
交易中的神经网络:使用语言模型进行时间序列预测

概述
贯穿本系列文章,我们已探讨了多种时间序列建模的架构方式。这些方式当中有许多都达成了值得称道的结果。然而,很明显,它们未能充分发挥时间序列中存在的复杂形态的优势,例如季节性、和趋势。这些分量是基本的时间序列区分特征数据。由此,最近的研究表明,基于深度学习的架构也许并不像以前认为的那样健壮,即使是浅层神经网络、或线性模型在某些基准测试中比它们出色。
与此同时,自然语言处理(NLP)、和计算机视觉(CV)中涌现的基本模型,标示着有效表示学习的显要里程碑。针对时间序列运营大数据预训练基础模型,可增强后续任务的性能。甚至,大语言模型能启用预训练的表示,取代从头开始训练模型的需求。然而,语言模型中现有的基础结构和方法并不能完全捕捉到时间形态的演变,而这对于时间序列建模至关重要。
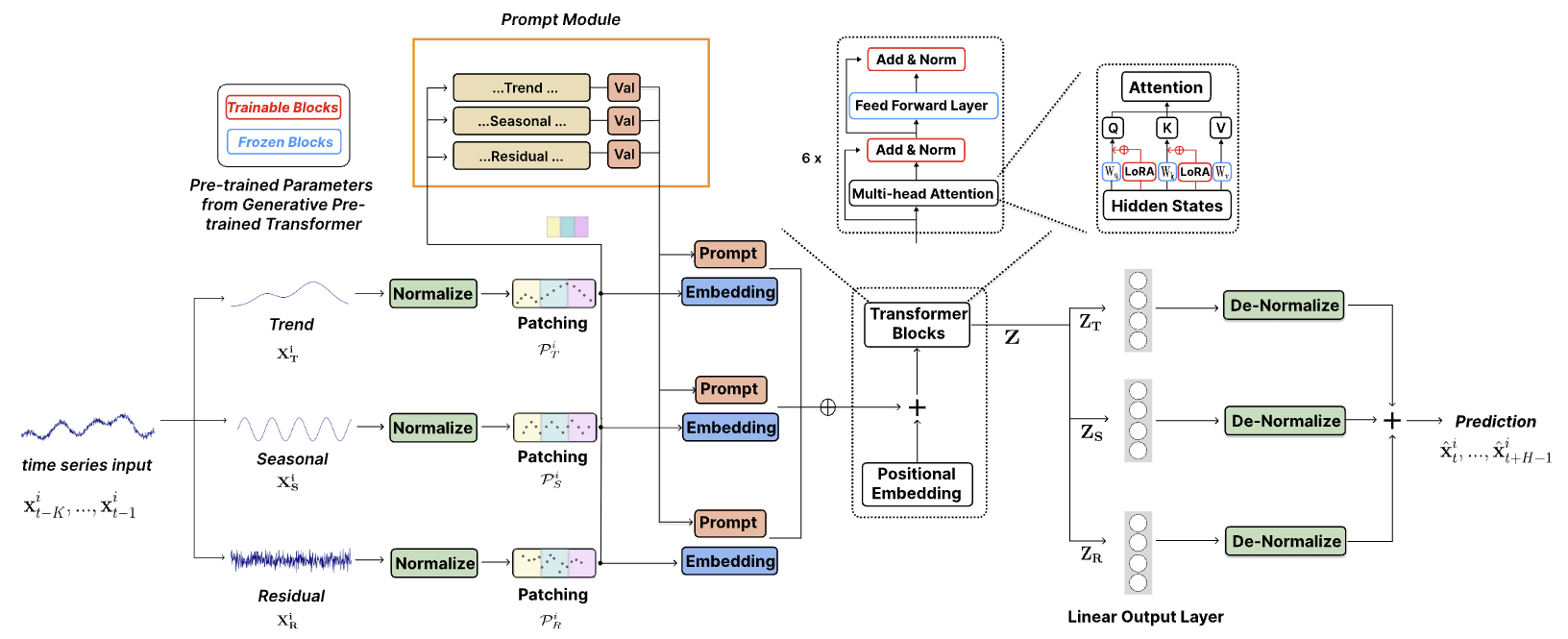
论文《TEMPO:基于提示的生成式预训练变换器进行时间序列预测》的作者解决了大型预训练模型适配时间序列预测的关键挑战。他们提出了 TEMPO,这是一个基于 GPT 的综合模型,设计用于有效的时间序列表示学习。TEMPO 由两个关键的分析分量组成:一个专注于针对特定时间序列形态(如趋势和季节性)建模,另一个旨在经由基于提示的方式从内部数据属性中提取更普适的见解。具体说,TEMPO 首先将原始多模态时间序列数据分解为三个分量:趋势、季节性、和残差。然后将每个分量映射到相应的潜在空间,从而构造 GPT 的初始时间序列嵌入。
作者将时间序列域与频域联系起来进行了正式分析,强调在时间序列分析时分解这些分量的必要性。他们还从理论上证明了注意力机制难以执行这种自动分解。
TEMPO 使用提示来解码有关趋势和季节性的时态知识,高效优调 GPT 执行预测任务。此外,趋势、季节性、和残差也被用来提供可解释的结构,帮助理解原始分量之间的交互。
1. TEMPO 算法
TEMPO 的作者在他们的工作中采用了一种混合方式,结合了时间序列统计分析的稳健性、与数据驱动方法的适应性。它们引入了一种创新,把季节性和趋势分解整合到基于变换器架构的预训练语言模型。该策略糅合了统计和机器学习方法两者的独特优势,增强了模型高效处理时间序列数据的能力。
此外,他们还引入了一种半软性基于提示的方法,提升了预训练模型针对时间序列处理的适应性。这种创新技术令模型能够与广博的预训练知识集成在一起,满足特殊时间序列分析需求。
对于多模态时间序列数据,将复杂的原生数据分解为有意义的分量(如趋势和季节性)有助于优化信息提取。
![]()
趋势分量 XT 捕获数据中的长期形态。季节性分量 XS 封装了重复性的短周期,评估是在去除趋势后进行。残差分量 XR 表示提取趋势和季节性后数据的剩余部分。
在实践中,建议尽可能多的利用这些信息进行更准确的分解。然而,为了维护计算效率,作者选用固定大小窗口进行局部分解,而非覆盖整个数据集进行全局分解。引入可训练参数来评估局局部分解的各种分量,并将该原理扩展到其他模型分量。
实验结果表明,分解显著简化了预测过程。
所提议原生数据分解对于基于现代变换器架构至关重要,因为注意力机制理论上无法自动拆解单向趋势和季节性信号。如果趋势和季节性分量是非正交的,则无法使用任何一组正交底数将它们完全分离。自注意力层自然地转换为正交变换,类似于主分量分析。因此,直接关注原生时间序列数据,对于拆解非正交趋势和季节性分量是无效的。
TEMPO 方法首先把可逆归一化应用到每个全局分量,以便促进信息传输,并把分布偏移引至的损失最小化。
此外,还实现了基于均方误差(MSE)的重造损失函数,以确保局部分解分量、与在训练数据集中观察到的全局分解对齐。
接下来,在时间序列数据中添加位置编码进行分段,将相邻时间步聚合到令牌,并提取局部语义。这显著扩展了历史横向范围,同时降低了冗余。
然后,出品的时间序列令牌将经由嵌入层传递。这些学成的嵌入令语言模型架构能够有效地将其能了转移到时间序列数据的新顺序模态。
提示技术以其在精心设计的提示中应用先验知识编码,已在各种应用中表现出卓越成效。这一成功归属于提示提供的结构,即模型输出与预期目标对齐。这强化了准确性、一致性、以及整体内容品质。为致力于利用不同时间序列分量中的固有丰富语义信息,作者引入了一种软性提示策略。该方式生成与每个主要时间序列分量对应的不同提示:趋势、季节性、和残差。这些提示与各自的原生数据分量相结合,能启用更高级的序列建模方式,以便计量时间序列数据的多面性本质。
该结构将每个数据实例与特定的提示相关联,作为归纳乖离,连结编码关键的预测相关信息。应当注意的是,所提议动态框架维护了高度的适应性,确保与广泛时间序列分析的兼容性。这种适应性凸显出提示策略随着不同时间序列数据集所呈现的复杂度而拓展的潜力。
TEMPO 的作者采用基于解码器的 GPT 模型作为时间序列表示学习的基础结构。为了有效地利用分解出的语义信息,将提示和各种分量集成,并通过 GPT 模块传递。
一种替代方式涉及针对不同类型的时间序列分量使用单独的 GPT 模块。
总体预测随后衍生为各个分量预测的组合。每个分量在通过 GPT 模块后,通过一个完全连接层进行处理,来生成预测。通过合并在归一化期间提取的相应统计参数,最终预测将投影回原始数据空间。汇总各个分量预测,重造全部的时间序列轨迹。
下面提供了作者对 TEMPO 方法的可视化。
2. 利用 MQL5 实现
在研究了 TEMPO 方法的理论层面之后,我们转到本文的实践部分,其中我们会利用 MQL5 实现我们对所提议方法的愿景。
重点要注意,很遗憾,我们无法访问预训练语言模型。结果如是,我们无法完全评估语言模型表达时间序列预测的可变换性。不过,我们可以复现提议的架构框架,并评估其依据真实历史数据预测金融时间序列的有效性。
在转到考察代码之前,我们首先审阅实现中采用的架构选择。
收入的原生数据被分解为三个分量:趋势、季节性、和残差。为了提取趋势,该方法作者计算输入数据平均值时使用了一个滑动窗口。通俗讲类似于标准的移动平均指标。在我们的实现中,我选择了之前讨论过的分段线性表示(PLR)方法。以我观点,这是一种信息更丰富的方法,拥有识别不同长度趋势的能力。然而,由于 PLR 结果不能直接从原始序列中减除,因此需要额外的算法改进,我们将在实现期间探讨。
关于季节性提取,频谱方式是当然的选择。然而,由于离散傅里叶变换(DFT)能以频域完全表示时间序列,因此逆 DFT(iDFT)能重造原始时间序列而不会失真。为了将季节性分量与噪声和异常值隔离开来,我们需要截断某些频段。故此,下一个问题是哪个量级和频率列表需要重置。这个问题没有明确的答案。我们曾在按频域进行时间序列预测中讨论过类似问题。但这次我从一个稍微不同的角度来接手这个问题。在我们的数据分析中,我们用到一种与金融工具相关的多模态时间序列。并且可以预期,它的各个分量的周期将彼此一致。那么,为何不用自注意力机制来识别独立单一时间序列频谱中的一致性频率呢?我们预计匹配的频谱频率能凸显出季节性分量。
以这种方式,我们可将原始数据分离为由 TEMPO 方法提供的各个分量。所构造模型的操作已部分阐述。我们已有一个完备的方案,可把单一模型分解为单个分段,并嵌入它们。基于变换器架构的解决方案也是如此。什么是提示?该方法的作者提议使用提示来推动 GPT 模型按预期上下文生成序列。在这项工作中,我决定采用 PLR 输出作为提示。
大概最后一个全局问题要涉及到所用注意力模型的数量:一个通用模型、或每个分量一个模型。我选择采用通用模型,因为它允许将整个数据处理过程,规划为可同时工作的并行流。而每个分量采用单独模型,其结果会是按顺序处理。反之,这将提升训练模型、及随后制定决策两者的时间。
我们已讨论了正在构建的模型要点,现在可转到实际工作。
2.1扩展 OpenCL 程序
我们从 OpenCL 程序端创建新内核来开始我们的工作。如上所述,为了从原始数据的多模态时间序列中提取主要趋势,我们将使用分段线性表示方法(PLR),其会涉及将每个分段表示为 3 个值:斜率、偏移量、和分段尺寸。显然,给出的这种时间序列表示形式,要从原始数据中减除趋势是相当困难的。不过,这是可能的。为了实现该功能,我们来创建一个 CutTrendAndOther 内核。在参数中,该内核接收 4 个指向数据缓冲区的指针。其中 2 个包含张量形式的输入时间序列(inputs),和分段线性表示张量 (plr)。我们将操作结果保存在其它 2 个缓冲区当中:
- trend – 常规时间序列形式的趋势
- other – 原始数据与趋势线之间的差值
__kernel void CutTrendAndOther(__global const float *inputs, __global const float *plr, __global float *trend, __global float *other ) { const size_t i = get_global_id(0); const size_t lenth = get_global_size(0); const size_t v = get_global_id(1); const size_t variables = get_global_size(1);
我们计划在 2-维任务空间中调用这个内核。第一个维度表示输入数据序列的大小,第二个维度表示正分析变量(单一序列)的数量。在内核主体中,我们在任务空间所有维度中识别当前线程。
之后,我们可以声明必要的常量。
//--- constants const int shift_in = i * variables + v; const int step_in = variables; const int shift_plr = v; const int step_plr = 3 * step_in;
下一步是找到序列的当前元素所属的分段线性表示。为此,我们创建一个循环,并迭代覆盖全部分段。
//--- calc position int pos = -1; int prev_in = 0; int dist = 0; do { pos++; prev_in += dist; dist = (int)fmax(plr[shift_plr + pos * step_plr + 2 * step_in] * lenth, 1); } while(!(prev_in <= i && (prev_in + dist) > i));
基于已发现分段的参数,我们将判定当前点的趋势线值,及其与原始时间序列值的偏差。
//--- calc trend float sloat = plr[shift_plr + pos * step_plr]; float intercept = plr[shift_plr + pos * step_plr + step_in]; pos = i - prev_in; float trend_i = sloat * pos + intercept; float other_i = inputs[shift_in] - trend_i;
现在我们只需把输出值保存到全局结果缓冲区的相应元素之中。
//--- save result
trend[shift_in] = trend_i;
other[shift_in] = other_i;
}
类似地,我们将构造一个误差梯度派发内核,CutTrendAndOtherGradient,贯穿上述操作进行反向传播通验。该内核在其参数中接收类似指向含有误差梯度的数据缓冲区的指针。
__kernel void CutTrendAndOtherGradient(__global float *inputs_gr, __global const float *plr, __global float *plr_gr, __global const float *trend_gr, __global const float *other_gr ) { const size_t i = get_global_id(0); const size_t lenth = get_global_size(0); const size_t v = get_global_id(1); const size_t variables = get_global_size(1);
于此,我们使用相同 2-维任务空间,并于其中标识当前线程。之后,我们定义常量值。
//--- constants const int shift_in = i * variables + v; const int step_in = variables; const int shift_plr = v; const int step_plr = 3 * step_in;
接下来,我们重复算法搜索所需的分段。
//--- calc position int pos = -1; int prev_in = 0; int dist = 0; do { pos++; prev_in += dist; dist = (int)fmax(plr[shift_plr + pos * step_plr + 2 * step_in] * lenth, 1); } while(!(prev_in <= i && (prev_in + dist) > i));
但这一次,我们计算了分段参数误差梯度。
//--- get gradient float other_i_gr = other_gr[shift_in]; float trend_i_gr = trend_gr[shift_in] - other_i_gr; //--- calc plr gradient pos = i - prev_in; float sloat_gr = trend_i_gr * pos; float intercept_gr = trend_i_gr;
我们将结果保存在数据缓冲区之中。
//--- save result
plr_gr[shift_plr + pos * step_plr] += sloat_gr;
plr_gr[shift_plr + pos * step_plr + step_in] += intercept_gr;
inputs_gr[shift_in] = other_i_gr;
}
注意,我们并非覆盖,而是将误差梯度附加到 PRP 梯度缓冲区中的现有数据。这是由于事实上,我们计划在 2 个方向上使用时间序列 PRP 结果:
- 在上述内核中实现的隔离趋势
- 如上所述,作为注意力模型的提示
因此,我们需要从 2 个方向收集误差梯度。为了剔除使用额外的缓冲区,及 2 个缓冲区数值求和的不必要操作,我们在该内核中实现了求和。
此外,我们还创建了内核 CutOneFromAnother 和 CutOneFromAnotherGradient,以便将季节性分量与其它数据分离。这些内核的算法非常简单,字面上由 2-3 行代码组成。我想您能自行领悟而不会有任何麻烦。附件中包含本文中用到的所有程序的完整代码。
OpenCL 程序端的操作至此完毕。接下来,我们转到主要代码库的工作。
2.2创建 TEMPO 方法类
在主程序端,我们将为所研究的 TEMPO 方法构建一个相当复杂和综合性的算法。您或许已注意到,所提议方法具有复杂的分支数据流结构。也许,在一个类的框架内实现整个方式的情况下,将显著提升所提议方式的利用效率。
为了实现所提议方式,我们将创建 CNeuronTEMPOOCL 类,其将继承全连接层基类 CNeuronBaseOCL 的主要功能。下面是新类的丰富结构。它既包含我们以前作品中已熟悉的元素,也包含了全新的元素。在实现其方法的过程中,我们将更加精通新类结构中每个元素的功能。
class CNeuronTEMPOOCL : public CNeuronBaseOCL { protected: //--- constants uint iVariables; uint iSequence; uint iForecast; uint iFFT; //--- Trend CNeuronPLROCL cPLR; CNeuronBaseOCL cTrend; //--- Seasons CNeuronBaseOCL cInputSeasons; CNeuronTransposeOCL cTranspose[2]; CBufferFloat cInputFreqRe; CBufferFloat cInputFreqIm; CNeuronBaseOCL cInputFreqComplex; CNeuronBaseOCL cNormFreqComplex; CBufferFloat cMeans; CBufferFloat cVariances; CNeuronComplexMLMHAttention cFreqAtteention; CNeuronBaseOCL cUnNormFreqComplex; CBufferFloat cOutputFreqRe; CBufferFloat cOutputFreqIm; CNeuronBaseOCL cOutputTimeSeriasRe; CBufferFloat cOutputTimeSeriasIm; CBufferFloat cZero; //--- Noise CNeuronBaseOCL cResidual; //--- Forecast CNeuronBaseOCL cConcatInput; CNeuronBatchNormOCL cNormalize; CNeuronPatching cPatching; CNeuronBatchNormOCL cNormalizePLR; CNeuronPatching cPatchingPLR; CNeuronPositionEncoder acPE[2]; CNeuronMLCrossAttentionMLKV cAttention; CNeuronTransposeOCL cTransposeAtt; CNeuronConvOCL acForecast[2]; CNeuronTransposeOCL cTransposeFrc; CNeuronRevINDenormOCL cRevIn; CNeuronConvOCL cSum; //--- Complex functions virtual bool FFT(CBufferFloat *inp_re, CBufferFloat *inp_im, CBufferFloat *out_re, CBufferFloat *out_im, bool reverse = false); virtual bool ComplexNormalize(void); virtual bool ComplexUnNormalize(void); virtual bool ComplexNormalizeGradient(void); virtual bool ComplexUnNormalizeGradient(void); //--- bool CutTrendAndOther(CBufferFloat *inputs); bool CutTrendAndOtherGradient(CBufferFloat *inputs_gr); bool CutOneFromAnother(void); bool CutOneFromAnotherGradient(void); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; //--- public: CNeuronTEMPOOCL(void) {}; ~CNeuronTEMPOOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint sequence, uint variables, uint forecast, uint heads, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronTEMPOOCL; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); //--- virtual CBufferFloat *getWeights(void) override; };
注意,尽管嵌套对象种类繁多,但它们都声明为静态。这允许我们将类的构造函数和析构函数留空。类对象被删除之后,与释放内存相关的所有操作都会由系统自身执行。
所有嵌套对象和变量都在 Init 方法中初始化。如常,在方法参数中,我们会收到主要参数,允许我们为所创建层定义独特架构。这些参数我们已很熟悉了:
- sequence — 所分析多模态时间序列的大小
- variables — 所分析变量的数量(单一序列)
- Forecast — 预测值的计划深度
- heads — 在所用自注意力机制中的注意力头数量
- layers — 注意力模块中的层数。
bool CNeuronTEMPOOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint sequence, uint variables, uint forecast, uint heads, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { //--- base if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, forecast * variables, optimization_type, batch)) return false;
在初始化继承对象的方法主体中,我们如常调用父类同名方法。除了初始化继承的对象之外,父类方法还实现针对所接收参数的必要验证。
父类方法操作成功执行后,我们将收到的参数保存在嵌套变量之中。
//--- constants iVariables = variables; iForecast = forecast; iSequence = MathMax(sequence, 1);
接下来,我们定义信号频率分解操作的数据缓冲区大小。
//--- Calculate FFTsize uint size = iSequence; int power = int(MathLog(size) / M_LN2); if(MathPow(2, power) < size) power++; iFFT = uint(MathPow(2, power));
为了从所分析输入序列中分离出趋势,我们初始化一个序列的分段线性分解对象。
//--- trend if(!cPLR.Init(0, 0, OpenCL, iVariables, iSequence, true, optimization, iBatch)) return false;
然后,我们初始化对象,以常规时间序列的形式写入某些趋势。
if(!cTrend.Init(0, 1, OpenCL, iSequence * iVariables, optimization, iBatch)) return false;
我们把趋势时间序列与初始值的偏差写入一个单独对象之中,其将作为季节性波动选择模块的初始数据。
//--- seasons if(!cInputSeasons.Init(0, 2, OpenCL, iSequence * iVariables, optimization, iBatch)) return false;
此处值得注意的是,获得的初始数据代表一串描述各个时间步骤的多模态数据序列。为了提取单一时间序列的频谱,我们需要转置输入张量。在模块的输出端,我们执行逆向操作。为了实现该功能,我们初始化两个数据转置层。
if(!cTranspose[0].Init(0, 3, OpenCL, iSequence, iVariables, optimization, iBatch)) return false; if(!cTranspose[1].Init(0, 4, OpenCL, iVariables, iSequence, optimization, iBatch)) return false;
我们将信号频率分解的结果保存在两个数据缓冲区之中:一个用于信号的实部,另一个用于虚部。
if(!cInputFreqRe.BufferInit(iFFT * iVariables, 0) || !cInputFreqRe.BufferCreate(OpenCL)) return false; if(!cInputFreqIm.BufferInit(iFFT * iVariables, 0) || !cInputFreqIm.BufferCreate(OpenCL)) return false;
但是对于频域中的注意力模块,我们需要将两个数据缓冲区串联到一个对象。
if(!cInputFreqComplex.Init(0, 5, OpenCL, iFFT * iVariables * 2, optimization, batch)) return false;
不要忘记,在与归一化数据打交道时,模型会展现更稳定的结果。故此,我们创建对象来写入归一化数据,及提取的原始分布的参数。
if(!cNormFreqComplex.Init(0, 6, OpenCL, iFFT * iVariables * 2, optimization, batch)) return false; if(!cMeans.BufferInit(iVariables, 0) || !cMeans.BufferCreate(OpenCL)) return false; if(!cVariances.BufferInit(iVariables, 0) || !cVariances.BufferCreate(OpenCL)) return false;
现在我们已抵达频域中注意力对象的初始化。我要提醒你,根据我们的逻辑,其任务是在多模态数据中识别一致性频率特征,这将有助于我们识别输入数据中的季节性波动。
if(!cFreqAtteention.Init(0, 7, OpenCL, iFFT, 32, heads, iVariables, layers, optimization, batch)) return false;
在这种情况下,我们根据外部参数值,选用注意力头的数量、及注意力模块的层数。
在识别出关键频率特征后,我们执行逆操作。首先,我们将频率返回到其原始分布。
if(!cUnNormFreqComplex.Init(0, 8, OpenCL, iFFT * iVariables * 2, optimization, batch)) return false;
然后我们将信号的实部和虚部分离到单独的数据缓冲区之中
if(!cOutputFreqRe.BufferInit(iFFT * iVariables, 0) || !cOutputFreqRe.BufferCreate(OpenCL)) return false; if(!cOutputFreqIm.BufferInit(iFFT * iVariables, 0) || !cOutputFreqIm.BufferCreate(OpenCL)) return false;
并将它们转换到时域。
if(!cOutputTimeSeriasRe.Init(0, 9, OpenCL, iFFT * iVariables, optimization, iBatch)) return false; if(!cOutputTimeSeriasIm.BufferInit(iFFT * iVariables, 0) || !cOutputTimeSeriasIm.BufferCreate(OpenCL)) return false;
接下来,我们创建一个填充零值的辅助缓冲区,其将用于填充空值。
if(!cZero.BufferInit(iFFT * iVariables, 0) || !cZero.BufferCreate(OpenCL)) return false;
我们的季节性分量选择模块的工作完毕。我们将信号的差异隔离到信号第三个分量的单独对象之中。
//--- Noise if(!cResidual.Init(0, 10, OpenCL, iSequence * iVariables, optimization, iBatch)) return false;
将原始数据信号切分到 3 个分量之后,我们转到 TEMPO 算法的下一阶段 – 后续值预测。在此,我们首先将来自三个分量的数据串联至一个张量之中。
//--- Forecast if(!cConcatInput.Init(0, 11, OpenCL, 3 * iSequence * iVariables, optimization, iBatch)) return false;
之后,我们对齐数据。
if(!cNormalize.Init(0, 12, OpenCL, 3 * iSequence * iVariables, iBatch, optimization)) return false;
接下来,我们需要对单一序列进行分割,由于每个单一序列被分解为三个分量,故现在多了 3 倍。
int window = MathMin(5, (int)iSequence - 1); int patches = (int)iSequence - window + 1; if(!cPatching.Init(0, 13, OpenCL, window, 1, 8, patches, 3 * iVariables, optimization, iBatch)) return false; if(!acPE[0].Init(0, 14, OpenCL, patches, 3 * 8 * iVariables, optimization, iBatch)) return false;
我们将往生成的分段里添加定位编码。
针对输入时间序列的分段线性表示执行类似的操作。
int plr = cPLR.Neurons(); if(!cNormalizePLR.Init(0, 15, OpenCL, plr, iBatch, optimization)) return false; plr = MathMax(plr/(3 * (int)iVariables),1); if(!cPatchingPLR.Init(0, 16, OpenCL, 3, 3, 8, plr, iVariables, optimization, iBatch)) return false; if(!acPE[1].Init(0, 17, OpenCL, plr, 8 * iVariables, optimization, iBatch)) return false;
我们初始化交叉注意力层,它将在原始时间序列的分段线性表示的上下文中分析分解为三个分量的信号。
if(!cAttention.Init(0, 18, OpenCL, 3 * 8 * iVariables, 3 * iVariables, MathMax(heads, 1), 8 * iVariables, MathMax(heads / 2, 1), patches, plr, MathMax(layers, 1), 2, optimization, iBatch)) return false;
处理之后,我们转到后续数据预测。于此我们意识到,如同频率分解的情况,我们需要预测单一序列的数据。为此,我们首先需要转置数据。
if(!cTransposeAtt.Init(0, 19, OpenCL, patches, 3 * 8 * iVariables, optimization, iBatch)) return false;
接下来,我们用到一个由两个连续卷积层组成的模块,它将执行预测独立单一序列中数据的作用。第一层将针对每个嵌入元素预测单一序列。
if(!acForecast[0].Init(0, 20, OpenCL, patches, patches, iForecast, 3 * 8 * iVariables, optimization, iBatch)) return false; acForecast[0].SetActivationFunction(LReLU);
第二个将嵌入序列折叠为原始数据分析分量的单一序列。
if(!acForecast[1].Init(0, 21, OpenCL, 8 * iForecast, 8 * iForecast, iForecast, 3 * iVariables, optimization, iBatch)) return false; acForecast[1].SetActivationFunction(TANH);
之后,我们将预测值的张量返回到预期结果的维度。
if(!cTransposeFrc.Init(0, 22, OpenCL, 3 * iVariables, iForecast, optimization, iBatch)) return false;
我们将获得的数值投影到所分析分量的原始分布之中。为此,我们在数据归一化期间加上删除的统计参数。
if(!cRevIn.Init(0, 23, OpenCL, 3 * iVariables * iForecast, 11, GetPointer(cNormalize))) return false;
为了获得目标变量的预测值,我们需要把各个分量的预测值相加。我决定用卷积层内可训练参数的加权和,来代替简单的求和运算。
if(!cSum.Init(0, 24, OpenCL, 3, 3, 1, iVariables, iForecast, optimization, iBatch)) return false; cSum.SetActivationFunction(None);
为避免不必要的数据复制,我们以相应缓冲区替换指针。
SetActivationFunction(None); SetOutput(cSum.getOutput(), true); SetGradient(cSum.getGradient(), true); //--- return true; }
新类初始化方法的描述完毕。不要忘记监控每个阶段的操作过程。在方法结束时,我们将操作的逻辑值返回给调用方。
对象初始化之后,我们转到下一步,即构建前馈通验算法。为了实现前馈通验,我构建了一定数量的方法,以便对上述内核的执行排队。这种方法的算法对您来讲已很熟悉了。新方法不用任何特定功能。因此,我把这些方法留待独立研究。附件中提供了该类及其所有方法的完整代码。现在,我们转到在 CNeuronTEMPOOCL::feedForward 方法中实现主要的前馈通验算法。
bool CNeuronTEMPOOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- trend if(!cPLR.FeedForward(NeuronOCL)) return false;
在方法参数中,我们收到一个指向上一层对象的指针,其中传递原始数据。我们将该指针转移到嵌套层的前馈方法,并用分段线性表示方法提取趋势。
请注意,在该阶段,我们不会验证收到的指针。这个验证已在我们调用的嵌套对象方法中实现了。组织另一个控制点将是多余的。
一旦趋势判定之后,我们会从原始数据中减除它们的影响。
if(!CutTrendAndOther(NeuronOCL.getOutput())) return false;
我们工作的下一阶段是提取季节性分量。在此,我们首先转置减除趋势后得到的数据。
if(!cTranspose[0].FeedForward(cInputSeasons.AsObject())) return false;
接下来,我们将用快速傅里叶变换来获所得分析信号的频谱。
if(!FFT(cTranspose[0].getOutput(), NULL,GetPointer(cInputFreqRe),GetPointer(cInputFreqIm),false)) return false;
我们将频率特征的实部和虚部串联到一个张量之中
if(!Concat(GetPointer(cInputFreqRe), GetPointer(cInputFreqIm), cInputFreqComplex.getOutput(), 1, 1, iFFT * iVariables)) return false;
并归一化获得的值。
if(!ComplexNormalize()) return false;
然后,在注意力模块中,我们选择频率特征频谱的显要部分。
if(!cFreqAtteention.FeedForward(cNormFreqComplex.AsObject())) return false;
通过执行逆运算,我们以时间序列的形式获得季节性分量。
if(!ComplexUnNormalize()) return false; if(!DeConcat(GetPointer(cOutputFreqRe), GetPointer(cOutputFreqIm), cUnNormFreqComplex.getOutput(), 1, 1, iFFT * iVariables)) return false; if(!FFT(GetPointer(cOutputFreqRe), GetPointer(cOutputFreqIm), GetPointer(cInputFreqRe), GetPointer(cOutputTimeSeriasIm), true)) return false; if(!DeConcat(cOutputTimeSeriasRe.getOutput(), cOutputTimeSeriasRe.getGradient(), GetPointer(cInputFreqRe), iSequence, iFFT - iSequence, iVariables)) return false; if(!cTranspose[1].FeedForward(cOutputTimeSeriasRe.AsObject())) return false;
之后,我们选择第三个分量的值。
//--- Noise if(!CutOneFromAnother()) return false;
从时间序列中提取这三个分量后,我们将它们串联成一个张量。
//--- Forecast if(!Concat(cTrend.getOutput(), cTranspose[1].getOutput(), cResidual.getOutput(), cConcatInput.getOutput(), 1, 1, 1, 3 * iSequence * iVariables)) return false;
注意,在串联数据时,我们按顺序获取每个单独分量的一个元素。这令我们能够把与同一单位序列的同一时间步骤相关的不同分量的元素彼此相邻放置。这个数据序列将允许我们运用卷积层,针对各个分量的预测值进行加权求和,从而在层输出处获得目标预测序列。
接下来,我们对串联分量的张量值进行归一化,这将令我们能够把各个分量与所分析变量值对齐。
if(!cNormalize.FeedForward(cConcatInput.AsObject())) return false;
我们将归一化数据拆分为分段,并为它们创建嵌入。
if(!cPatching.FeedForward(cNormalize.AsObject())) return false;
之后,我们添加定位编码,以便唯一标识张量中每个元素的位置。
if(!acPE[0].FeedForward(cPatching.AsObject())) return false;
以类似的方式,我们为时间序列的分段线性表示准备数据。首先,我们对数据进行归一化。
if(!cNormalizePLR.FeedForward(cPLR.AsObject())) return false;
然后我们将其拆分为多个分段,并添加定位编码。
if(!cPatchingPLR.FeedForward(cPatchingPLR.AsObject())) return false; if(!acPE[1].FeedForward(cPatchingPLR.AsObject())) return false;
现在我们已经准备好了分量表示和提示,我们可以使用注意力模块,其应隔离所分析时间序列表示的主要特征。
if(!cAttention.FeedForward(acPE[0].AsObject(), acPE[1].getOutput())) return false;
然后我们转置数据。
if(!cTransposeAtt.FeedForward(cAttention.AsObject())) return false;
然后使用两层 MLP 预测未来值,其由两个卷积层表示。
if(!acForecast[0].FeedForward(cTransposeAtt.AsObject())) return false; if(!acForecast[1].FeedForward(acForecast[0].AsObject())) return false;
卷积层的使用令我们能够根据独立单一序列来组织序列的独立预测。
我们将预测数据返回到其原始表示。
if(!cTransposeFrc.FeedForward(acForecast[1].AsObject())) return false;
接下来,我们添加原始数据的统计分布参数,其在串联分量张量的归一化过程中被删除。
if(!cRevIn.FeedForward(cTransposeFrc.AsObject())) return false;
在方法结束处,我们将各个分量的预测值相加,从而获得所需的未来值序列。
if(!cSum.FeedForward(cRevIn.AsObject())) return false; //--- return true; }
在此,我想提醒您,通过替换指向结果和误差梯度缓冲区的指针,我们消除了不必要的数据复制。甚至,这令我们能够避免逆向操作 — 在构造反向传播方法时复制误差梯度。
如您所知,在我们的实现中,反向传播通验通常由 2 个方法组成:
- calcInputGradients 根据误差梯度对于整体结果的影响,将误差梯度分派给所有元素,以及
- updateInputWeights 调整模型参数,以便误差最小化。
我们首先执行误差梯度分派操作,以便判定每个模型参数对于整体结果的影响。这些操作表示前馈通验中数据流的相反顺序。
bool CNeuronTEMPOOCL::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; //--- Devide to Trend, Seasons and Noise if(!cRevIn.calcHiddenGradients(cSum.AsObject())) return false;
首先,我们将获得的误差梯度分派到各个分量之间,并根数据归一化参数进行调整。
//--- Forecast gradient if(!cTransposeFrc.calcHiddenGradients(cRevIn.AsObject())) return false;
然后,我们将误差梯度传播到 MLP。
if(!acForecast[1].calcHiddenGradients(cTransposeFrc.AsObject())) return false; if(acForecast[1].Activation() != None && !DeActivation(acForecast[1].getOutput(), acForecast[1].getGradient(), acForecast[1].getGradient(), acForecast[1].Activation()) ) return false; if(!acForecast[0].calcHiddenGradients(acForecast[1].AsObject())) return false;
然后通过交叉注意力层。
//--- Attention gradient if(!cTransposeAtt.calcHiddenGradients(acForecast[0].AsObject())) return false; if(!cAttention.calcHiddenGradients(cTransposeAtt.AsObject())) return false; if(!acPE[0].calcHiddenGradients(cAttention.AsObject(), acPE[1].getOutput(), acPE[1].getGradient(), (ENUM_ACTIVATION)acPE[1].Activation())) return false;
前馈通验中的交叉注意力模块从两个数据线程接收数据:
- 串联分量
- 原始数据的分段线性表示
我们在两个方向上按顺序分派误差梯度。首先是 PLR 方向。
//--- Gradient to PLR if(!cPatchingPLR.calcHiddenGradients(acPE[1].AsObject())) return false; if(!cNormalizePLR.calcHiddenGradients(cPatchingPLR.AsObject())) return false; if(!cPLR.calcHiddenGradients(cNormalizePLR.AsObject())) return false;
然后到串联的分量张量。
//--- Gradient to Concatenate buffer of Trend, Season and Noise if(!cPatching.calcHiddenGradients(acPE[0].AsObject())) return false; if(!cNormalize.calcHiddenGradients(cPatching.AsObject())) return false; if(!cConcatInput.calcHiddenGradients(cNormalize.AsObject())) return false;
接下来,我们将误差梯度分派到各个分量缓冲区之中。
//--- DeConcatenate if(!DeConcat(cTrend.getGradient(), cOutputTimeSeriasRe.getGradient(), cResidual.getGradient(), cConcatInput.getGradient(), 1, 1, 1, 3 * iSequence * iVariables)) return false;
请注意,当串联张量被切分成单独的部分时,每个分量都会收到其误差梯度份额。但还有另一个数据线程。在判定残余噪声分量时,我们从总值中减去季节性分量。因此,季节性分量会影响噪声值,且应该接收噪声误差梯度。我们来调整梯度值。
//--- Seasons if(!CutOneFromAnotherGradient()) return false; if(!SumAndNormilize(cOutputTimeSeriasRe.getGradient(), cTranspose[1].getGradient(), cTranspose[1].getGradient(), 1, false, 0, 0, 0, 1)) return false;
接下来,我们需要为季节性分量时间序列准备误差梯度。当运用逆傅里叶变换方法从频谱形成季节分量时,我们获得了时间序列的实部和虚部。我们按从噪声和串联分量张量获得的值,来判定实部的误差梯度。我们用零值补充缺失的元素。
if(!cOutputTimeSeriasRe.calcHiddenGradients(cTranspose[1].AsObject())) return false; if(!Concat(cOutputTimeSeriasRe.getGradient(), GetPointer(cZero), GetPointer(cInputFreqRe), iSequence, iFFT - iSequence, iVariables)) return false;
对于虚部,我们期望零值。因此,我们将带有相反符号的虚部的值写入误差梯度。
if(!SumAndNormilize(GetPointer(cOutputTimeSeriasIm), GetPointer(cOutputTimeSeriasIm), GetPointer(cOutputTimeSeriasIm), 1, false, 0, 0, 0, -0.5f)) return false;
我们将获得的误差梯度转换到频域。
if(!FFT(GetPointer(cInputFreqRe), GetPointer(cOutputTimeSeriasIm), GetPointer(cOutputFreqRe), GetPointer(cOutputFreqIm), false)) return false;
并经频率注意力层传递给原始数据。
if(!Concat(GetPointer(cOutputFreqRe), GetPointer(cOutputFreqIm), cUnNormFreqComplex.getGradient(), 1, 1, iFFT * iVariables)) return false; if(!ComplexUnNormalizeGradient()) return false; if(!cNormFreqComplex.calcHiddenGradients(cFreqAtteention.AsObject())) return false; if(!ComplexNormalizeGradient()) return false; if(!DeConcat(GetPointer(cOutputFreqRe), GetPointer(cOutputFreqIm), cInputFreqComplex.getGradient(), 1, 1, iFFT * iVariables)) return false; if(!FFT(GetPointer(cOutputFreqRe), GetPointer(cOutputFreqIm), GetPointer(cInputFreqRe), GetPointer(cInputFreqIm), true)) return false; if(!DeConcat(cTranspose[0].getGradient(), GetPointer(cInputFreqIm), GetPointer(cInputFreqRe), iSequence, iFFT - iSequence, iVariables)) return false; if(!cInputSeasons.calcHiddenGradients(cTranspose[0].AsObject())) return false;
然后,我们将噪声误差梯度添加到获得的原始数据梯度之中。
if(!SumAndNormilize(cInputSeasons.getGradient(), cResidual.getGradient(), cInputSeasons.getGradient(), 1, 1, false, 0, 0, 1)) return false;
现在我们只需要通过 PLR 层传播误差梯度,并将其传递给前一层。
//--- trend if(!CutTrendAndOtherGradient(NeuronOCL.getGradient())) return false; //--- input gradient if(!NeuronOCL.calcHiddenGradients(cPLR.AsObject())) return false; if(!SumAndNormilize(NeuronOCL.getGradient(), cInputSeasons.getGradient(), NeuronOCL.getGradient(), 1, false, 0, 0, 0, 1)) return false; //--- return true; }
更新模型参数的方法算法非常标准。它仅按顺序调用包含正训练参数的嵌套对象的同名方法。因此,我们现在不再详研该方法。您可自行分析。这同样适用于为我们的新类提供服务的辅助方法。您可在附件中找到该类及其所有方法的完整代码。
结束语
在本文中,我们概述了一种新的复杂时间序列预测方法 TEMPO,意即使用预先训练的语言模型来预测时间序列。此外,该方法的作者提出了一种分解时间序列的新方式,这提升了学习原始数据表示的效率。
在本文的实践部分,我们利用 MQL5 实现了我们所提议方式的愿景。我们已完成了很多工作。不幸的是,文章的格式不允许囊括整个工作量。因此,依据真实历史数据的模型操作结果将在下一篇文章中讲述。
参考
文章中所用程序
| # | 名称 | 类型 | 说明 |
|---|---|---|---|
| 1 | Research.mq5 | 智能系统 | 样本收集 EA |
| 2 | ResearchRealORL.mq5 | 智能系统 | 利用 Real ORL方法收集样本的 EA |
| 3 | Study.mq5 | 智能系统 | 模型训练 EA |
| 4 | StudyEncoder.mq5 | 智能系统 | 编码器训练 EA |
| 5 | Test.mq5 | 智能系统 | 模型测试 EA |
| 6 | Trajectory.mqh | 类库 | 系统状态描述结构 |
| 7 | NeuroNet.mqh | 类库 | 创建神经网络的类库 |
| 8 | NeuroNet.cl | 代码库 | OpenCL 程序代码库 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/15451
 在MQL5中实现基于抛物线转向指标(Parabolic SAR)和简单移动平均线(SMA)的快速交易策略算法
在MQL5中实现基于抛物线转向指标(Parabolic SAR)和简单移动平均线(SMA)的快速交易策略算法