Articles with examples of trading robots developed in MQL5
An Expert Advisor is the 'pinnacle' of programming and the desired goal of every automated trading developer. Read the articles in this section to create your own trading robot. By following the described steps you will learn how to create, debug and test automated trading systems.
The articles not only teach MQL5 programming, but also show how to implement trading ideas and techniques. You will learn how to program a trailing stop, how to apply money management, how to get the indicator values, and much more.
Add a new article

You are missing trading opportunities:
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
Registration
Log in
You agree to website policy and terms of use
If you do not have an account, please register

Learn how to trade the Fair Value Gap (FVG)/Imbalances step-by-step: A Smart Money concept approach
A step-by-step guide to creating and implementing an automated trading algorithm in MQL5 based on the Fair Value Gap (FVG) trading strategy. A detailed tutorial on creating an expert advisor that can be useful for both beginners and experienced traders.

Neural networks made easy (Part 53): Reward decomposition
We have already talked more than once about the importance of correctly selecting the reward function, which we use to stimulate the desired behavior of the Agent by adding rewards or penalties for individual actions. But the question remains open about the decryption of our signals by the Agent. In this article, we will talk about reward decomposition in terms of transmitting individual signals to the trained Agent.

Graphical Interfaces X: Updates for the Rendered table and code optimization (build 10)
We continue to complement the Rendered table (CCanvasTable) with new features. The table will now have: highlighting of the rows when hovered; ability to add an array of icons for each cell and a method for switching them; ability to set or modify the cell text during the runtime, and more.
Neural networks made easy (Part 22): Unsupervised learning of recurrent models
We continue to study unsupervised learning algorithms. This time I suggest that we discuss the features of autoencoders when applied to recurrent model training.

Wrapping ONNX models in classes
Object-oriented programming enables creation of a more compact code that is easy to read and modify. Here we will have a look at the example for three ONNX models.
Understanding Programming Paradigms (Part 2): An Object-Oriented Approach to Developing a Price Action Expert Advisor
Learn about the object-oriented programming paradigm and its application in MQL5 code. This second article goes deeper into the specifics of object-oriented programming, offering hands-on experience through a practical example. You'll learn how to convert our earlier developed procedural price action expert advisor using the EMA indicator and candlestick price data to object-oriented code.
Learn how to trade the Fair Value Gap (FVG)/Imbalances step-by-step: A Smart Money concept approach
A step-by-step guide to creating and implementing an automated trading algorithm in MQL5 based on the Fair Value Gap (FVG) trading strategy. A detailed tutorial on creating an expert advisor that can be useful for both beginners and experienced traders.

Neural networks made easy (Part 44): Learning skills with dynamics in mind
In the previous article, we introduced the DIAYN method, which offers the algorithm for learning a variety of skills. The acquired skills can be used for various tasks. But such skills can be quite unpredictable, which can make them difficult to use. In this article, we will look at an algorithm for learning predictable skills.
Timeseries in DoEasy library (part 57): Indicator buffer data object
In the article, develop an object which will contain all data of one buffer for one indicator. Such objects will be necessary for storing serial data of indicator buffers. With their help, it will be possible to sort and compare buffer data of any indicators, as well as other similar data with each other.

Neural networks made easy (Part 23): Building a tool for Transfer Learning
In this series of articles, we have already mentioned Transfer Learning more than once. However, this was only mentioning. in this article, I suggest filling this gap and taking a closer look at Transfer Learning.

Neural networks made easy (Part 20): Autoencoders
We continue to study unsupervised learning algorithms. Some readers might have questions regarding the relevance of recent publications to the topic of neural networks. In this new article, we get back to studying neural networks.
Learn how to trade the Fair Value Gap (FVG)/Imbalances step-by-step: A Smart Money concept approach
A step-by-step guide to creating and implementing an automated trading algorithm in MQL5 based on the Fair Value Gap (FVG) trading strategy. A detailed tutorial on creating an expert advisor that can be useful for both beginners and experienced traders.

Neural networks made easy (Part 50): Soft Actor-Critic (model optimization)
In the previous article, we implemented the Soft Actor-Critic algorithm, but were unable to train a profitable model. Here we will optimize the previously created model to obtain the desired results.

Neural networks made easy (Part 38): Self-Supervised Exploration via Disagreement
One of the key problems within reinforcement learning is environmental exploration. Previously, we have already seen the research method based on Intrinsic Curiosity. Today I propose to look at another algorithm: Exploration via Disagreement.

Implementing the Generalized Hurst Exponent and the Variance Ratio test in MQL5
In this article, we investigate how the Generalized Hurst Exponent and the Variance Ratio test can be utilized to analyze the behaviour of price series in MQL5.

Neural networks made easy (Part 43): Mastering skills without the reward function
The problem of reinforcement learning lies in the need to define a reward function. It can be complex or difficult to formalize. To address this problem, activity-based and environment-based approaches are being explored to learn skills without an explicit reward function.

Neural networks made easy (Part 66): Exploration problems in offline learning
Models are trained offline using data from a prepared training dataset. While providing certain advantages, its negative side is that information about the environment is greatly compressed to the size of the training dataset. Which, in turn, limits the possibilities of exploration. In this article, we will consider a method that enables the filling of a training dataset with the most diverse data possible.
Learn how to trade the Fair Value Gap (FVG)/Imbalances step-by-step: A Smart Money concept approach
A step-by-step guide to creating and implementing an automated trading algorithm in MQL5 based on the Fair Value Gap (FVG) trading strategy. A detailed tutorial on creating an expert advisor that can be useful for both beginners and experienced traders.

Neural networks made easy (Part 35): Intrinsic Curiosity Module
We continue to study reinforcement learning algorithms. All the algorithms we have considered so far required the creation of a reward policy to enable the agent to evaluate each of its actions at each transition from one system state to another. However, this approach is rather artificial. In practice, there is some time lag between an action and a reward. In this article, we will get acquainted with a model training algorithm which can work with various time delays from the action to the reward.

Experiments with neural networks (Part 4): Templates
In this article, I will use experimentation and non-standard approaches to develop a profitable trading system and check whether neural networks can be of any help for traders. MetaTrader 5 as a self-sufficient tool for using neural networks in trading. Simple explanation.

Neural networks made easy (Part 48): Methods for reducing overestimation of Q-function values
In the previous article, we introduced the DDPG method, which allows training models in a continuous action space. However, like other Q-learning methods, DDPG is prone to overestimating Q-function values. This problem often results in training an agent with a suboptimal strategy. In this article, we will look at some approaches to overcome the mentioned issue.
Multilayer perceptron and backpropagation algorithm (Part 3): Integration with the Strategy Tester - Overview (I).
The multilayer perceptron is an evolution of the simple perceptron which can solve non-linear separable problems. Together with the backpropagation algorithm, this neural network can be effectively trained. In Part 3 of the Multilayer Perceptron and Backpropagation series, we'll see how to integrate this technique into the Strategy Tester. This integration will allow the use of complex data analysis aimed at making better decisions to optimize your trading strategies. In this article, we will discuss the advantages and problems of this technique.

Category Theory in MQL5 (Part 7): Multi, Relative and Indexed Domains
Category Theory is a diverse and expanding branch of Mathematics which is only recently getting some coverage in the MQL5 community. These series of articles look to explore and examine some of its concepts & axioms with the overall goal of establishing an open library that provides insight while also hopefully furthering the use of this remarkable field in Traders' strategy development.

Neural networks made easy (Part 47): Continuous action space
In this article, we expand the range of tasks of our agent. The training process will include some aspects of money and risk management, which are an integral part of any trading strategy.

Data Science and ML (Part 22): Leveraging Autoencoders Neural Networks for Smarter Trades by Moving from Noise to Signal
In the fast-paced world of financial markets, separating meaningful signals from the noise is crucial for successful trading. By employing sophisticated neural network architectures, autoencoders excel at uncovering hidden patterns within market data, transforming noisy input into actionable insights. In this article, we explore how autoencoders are revolutionizing trading practices, offering traders a powerful tool to enhance decision-making and gain a competitive edge in today's dynamic markets.

How to build and optimize a volatility-based trading system (Chaikin Volatility - CHV)
In this article, we will provide another volatility-based indicator named Chaikin Volatility. We will understand how to build a custom indicator after identifying how it can be used and constructed. We will share some simple strategies that can be used and then test them to understand which one can be better.
Neural networks made easy (Part 34): Fully Parameterized Quantile Function
We continue studying distributed Q-learning algorithms. In previous articles, we have considered distributed and quantile Q-learning algorithms. In the first algorithm, we trained the probabilities of given ranges of values. In the second algorithm, we trained ranges with a given probability. In both of them, we used a priori knowledge of one distribution and trained another one. In this article, we will consider an algorithm which allows the model to train for both distributions.

Automated exchange grid trading using stop pending orders on Moscow Exchange (MOEX)
The article considers the grid trading approach based on stop pending orders and implemented in an MQL5 Expert Advisor on the Moscow Exchange (MOEX). When trading in the market, one of the simplest strategies is a grid of orders designed to "catch" the market price.

Introduction to MQL5 (Part 4): Mastering Structures, Classes, and Time Functions
Unlock the secrets of MQL5 programming in our latest article! Delve into the essentials of structures, classes, and time functions, empowering your coding journey. Whether you're a beginner or an experienced developer, our guide simplifies complex concepts, providing valuable insights for mastering MQL5. Elevate your programming skills and stay ahead in the world of algorithmic trading!

Neural networks made easy (Part 60): Online Decision Transformer (ODT)
The last two articles were devoted to the Decision Transformer method, which models action sequences in the context of an autoregressive model of desired rewards. In this article, we will look at another optimization algorithm for this method.

Neural networks made easy (Part 39): Go-Explore, a different approach to exploration
We continue studying the environment in reinforcement learning models. And in this article we will look at another algorithm – Go-Explore, which allows you to effectively explore the environment at the model training stage.
Seasonality Filtering and time period for Deep Learning ONNX models with python for EA
Can we benefit from seasonality when creating models for Deep Learning with python? Does filtering data for the ONNX models help to get better results? What time period should we use? We will cover all of this over this article.

Integrating ML models with the Strategy Tester (Conclusion): Implementing a regression model for price prediction
This article describes the implementation of a regression model based on a decision tree. The model should predict prices of financial assets. We have already prepared the data, trained and evaluated the model, as well as adjusted and optimized it. However, it is important to note that this model is intended for study purposes only and should not be used in real trading.
Neural networks made easy (Part 45): Training state exploration skills
Training useful skills without an explicit reward function is one of the main challenges in hierarchical reinforcement learning. Previously, we already got acquainted with two algorithms for solving this problem. But the question of the completeness of environmental research remains open. This article demonstrates a different approach to skill training, the use of which directly depends on the current state of the system.

Neural networks made easy (Part 51): Behavior-Guided Actor-Critic (BAC)
The last two articles considered the Soft Actor-Critic algorithm, which incorporates entropy regularization into the reward function. This approach balances environmental exploration and model exploitation, but it is only applicable to stochastic models. The current article proposes an alternative approach that is applicable to both stochastic and deterministic models.

Introduction to MQL5 (Part 3): Mastering the Core Elements of MQL5
Explore the fundamentals of MQL5 programming in this beginner-friendly article, where we demystify arrays, custom functions, preprocessors, and event handling, all explained with clarity making every line of code accessible. Join us in unlocking the power of MQL5 with a unique approach that ensures understanding at every step. This article sets the foundation for mastering MQL5, emphasizing the explanation of each line of code, and providing a distinct and enriching learning experience.

Neural networks made easy (Part 68): Offline Preference-guided Policy Optimization
Since the first articles devoted to reinforcement learning, we have in one way or another touched upon 2 problems: exploring the environment and determining the reward function. Recent articles have been devoted to the problem of exploration in offline learning. In this article, I would like to introduce you to an algorithm whose authors completely eliminated the reward function.

Quantitative analysis in MQL5: Implementing a promising algorithm
We will analyze the question of what quantitative analysis is and how it is used by major players. We will create one of the quantitative analysis algorithms in the MQL5 language.

Neural networks made easy (Part 46): Goal-conditioned reinforcement learning (GCRL)
In this article, we will have a look at yet another reinforcement learning approach. It is called goal-conditioned reinforcement learning (GCRL). In this approach, an agent is trained to achieve different goals in specific scenarios.
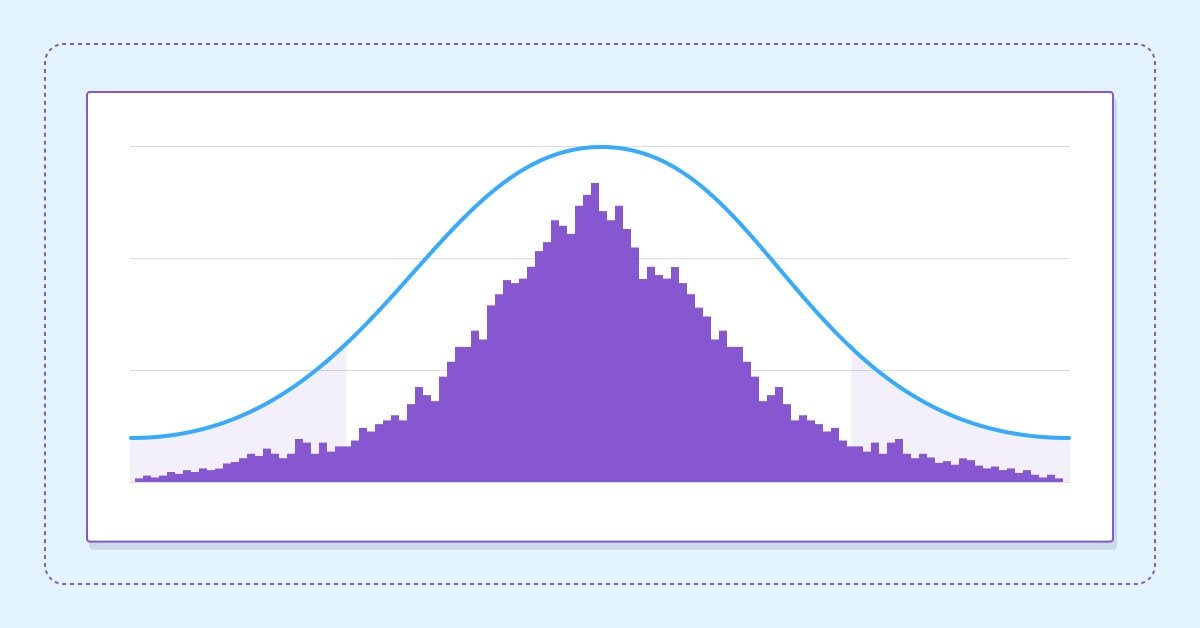
Estimate future performance with confidence intervals
In this article we delve into the application of boostrapping techniques as a means to estimate the future performance of an automated strategy.