Aprendizaje automático en el trading: teoría, práctica, operaciones y más - página 3008
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
serás demasiado viejo para esperar.
No tengo muchas esperanzas, solo me asomo de vez en cuando. Después de todo gpt auguro estancamiento y paralización en este tema. No se ven avances. Puro hype flash, como con las criptomonedas.
Yo tengo la opinión contraria.
En general creo que hace tiempo que se ha creado una IA fuerte (sólo que no para nosotros), y toda la criptoindustria (el mundo entero) ha estado trabajando en su entrenamiento, sin saberlo.
Yo opino lo contrario.
En general, creo que hace tiempo que se ha creado una IA fuerte (sólo que no para nosotros), y toda la criptoindustria (el mundo entero) ha estado trabajando en su entrenamiento, sin saberlo.
No es prudente, no necesito ayuda. El foro es incluso más una distracción que una pista. Sólo expongo mi experiencia en términos generales. A veces la vendo :) quien la escuche ahorrará tiempo heredándola.
Sobrepasar las señales es una táctica errónea muy poco efectiva, esto ya es como un axioma para mi. Me gustaría decir IMHO, pero es más como un axioma.
Y necesito ayuda - se me ocurren más cosas y más rápido de lo que puedo comprobarlo en el código.
No necesitas buscar características - necesitas seleccionarlas y configurarlas correctamente.
Y necesito ayuda: se me ocurren más cosas y más rápido de lo que puedo probarlas en código.
No se necesita una sobreabundancia de funciones: hay que seleccionarlas y configurarlas correctamente.
Entonces la pregunta lógica es: en qué tecnología. Si es en Transformers, no es IA en absoluto y nunca lo será.
¿Quién puede decirlo?
Pero la tecnogolia debe ser tan mala si se necesita la potencia de cálculo de todo el mundo, desde teléfonos móviles hasta una granja de criptomonedas conectada a una central eléctrica...
Pero no hay mejor tecnología en este momento.
A mí me parece sencillo y trivial.
1. Yo mismo he trabajado y trabajo: hay un maestro y a él hay que recoger/procesar las señales.
2. Como afirma mytarmailS, se puede plantear la tarea contraria: hay signos y a ellos hay que corresponder/crear un profesor. Hay algo en esto que no me gusta. No intento seguir este camino.
En realidad, ambas formas son iguales: el error de clasificación en el par profesor-rasgo disponible no debe superar el 20% fuera de la muestra. Pero lo más importante es que debe haber una prueba teórica de que el poder predictivo de los rasgos disponibles no cambia, o cambia débilmente en el futuro. En todo apisonamiento, esto es lo más importante.
Observaré que mi razonamiento no incluye la selección del modelo. Creo que el modelo desempeña un papel extremadamente secundario, ya que no tiene nada que ver con la estabilidad de la capacidad predictiva de los rasgos: la estabilidad de la capacidad predictiva es una propiedad del par profesor-rasgo.
1. ¿Alguien más tiene un par profesor-rasgo con un error de clasificación inferior al 20%?
2. ¿Alguien más tiene pruebas reales de que la variabilidad de la capacidad predictiva de las características utilizadas es inferior al 20%?
¿La tiene alguien? Entonces hay algo que discutir
¿No? Todo lo demás es bla, bla, bla.
A mí me parece sencillo y trivial.
1. Yo mismo he trabajado y trabajo: hay un maestro y es necesario recoger/procesar los signos.
2. Como dice mytarmailS, se puede plantear la tarea contraria: hay atributos y hay que coger/crear un profesor para ellos. Hay algo en esto que no me gusta. No intento ir por ese camino.
En realidad, ambas formas son iguales: el error de clasificación en el par profesor-rasgo disponible no debe superar el 20% fuera de la muestra. Pero lo más importante es que debe haber una prueba teórica de que el poder predictivo de los rasgos disponibles no cambia, o cambia débilmente en el futuro. Esto es lo más importante.
Observaré que mi razonamiento no incluye la selección del modelo. Creo que el modelo desempeña un papel extremadamente secundario, ya que no tiene nada que ver con la estabilidad de la capacidad predictiva de los rasgos: la estabilidad de la capacidad predictiva es una propiedad del par profesor-rasgo.
1. ¿Alguien más tiene un par profesor-rasgo con un error de clasificación inferior al 20%?
2. ¿Alguien tiene pruebas reales de una variabilidad en la capacidad de predicción de las características utilizadas inferior al 20%?
¿Alguien la tiene? Entonces hay algo que discutir
¿No? Todo lo demás es bla bla bla bla.
Pero lo más importante es que exista una prueba teórica de que el poder predictivo de las características disponibles no cambia, o cambia débilmente en el futuro. En toda la apisonadora, esto es lo más importante.
Por desgracia, nadie ha encontrado esto, de lo contrario no estaría aquí, pero en las islas tropicales))))
Sí. Incluso 1 árbol o regresión puede encontrar un patrón si está ahí y no cambia.
1. ¿Alguien más tiene un par profesor-rasgo con menos del 20% de error de clasificación?
Fácil. Puedo desgenerar docenas de conjuntos de datos. Ahora estoy investigando TP=50 y SL=500. Hay una media del 10% de error en la calificación del profesor. Si es del 20%, será un modelo de ciruela.
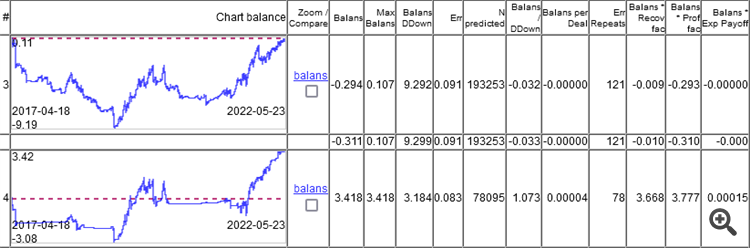
Así que el punto no está en el error de clasificación, sino en el resultado de sumar todas las ganancias y pérdidas.
Como se puede ver, el modelo superior tiene un error del 9,1%, y se puede ganar algo con un error del 8,3%.
Los gráficos muestran sólo OOS, obtenidos por Walking Forward con reentrenamiento una vez a la semana, un total de 264 reentrenamientos en 5 años.
Es interesante que el modelo funcionara a 0 con un error de clasificación del 9,1%, y 50/500 = 0,1, es decir, el 10% debería ser. Resulta que el 1% se comió el diferencial (mínimo por barra, el real será mayor).
Primero hay que darse cuenta de que el modelo está lleno de basura por dentro...
Si descompones un modelo de madera entrenado en las reglas que hay dentro y las estadísticas de esas reglas.
como :
y analizamos la dependencia del error de la regla err con la frecuencia de su ocurrencia en la muestra.
obtenemos
Entonces nos interesa esta zona
Donde las reglas funcionan muy bien, pero son tan raras que tiene sentido dudar de la autenticidad de las estadísticas sobre ellas, porque 10-30 observaciones no es estadística