What to feed to the input of the neural network? Your ideas... - page 31
You are missing trading opportunities:
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
Registration
Log in
You agree to website policy and terms of use
If you do not have an account, please register
As confirmation, my graphs above. One input, two inputs, three inputs - one neuron, two neurons, three neurons. That's it, the next thing is retraining - memorising the path, not working on new data.
Similarly with wooden models. With 3-5 (maybe up to 10, but more likely up to 5) inputs/features, the model can still show profit on the forward, if more, it is already random or plum. I.e. retraining.
These 3-5 best chips were obtained by a complete search of pairs, threes, etc. and training models on them and selecting the best ones on the valving forward.
And imagine, an ordinary neural network takes each number, each feature - and stupidly sums it up, additionally multiplied by weight, into one pile of rubbish, called an adder.
Trees also use the average of leaves.If a forest - it averages with other trees, if a bush - it summarises with refining trees.
I.e. the situation is the same with neural networks as with tree models. All averaging. When there is a lot of noise, it is possible to train normally only on 3-5 chips. Averaging with noise is retraining for noise.
P.S. Instead of 20+ years old NeuroPro you can use something newer. R, Python, or if it is difficult to deal with them, use the EXE of Catbusta, as here https://www.mql5.com/ru/articles/8657 You can automatically run the EXE directly from the EA, i.e. fully automate the process. Example https://www.mql5.com/ru/forum/86386/page3282#comment_49771059
P.P.S. It is better to sleep at night. You can't buy your health, even if you make millions on these networks.
Similarly with wooden models. With 3-5 (maybe up to 10, but more likely up to 5) inputs/features the model can still show profit on the forward, if more, then it is already random or plum. I.e. retraining.
These 3-5 best fichas were obtained by a complete search of pairs, threes, etc. and training models on them and selecting the best ones on the jacking forward.
Trees also use the average value of leaves.If forest - it averages with other trees, if bush - it sums with refining trees.
I.e. the situation is the same with neural networks as with tree models. All averaging. When there is a lot of noise, it is possible to train normally only on 3-5 chips. Averaging with noise is retraining for noise.
P.S. Instead of 20+ years old NeuroPro you can use something newer. R, Python, or if it is difficult to deal with them, use the EXE of Catbusta, as here https://www.mql5.com/ru/articles/8657 You can automatically run the EXE directly from the EA, i.e. fully automate the process. Example https://www.mql5.com/ru/forum/86386/page3282#comment_49771059
P.P.S. It is better to sleep at night. You can't buy your health, even if you make millions on these networks.
Thanks for the post
I see the grail not in summation, but in splitting the number
UPD
And the task of neurons is not to get a set of numbers, but to get one number as input. Multiply it by a weight and feed it through a non-linear function. Then you get data analysis, not soup cooking.
That is, there is one number (input value, or neuron output), and this number is split by two or more neurons of the next layer. They must be independent of the other neurons.
This is a department that does its own thing.
Then all these departments must report to a boss - the output neuron. It draws an inference based on the outputs of all the final neurons. With its own weights.
In this way we reduce the distortion of information and increase its reading.
The grail I see is not summation, but number splitting
Well leaves are obtained by splitting the data, even into 1000000 different parts/leaves. But the result/response of a leaf is the average of the examples/rows included in it.
So splitting is there, but so is summing. You can split to 1 example in a leaf, but that's 100% overtraining on noise. Trees also under noise, should not split deeply, for a good forward (it's how you have the number of neurons better - small).
Stumbled into such a thing as spread and commission. They break the neural network quickly.
Thanks MT5, you know how to sober up. I should have switched to you from MT4 a long time ago
@Andrey Dik was right many years ago - the grail still lies around the spread and commission.
As soon as you remove them - the neural network grails on forwards.
Well, leaves are obtained by splitting the data into 1000000 different parts/leaves. But the result/response of a leaf is the average of the examples/rows included in it.
So there is splitting, but summarisation too. You can split to 1 example in a leaf, but that's 100% overtraining on noise. Trees also under noise, should not split deeply, for a good forward (it's how you have the number of neurons better - small).
Man, what a vast topic. Now to google leaves. In about 5 years I will reach the MO branch, but I will not reread it
Moved from Toyota to an old sports car
Since MT5 is limited in the number of optimisable parameters, I moved to NeuroPro 1999, from the article here - Neural Networks for free and easy - connecting NeuroPro and MetaTrader 5.
I increased the architecture in quantity: in MT5 it was 5-5-5-5, and here it is 10-10-10, and the training is already real (to be more precise - standard, by the method of error back propagation and other internal features inside the programme. Its author doesn't care about it and is not even going to update the rarity - based on his answers to my questions, he has no interest in developing NeoroPro, introducing multithreading, modern methods, etc.
Stumbled into such a thing as spread and commission. They break the neural network quickly.
Thanks MT5, you know how to sober up. I should have switched to you from MT4 a long time ago
@Andrey Dik was right many years ago - the grail still lies around the spread with commission.
As soon as you remove them - the neural network grails on forwards.
Curious phenomenon.
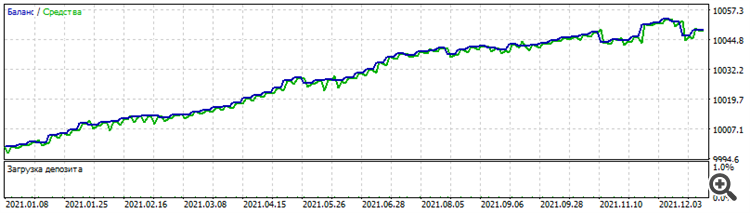
Training on the "extension" architecture, when the first layer consists of 1 neuron, then the 2nd layer of 2, the 3rd layer of 3, etc. gave such a funny and yet curious set:
The results of the set on the EURUSD optimisation period are exactly the same on other dollar pairs:
Optimisation for 2021 on EURUSD
Test on GBPUSD for 2021
Test on AUDUSD for 2021
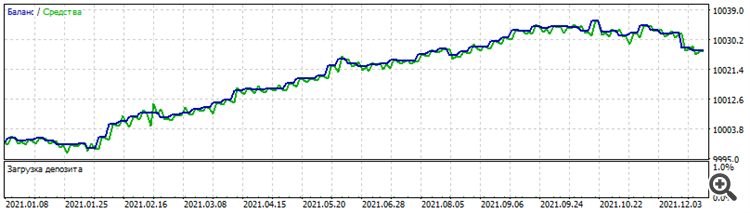

Test on NZDUSD for 20 21
Why only the curious? Because it's a dead set, it doesn't work before or after. But, the very fact that it works on several dollar pairs on the same period, given that although there is some correlation between them, the pricing of each pair is stilldifferent.
Curious phenomenon.
Training on the "extension" architecture, when the first layer consists of 1 neuron, then the 2nd layer of 2, the 3rd layer of 3, etc. gave such a funny and yet curious set:
Results of the set on EURUSD optimisation period are exactly the same on other dollar pairs:
Optimisation for 2021 on EURUSD
Test on GBPUSD for 2021
Test on AUDUSD for 2021
Test on NZDUSD for 2021
Why only the curious? Yes because it's a dead set, it doesn't work before or after. But, the very fact that it works on several dollar pairs on the same period, given that although there is some correlation between them, the pricing of each pair is stilldifferent.
No, it's different.
on all of them, except for the euro, one third of the balance at the end is in the same place.