Что подать на вход нейросети? Ваши идеи... - страница 54
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
Такая идея:
Как известно, SL и TP при обучении/оптимизации обычно не ставятся. Для обучения это затруднительно, а при оптимизации - результаты на беке и форварде обычно хуже, чем без них. Цена так и норовит задеть стопы.
Да и задача стоит - научить НС вовремя выходить как в профите, так и в убытке.
Но на практике, на беке и форварде без стопов, НС часто уходит в пересиживание, либо закрывает на донном дне, поскольку не владеет навыками на новых данных — когда ей выходить.
А что, если на вход подавать просадку по средствам?
Мы будем тыкать носом НС в онлайн-результат её работы, в котором она будет видеть лютую просадку и принудительно реагировать на это.
Например, известно, что число тем больше влияет на работу НС, чем больше его значение. При обычной работе входное значение просадки будет нулевым или около нуля, а когда позиция пойдёт в разнос - значение увеличится и начнёт "кошмарить" целлостную структуру весов, в результате чего оптимизатор будет подбирать веса таким образом, чтобы реагировать на этот вход.
В итоге, он либо занулит его, чтобы не мешал нафиг, тогда фича не будет работать, либо как-то научится реагировать на свою работу.
Нотки обучения с подкреплением проскальзывают, в котором в качестве состояния тоже кидают все данные счёта: баланс, просадку и тд.
Но подобное с MLP я не делал.
Если будет что-то интересное - отпишусь.
Такая идея:
Как известно, SL и TP при обучении/оптимизации обычно не ставятся. Для обучения это затруднительно, а при оптимизации - результаты на беке и форварде обычно хуже, чем без них. Цена так и норовит задеть стопы.
Да и задача стоит - научить НС вовремя выходить как в профите, так и в убытке.
Но на практике, на беке и форварде без стопов, НС часто уходит в пересиживание, либо закрывает на донном дне, поскольку не владеет навыками на новых данных — когда ей выходить.
А что, если на вход подавать просадку по средствам?
Мы будем тыкать носом НС в онлайн-результат её работы, в котором она будет видеть лютую просадку и принудительно реагировать на это.
Например, известно, что число тем больше влияет на работу НС, чем больше его значение. При обычной работе входное значение просадки будет нулевым или около нуля, а когда позиция пойдёт в разнос - значение увеличится и начнёт "кошмарить" целлостную структуру весов, в результате чего оптимизатор будет подбирать веса таким образом, чтобы реагировать на этот вход.
В итоге, он либо занулит его, чтобы не мешал нафиг, тогда фича не будет работать, либо как-то научится реагировать на свою работу.
Нотки обучения с подкреплением проскальзывают, в котором в качестве состояния тоже кидают все данные счёта: баланс, просадку и тд.
Но подобное с MLP я не делал.
Если будет что-то интересное - отпишусь.
А что, если на вход подавать просадку по средствам?
будет мартингейл. обратная связь с просадкой порождает именно его, и без разницы как связь реализуется жёсткой формулой или с прослойкой нейронки
будет мартингейл. обратная связь с просадкой порождает именно его, и без разницы как связь реализуется жёсткой формулой или с прослойкой нейронки
Для MLP то с 3-мя нейронами.
Сколько предикторов? Сколько предикторов реально влияют в модели на результат?
На других инструментах удаётся получить схожий результат?
Как останавливаете обучение - по какому критерию или полный перебор?
Сколько предикторов? Сколько предикторов реально влияют в модели на результат?
На других инструментах удаётся получить схожий результат?
Как останавливаете обучение - по какому критерию или полный перебор?
Когда ЗигЗаг, от 1 до 3-х входов.
Когда положение цены в коридоре, тоже от 1 до 3-х входов.
Проверял только на евро, фунте и франке. На евро и фунте все хороши, на франке лучше себя ведёт положение цены, видимо изза флетовости пары.
Обучение, если через обратное распространение ошибки, то не останавливаю, в NeuroPro оно само останавливается после нескольких появлений ZeroStep вместо числа ошибки. Там критерий я хрен знает, никакого не выставляется.
А если оптимизатор - то полный ход, пока не остановится. Иногда второй раз запущу. Роман Поштар в своих статьях по десять раз запускает, я пока до таких мероприятий не дошёл.
Реализовал две фичи
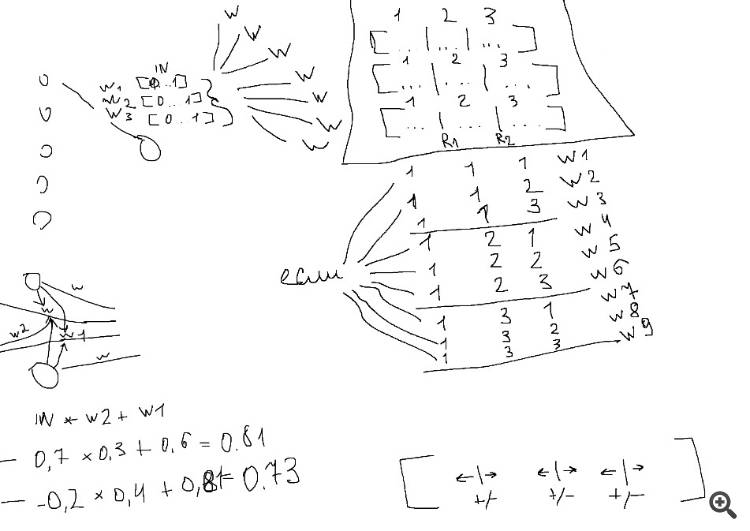
Это всё относится к подгонке, поэтому ничего сверхъестественного
Первая - это динамический вес, подвижность диапазона, прогон входного числа через искусственную функцию. Это всё одна суть.
Нарисовал себе в пейнте мысль, варианты идеи
То есть, в зависимости от того, какое значение на входе, оно умножается на разный вес. Такая штука жрёт больше значений в оптимизаторе МТ на один нейрон, но она более... гибкая что-ли. И иногда раскрывает потенциал входных данных, выдавая сеты, которые не появляются в стандартном MLP с тождественным количеством весов.
Вторая фича - усиление/ослабление сигнала.
Она отличается от перевёртыша из предыдущей фичи (когда отдельный участок в диапазоне числа меняет полярность) тем, что переворачивает числа только в своей полярности.
Например, если число на вход пришло 0.9 из диапазона [0..1], то система его переворачивает на 0.1. И наоборот.
Если диапазон [-1..1], и пришло число -0.3, то оно будет перевёрнуто и усилено в отрицательную зону до -0.7.
Эта фича необходима в том случае, если надо усилить сигнал, который в обычной MLP постоянно только ослабевает (в силу специфики весов - они все - меньше 0). Конечно, можно в качестве весов поставить диапазон от -2 до 2, или от -10 до 10, особенно актуально в первой фиче - но, во-первых, это более затратно для Оптимизатора, который ограничен параметрами, и где легче перевернуть число одним булом (true-false), который для Оптимизатора ниочём, и уже это новое число ДОмножить на стандартный вес ниже 0-ля, сделав с входом тем самым нужную корректировку. Во-вторых, невозможно таким диапазоном усилить входное число 0.01 и ниже. Оно всё также будет невлиятельным для системы. А что, если оно - ключевое для стратегии? Тут и необходимо усиление.
Опционально оптимизатором также выбирается что будет применено ко входу - ослабевание или усиление.
Все эти фичи на практике по моему субъективному мнению лучше и быстрее раскрывают потенциал входных данных в том ограниченном виде, который предоставляет Оптимизатор.
А также, представляет новые сеты, которые в стандартной схеме весов (все со всеми и статичны) - не дают раскрыться входным данным.
Фича
На удивление обнаружил откровенный косяк MLP - она не просто подгоняет торговлю под историю, она подгоняет конкретно позиции под историю
Исходя из этих соображений добавил модуль зеркала - повторно подаю данные на вход, только отзеркаленые: каждое значение умножаю на -1.
Но делаю это только в том случае, если нет сигнала в одну из позиций.
То есть, если после первого прогона выход НС больше порога открытия - пожалуйста, открывай наздоровье.
А если меньше порогового значения - то зеркалю на предмет соответствия на графике перевёрнутого паттерна, который НС не хочет торговать.
И если новое значение выше порогового - тогда уже переписываю OUT на данное значение, но с противоположным знаком.
В результате, НС не может "скрыться" от одного и видов позиции и ей приходится мириться с тем, что нужно открывать как BUY, так и SELL, в зависимости от графика. Теперь "на склоне" не пропадают SELL, а на подъеме не пропадают BUY
На практике сетов стало меньше, ушли крайне "крутые", остались "хорошие".
Субъективно - кажется, что на беке и форварде при переоптимизации баланс чаще флетит, чем летит на дно. Это уже хорошо.
Думаю, такая фича должна быть обязательным атрибутом НС.
На практике сетов стало меньше, ушли крайне "крутые", остались "хорошие".
Субъективно - кажется, что на беке и форварде при переоптимизации баланс чаще флетит, чем летит на дно. Это уже хорошо.
Думаю, такая фича должна быть обязательным атрибутом НС.
Если я правильно понял идею, то в данных условиях сеть пытается искать только зеркальные паттерны, по сути.
Наверное, сделок меньше стало, так как по настоящему зеркальных паттернов, похоже, не существует, на сел и бай разные паттерны - это глазами видно хорошо.
Можно попробовать обучать две сети для двух направлений, при этом сделок по обоим направлениям должно быть примерно равное количество. При сильной разнице в количестве - применять штрафы или снижающий коэфф на итоговое значение фф.
Если я правильно понял идею, то в данных условиях сеть пытается искать только зеркальные паттерны, по сути.
Наверное, сделок меньше стало, так как по настоящему зеркальных паттернов, похоже, не существует, на сел и бай разные паттерны - это глазами видно хорошо.
Можно попробовать обучать две сети для двух направлений, при этом сделок по обоим направлениям должно быть примерно равное количество. При сильной разнице в количестве - применять штрафы или снижающий коэфф на итоговое значение фф.
Мы пришли к принципиальным парадигмам торговли:
1) Паттерны одинаковы для бай и для сел, просто зеркальные
2) Паттерны для бай и для сел - разные
Да, действительно, пока нет доказательств, можно опираться на какие-то убеждения или факты.
В данном случае я опираюсь, как уже выше говорил, на то, что во всех известных ТС условия для BUY и для SELL - одинаковые, зеркальные.
Это касается как сливных (99,9....%) ТС, так и успешных. Подчёркиваю - успешных. У них у всех - зеркальные правила.
Против второй позиции по моему убеждению также играет тот факт, что любое проявления дискриминации одной из видов сделок - негативно проявляется на форварде и беке.
Например, моя фича про диапазон - если его не сделать зеркальным, а разным (то есть от -1 до 0 и от 0 до 1 будут совершенно разные участки в разными весами) - то сама оптимизация и само обучение будет выглядеть как на оптимизационном периоде - страшно и коряво, так и на форварде и беке - страшно и коряво.
А если зеркалить - то чаще прявляются плавные переходы. Имхо, субъективно.
Также против второго варианта играет тот факт, как упомянул выше, если обучать на 2020-м году - то в 2021-м льёт. А это два противоположных по направлению года, начиная прямо с Нового года.
То есть, НС без зеркала, либо отдельная для BUY НС, которая обучается обособленно, гарантированно будет лить во всем сетах оптимизации в 2021-м. Прям друг за дружком их нажимаешь - они все пикируют. Все обучились BUY, и в 2021-м открывают BUY, где только можно, не умеют выходить из него, и совсем чуть-чуть SELL, и то - непонятно где.
Но, я не откидываю этот вариант и тестирую всё подряд, что под руку подпадётся ))
Потому что каждый день что-то новое проявляется