, pero con CatBoost tuve que cambiar a dos objetivos.
Sí, el modelo sólo decide si entrar o no. Sin embargo, en el marco de este experimento no está prohibido enseñar el modelo con tres objetivos, para ello basta con transformar el objetivo teniendo en cuenta la dirección de entrada.
Si la clase es cero - no introduzca la transacción.
Anteriormente solía utilizar 3 objetivos - por eso las dos últimas columnas con resultado financiero en lugar de una, pero con CatBoost tuve que cambiar a dos objetivos.
Sí, el modelo sólo decide si entrar o no. Sin embargo, en el marco de este experimento no está prohibido enseñar el modelo con tres objetivos, para ello basta con transformar el objetivo teniendo en cuenta la dirección de entrada.
Catbusta tiene multiclase, es extraño abandonar 3 clases
Es decir, si en la clase 0 (no entrar) se elige la dirección correcta de la transacción, ¿habrá beneficios o no?
No habrá beneficio (si hace revalorización, habrá un pequeño porcentaje de beneficio en cero).
Es posible rehacer el objetivo correctamente sólo rompiendo "1" en "-1" y "1", de lo contrario es una estrategia diferente.
Existe, pero no hay integración en MQL5.
No hay descarga de modelos en ningún lenguaje en absoluto.
Probablemente, es posible añadir una biblioteca dll, pero no puedo averiguarlo por mi cuenta.
No habrá beneficio (si se hace una revalorización habrá un pequeño porcentaje de beneficio a cero).
Entonces no tienen mucho sentido las columnas de resultados financieros. También habrá errores de previsión de clase 0 (en lugar de 0 preveremos 1). Y el precio del error es desconocido. Es decir, no se construirá la línea de equilibrio. Sobre todo porque se tiene un 70% de clase 0. Es decir, 70% de errores con resultado financiero desconocido.
Puede olvidarse de 3000 puntos. Si lo hace, será poco fiable.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
En realidad, sugiero descargar el archivo desde el enlace. Hay 3 archivos csv en el archivo:
La muestra en sí contiene 5581 columnas con predictores, el objetivo en 5583 columna "Target_100", las columnas 5581, 5582, 5584, 5585 son auxiliares, y contienen:
El objetivo es crear un modelo que "ganar" más de 3000 puntos en exam.csv muestra.
La solución debe ser sin mirar en el examen, es decir, sin utilizar los datos de esta muestra.
Para mantener el interés - es deseable contar sobre el método que permitió alcanzar tal resultado.
Las muestras pueden transformarse como se desee, incluso cambiando la muestra objetivo, pero debe explicarse la naturaleza de la transformación para que no sea un ajuste puro a la muestra de examen.