
HTML Komplettlösung mit MQL4

Einführung
HTML (Hypertext Mark-Up Language) wurde für eine zweckmäßige Formatierung textbasierter Materialien geschaffen. Alle Dokumente dies Typs werden mit speziellen, 'Tags' genannten Funktionswörtern formatiert. Praktisch alle Informationen in HTML Dateien erweisen sich als in Tags eingeschlossen. Wenn wir die reinen Daten entnehmen wollen, müssen wir die Service-Informationen (Tags) von den relevanten Daten trennen. Wir werden dieses Verfahren HTML Komplettlösung zu Aussonderung der Tag-Struktur nennen.
Was Ist ein Tag?
Im Hinblick auf eine einfache Beschreibung, ist ein Tag jedes Wort das in spitze Klammern eingeschlossen ist. Zum Beispiel ist dies ein Tag: <tag>, obwohl, in HTML sind Tags bestimmte Wordtypen in lateinischen Buchstaben. Zum Beispiel, <html> ist ein korrekter Tag, aber es gibt keinen Tag <html2>. Darüber hinaus können viele Tags zusätzliche Attribute haben, welche die ausgeführte Formatierung des bestimmten Tags präzisieren. Zum Beispiel, <div align="center"> bedeutet Tag <div>, in dem das zusätzliche Attribut der zentralen Ausrichtung des Tag-Inhalts angegeben ist.
Tags werden in der Regel paarweise verwendet: Es gibt öffnende und schließende Tags. Sie unterscheiden sich voneinander nur durch das Vorhandensein eines Slash (/). Der Tag<div> ist ein öffnender Tag, während der Tag </div> ein schließender ist. Alle zwischen dem öffnenden Tag und schließenden Tag eingeschlossenen Daten werden Tag-Inhalt genannt. Es ist dieser Inhalt, an dem wir in der HTML Komplettlösung interessiert sind. Beispiel:
<td>6</td>
Der Tag <td> enthält hier '6'.
Was bedeutet "Text Komplettlösung"?
In Zusammenhang mit diesem Artikel bedeutet es, dass wir alle Worte erhalten wollen, die in einer HTML Datei vorkommen und in zwei spitzen Klammern eingeschlossen sind: '<' und '>' - Öffnend und schließend. Wir werden hier nicht analysieren, ob jedes in diesen Klammern ein korrekter Tag ist oder nicht. Unsere Aufgabe ist rein technisch. Wir werden alle gefundenen Tags aufeinander folgend auf einer "was-zuerst-kommt" Basis in ein String-Array schreiben. Dies werden wir 'Tag-Struktur' nennen.
Datei Lesefunktion
Vor der Analyse einer Textdatei, ist es besser sie in ein String-Array zu laden. So werden wir die Datei sofort öffnen oder schließen, um nicht aus Versehen zu vergessen die Datei zu schließen. Darüber hinaus ist eine benutzerdefinierte Funktion, die den Text von einer Datei in ein Array einliest, viel praktischer für die mehrfache Anwendung, als jedes Mal der volle Ablauf des Daten Einlesen mit der obligatorischen Überprüfung auf Fehler. Die Funktion ReadFileToArray() hat drei Parameter:
- string array[] - ein durch einen Link übergebenes String-Array, er ermöglich die Größe und den Inhalt direkt in der Funktion zu ändern,
- string FileName - Dateiname, die Zeilen von denen aus in array[] eingelesen wird,
- string WorkFolderName - Name des Unterordners in dem Verzeichnis Terminal_Verzeichnis\experts\files.
//+------------------------------------------------------------------+ //| writing the content of the file into string array 'array[]' | //| in case of failing, return 'false' | //+------------------------------------------------------------------+ bool ReadFileToArray(string &array[],string FileName, string WorkFolderName) { bool res=false; int FileHandle; string tempArray[64000],currString; int stringCounter; int devider='\x90'; string FullFileName; if (StringLen(WorkFolderName)>0) FullFileName=StringConcatenate(WorkFolderName,"\\",FileName); else FullFileName=FileName; //---- Print("Trying to read file",FileName); FileHandle=FileOpen(FullFileName,FILE_READ,devider); if (FileHandle!=-1) { while(!FileIsEnding(FileHandle)) { tempArray[stringCounter]=FileReadString(FileHandle); stringCounter++; } stringCounter--; if (stringCounter>0) { ArrayResize(array,stringCounter); for (int i=0;i<stringCounter;i++) array[i]=tempArray[i]; res=true; } FileClose(FileHandle); } else { Print("Failed reading file ",FileName); } //---- return(res); }
Die Größe des zusätzlichen String-Arrays ist 64000 Elemente. Dateien mit einer großen Anzahl an Zeilen sollten nicht allzu oft vorkommen. Sie können diesen Parameter allerdings ändern, wenn Sie es möchten. Die Variable stringCounter zählt die Anzahl der von der Datei in das zusätzliche Array temArray[] eingelesenen Zeilen, dann werden die eingelesenen Zeilen nach array[] geschrieben, dessen Größe vorläufig gleich zu stringCounter eingestellt ist. Im Falle eines Fehlers, wird das Programm eine Nachricht in der Protokolldatei des EAs anzeigen, die sie in der "Experten" Registerkarte sehen können.
Wenn array[] erfolgreich ausgefüllt wurde, gibt die Funktion ReadFileToArray() 'true' zurück. Andernfalls gibt sie 'false' zurück.
Hilfsfunktion FindInArray()
Bevor wir mit der Verarbeitung des Inhalts des String-Arrays in unserer Suche nach Tags beginnen, sollten wir die allgemeinen Aufgaben in mehrere kleinere Teilaufgaben aufteilen. Es gibt mehrere Lösungen für die Aufgabe zum Erkennen der Tag-Struktur. Wir werden nun eine bestimmte betrachten. Erstellen wir eine Funktion, die uns darüber informiert, in welcher Zeile und in welcher Position in der Zeile das gesuchte Wort sich befindet. Wir werden an diese Funktion das String-Array, in dem sich das von uns gesuchte Wort befindet, übergeben.
//+-------------------------------------------------------------------------+ //| It returns the coordinates of the first entrance of text matchedText | //+-------------------------------------------------------------------------+ void FindInArray(string Array[], // string array to search matchedText for int inputLine, // line number to start search from int inputPos, // position number to start search from int & returnLineNumber, // found line number in the array int & returnPosIndex, // found position in the line string matchedText // searched word ) { int start; returnLineNumber=-1; returnPosIndex=-1; int pos; //---- for (int i=inputLine;i<ArraySize(Array);i++) { if (i==inputLine) start=inputPos; else start=0; if (start>=StringLen(Array[i])) start=StringLen(Array[i])-1; pos=StringFind(Array[i],matchedText,start); if (pos!=-1) { returnLineNumber=i; returnPosIndex=pos; break; } } //---- return; }
Die Funktion FindInArray() gibt die "Koordinaten" von matchedText zurück, unter Verwendung von durch Link übergebenen integer Variablen. Die Variable returnLineNumber enthält die Zeilennummer, während returnPosIndex die Positionsnummer in dieser Zeile enthält.
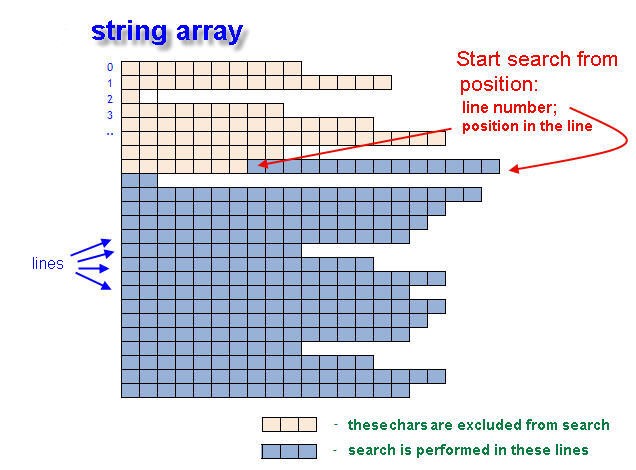
Abb. 1. Suche nach der Anfangsposition des Texts in dem String-Array.
Die Suche wird nicht in dem gesamten Array durchgeführt, sondern beginnt von der Zeilennummer inputLine und Positionsnummer inputPos. Dies sind die anfänglichen Suchkoordinaten in Array[]. Wird das gesuchte Wort nicht gefunden, werden die zurückgebenden Variablen (returnLineNumber und returnPosIndex) den Wert -1 (minus Eins) enthalten.
Ermitteln einer Zeile durch ihre Anfang- und Endkoordinaten von einem Array
Wenn wir die Anfangs- und Endkoordinaten eines Tag kennen, müssen wir alle Zeichen zwischen den spitzen Klammern erhalten und in einen String schreiben. Dazu werden wir die Funktion getTagFromArray() verwenden..
//+------------------------------------------------------------------+ //| it returns a tag string value without classes | //+------------------------------------------------------------------+ string getTagFromArray(string inputArray[], int lineOpen, int posOpen, int lineClose, int posClose, int line_, int pos_) { string res=""; //---- if (ArraySize(inputArray)==0) { Print("Zero size of the array in function getTagFromArray()"); return(res); } string currString; int endLine=-1; int endPos=-1; if (lineClose>=0 && line_>=0) // both space and a closing angle bracket are available { endLine=MathMin(lineClose,line_); // the number of ending line is defined if (lineClose==line_ && pos_<posClose) endPos=pos_;// if the space and the closing angle bracket are in // one line, the position number is the same as that of the space if (lineClose==line_ && pos_>posClose) endPos=posClose;// if the space and the closing angle bracket are in // one line, the position number is the same as that of the space if (lineClose>line_) endPos=pos_;// if the line containing a space is before the line containing a closing bracket, // the position is equal to that of the space if (lineClose<line_) endPos=posClose;// if the line containing a closing bracket is before the line // containing a space, the position is equal to that of the closing bracket } if (lineClose>=0 && line_<0) // no space { endLine=lineClose; endPos=posClose; } for (int i=lineOpen;i<=endLine;i++) { if (i==lineOpen && lineOpen!=endLine) // if the initial line from the given position { currString=inputArray[i]; res=StringConcatenate(res,StringSubstr(currString,posOpen)); } if (i==lineOpen && lineOpen==endLine) // one line { currString=inputArray[i]; res=StringConcatenate(res,StringSubstr(currString,posOpen,endPos-posOpen)); } if (i>lineOpen && i<endLine) // copy the whole line { res=StringConcatenate(res,inputArray[i]); } if (i>endLine && endLine>lineOpen) // copy the beginning of the end line { currString=inputArray[i]; if (endPos>0) res=StringConcatenate(res,StringSubstr(currString,0,endPos)); } } if (StringLen(res)>0) res=res+">"; //---- return(res); }
In dieser Funktion durchsuchen wir nacheinander alle Zeilen innerhalb der Koordinaten der öffnenden und schließenden spitzen Klammer, unter Einbeziehung der Leerzeichen-Koordinaten. Die Funktionsoperation führt zum Ausdruck von '<tag_name>, der aus mehreren Zeilen zusammengesetzt sein kann.
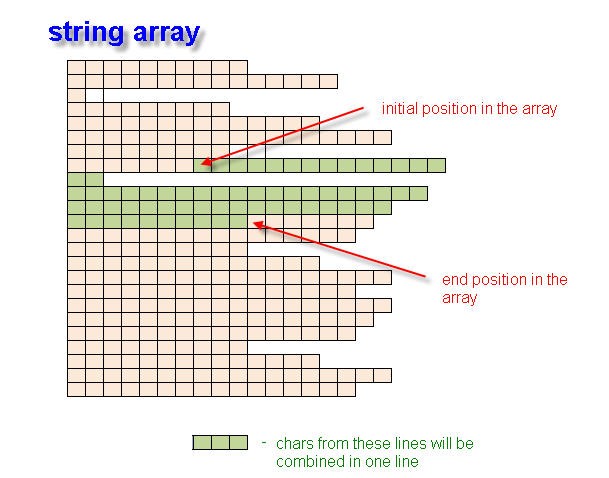
Abb. 2. Erzeugen einer String-Variable des String-Array mit der Anfangs- und der Endposition.
Abrufen der Tag-Struktur
Jetzt haben wir zwei Hilfsfunktionen, also können wir anfangen nach Tags zu suchen. Dazu werden wir fortlaufend mit der Funktion FindInArray() nach '<', '>' und ' ' (Leerzeichen) suchen. Um genauer zu sein, werden wir nach der Position dieser Zeichen in dem String-Array suchen, und dann die Namen der gefundenen Tags mit der Funktion getTagFromArray() zusammensetzen und diese in einem Array mit der Tag-Struktur platzieren. Wie Sie sehen, ist die Technologie recht einfach. Dieser Algorithmus wir in der Funktion FillTagStructure() umgesetzt.
//+------------------------------------------------------------------+ //| fill out the tag structure | //+------------------------------------------------------------------+ void FillTagStructure(string & structure[],// tag structure being created string array[], // initial html text int line, // line number in array[] int pos) // position number in the line { //---- int array_Size=ArraySize(array); if (line==-1000 || pos==-1000 ) { Alert("Invalid values of search position in function FillTagStructure()"); return; } string currString="",newTag=""; int size=ArraySize(array),structureSize=ArraySize(structure); if (size==0) { Alert("Zero-size array is passed for processing to function FillTagStructure()"); return; } int newLine=-1000,newPos=-1000; bool tagFounded=false; int lineOpen,posOpen,lineClose,posClose,line_,pos_; FindInArray(array,line,pos,lineOpen,posOpen,"<"); if (lineOpen!=-1 && posOpen!=-1) { FindInArray(array,lineOpen,posOpen+1,lineClose,posClose,">"); FindInArray(array,lineOpen,posOpen+1,line_,pos_,""); if (lineClose !=-1) // a closing angle bracket is found { newTag=getTagFromArray(array,lineOpen,posOpen,lineClose,posClose,line_,pos_); newLine=lineClose; newPos=posClose+1; tagFounded=true; } else { Print("Closing angle bracket is not found in function FillTagStructure()" ); return; } } if (tagFounded) { ArrayResize(structure,structureSize+1); structure[structureSize]=newTag; FillTagStructure(structure,array,newLine,newPos); } //---- return; }
Bitte beachten Sie, dass im Falle der erfolgreichen Suche nach einem Tag, die Größe des die tag-Struktur darstellenden Arrays um eins erhöht wird, ein neuer Tag wird hinzugefügt und dann ruft die Funktion rekursiv sich selbst auf.

Abb. 3. Ein Beispiel der rekursiven Funktion: FillTagStructure() ruft sich selbst auf.
Diese Methode des Schreibens von Funktionen für fortlaufende Berechnungen ist sehr interessant und verbessert oft das Los eines Programmierers. Basierend auf dieser Funktion wurde das Skript TagsFromHTML.mq4 entwickelt, das in dem Tester-Berichtnach Tags sucht, StrategyTester.html, und alle gefundenen Tags in der Protokolldatei anzeigt.
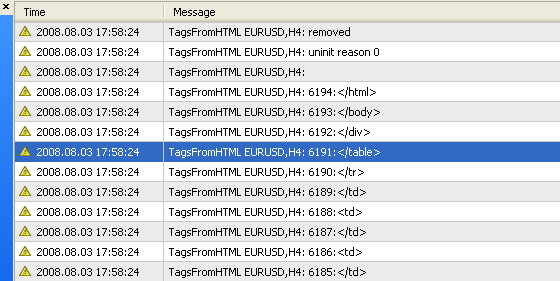
Abb. 4. Ergebnis der Operation von Skript TagsFromHTML.mq4: Die Tag-Nummer und das Tag selbst werden angezeigt.
Wie Sie sehen, kann ein Test-Bericht einige tausend Tags enthalten. In Abb. 4 können Sie sehen, dass das letzte gefundene Tag, </html>, die Nummer 6194 hat. Es ist unmöglich eine derart große Menge an Tags manuell zu durchsuchen.
In Tags Eingeschlossene Inhalte Abrufen
Die Suche nach Tags ist eine zugehörige Aufgabe, die Hauptaufgabe ist, die in Tags eingefassten Informationen zu erhalten. Wenn wir den Inhalt der Datei StrategyTester.html mit einem Texteditor ansehen, z.B. Notepad, können wir sehen, dass die Daten des Berichts zwischen Tags <table> und </table> platziert sind. Der Tag 'table' dient zur Formatierung tabellarischer Daten und beinhaltet in der Regel viele zwischen den Tags <tr> und </tr> platzierte Zeilen.
Jede Zeile enthält ihrerseits Zeilen, die von den Tags <td> und </td> eingeschlossen sind. Unser Ziel ist es, die wertvollen Inhalte zwischen <td> Tags zu finden und diese Daten in Strings formatiert für unsere Bedürfnisse zu sammeln. Zunächst machen wir einige Änderungen in der Funktion FillTagStructure(), so dass wir beides speichern können, die Tag-Struktur und die Informationen über die Tag Anfangs-/End-Positionen.

Abb. 5. Zusammen mit dem Tag selbst, werden seine Anfangs- und Endposition in dem String-Array in das entsprechende Array geschrieben.
Kennen wir den Tag-Namen und die Koordinaten von Anfang und Ende von jedem Tag, können wir leicht den zwischen zwei aufeinander folgende Tags liegenden Inhalt abrufen. Zu diesem Zweck schreiben wir eine weitere Funktion, GetContent(), die sehr ähnlich ist zu der Funktion getTagFromArray().
//+------------------------------------------------------------------+ //| get the contents of lines within the given range | //+------------------------------------------------------------------+ string GetContent(string array[], int start[1][2],int end[1][2]) { string res = ""; //---- int startLine = start[0][0]; int startPos = start[0][1]; int endtLine = end[0][0]; int endPos = end[0][1]; string currString; for (int i = startLine; i<=endtLine; i++) { currString = array[i]; if (i == startLine && endtLine > startLine) { res = res + StringSubstr(currString, startPos); } if (i > startLine && i < endtLine) { res = res + currString; } if (endtLine > startLine && i == endtLine) { if (endPos > 0) res = res + StringSubstr(currString, 0, endPos); } if (endtLine == startLine && i == endtLine) { if (endPos - startPos > 0) res = res + StringSubstr(currString, startPos, endPos - startPos); } } //---- return(res); }
Jetzt können wie die Inhalte von Tags in jeder für uns komfortablen Form verarbeiten. Sie finden ein Beispiel einer solchen Verarbeitung in dem Skript ReportHTMLtoCSV.mq4. Unten befindet sich die Funktion start() des Skripts:
int start() { //---- int i; string array[]; ReadFileToArray(array, filename,""); int arraySize=ArraySize(array); string tags[]; // array to store tags int startPos[][2];// tag-start coordinates int endPos[][2]; // tag-end coordinates FillTagStructure(tags, startPos, endPos, array, 0, 0); //PrintStringArray(tags, "tags contains tags"); int tagsNumber = ArraySize(tags); string text = ""; string currTag; int start[1][2]; int end[1][2]; for (i = 0; i < tagsNumber; i++) { currTag = tags[i]; //Print(tags[i],"\t\t start pos=(",startPos[i][0],",",startPos[i][1],") \t end pos = (",endPos[i][0],",",endPos[i][1],")"); if (currTag == "<table>") { Print("Beginning of table"); } if (currTag == "<tr>") { text = ""; start[0][0] = -1; start[0][1] = -1; } if (currTag == "<td>") {// coordinates of the initial position for selecting the content between tags start[0][0] = endPos[i][0]; start[0][1] = endPos[i][1]; } if (currTag == "</td>") {// coordinates of the end position for selecting the content between tags end[0][0] = startPos[i][0]; end[0][1] = startPos[i][1]; } if (currTag == "</td>") {// coordinates of the end position for selecting the content between tags end[0][0] = startPos[i][0]; end[0][1] = startPos[i][1]; text = text + GetContent(array, start, end) + ";"; } if (currTag == "</tr>") { Print(text); } if (currTag == "</table>") { Print("End of table"); } } //---- return(0); }
In Abb. 6, sehen Sie, wie eine Protokolldatei mit der Nachricht von diesem Skript und mit Microsoft Excel geöffnet aussieht.
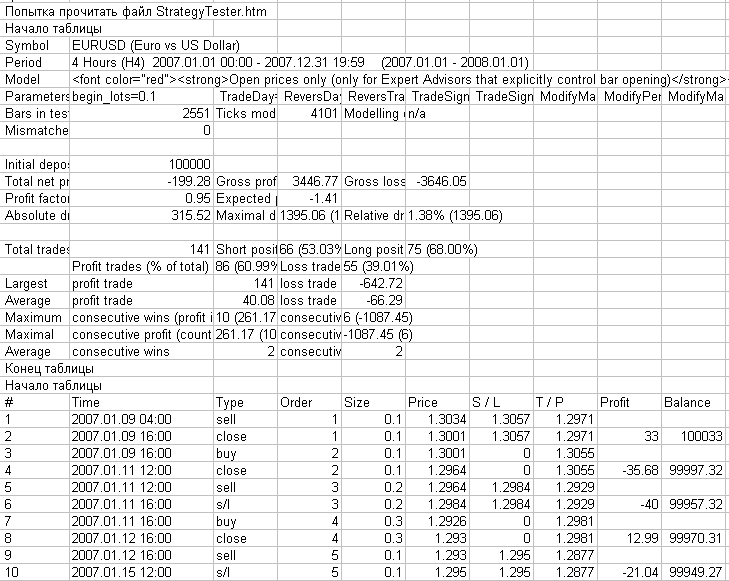
Abb. 6. Protokolldatei aus dem Ordner MetaTrader 4\experts\logs mit den Betriebsergebnissen des Skripts ReportHTMLtoCSV.mq4, geöffnet mit Microsoft Excel.
In Abb. 6 oben können Sie die bekannte Struktur des MetaTrader 4 Test-Berichts sehen.
Fehler dieses Skripts
Es gibt mehrere Arten von Programmierfehlern. Fehler der ersten Art (Syntaxfehler) sind leicht während der Kompilierungsphase zu erkennen. Fehler der zweiten Art sind algorithmisch. Der Programm-Code wurde erfolgreich kompiliert, aber es können unvorhergesehene Situationen in dem Algorithmus auftreten, die zu einem Fehlermuster in dem Programm führen, oder sogar zu seinem Absturz. Diese Fehler sind nicht so leicht zu erkennen, aber es ist trotzdem möglich.
Schließlich kann es Fehler der dritten Art geben, die konzeptionellen. Solche Fehler treten auf, wenn der Programm-Algorithmus, obwohl richtig geschrieben, nicht zur Verwendung des Programms unter etwas anderen Bedingungen bereit ist. Das Skript ReportHTMLtoCSV.mq4 passt gut für die Verarbeitung kleiner HTML Dokumente mit tausenden Tags, aber es ist nicht für Millionen von ihnen. Es hat zwei Flaschenhälse. Der erste ist die mehrfache Größenänderung des Arrays.

Abb. 7. Mehrfache Aufrufe der Funktion ArrayResize() für jeden neu gefundenen Tag.
In dem Prozess der Skript-Operation wird der Aufruf der Funktion ArrayResize() zig, hunderttausende oder gar Millionen Mal, zu einer riesigen Zeitverschwendung führen. Jede dynamische Größenveränderung eines Arrays erfordert etwa Zeit um einen neuen Bereiche der notwendigen Größe in PC-Speicher zu reservieren, und zum Kopieren der Inhalte aus dem alten Array in das neue. Wenn wir eine Array mit einer ziemlich großen Größe im Voraus reservieren, sind wir in der Lage die von diesen exzessiven Operationen beanspruchte Zeit deutlich zu reduzieren. Zum Beispiel, deklarieren wir das Array 'Tags' wie folgt:
string tags[1000000]; // array to store tags
Nun können wir bis zu einer Million Tags hinein schreiben, ohne die Notwendigkeit die Funktion ArrayResize() eine Million Mal aufzurufen!
Der andere Fehler des betrachteten Skripts ReportHTMLtoCSV.mq4 ist die Verwendung der rekursiven Funktion. Jeder FillTagStructure() Funktionsaufruf ist mit der Reservierung von einem Bereich im RAM verbunden, um die erforderliche lokale Variable in diese lokale Kopie der Funktion zu platzieren. Wenn das Dokument 10.000 Tags enthält, wird die Funktion FillTagStructure() 10.000 Mal aufgerufen. Der Speicher, um die rekursive Funktion auszurufen, ist von einem vorläufig reservierten Bereich der Größe, die durch die Anweisung #property stacksize bestimmt wird:
#property stacksize 1000000
In diesem Fall wird der Compiler angewiesen eine Million Byte für den Stack zu reservieren. Wenn der Stackspeicher nicht ausreichend für die Funktionsaufrufe ist, erhalten wir den Fehler Stack Overflow. Wenn wir die rekursive Funktion Millionen Mal aufrufen müssen, kann auch die Reservieren von hunderten Megabyte umsonst gewesen sein. Also müssen wir den Tag-Suchalgorithmus leicht modifizieren, um die Verwendung rekursiver Aufrufe zu vermeiden.
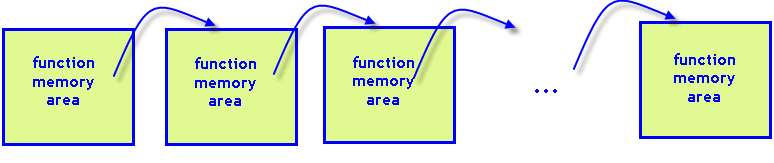
Abb. 8. Jeder rekursive Funktionsaufruf erfordert seinen eigenen Speicherbereich in dem Programmstack.
Wir Werden Einen Anderen Weg Nehmen - Die Neue Funktion FillTagStructure()
Schreiben wir die Funktion zum Abrufen der Tag-Struktur neu. Sie wird nun explizit einen Zyklus für die Arbeit mit dem string array[] vewrwenden. Der Algorithmus der neuen Funktion ist klar, wenn Sie den der alten Funktion verstanden haben.
//+------------------------------------------------------------------+ //| it fills out the tag structure | //+------------------------------------------------------------------+ void FillTagStructure(string & structure[],// tag structure to be created int & start[][], // tag start (line, position) int & end[][], // tag end (line, position) string array[]) // initial html text { //---- int array_Size = ArraySize(array); ArrayResize(structure, capacity); ArrayResize(start, capacity); ArrayResize(end, capacity); int i=0, line, posOpen, pos_, posClose, tagCounter, currPos = 0; string currString; string tag; int curCapacity = capacity; while (i < array_Size) { if (tagCounter >= curCapacity) // if the number of tags exceeds { // the storage capacity ArrayResize(structure, curCapacity + capacity); // increase the storage in size ArrayResize(start, curCapacity + capacity); // also increase the size of the array of start positions ArrayResize(end, curCapacity + capacity); // also increase the size of the array of end positions curCapacity += capacity; // save the new capacity } currString = array[i]; // take the current string //Print(currString); posOpen = StringFind(currString, "<", currPos); // search for the first entrance of '<' after position currPos if (posOpen == -1) // not found { line = i; // go to the next line currPos = 0; // in the new line, search from the very beginning i++; continue; // return to the beginning of the cycle } // we are in this location, so a '<' has been found pos_ = StringFind(currString, "", posOpen); // then search for a space, too posClose = StringFind(currString, ">", posOpen); // search for the closing angle bracket if ((pos_ == -1) && (posClose != -1)) // space is not found, but the bracket is { tag = StringSubstr(currString, posOpen, posClose - posOpen) + ">"; // assemble tag structure[tagCounter] = tag; // written it into tags array setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // we will start the next search for a new tag continue; // from position posClose where a closing bracket has been found } // we are in this location, so both the space and the closing bracket have been found if ((pos_ != -1) && (posClose != -1)) { if (pos_ > posClose) // space is after bracket { tag = StringSubstr(currString, posOpen, posClose - posOpen) + ">"; // assemble tag structure[tagCounter] = tag; // written it to the tags array setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // we will start the next search for a new tag continue; // from position posClose where a closing bracket has been found } // no, the space is still before the closing bracket if (pos_ < posClose) { tag = StringSubstr(currString, posOpen, pos_ - posOpen) + ">"; // assemble tag structure[tagCounter] = tag; // written it to the tags array setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // we will start the next search for a new tag continue; // from position posClose where a closing bracket has been found } } // we are in this location, so neither a space nor a closing bracket have been found if ((pos_ == -1) && (posClose == -1)) { tag = StringSubstr(currString, posOpen) + ">"; // assemble a tag of what we have structure[tagCounter] = tag; // written it to the tags array while (posClose == -1) // and organized a cycle to search for { // the first closing bracket i++; // increase in size the counter of lines currString = array[i]; // count the new line posClose = StringFind(currString, ">"); // and search for a closing bracket in it } setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // it seems to have been found, then set the initial position } // to search for a new tag } ArrayResize(structure, tagCounter); // cut the tags array size down to the number of //---- // tags found return; }
Die Arrays werden nun in Portionen der Kapazität von Elementen angepasst. Der Wert der Kapazität wird bestimmt durch die Deklaration der Konstante:
#define capacity 10000
Die Anfangs- und Endpositionen der Tags sind jetzt festgelegt mit der Funktion setPositions().
//+------------------------------------------------------------------+ //| write the tag coordinates into the corresponding arrays | //+------------------------------------------------------------------+ void setPositions(int & st[][], int & en[][], int counter,int stLine, int stPos, int enLine, int enPos) { //---- st[counter][0] = stLine; st[counter][1] = stPos; en[counter][0] = enLine; en[counter][1] = enPos; //---- return; }
Übrigens brauchen wir die Funktionen FindInArray() und getTagFromArray() nicht mehr. Der vollständige Code ist angegeben in dem Skript ReportHTMLtoCSV-2.mq4 , das hier angehangen ist.
Fazit
Der Algorithmus für die HTML-Dokument Komplettlösung für Tags wurde betrachtet und ein Beispiel, wie man Informationen aus den Strategietester-Bericht entnimmt ist gegeben.
Versuchen Sie nicht massenhafte ArrayResize() Funktionsaufrufe zu verwenden, da dies extrem zeitraubend werden kann.
Außerdem kann die Verwendung rekursiver Funktionen wesentliche RAM-Ressourcen verbrauchen. Wenn massenhafte Aufrufe einer solchen Funktion unternommen werden, versuchen sie es neu zu schreiben, damit keine Rekursion erforderlich ist.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/1544
 Gruppierte Dateioperationen
Gruppierte Dateioperationen
 Wie man Schnelle Nicht-Nachzeichnende ZigZags Schreibt
Wie man Schnelle Nicht-Nachzeichnende ZigZags Schreibt
 Expert Advisors Basierend auf Beliebten Handelssystemen und Alchemie der Handelsroboter Optimierung (Teil VII)
Expert Advisors Basierend auf Beliebten Handelssystemen und Alchemie der Handelsroboter Optimierung (Teil VII)
 Faulheit ist der Reiz zum Fortschritt, oder Wie man mit Grafiken Interaktiv Arbeitet
Faulheit ist der Reiz zum Fortschritt, oder Wie man mit Grafiken Interaktiv Arbeitet
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.