¿Hay algún patrón en el caos? ¡Intentemos encontrarlo! Aprendizaje automático a partir de una muestra concreta. - página 11
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
Ese es el punto, es mejor por un factor de 2 que en 5000+ características.
Resulta que todas las demás fichas 5000+ sólo empeoran el resultado. Aunque si las seleccionas, seguro que encuentras algunas que mejoran.
Es interesante comparar lo que mostrará tu modelo en estas 2.
Tengo mat. expectativa un poco más de uno, el beneficio dentro de 5 mil, la precisión escribe 51% - es decir, los resultados son claramente peores.
Sí, y en la muestra de prueba que tengo una pérdida en todos los 100 modelos.Tengo mat. expectativa un poco más de uno, el beneficio dentro de 5 mil, la precisión dice 51% - es decir, los resultados son claramente peores.
Sí, y en la muestra de prueba hubo una pérdida en los 100 modelos.Pero en la primera, también está perdiendo.
¿En la segunda muestra H1? Estoy mejorando en esa.
Y en la primera, también estoy perdiendo.
Sí, estoy hablando de la muestra H1. Inicialmente me entreno en train.csv, paro en test.csv, y compruebo independientemente en exam.csv, así que la variante con dos columnas falla en test.csv. Las variantes de ayer también se desprendían, pero también las había que ganaban un poco.
¿Qué gráficos milagrosos tienes?Y así es como avanza el valvulado con la formación sobre 20000 líneas en 10000 líneas. Es decir, el gráfico muestra no 2 años, pero 5. 2 años de ellos tendrán que sentarse en drawdown, y luego otro año sin beneficios, debido a lo cual las ganancias medias de nuevo se redujo a 0.00002 por comercio. También no es bueno para el comercio.
Sólo en 2 columnas de tiempo.
La misma configuración en todas las columnas 5000+. Ligeramente mejor. 0.00003 por operación.
Beneficio 0,20600, una media de 0,00004 por operación. En proporción al diferencial
Sí, la cifra ya es impresionante. Sin embargo, el objetivo está marcado para vender, y ahí todo el periodo en un TF grande es vender, creo que también mejora artificialmente el resultado.
Es más de 0.00002 en todas las columnas, pero como dije antes "Spread, deslizamientos, etc. se comerán toda la ganancia". Teriminal muestra el spread mínimo por barra (es decir, durante toda la hora), pero en el momento de una operación puede ser de 5 - 10 pts, y en noticias puede ser de 20 y más.
Así que el margen que tengo está tomado en barras de minutos, los spreads se amplían normalmente durante un periodo de tiempo, es decir, en un minuto probablemente habrá un spread grande todo el tiempo, ¿o no es así ahora? Ni siquiera me he enterado de cómo funciona el spread en 5, me resulta más cómodo para hacer pruebas en 4.
Deberías buscar modelos con ganancias medias de al menos 0,00020 por operación. Entonces en el comercio real usted puede conseguir 0.00010. Esto es para EURUSD, en otros pares como AUD NZD incluso 50 pts no serán suficientes, allí los spreads son de 20-30 pts.
Estoy de acuerdo. La primera muestra en este hilo da una expectativa de 30 pips. Por eso sigo manteniendo la opinión de que el markup debe ser inteligente.
Bueno de nuevo este es el mejor gráfico de la muestra de examen. Como por trayne elegir ajustes que luego den el mejor balance en el de examen es una pregunta sin solución. Se elige por prueba. He entrenado en traine+test. Básicamente, lo que usted tiene un examen, tengo una prueba.
Creo que deberías empezar por conseguir que la mayoría de la muestra supere el umbral de selección. Además, podría tener sentido elegir el modelo menos entrenado de todos: tiene menos ajuste.
Y así es como el rollo hacia adelante con la formación en 20000 filas en 10000 filas. Es decir, en el gráfico no 2 años, pero 5. 2 años de ellos tendrán que sentarse en drawdown, luego otro año sin ganancias, debido a esto las ganancias medias de nuevo se redujo a 0.00002 por el comercio. También no es bueno para el comercio.
Sólo en 2 columnas de tiempo.
La misma configuración en todas las columnas 5000 +. Un poco mejor. 0.00003 por operación.
Aún así, resulta que los otros predictores también pueden ser útiles. Puedes intentar añadirlos en grupos, puedes primero cribar la correlación y reducirlos ligeramente.
En cuanto a la matriz de expectativas, tal vez en esta estrategia es más rentable entrar no por apertura de vela, sino por los mismos 30 pips desde el precio de apertura - las velas sin cola son raras.
Así que el margen que tengo está tomado en barras de minutos, los spreads se amplían normalmente en un periodo de tiempo, es decir, en un minuto probablemente habrá un gran spread todo el tiempo, ¿o no es así ahora? Ni siquiera he averiguado cómo funciona el spread en 5 - para mí es más conveniente para pruebas en 4.
Y en M1 también se mantiene el spread mínimo para el tiempo de barra. En las cuentas ECH casi todas las barras M1 tienen 0.00001...0.00002 raramente más. Todas las barras senior se construyen a partir de M1, es decir, el mismo spread mínimo será. Hay que añadir 4 pts. de comisión por ronda (otros centros de corretaje pueden tener otra comisión).
Sin embargo, resulta que los otros predictores también pueden ser útiles. Puedes intentar añadirlos en grupos, puedes primero cribar la correlación y reducirlos ligeramente.
Tal vez deberíamos seleccionarlos. Pero si añadir 5000+ a 2 añade una pequeña mejora, puede ser más rápido seleccionar 10 piezas por fuerza bruta completa con el entrenamiento del modelo. Creo que será más rápido que esperar a la correlación durante 24 horas. Sólo es necesario automatizar re-entrenamiento en un bucle directamente desde el terminal.
¿Katbusta no tiene una versión DLL? DLL se puede llamar directamente desde el terminal. Había un artículo con ejemplos aquí. https://www.mql5.com/ru/articles/18 y https://www.mql5.com/ru/articles/5798.
Tal vez deberíamos seleccionar. Pero si añadir 5000+ a los 2s da una pequeña mejora, podría ser más rápido seleccionar 10 piezas por fuerza bruta completa con el entrenamiento del modelo. Creo que sería más rápido que esperar la correlación durante 24 horas.
Sí, es mejor hacerlo en grupos al principio - puedes hacer, digamos, 10 grupos y entrenar con sus combinaciones, evaluar los modelos, eliminar los grupos más fallidos, y reagrupar los restantes, es decir, reducir el número de predictores en el grupo y entrenar de nuevo. He utilizado este método antes - el efecto está ahí, pero de nuevo no es rápido.
Sólo tienes que automatizar el re-entrenamiento en un bucle directamente desde el terminal.
¿No tiene catbust una versión DLL? La DLL se puede llamar directamente desde el terminal. Había un artículo con ejemplos aquí. https://www.mql5.com/ru/articles/18 y https://www.mql5.com/ru/articles/5798.
Je, estaría bien tener un control total del aprendizaje a través del terminal, pero según tengo entendido no hay una solución preparada. Hay una biblioteca catboostmodel.dll que sólo se aplica el modelo, pero no sé cómo implementarlo en MQL5. En teoría, por supuesto, es posible hacer una interfaz en forma de una biblioteca para la formación - el código está abierto, pero no me lo puedo permitir.
Sí, es mejor empezar con grupos: puede hacer, digamos, 10 grupos y entrenarlos en combinaciones, evaluar los modelos, eliminar los grupos más fracasados y reagrupar los restantes, es decir, reducir el número de predictores en el grupo y entrenarlos de nuevo. Ya he utilizado este método antes: el efecto está ahí, pero, de nuevo, no es rápido.
Propongo otra cosa. Añadimos características al modelo una a una. Y seleccionamos las mejores.
1) Entrenar 5000+ modelos en una característica: cada una de 5000+ características. Tomar el mejor de la prueba.
2) Tren (5000 + -1) modelos en 2 características: la primera mejor característica y ( 5000 + -1) los restantes. Encuentre la segunda mejor.
3) Entrenar (5000+ -2) modelos sobre 3 características: sobre la 1ª, la 2ª mejor característica y( 5000+ -2) las restantes. Encuentre la tercera mejor.
Repite hasta que el modelo mejore.
Yo suelo dejar de mejorar el modelo después de añadir entre 6 y 10 características. También puede ir hasta 10-20 o tantas características como desee añadir.
Pero creo que la selección de características por prueba es ajustar el modelo a la sección de prueba de los datos. Existe una variante de selección por trayne con peso 0.3 y test con peso 0.7. Pero creo que eso también es un ajuste.
Yo quería hacer el roll forward, entonces el ajuste será para muchas secciones de prueba, tardará más en contar, pero me parece que es la mejor opción.
Aunque usted no tiene la automatización para ejecutar catbusters.... 50+ mil veces será difícil volver a entrenar los modelos manualmente para obtener 10 características.Eso es más o menos por qué prefiero mi oficio sobre catbust. A pesar de que funciona 5-10 veces más lento que Cutbust. Tuviste un modelo durante 3 min, yo tuve 22.
Eso no es lo que estoy sugiriendo. Añadimos características al modelo una a una. Y seleccionamos las mejores.
1) Entrena 5000+ modelos en una característica: cada una de 5000+ características. Toma el mejor de la prueba.
2) Entrena (5000+ -1) modelos en 2 características: la primera mejor característica y( 5000+ -1) las restantes. Encuentre la segunda mejor.
3) Entrenar (5000+ -2) modelos sobre 3 características: sobre la 1ª, la 2ª mejor característica y( 5000+ -2) las restantes. Encuentre la tercera mejor.
Repite hasta que el modelo mejore.
Yo suelo dejar de mejorar el modelo después de añadir entre 6 y 10 características. También puede ir hasta 10-20 o tantas características como desee añadir.
Los enfoques pueden ser diferentes - su esencia es la misma en general, pero la desventaja es por supuesto común - costes computacionales demasiado altos.
Pero creo que la selección de características por prueba es un ajuste del modelo a la sección de prueba de los datos. Hay una variante de selección por trayne con peso 0,3 y test con peso 0,7. Pero creo que también es un ajuste.
Me gustaría hacer valving forward, entonces el ajuste será para muchas secciones de prueba, tardará más en calcularse, pero me parece que es la mejor opción.
Es por eso que estoy buscando algún grano racional dentro de la función para justificar su selección. Hasta ahora me he decantado por la frecuencia de recurrencia de los sucesos y el desplazamiento de la probabilidad de clase. En promedio, el efecto es positivo, pero este método evalúa realmente por la primera división, sin tener en cuenta los predictores correlacionados. Pero creo que también deberías probar el mismo método para la segunda división, eliminando de la muestra las filas de las puntuaciones de los predictores con una fuerte predisposición negativa.
Aunque no tienes automatización para ejecutar catbusters.... 50+ mil veces, sería difícil volver a entrenar los modelos manualmente para obtener 10 rasgos.
Es más o menos por eso que prefiero mi oficio sobre catbust. A pesar de que funciona 5-10 veces más lento que Cutbust. Tú tenías un modelo que tardaba 3 min en contar, yo tenía 22.
Aún así, lee mi artículo.... Ahora todo funciona de forma semi-automática - se generan las tareas y se lanza el bootnik (incluyendo las tareas para el número de características a utilizar en el entrenamiento, es decir, se pueden generar todas las variantes a la vez y lanzarlas). En esencia, es necesario enseñar a la terminal para ejecutar el archivo bat, que es posible, creo, y controlar el final de la formación, a continuación, analizar el resultado, y ejecutar otra tarea basada en los resultados.
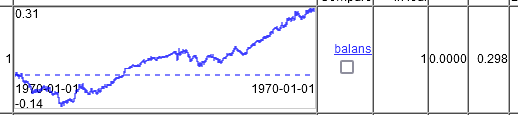
Sólo cambiando el ritmo de aprendizaje fue capaz de obtener dos modelos de 100 que cumplieran el criterio establecido.
El primero.
El segundo.
Resulta que, sí, CatBoost puede hacer mucho, pero parece necesario afinar los ajustes de forma más agresiva.
¿Selecciona estos modelos por los mejores en el examen?
¿O entre un conjunto de los mejores en el examen?