
Manipulação de Arquivos ZIP em Linguagem MQL5 Pura

Índice
- Introdução
- Cápitulo 1. Formato dos arquivos ZIP e armazenamento de dados
- Capitulo 2. Visão geral da classe CZip e seus algoritmos
- Capítulo 3. Exemplos do uso da classe CZip, medindo o desempenho
- Capítulo 4. Documentação para as classes que operam com arquivos ZIP
- Conclusion
Introdução
História atrás do assunto
Particularmente o autor deste artigo foi atraído por uma característica interessante da função CryptDecode, a sua capacidade de descompactar um array ZIP transferido a ele. Este modificador foi introduzido pelos desenvolvedores da plataforma de negociação MetaTrader 5, a fim de extrair respostas de vários servidores usando a função padrão WebRequest. No entanto, devido a certas características do formato de arquivo ZIP, era impossível usá-lo diretamente.
Foi necessária uma autenticação adicional: para descompactar um arquivo era necessário conhecer seu código hash antes de compactar - Adler-32 que, claramente, não estava disponível. No entanto, enquanto discutiam este problema, os desenvolvedores encontraram a necessidade de sobrecarregar o CryptDecode e CryptEncode, irmãos gêmeos "espelho-imagem", com uma flag especial que permitiu ignorar a função hash Adler32 ao descomprimir os dados transmitidos. Para os usuários inexperientes do ponto de vista técnico esta inovação pode ser facilmente explicada: isto habilita todas as funcionalidades de arquivos ZIP. Este artigo descreve o formato de arquivos ZIP, suas especificidades de armazenamento de dados e oferece a conveniência da classe orientada a objeto CZIP para manipular um arquivo
Porque é necessário?
A compressão de dados é uma das tecnologias mais importantes, particularmente muito difundida na Web. A compressão ajuda a economizar recursos necessários para a transmissão, armazenamento e processamento de dados. A compressão de dados é usada em praticamente todas as áreas das comunicações e atinge quase todas as tarefas relacionadas com computadores.
O setor financeiro não é exceção: gigabytes de histórico de ticks, o fluxo das cotações, incluindo o Livro de Ofertas (Profundidade de Mercado - Nível 2/dados) que não pode ser armazenado no formato original, desscompactado. Muitos servidores, incluindo aqueles que fornecem informação analítica necesssária para a negociação, também armazenam dados em arquivos ZIP. Anteriormente era impossível obter esta informação automaticamente usando as ferramentas padrões MQL5. Agora, a situação mudou.
Usando a função WebRequest você pode baixar um arquivo ZIP e, instantaneamente, descompactá-lo no computador. Todos esses recursos são importantes e serão demanda definitiva de muitos traders. A compressão de dados pode ainda ser usada para otimizar a memória do computador. Como isso é feito? Iremos descrever na Seção 3.2 deste artigo. Finalmente, a capacidade de manipular arquivos ZIP dá acesso à formação de documentos com o padrão "Office Open XML" da Microsoft Office, que por sua vez permite criar simples arquivos do Excel ou Word diretamente do MQL5, sem usar bibliotecas DLL de terceiros.
Como podemos ver, a aplicação de arquivos ZIP é extensa e a classe que estamos criando vai servir muito bem a todos os usuários MetaTrader.
No primeiro capítulo deste artigo vamos descrever um formato de arquivos ZIP e ter uma ideia sobre quais blocos de dados ele contém. Este capítulo será de interesse não só para aqueles que estudam MQL, mas ele também pode servir como um bom material educativo para os envolvidos em questões relacionadas com a compactação e armazenamento de dados. O segundo capítulo está concentrado nas classes CZip, CZipFile e CZipDirectory que são os principais elementos orientados a objetos que operam com arquivos. O terceiro capítulo descreve exemplos práticos relacionados com a utilização do arquivamento. E o quarto capítulo contém toda a documentação relacionada com as classes propostas.
Então, vamos seguir e estudar o tipo de compactação mais comum.
Cápitulo 1. Formato dos arquivos ZIP e armazenamento de dados
1.1. Estrutura do arquivo ZIP
O formato ZIP foi criado por Phil Katz em 1989 e foi implementado pela primeira vez no programa PKZIP para MS-DOS, lançado pela empresa PKWARE que Katz fundou. Este formato usa com mais freqüência o algoritmo de compactação de dados DEFLATE . Os programas mais comuns que trabalham no Windows com este formato são WinZip e WinRAR.
É importante entender que o formato do arquivo ZIP foi desenvolvido ao longo do tempo e tem várias versões. Para criar uma classe que funcione com um arquivo ZIP, contamos com a especificação do formato oficial da versão 6.3.4, encontrada no site da empresa PKWARE: https://pkware.cachefly.net/webdocs/casestudies/APPNOTE.TXT. Esta é a especificação de formato mais recente datada de 01 de outubro de 2014, que é extensiva e inclui descrições de inúmeras nuances.
Neste artigo, somos guiados pelo princípio do menor esforço e iremos criar uma ferramenta que utilizará apenas os dados mais necessários para a extração e criação de novos arquivos com sucesso. Isto significa que a operação com arquivos ZIP será limitado até um certo ponto - a compatibilidade dos formatos não é garantida, portanto não existe necessidade de mencionar a completa "onívoria" de arquivos. Existe a possibilidade de alguns arquivos ZIP criados por aplicativos de terceiros não poderem ser extraídos através do instrumento proposto.
Cada arquivo ZIP é um arquivo binário que contém uma seqüência ordenada de bytes. Por outro lado, cada arquivo do ZIP tem um nome, atributos (tais como a data de modificação do arquivo) e outras propriedades, que estamos acostumados a ver em sistemas de arquivos de qualquer sistema operacional . Portanto, além dos dados compactados, cada armazenamento de arquivo ZIP possui o nome de um arquivo comprimido, seus atributos e outras informações do serviço. A informação do serviço é colocada de uma forma muito específica e tem uma estrutura padrão. Por exemplo, se um arquivo contém dois arquivos(File#1 e File#2), então terá o seguinte esquema:
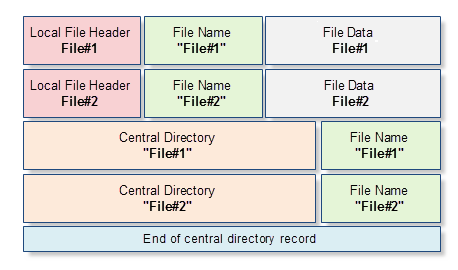
Fig. 1. Representação esquemática de um arquivo ZIP que contém dois arquivos: File#1 e File#2
Numa fase posterior, examinaremos cada bloco deste esquema, mas no momento vamos dar uma breve descrição de todos os blocos:
- "Local File Header" — este bloco de dados contém informações básicas sobre o arquivo compactado: o tamanho do arquivo antes e depois da compressão, data e hora da modificação do arquivo, checksum CRC-32 e ponteiro local para o nome do arquivo. Também este bloco contém a versão do descompactador necessário para abrir o arquivo.
- File Name é uma sequência de bytes com comprimento arbitrário que forma o nome do arquivo compactado. O comprimento do nome do arquivo não deve exceder os 65 536 caracteres.
- File Data é um conteúdo dos arquivos compactados na forma de um array de bytes de comprimento arbitrário. Se o arquivo estiver vazio ou compreende um diretório, então esse array não é usado, e o título do "Local File Header" descreve o próximo arquivo seguido do nome do arquivo ou diretório.
- "Central Directory" permite uma visualização de dados expandida no "Local File Header". Além dos dados contidos no "Local File Header", também tem atributos de arquivo, uma referência local a estrutura do "Local File Header" e outras informações que na maior parte não são utilizadas.
- Registro do "End of Central Directory" - esta estrutura é apresentada como um modelo único em cada arquivo e é escrita no final do arquivo. O dado mais interessante que ele contém é um número de registro dos arquivos (ou o número de arquivos e diretórios) e referências locais para o início do bloco "Central Directory".
Cada bloco deste esquema pode ser apresentado quer como uma estrutura regular, ou como um array de bytes de comprimento arbitrário. Cada estrutura pode ser descrita com um structure, que é o mesmo nome de construção de programação MQL.
A estrutura sempre contém um número fixo de bytes, portanto não pode conter arrays de comprimento arbitrários e linhas. No entanto, ela pode ter ponteiros para estes objetos. Esta é a razão pela qual os nomes de arquivos são colocados fora da estrutura, então eles podem conter qualquer comprimento. O mesmo se aplica aos arquivos de dados compactados - seu tamanho é arbitrário, portanto eles também são mantidos fora das estruturas. Dessa forma, podemos concluir que um arquivo ZIP é apresentadao pela seqüência de padrões, linhas e dados compactados.
O formato do arquivo ZIP, além do explicado acima, descreve a estrutura adicional, o assim chamado Data Descriptor. Essa estrutura é usada apenas no caso da estrutura do "Local File Header" não poder ser formada por algum motivo, e a fração de dados necessários para o "Local File Header" torna-se disponível após a compactaçao dos dados. Na prática, a situação atual parece ser muito exótica, portanto essa estrutura quase nunca é usada, e em nossa classe para manipulação de arquivos este bloco não é suportado.
| Por favor, note que de acordo com o formato de arquivo ZIP, cada arquivo é compactado separadamente do resto. Por um lado, permite localizar a ocorrência de erros, um arquivo "quebrado" pode ser restaurado excluindo arquivos com conteúdo errado e deixando o conteúdo remanescente sem qualquer alteração. Por outro lado, quando se compacta cada arquivo em separado, a eficiência da compactaçao é diminuída, em especial quando cada arquivo ocupa pouco espaço. |
|---|
1.2. Estudando o arquivo ZIP em um editor hexadecimal
Armado com o conhecimento necessário, podemos ver o que está dentro de um típico arquivo ZIP. Para fazer isso, vamos utilizar um editor hexadecimal WinHex. Se por algum motivo você não tem WinHex, você pode usar qualquer outro editor hexadecimal. Afinal de contas, nos lembramos que qualquer arquivo é um arquivo binário e pode ser aberto como uma simples seqüência de bytes. Como modelo, vamos criar um simples arquivo ZIP que contém um singelo arquivo de texto com a frase "HelloWorld!":

Fig. 2. Criando um arquivo de texto no Bloco de Notas
Então, vamos usar qualquer compactador ZIP para criar um arquivo. No nosso caso usaremos o descompactador WinRAR. É necessário selecionar o arquivo que foi criado e arquivá-lo no formato ZIP:
Fig. 3. Usando arquivo WinRAR para criar um arquivo
Depois que terminar com a compactação no disco rígido do computador, um novo arquivo "HelloWorld.zip" aparecerá no diretório correspondente. A primeira característica marcante deste arquivo é o seu tamanho de 135 bytes, consideravelmente maior do que o arquivo fonte de 11 bytes. Se deve o fato de que além dos dados comprimidos, o arquivo ZIP também contém informação do serviço. Portanto, a compactação é inútil para pequenos volumes de dados que só recebem algumas centenas de bytes.
Agora que temos o esquema do layout de dados, a idéia de um arquivo criado por um conjunto de bytes não parece tão assustadora para nós. Vamos abri-lo com um editor hexadecimal WinHex. A figura abaixo mostra o array de bytes do arquivo com um destaque condicional de cada área descrita no Esquema 1:
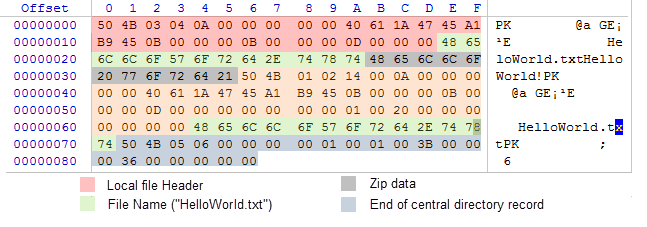
Fig. 4. Conteúdo interno de arquivo ZIP que contêm o arquivo HelloWorld.txt
Na verdade, a frase "HelloWorld!" está contida no intervalo de 0x35 para 0x2B bytes e ocupa apenas 11 bytes. Por favor, note que o algoritmo de compactação decidiu não compactar a frase original e o arquivo ZIP está presente na sua forma original. Isto aconteceu porque a compactação de uma mensagem curta é ineficiente, e o array compactado tornar-se mais pesado do que o não compactado.
| Um arquivo ZIP nem sempre contém dados compactados. Às vezes, os dados compactados estão localizados na forma original, não compactados, mesmo quando foi realizada a compactação, pois foi claramente indicado para comprimir os dados durante a compactação. Esta situação ocorre quando o volume de dados é insignificante e a compactação de dados é ineficiente. |
|---|
Se você olhar para Fig. 4, fica claro como diferentes blocos de dados são armazenados num arquivo compactado e onde os dados do arquivo são mantidos exatamente. Agora vamos analisar cada um dos blocos de dados individualmente.
1.3. Estrutura do "Local File Header"
Cada arquivo ZIP começa com a estrutura do "Local File Header" (Cabeçalho do Arquivo Local). Ele contém metadados de um arquivo que segue como um array de bytes compactados. Cada estrutura de um arquivo, de acordo com a especificação de formato, tem o seu identificador único de quatro bytes Essa estrutura não é exceção, seu identificador exclusivo é igual a 0x04034B50.
Você deve saber que os processadores baseados em x86 carregam dados de arquivos binários para a memória RAM na ordem inversa. Os números estão localizados de dentro para fora: o último byte toma o lugar do primeiro byte e vice-versa. Um método de gravação de dados no arquivo é determinado pelo formato do arquivo e para os arquivos ZIP também ocorre na ordem inversa Para mais informações sobre a seqüência de bytes por favor leia o artigo no site Wikipedia - "Endianness". Para nós, isso significa que o identificador de estrutura será escrito como uma figura 0x504B0304 (valor inverso 0x04034B50). Qualquer arquivo ZIP começa com essa seqüência de bytes.
Uma vez que a estrutura é uma sequência de bytes estritamente definida, isto pode ser apresentado como uma estrutura semelhante na linguagem de programação MQL5. A descrição da estrutura do "Local File Header" (Cabeçalho do Arquivo Local) em MQL5 é a seguinte:
//+------------------------------------------------------------------+ //| Local file header based on specification 6.3.4: | //| https://pkware.cachefly.net/webdocs/casestudies/APPNOTE.TXT, | //| 4.3.7 | //+------------------------------------------------------------------+ struct ZipLocalHeader { uint header; // Cabeçalho local sempre igual a 0x04034b50 ushort version; // Versão mínima para extração ushort bit_flag; // Bit flag ushort comp_method; // Método de Compactação (0 - Sem Compactação, 8 - deflate) ushort last_mod_time; // Hora da modificação do arquivo ushort last_mod_date; // Data da modificação do arquivo uint crc_32; // Código (hash) CRC-32 uint comp_size; // Tamanho do arquivo compactado uint uncomp_size; // Tamanho do arquivo sem compactação ushort filename_length; // Comprimento do nome do arquivo ushort extrafield_length; // Campo de comprimento com dados adicionais bool LoadFromCharArray(uchar& array[]); int ToCharArray(uchar &array[]); ZipLocalHeader(): header(0x04034B50), version(10), bit_flag(2), comp_method(DEFLATE), last_mod_time(0), last_mod_date(0), crc_32(0), comp_size(0), uncomp_size(0), filename_length(0), extrafield_length(0) {;} };
Essa estrutura é usada para operação real com arquivos ZIP, assim além do campo de dados, também contém métodos adicionais que permitem converter a estrutura num conjunto de bytes (array de bytes uchar) e, inversamente, para criar uma estrutura a partir dos conjuntos de bytes. Aqui estão os conteúdos dos métodos ToCharArray e LoadFromCharArray que permitem essa conversão:
//+------------------------------------------------------------------+ //|Estrutura privada para converter LocalHeader em array uchar | //+------------------------------------------------------------------+ struct ZipLocalHeaderArray { uchar array[sizeof(ZipLocalHeader)]; // Tamanho do ZipLocalHeader }; //+------------------------------------------------------------------+ //| Estrutura ZipHeader de conversão para array uchar. | //| RETORNO: | //| Número de´elementos copiados. | //+------------------------------------------------------------------+ int ZipLocalHeader::ToCharArray(uchar &array[]) { ZipLocalHeaderArray zarray=(ZipLocalHeaderArray)this; return ArrayCopy(array, zarray.array); } //+------------------------------------------------------------------+ //| Estrutura inicial do cabeçalho local a partir do array uchar | //+------------------------------------------------------------------+ bool ZipLocalHeader::LoadFromCharArray(uchar &array[]) { if(ArraySize(array)!=sizeof(ZipLocalHeader)) { SetUserError(ZIP_ERROR_BAD_FORMAT_ZIP); return false; } ZipLocalHeaderArray zarray; ArrayCopy(zarray.array,array); this=(ZipLocalHeader)zarray; if(header!=ZIP_LOCAL_HEADER) { SetUserError(ZIP_ERROR_BAD_FORMAT_ZIP); return false; } return true; }
Vamos descrever a estrutura dos campos (listados em ordem):
- header — identificador único da estrutura, para "File Local Header" é igual a 0x04034B50;
- versão — versão mínima para descompactação dos arquivos;
- bit_flag — byte flag tem identificador 0x02;
- comp_method — tipo de compressão usado. Normalmente, é usado um método de compressão DEFLATE com um identificador 0x08.
- last_mod_time — hora da última modificação do arquivo. Ele contém horas, minutos e segundos da modificação do arquivo no formato MS-DOS. Este formato é descrito na página da empresa Microsoft.
- last_mod_date — data da última modificação do arquivo. Ele contém um dia do mês, um número do mês no ano e o ano da modificação do arquivo no formato MS-DOS.
- crc_32 — checksum CRC-32 (soma de verificação). Ele é usado por programas que trabalham para localizar erros de conteúdo do arquivo. Se este campo não for preenchido, o descompactador ZIP irá se recusar a abrir o arquivo compactado referindo-se ao arquivo como corrompido.
- comp_size — tamanho dos dados compactados em bytes;
- uncomp_size — tamanho dos dados originais em bytes;
- filename_length — comprimento do nome do arquivo;
- extrafield_length — campo especial para escrever dados adicionais de atributos. Quase nunca usado, é igual a zero.
Ao salvar esta estrutura no arquivo, é criada uma seqüência de bytes que contém os valores dos campos correspondentes desta estrutura. Vamos recarregar nosso arquivo ZIP com o arquivo HelloWorld.txt no editor hex e desta vez iremos analisar cuidadosamente o array de bytes desta estrutura:

Fig. 5. Gráfico de Byte da Estrutura "Local File Header" no Arquivo HelloWorld.zip
O diagrama mostra quais bytes preenchem os campos da estrutura. Para verificar os dados, vamos prestar atenção no campo "File Name length" (comprimento do nome do arquivo), leva 2 bytes e é igual ao valor de 0x0D00. Ao transformar esse número no inverso e colocá-lo em formato decimal, obtemos um valor igual a 13 - que é também o número de símbolos que o arquivo "HelloWorld.txt" tem. O mesmo pode ser feito com um campo que indica o tamanho dos dados compactados. É igual 0x0B000000, o que corresponde a 11 bytes. Na verdade, a frase "HelloWorld!"(Olá mundo) é armazenada num arquivo sem compactação e ocupa 11 bytes.
A estrutura é seguida pelos dados compactados e então a a nova estrutura começa - "Central Directory" (Diretório Central), que iremos ver com mais detalhes na próxima seção.
1.4. Estrutura do "Central Directory"
A estrutura do "Central Directory" (Diretório Central) é uma apresentação de dados expandidos no "Local File Header". Na verdade, para o trabalho básico com arquivo ZIP, é suficiente os dados do "Local File Header". No entanto, o uso da estrutura "Central Directory" é obrigatório e seu valor deve ser preenchido corretamente. Esta estrutura tem o seu identificador exclusivo, 0x02014B50. Em MQL5 sua apresentação será a seguinte:
//+------------------------------------------------------------------+ //| Estrutura do Central Directory | //+------------------------------------------------------------------+ struct ZipCentralDirectory { uint header; // "Central Directory Header" sempre igual a 0x02014B50 ushort made_ver; // Versão feita por ushort version; // Versão mínima para extração ushort bit_flag; // Bit flag ushort comp_method; // Método de Compactação (0 - Sem Compactação, 8 - deflate) ushort last_mod_time; // Hora da modificação do arquivo ushort last_mod_date; // Data da modificação do arquivo uint crc_32; // Código hash CRC32 uint comp_size; // Tamanho do arquivo com compactação uint uncomp_size; // Tamanho do arquivo sem compactação ushort filename_length; // Comprimento do nome do arquivo ushort extrafield_length; // Campo de comprimento com dados adicionais ushort file_comment_length; // Comprimento do arquivo de comentário ushort disk_number_start; // Início do número de disco ushort internal_file_attr; // Atributos do arquivo interno uint external_file_attr; // Atributos do arquivo externo uint offset_header; // Deslocamento relativo do cabeçalho local bool LoadFromCharArray(uchar &array[]); int ToCharArray(uchar &array[]); ZipCentralDirectory() : header(0x02014B50), made_ver(20), version(10), bit_flag(0), comp_method(DEFLATE), last_mod_time(0), last_mod_date(0), crc_32(0), comp_size(0), uncomp_size(0), filename_length(0), extrafield_length(0), file_comment_length(0), disk_number_start(0), internal_file_attr(0), external_file_attr(0) {;} };
Como você pode ver, ele já contém mais dados, no entanto a maioria deles duplica os dados do "Local File Header". Assim como a estrutura anterior, contém métodos para converter seu conteúdo para um array de bytes e vice-versa.
Nós descrevemos seus campos:
- header — identificador de estrutura única, é igual a 0x02014B50;
- made_ver — versão padrão usado para compactação;
- version — versão padrão mínima para a descompressão de arquivos com sucesso;
- bit_flag — byte flag, tem o identificador 0x02;
- comp_method — tipo de compressão usado. Normalmente, é usado um método de compressão DEFLATE com um identificador 0x08.
- last_mod_time — hora da última modificação do arquivo. Ele contém horas, minutos e segundos da modificação do arquivo no formato MS-DOS. Este formato é descrito na página da empresa Microsoft.
- last_mod_date — data da última modificação do arquivo. Ele contém um dia do mês, um número do mês no ano e o ano da modificação do arquivo no formato MS-DOS.
- crc_32 — checksum CRC-32 (soma de verificação). Ele é usado por programas que trabalham para localizar erros de conteúdo do arquivo. Se este campo não for preenchido, o descompactador ZIP irá se recusar a abrir o arquivo compactado referindo-se ao arquivo como corrompido.
- comp_size — tamanho dos dados compactados em bytes;
- uncomp_size — tamanho dos dados originais em bytes;
- filename_length — comprimento do nome do arquivo;
- extrafield_length — campo especial para escrever dados adicionais de atributos. Quase nunca usado, é igual a zero.
- file_comment_length — comprimento de comentários do arquivo;
- disk_number_start — número de um disco onde arquivo é escrito. Quase sempre igual a zero.
- attr arquivo interno — atributos de arquivo no formato MS-DOS;
- external_file_attr —arquivos estendido atributos em formato MS-DOS;
- offset_header — endereço do início da estrutura do "Local File Header".
Ao salvar esta estrutura no arquivo, é criada uma seqüência de bytes que contém os valores dos campos. Aqui está o layout dos bytes nesta estrutura, como na Figura 5:

Fig. 6. Gráfico Byte da estrutura do "Central Directory" no arquivo HelloWorld.zip
Ao contrário do "Local File Header", as estruturas do "Central Directory" tem uma ordem consecutiva. O endereço inicial daquele primeiro é especificado no final do bloco de dados especial - estrutura ECDR. Informações mais detalhadas sobre esta estrutura na próxima seção.
1.5. Estrutura do "End of Central Directory Record" (ECDR)
A estrutura do "End of Central Directory Record" (ou simplesmente ECDR) completa um arquivo ZIP. Seu identificador exclusivo é igual a 0x06054B50. Cada pacote contém uma única cópia da estrutura. O ECDR armazena o número de arquivos e diretórios que estão no arquivo, bem como o endereço da seqüência, começando pela estrutura do "Central Directory" e seu tamanho total.C Além disso, o bloco de dados armazena também outras informações. Aqui está uma descrição completa de EMDR em MQL5:
//+------------------------------------------------------------------+ //| Estrutura do "End of central directory record" | //+------------------------------------------------------------------+ struct ZipEndRecord { uint header; // Cabeçalho do "End Central Directory Record", sempre igual a 0x06054b50 ushort disk_number; // Número deste disco ushort disk_number_cd; // Número do disco com o início no "Central Directory" ushort total_entries_disk; // Número total de entradas no "Central Directory" neste disco ushort total_entries; // Número total de entradas no "Central Directory" uint size_central_dir; // Tamanho do "Central Directory" uint start_cd_offset; // Início do número de disco ushort file_comment_lengtt; // Comprimento do comentário de arquivo string FileComment(void); bool LoadFromCharArray(uchar& array[]); int ToCharArray(uchar &array[]); ZipEndRecord(void) : header(0x06054B50){;} };
Iremos descrever os campos dessa estrutura em mais detalhes:
- header — identificador de estrutura única, é igual a 0x06054B50;
- disk_number — número de disco;
- disk_number_cd — número do disco a partir do qual inicia o "Central Directory";
- total_entries_disk — número total de entradas no "Central Directory" (número de arquivos e diretórios);
- total_entries — todas as entradas (número de arquivos e diretórios);
- size_central_dir — tamanho da seção "Central Directory";
- start_cd_offset — endereço de byte do início da seção "Central Directory";
- file_comment_length — comprimento do comentário de arquivo.
Ao salvar esta estrutura no arquivo, é criada uma seqüência de bytes que contém os valores dos campos. Aqui está o layout dos bytes da estrutura:

Fig. 7. Gráfico de Byte da estrutura ECDR
Nós usaremos esse bloco de dados para determinar um número de elementos no array.
Capitulo 2. Visão geral da classe CZip e seus algoritmos
2.1. Estrutura de arquivos compactados dentro de um arquivo, classe CZip e CZipFolder
Assim, no primeiro capítulo examinamos o formato de um arquivo ZIP. Analisamos, quais os tipos de dados que consiste um arquivo ZIP e descrevemos as estruturas relevantes destes tipos de dados. Depois de definir esses tipos, vamos implementar uma classe especializada de alto nível, CZip, poderá ser usada para executar as seguintes ações rápidas e fáceis com arquivos ZIP:
- Criar um novo arquivo;
- Abrir um arquivo criado anteriormente num disco rígido;
- Fazer o download do arquivo a partir de um servidor remoto;
- Adicionar novos arquivos a um arquivo;
- Apagar arquivos de um arquivo;
- Descompactar um arquivo completo ou seus arquivos separadamente.
A classe CZip pode ser usada para completar as estruturas necessárias de um arquivo corretamente, fornecendo-nos uma interface de alto nível usual para trabalhar com a coleção de arquivo. A classe fornece múltiplas oportunidades adequadas para a maioria das tarefas relacionadas com a compactação.
Obviamente, o conteúdo de um arquivo ZIP pode ser dividido em pastas e arquivos. Ambos os tipos de conteúdo têm um extenso conjunto de recursos: nome, tamanho, arquivo atributos, data de criação etc. Algumas dessas propriedades são comuns para ambas as pastas e arquivos, e algumas, como os dados compactados, não são. A solução ideal para o uso de arquivos seria fornecer classes de serviço especiais: CZipFile e CZipDirectory. Essas classes particulares estariam fornecendo arquivos e pastas, respectivamente. Classificação condicional do conteúdo dos arquivos é mostrado no gráfico abaixo:
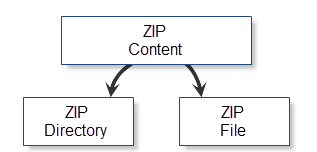
Fig. 8. Classificação condicional dos objetos do arquivo
Assim, para adicionar um arquivo ao CZip você deve primeiro criar um objeto do tipo CZipFile e em seguida adicionar este arquivo de objeto no arquivo. Como exemplo, vamos criar um arquivo de texto "HelloWorld.txt" que contém texto "HelloWorld!", e adicioná-lo ao arquivo:
//+------------------------------------------------------------------+ //| Criando o arquivo com a mensagem "HelloWorld!" | //+------------------------------------------------------------------+ void CreateHelloWorld() { CZip zip; // nós criamos um arquivo ZIP vazio uchar content[]; StringToCharArray("HelloWorld!",content,0, StringLen("HelloWorld!")); // nós escrevemos a frase "HelloWorld!" no array de byte CZipFile* file = new CZipFile("HelloWorld.txt",content); // nós criamos um arquivo ZIP com o nome "HelloWorld.txt" // que contém o array de byte "HelloWorld!" zip.AddFile(file); // nós adicionamos o arquivo ZIP ao compactador zip.SaveZipToFile("HellowWorld.zip",FILE_COMMON); // salvamos o arquivo num disco com o nome "HelloWorld.zip" printf("Size: "+(string)zip.Size()); }
Depois de executar este código no disco do computador, aparecerá um novo arquivo ZIP com um único arquivo de texto, "HelloWorld.txt", com o mesmo nome. Se quiséssemos criar uma pasta em vez de um arquivo, então no lugar de CZipFile, criaria uma cópia da classe CZipFolder. Para este efeito, seria suficiente apenas especificar o seu nome.
Como já foi dito, as classes CZipFile e CZipFolder têm muito em comum. Portanto, ambas as classes são herdadas do ancestral comum — CZipContent. Esta classe contém métodos genéricos e dados para operação com o conteúdo do arquivo.
2.2. Criando arquivos compactados com CZipFile
A criação de um arquivo ZIP compactado é idêntico à criação de uma cópia CZipFile. Como se sabe, a fim de criar um arquivo deve-se especificar o seu nome e conteúdo. Portanto, o construtor CZipFile também exige uma indicação explícita de parâmetros importantes:
//+------------------------------------------------------------------+ //| Criar um arquivo ZIP a partir do array e nome do arquivo | //+------------------------------------------------------------------+ CZipFile::CZipFile(string name,uchar &file_src[]) : CZipContent(ZIP_TYPE_FILE,name) { AddFileArray(file_src); }
Na seção 2.1, é mostrado a chamada deste construtor.
Também não é necessário criar um arquivo, mas fazer o download de arquivo existente a partir de um disco. Neste caso existe um segundo construtor na classe CZipFile que permite a criação de um arquivo ZIP com base num arquivo normal de um disco rígido:
//+------------------------------------------------------------------+ //| Criar um arquivo ZIP a partir do array e nome do arquivo | //+------------------------------------------------------------------+ CZipFile::CZipFile(string path_file,int file_common) : CZipContent(ZIP_TYPE_FILE,"") { AddFile(path_file,file_common); }
Todos os trabalhos nesta construção é delegada ao método particular AddFile. Seu algoritmo de funcionamento é o seguinte:
- O arquivo indicado é aberto para leitura, seu conteúdo é lido em um array de bytes.
- O array de bytes obtido é compactado utilizando o método de array AddFileArray, é armazenado numa matriz dinâmica especial do tipo uchar.
O método AddFileArray é o "coração" de todo o sistema de classes para trabalhar com arquivos. Afinal de contas, este método tem a função mais importante do sistema - CryptEncode. Aqui está o código fonte para este método:
//+------------------------------------------------------------------+ //| Adicionar arquivo de array e compactar | //+------------------------------------------------------------------+ bool CZipFile::AddFileArray(uchar &file_src[]) { ResetLastError(); ArrayResize(m_file_puck,0); CompressedSize(0); UncompressedSize(0); CreateDateTime(TimeCurrent()); if(ArraySize(file_src)<1) { SetUserError(ZIP_ERROR_EMPTY_SOURCE); return false; } uchar key[]={1,0,0,0}; CryptEncode(CRYPT_ARCH_ZIP,file_src,key,m_file_puck); if(ArraySize(m_file_puck)<1) { SetUserError(ZIP_ERROR_BAD_PACK_ZIP); return false; } UncompressedSize(ArraySize(file_src)); CompressedSize(ArraySize(m_file_puck)); uint crc32=CRC32(file_src); m_header.crc_32=crc32; m_directory.crc_32=crc32; return true; }
A configuração da função CryptEncode está marcada em amarelo com a compactação posterior do array de bytes. Assim, concluímos que a compactação de arquivos ocorre no ponto de criação do objeto CZipFile, ao invés do ponto de criação ou preservação do próprio arquivo ZIP. Devido a esta qualidade de todos os dados transmitidos para a classe CZip são automaticamente compactados, consequentemente, exige menos memória no seu armazenamento.
Por favor, note que em todos os casos, o array de bytes do tipo uchar é usado nos dados. Na verdade, todos os dados que operam num computador podem ser representados como uma determinada sequência de bytes. Portanto, para criar um recipiente verdadeiramente universal para dados compactados, que na verdade é o que CZipFile é, utilizamos um array de bytes do tipo uchar.
| O usuário deve converter os dados para a compactação no array uchar[] por conta própria, e que por sua vez deve ser passado por referência como conteúdo do arquivo para a classe CZipFile. Devido a esta característica, absolutamente qualquer tipo de arquivo pode ser colocado num arquivo ZIP, sendo transferido a partir do disco ou criado no processo do programa em MQL. |
|---|
Extração de dados é uma tarefa trivial. Para extrair dados do array de bytes original, file_array, o método GetUnpackFile é usado, que é essencialmente um método de invólucro para a função CryptDecode do sistema:
//+------------------------------------------------------------------+ //| Obter arquivo descompactado. | //+------------------------------------------------------------------+ void CZipFile::GetUnpackFile(uchar &file_array[]) { uchar key[]={1,0,0,0}; CryptDecode(CRYPT_ARCH_ZIP,m_file_puck,key,file_array); }
2.3. Relembrando MS-DOS. Formato data e hora em um arquivo ZIP
O formato ZIP de armazenamento de dados foi criado no final dos anos 80 do século passado para a plataforma MS-DOS, cujo "sucessor legal" tornou-se "Windows". Naquela época, os recursos para armazenamento de dados foram limitados, de modo que a data e hora do sistema operativo MS-DOS foram armazenadas separadamente: dois bytes (ou uma palavra para os processadores de 16 bits daquele tempo) foram alocados para dados e dois bytes para o tempo. Os minutos, horas, dias, meses e anos ocupam certos intervalos de bytes numa palavra, onde para extrair ou gravar dados é ainda obrigado a recorrer às operações de byte.
A especificação deste formato está disponível no site da Microsoft no seguinte link: https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx.
Aqui temos o formato de armazenamento de dados correspondendo ao campo de dois bytes:
| N bytes | Descrição |
|---|---|
| 0-4 | Dia do mês (0-31) |
| 5-8 | Número do mês (1 — Janeiro, 2 — Fevereiro, etc.) |
| 9-15 | Número do ano a partir de 1980 |
Table 1. Formato de armazenamento de data em campo de dois bytes
Da mesma forma, vamos indicar o formato de armazenamento do tempo no campo correspondente de dois bytes:
| N bytes | Descrição |
|---|---|
| 0-4 | Segundos (armazenamento apurado em +/- 2 segundos) |
| 5-10 | Minutos (0-59) |
| 11-15 | Formato de tempo em 24 horas |
Table 2. Formato de armazenamento de tempo no campo de dois bytes
Sabendo a especificação desse formato, pode-se trabalhar com operações de bytes, assim você pode escrever as funções correspondentes que convertem a data e hora do formato de MQL ao formato MS-DOS. É também possível escrever procedimentos de reversão. Tais técnicas de conversão são comuns para ambas as pastas fornecidas pela classe CZipFolder e arquivos fornecidos pela CZipFile. Ao definir data e hora para eles no formato MQL de costume, podemos converter "nos bastidores" este tipo de dados para o formato MS-DOS. Os métodos DosDate, DosTime, MqlDate e MqlTime estão envolvidos com essa conversão.
Código fonte abaixo, na conversão de dados de formato MQL para o formato de data do MS-DOS:
//+---------------------------------------------------------------------------------+ //| Obter dados no formato MS-DOS. Ver especificações no: | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ ushort CZipContent::RjyDosDate(datetime date) { ushort dos_date=0; MqlDateTime time={0}; TimeToStruct(date,time); if(time.year>1980) { dos_date = (ushort)(time.year-1980); dos_date = dos_date << 9; } ushort mon=(ushort)time.mon<<5; dos_date = dos_date | mon; dos_date = dos_date | (ushort)time.day; return dos_date; }
Conversão de dados do formato MS-DOS ao formato MQL:
//+---------------------------------------------------------------------------------+ //| Obter dados no formato MQL. Ver especificações no: | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ datetime CZipContent::MqlDate(void) { MqlDateTime time={0}; ushort date=m_directory.last_mod_date; time.day = date & 0x1F; time.mon = date & 0xE0; time.year= 1980+(date & 0xFE00); return StructToTime(time); }
Conversão de data e hora do formato MS-DOS para o formato do MQL:
//+---------------------------------------------------------------------------------+ //| Obter formato MS-DOS de tempo. Ver especificações em: | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ ushort CZipContent::DosTime(datetime time) { ushort date=0; MqlDateTime mql_time={0}; TimeToStruct(time,mql_time); date=(ushort)mql_time.hour<<11; ushort min=(ushort)mql_time.min<<5; date = date | min; date = date | (ushort)(mql_time.sec/2); return date; }
Conversão de data e hora do formato MS-DOS para o formato do MQL:
//+---------------------------------------------------------------------------------+ //| Obter dados no formato MQL. Ver especificações em: | //| https://msdn.microsoft.com/en-us/library/windows/desktop/ms724247(v=vs.85).aspx | //+---------------------------------------------------------------------------------+ datetime CZipContent::MqlTime(void) { MqlDateTime time={0}; ushort date=m_directory.last_mod_time; time.sec = (date & 0x1F)*2; time.min = date & 0x7E0; time.hour= date & 0xF800; return StructToTime(time); }
Estes métodos utilizam variáveis internas para armazenar data e hora: m_directory.last_mod_time e m_directory.last_mod_date, onde m_directory é o tipo de estrutura "Central Directory".
2.4. Gerando código de checksum CRC-32
Uma característica interessante do formato de arquivo ZIP não é apenas sobre como armazenar dados, mas também uma informação específica com a finalidade de recuperação, onde em alguns casos ajuda a restaurar os dados corrompidos. A fim de verificar se os dados recebidos estão intactos ou danificados, o arquivo ZIP contém um campo especial extra de dois bytes que contém o valor do código "hash" CRC32. Esta é uma soma de verificação (checksum) que é calculada junto aos dados antes da compactação. Depois que os dados são descompactados a partir do arquivo, é recalculada a soma de verificação, e se eles não corresponderem, os dados são considerados corrompidos e não podem ser usados pelo usuário.
Assim, nossa classe CZip precisa ter seu próprio algoritmo de cálculo CRC-32. Caso contrário, os arquivos criados por nossa classe se recusarão a ler as ferramentas de terceiros, como por exemplo, o descompactador WinRAR pode dar um aviso de erro com os dados corrompidos.
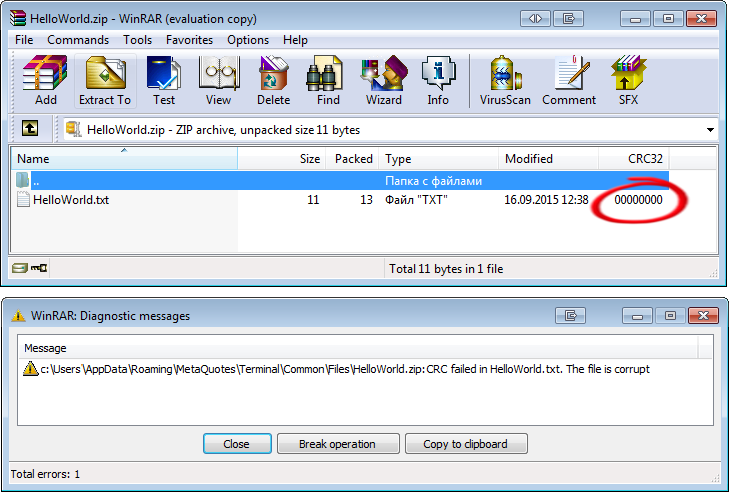
Fig. 9. WinRAR alerta sobre os problemas de dados do arquivo "HelloWorld.txt".
Uma vez que soma de verificação CRC-32 é necessária apenas para arquivos, um método que calcula a soma é fornecido exclusivamente na classe CZipFile. O método é implementado com base no exemplo da linguagem de programação C, disponível no seguinte link: https://ru.wikibooks.org:
//+------------------------------------------------------------------+ //| Retorna o código CRC-32 do array de dados | //+------------------------------------------------------------------+ uint CZipFile::CRC32(uchar &array[]) { uint crc_table[256]; ArrayInitialize(crc_table,0); uint crc=0; for(int i=0; i<256; i++) { crc=i; for(int j=0; j<8; j++) crc=(crc &1)>0 ?(crc>>1)^0xEDB88320 : crc>>1; crc_table[i]=crc; } crc=0xFFFFFFFF; int len=0,size=ArraySize(array); while(len<size) crc=crc_table[(crc^array[len++]) &0xFF]^(crc>>8); return crc ^ 0xFFFFFFFF; }
Para garantir um método de operação correto, basta abrir um arquivo criado no descompactador WinRAR via CZip. Cada arquivo terá o seu código CRC32 original:

Fig. 10. Código de verificação CRC32 na janela do descompactador WinRAR
O arquivo é descompactado no modo normal com um "hash" CRC-32 válido e a mensagem de aviso não aparece.
2.5. Lendo e escrevendo um arquivo
Finalmente, vamos discutir os métodos de leitura e gravação de um arquivo ZIP. Obviamente, se temos uma coleção, por exemplo CArrayObj que consiste nos elementos CZipFile e CZipFolder, o problema da formação do arquivo será de pouca importância. É suficiente converter cada elemento numa seqüência de bytes e escrever em um arquivo. Os métodos para lidar com essas tarefas são os seguintes:
- SaveZipToFile — abre o arquivo indicado e grava o array de bytes gerado.
- ToCharArray — cria a estrutura byte do arquivo correspondente. Gera a estrutura definitiva do ECDR.
- ZipElementsToArray — converte o tipo de elemento CZipContent em uma seqüência de bytes.
A única dificuldade é que cada elemento do arquivo apresentado com CZipContent é armazenado em duas partes de arquivos diferentes, nas estruturas dos "Local File Header" e "Central Directory". Por isso, é necessário utilizar um método especial chamado ZipElementsToArray, onde dependendo do modificador ENUM_ZIP_PART transferido a ele, fornece um array de bytes dos tipos "Local File Header" e "Central Directory".
Agora, tendo esta funcionalidade em mente, teremos uma boa compreensão do conteúdo de todos os três métodos, cujo código fonte é apresentado a seguir:
//+------------------------------------------------------------------+ //| Retorna um array uchar com os elementos ZIP | //+------------------------------------------------------------------+ void CZip::ZipElementsToArray(uchar &zip_elements[],ENUM_ZIP_PART part) { CArrayObj elements; int totalSize=0; for(int i=0; i<m_archive.Total(); i++) { uchar zip_element[]; CZipContent *zipContent=m_archive.At(i); if(part==ZIP_PART_HEADER) zipContent.ToCharArrayHeader(zip_element); else if(part==ZIP_PART_DIRECTORY) zipContent.ToCharArrayDirectory(zip_element); if(part==ZIP_PART_HEADER && zipContent.ZipType()==ZIP_TYPE_FILE) { uchar pack[]; CZipFile *file=zipContent; file.GetPackFile(pack); ArrayCopy(zip_element,pack,ArraySize(zip_element)); } totalSize+=ArraySize(zip_element); elements.Add(new CCharArray(zip_element)); } ArrayResize(zip_elements,totalSize); int offset= 0; for(int i = 0; i<elements.Total(); i++) { CCharArray *objArray=elements.At(i); uchar array[]; objArray.GetArray(array); ArrayCopy(zip_elements,array,offset); offset+=ArraySize(array); } } //+------------------------------------------------------------------+ //| Gera um arquivo ZIP como um array uchar. | //+------------------------------------------------------------------+ void CZip::ToCharArray(uchar &zip_arch[]) { uchar elements[],directories[],ecdr_array[]; ZipElementsToArray(elements,ZIP_PART_HEADER); ZipElementsToArray(directories,ZIP_PART_DIRECTORY); ZipEndRecord ecdr; ecdr.total_entries_disk=(ushort)m_archive.Total(); ecdr.total_entries=(ushort)m_archive.Total(); ecdr.size_central_dir= sizeof(ZipCentralDirectory)*m_archive.Total(); ecdr.start_cd_offset = ArraySize(elements); ecdr.ToCharArray(ecdr_array); int totalSize=ArraySize(elements)+ArraySize(directories)+ArraySize(ecdr_array); ArrayResize(zip_arch,totalSize); ArrayCopy(zip_arch,elements,0); ArrayCopy(zip_arch,directories,ArraySize(elements)); ArrayCopy(zip_arch,ecdr_array,ArraySize(elements)+ArraySize(directories)); } //+------------------------------------------------------------------+ //| Salva o arquivo ZIP no arquivo zip_name | //+------------------------------------------------------------------+ bool CZip::SaveZipToFile(string zip_name,int file_common) { uchar zip[]; ToCharArray(zip); int handle= FileOpen(zip_name,FILE_BIN|FILE_WRITE|file_common); if(handle == INVALID_HANDLE)return false; FileWriteArray(handle,zip); FileClose(handle); return true; }
O carregamento de arquivos tem algumas nuances a considerar. Obviamente, esta é uma operação inversa ao salvar. Se ao salvar um arquivo, os elementos do tipo CZipContent são convertidos numa seqüência de bytes, então ao carregar um arquivo, uma seqüência de byte é convertida em elementos do tipo CZipContent. Novamente, devido ao fato de que cada elemento de arquivo é armazenado em duas partes diferentes de arquivos - "Local File Header" e "Central Directory", o elemento CZipContent não pode ser criado depois de apenas uma leitura de dados.
É necessário usar um recipiente da classe CSourceZip, onde primeramente os elementos necessários são adicionados sequencialmente e então os tipos desejados de dados - CZipFile ou CZipFolder, são formados a partir do mesmo. Esta é a razão, porque estas duas classes têm um construtor adicional, construtor este que aceita um ponteiro para o tipo de elemento CSourceZip como um parâmetro por referência. Este tipo de inicialização, juntamente com a classe CSourceZip, foi criado exclusivamente para uso oficial da classe CZip e não é recomendado para ser diretamente.
Três métodos de classe CZip responsáveis pelo carregamento:
- LoadZipFromFile — abre um arquivo indicado e lê o seu conteúdo num array de bytes.
- LoadHeader — carrega a estrutura do "Local File Header" a partir do array de bytes do arquivos no endereço proposto.
- LoadDirectory — carrega a estrutura "Central Directory" a partir do array de bytes do arquivo no endereço proposto.
Por favor, veja o código fonte destes métodos abaixo:
//+--------------------------------------------------------------------------+ //| Carregamento do Local Header com arquivo do nome pelo array offset. | //| RETORNO: | //| Endereço de retorno após "Local Header", nome e conteúdo zip. | //| Retorno -1 se a leitura falhar. | //+--------------------------------------------------------------------------+ int CZip::LoadHeader(uchar &zip_array[],int offset,CSourceZip &zip) { //Copy local header uchar header[]; ArrayCopy(header,zip_array,0,offset,sizeof(ZipLocalHeader)); if(!zip.header.LoadFromCharArray(header))return -1; offset+=ArraySize(header); uchar name[]; //Copy header file name ArrayCopy(name,zip_array,0,offset,zip.header.filename_length); zip.header_file_name=CharArrayToString(name); offset+=ArraySize(name); //Copy zip array ArrayCopy(zip.zip_array,zip_array,0,offset,zip.header.comp_size); offset+=ArraySize(zip.zip_array); return offset; } //+-------------------------------------------------------------------------+ //| Carregamento do Central Directory com arquivo do nome pelo array offset.| //| RETORNO: | //| Endereço de retorno após CD e nome. | //| Retorno -1 se a leitura falhar. | //+-------------------------------------------------------------------------+ int CZip::LoadDirectory(uchar &zip_array[],int offset,CSourceZip &zip) { //Copy central directory uchar directory[]; ArrayCopy(directory,zip_array,0,offset,sizeof(ZipCentralDirectory)); if(!zip.directory.LoadFromCharArray(directory))return -1; offset+=ArraySize(directory); uchar name[]; //Copy directory file name ArrayCopy(name,zip_array,0,offset,zip.directory.filename_length); zip.directory_file_name=CharArrayToString(name); offset+=ArraySize(name); return offset; } //+-------------------------------------------------------------------------+ //|Carregamento do arquivo ZIP a partir do arquivo HDD. | //+-------------------------------------------------------------------------+ bool CZip::LoadZipFromFile(string full_path,int file_common) { uchar zip_array[]; ZipEndRecord ecdr; if(!LoadZipFile(full_path, file_common, zip_array))return false; if(!TakeECDR(zip_array, ecdr))return false; CSourceZip sources[]; ArrayResize(sources,ecdr.total_entries); int offset=0; int entries=ecdr.total_entries; for(int entry=0; entry<ecdr.total_entries; entry++) offset=LoadHeader(zip_array,offset,sources[entry]); for(int entry=0; entry<ecdr.total_entries; entry++) offset=LoadDirectory(zip_array,offset,sources[entry]); for(int entry=0; entry<ecdr.total_entries; entry++) { bool is_folder=sources[entry].header.bit_flag==3; CZipContent *content=NULL; if(is_folder) content=new CZipDirectory(sources[entry]); else content=new CZipFile(sources[entry]); m_archive.Add(content); } return true; }
Capítulo 3. Exemplos do uso da classe CZip, medindo o desempenho
No capítulo anterior, analisamos a classe CZip e o formato de dados do arquivo ZIP. Agora que conhecemos a estrutura do arquivo e os princípios gerais da classe CZip, podemos prosseguir com tarefas práticas relacionadas com a compactação. Neste capítulo, vamos analisar três exemplos diferentes que melhor definem toda a variedade de tarefas nesta classe.
3.1. Criar um arquivo ZIP com cotações de todos os símbolos selecionados
A primeira tarefa necessária para ser resolvida implica na forma de salvar os dados anteriormente obtidos. Na maioria das vezes os dados são obtidos no terminal MetaTrader.. Tais dados podem ser uma seqüência de ticks e cotações do formato OHLCV. Vamos olhar para o interior do problema, quando as cotações serão salvas em arquivos especiais CSV, cujo formato será o seguinte:
Date;Time;Open;High;Low;Close;Volume 31.08.2015;16:48;1.11767;1.12620;1.11692;1.12020;87230
Este é um formato de dados de texto. É freqüentemente usado para transferir dados entre diferentes sistemas de análises estatísticas. O formato dos arquivos de texto, infelizmente, tem uma grande redundância de armazenamento de dados, uma vez que cada byte tem um número muito limitado de caracteres utilizados. Normalmente, estes são sinais de pontuação, números, letras maiúsculas e minúsculas do alfabeto Além disso, muitos valores neste formato ocorrem frequentemente, por exemplo, a data de abertura ou abertura de preço normalmente são os mesmos para um grande array de dados. Portanto, este tipo de compactação de dados tem que ser eficaz.
Então, vamos escrever um script para adquirir os dados necessários a partir do terminal. O algoritmo será o seguinte:
- Os instrumentos apresentados na janela de Observação do Mercado são selecionados sequencialmente.
- Cada instrumento selecionado tem cotações solicitadas para cada um dos 21 timeframes.
- As cotações do timeframe selecionado são convertidas em um array de linhas CSV.
- O array de linhas CSV é convertido em um array de bytes.
- Um arquivo ZIP (CZipFile) contendo um array de bytes das cotações é criado e depois adicionado ao arquivo.
- Depois de criar todos os arquivos de cotação, a classe CZip é salva no disco do computador no arquivo Quotes.zip.
O código fonte do script para executar essas ações é o seguinte:
//+------------------------------------------------------------------+ //| ZipTask1.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> CZip Zip; // Create empty ZIP archive. //+------------------------------------------------------------------+ //| Script da função inicial do programa. | //+------------------------------------------------------------------+ void OnStart() { CopyBarsToCSV(); } //+------------------------------------------------------------------+ //| Criar ZIP com as cotações da observação do mercado | //+------------------------------------------------------------------+ void CopyBarsToCSV(void) { bool MarketWatch=true; for(int i=0; i<SymbolsTotal(MarketWatch); i++) { string symbol=SymbolName(i,MarketWatch); printf("Save quotes "+symbol+"..."); for(int t=1; t<22; t++) { ENUM_TIMEFRAMES tf=TimeframeAt(t); MqlRates rates[]; CopyRates(symbol,tf,0,100,rates); string csv_lines[]; uchar src_array[]; RatesToCSV(rates,csv_lines); LinesToCharArray(csv_lines,src_array); string name_arch=GenName(symbol,tf); CZipFile *file=new CZipFile(name_arch,src_array); Zip.AddFile(file); } } Zip.SaveZipToFile("Quotes.zip",FILE_COMMON); } ENUM_TIMEFRAMES TimeframeAt(int index) { switch(index) { case 1: return PERIOD_M1; case 2: return PERIOD_M2; case 3: return PERIOD_M3; case 4: return PERIOD_M4; case 5: return PERIOD_M5; case 6: return PERIOD_M6; case 7: return PERIOD_M10; case 8: return PERIOD_M12; case 9: return PERIOD_M15; case 10: return PERIOD_M20; case 11: return PERIOD_M30; case 12: return PERIOD_H1; case 13: return PERIOD_H2; case 14: return PERIOD_H3; case 15: return PERIOD_H4; case 16: return PERIOD_H6; case 17: return PERIOD_H8; case 18: return PERIOD_H12; case 19: return PERIOD_D1; case 20: return PERIOD_W1; case 21: return PERIOD_MN1; } return PERIOD_CURRENT; } void RatesToCSV(MqlRates &rates[],string &csv_lines[]) { string t=";"; ArrayResize(csv_lines,ArraySize(rates)); for(int i=0; i<ArraySize(rates); i++) { csv_lines[i] = TimeToString(rates[i].time,TIME_DATE|TIME_MINUTES)+ t; csv_lines[i]+= DoubleToString(rates[i].open,5) + t + DoubleToString(rates[i].high, 5) + t + DoubleToString(rates[i].low, 5) + t + DoubleToString(rates[i].close, 5) + t + (string)rates[i].tick_volume+t+"\n"; } } void LinesToCharArray(string &csv_lines[],uchar &src_array[]) { int size=0; for(int i=0; i<ArraySize(csv_lines); i++) size+=StringLen(csv_lines[i]); ArrayResize(src_array,size); size=0; for(int i=0; i<ArraySize(csv_lines); i++) { uchar array[]; StringToCharArray(csv_lines[i],array); ArrayCopy(src_array,array,size,0,WHOLE_ARRAY); size+=ArraySize(array); } } string GenName(string symbol,ENUM_TIMEFRAMES tf) { string stf=EnumToString(tf); string period=StringSubstr(stf,6); string name=symbol+"\\"+symbol+period+".csv"; return name; } //+------------------------------------------------------------------+
O carregamento de dados pode demorar um tempo considerável, portanto apenas quatro símbolos foram selecionados na Observação do Mercado. Além disso, vamos carregar apenas a última de uma centena de barras conhecidas. Isto deve reduzir o tempo de execução do script. Após a sua execução na pasta de arquivos MetaTrader compartilhada, aparece o arquivo Quotes.zip. O seu conteúdo pode ser visto em qualquer programa que opera com arquivos, como o WinRAR, por exemplo:
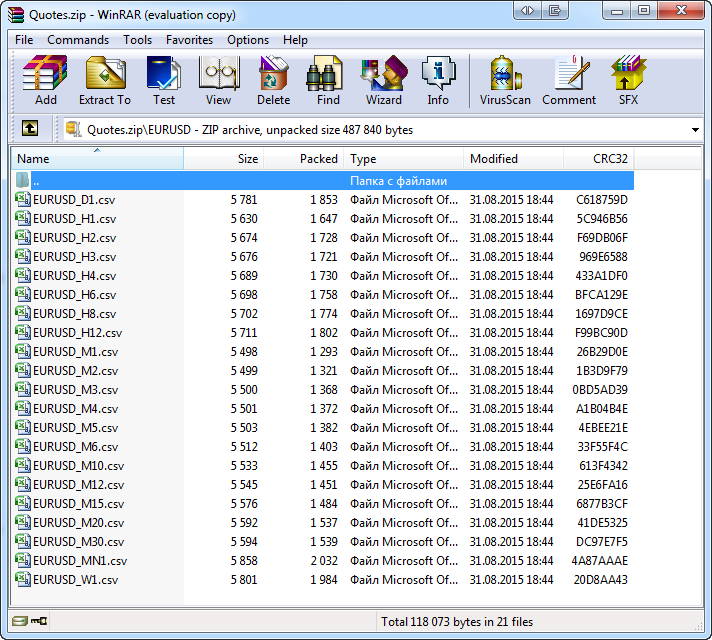
Fig. 11. Arquivos salvos com cotações são visualizados no descompactador WinRAR
O arquivo compactado criado é três vezes menor em comparação ao seu tamanho original. Esta Informação e fornecida pelo WinRAR:
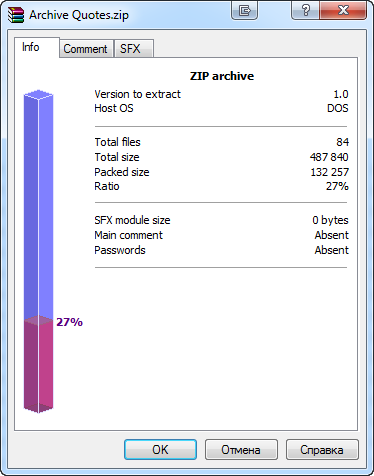
Fig. 12. Taxa de compactação de um arquivo gerado numa janela de informações WinRAR
Estes são bons resultados de compactação. No entanto, poderia ser alcançada uma taxa de compactação ainda melhor com arquivos pesados que são em número reduzidos.
O exemplo de um script que cria cotações e os salva num arquivo ZIP está anexado ao presente artigo sob o nome ZipTask1.mq5 e está localizado na pasta Scripts.
3.2. Baixando um arquivo a partir de um servidor remoto, MQL5.com é utilizado como exemplo
A próxima tarefa que vamos estudar é relacionada a rede. Nosso exemplo irá demonstrar, como você pode baixar arquivos ZIP de servidores remotos. Como exemplo, vamos carregar o indicador chamado Alligator, está localizado na Base de Código no seguinte link: https://www.mql5.com/en/code/9
Para cada indicador, Expert Advisor, script ou biblioteca que são publicados na Base de Código, existe uma versão de arquivo, onde todos os códigos fontes de produtos são compactados num único arquivo. Vamos baixar e descompactar esta versão arquivada num computador local. Antes de prosseguir, você deve autorizar o acesso ao site mql5.com: na janela Serviço -> Configurações -> Expert Advisors é necessário escrever o seguinte endereço na lista de servidores permitidos: "https://www.mql5.com".
A classe CZip tem seu próprio método de download de arquivos a partir dos recursos da Internet. Mas, em vez de usá-lo, vamos escrever nosso próprio script, que realiza o seguinte carregamento:
//+------------------------------------------------------------------+ //| ZipTask2.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> CZip Zip; //+------------------------------------------------------------------+ //| Script da função inicial do programa | //+------------------------------------------------------------------+ void OnStart() { string cookie,headers; string mql_url="https://www.mql5.com/ru/code/download/9"; int timeout=5000; uchar data[],zip_array[]; if(!WebRequest("GET",mql_url,cookie,NULL,timeout,data,0,zip_array,headers)) { printf("Unable to download ZIP archive from "+mql_url+". Check request and permissions EA."); return; } if(!Zip.CreateFromCharArray(zip_array)) { printf("Loaded bad ZIP archive. Check results array."); return; } printf("Archive successfully loaded. Total files: "+(string)Zip.TotalElements()); Zip.UnpackZipArchive("Alligator",FILE_COMMON); } //+------------------------------------------------------------------+
Como você pode ver, o código fonte do script é bastante simples. Inicialmente, o WebRequest com o endereço remoto do arquivo ZIP é chamado. O WebRequest carrega arrays de bytes do arquivo para o array obtido zip_array, em seguida, ele é carregado na classe CZip, usando o método CreateFromCharArray. Este método permite criar um arquivo diretamente de uma seqüência de bytes que às vezes é necessário para a operações internas com arquivos.
Além do método CreateFromCharArray, CZip LoadFromUrl inclui um método especial, LoadZipFromUrl, para baixar arquivos a partir de um link da web. Ela opera aproximadamente como nosso script anterior. Aqui está o código fonte:
//+------------------------------------------------------------------+ //| Carregar arquivo ZIP a partir da url | //+------------------------------------------------------------------+ bool CZip::LoadZipFromUrl(string url) { string cookie,headers; int timeout=5000; uchar data[],zip_array[]; if(!WebRequest("GET",url,cookie,NULL,timeout,data,0,zip_array,headers)) { SetUserError(ZIP_ERROR_BAD_URL); return false; } return CreateFromCharArray(zip_array); }
O resultado da operação deste método é o mesmo: um arquivo ZIP será criado depois de algum tempo e o seu conteúdo será baixado a partir de um servidor remoto.
Exemplo do script que faz o download de arquivos a partir do Base de Código está anexado a este artigo com o nome ZipTask2.mq5 e está localizado na pasta Scripts.
3.3. Compressão de dados internos do programa na memória RAM.
A compressão de dados internos do programa na RAM é uma forma não trivial de usar a compactação. Este método pode ser usado, quando existem muitos dados em processamento na memória. No entanto, ao usar essa abordagem, o desempenho total do programa é diminuído, pois ações adicionais são necessárias para compactação/descompactação das estruturas ou dados.
Vamos imaginar que o programa MQL tem de armazenar uma coleção de ordens históricas. Cada ordem será descrita por uma estrutura especial de Ordem que irá conter todas as suas propriedades: um identificador, tipo de ordem, tempo de renderização, volume, etc. Vamos descrever esta estrutura:
//+------------------------------------------------------------------+ //| Histórico de ordem | //+------------------------------------------------------------------+ struct Order { private: uchar m_comment[32]; uchar m_symbol[32]; public: ulong ticket; // Ticket da ordem datetime time_setup; // Setup do Tempo da ordem ENUM_ORDER_TYPE type; // Tipo da order ENUM_ORDER_STATE state; // Estado da ordem datetime time_exp; // Tempo de expiração datetime time_done; // Tempo alcançado ou cancelamento da ordem long time_setup_msc; // Tempo configurado em msc long time_done_msc; // Tempo alcançado em msc ENUM_ORDER_TYPE_FILLING filling; // Tipo de preenchimento ENUM_ORDER_TYPE_TIME type_time; // Tipo do tempo real ulong magic; // Número mágico da ordem ulong position_id; // Posição da ID double vol_init; // Volume inicial double vol_curr; // Volume real double price_open; // Preço de abertura double sl; // Nível Stop-Loss double tp; // Nível Take-Profit level double price_current; // Preço atual double price_stop_limit; // Preço stop limit string Comment(void); string Symbol(void); void Comment(string comment); void Symbol(string symbol); void ToCharArray(uchar& array[]); void InitByTicket(ulong ticket); }; //+------------------------------------------------------------------+ //| Início pelo ticket | //+------------------------------------------------------------------+ void Order::InitByTicket(ulong id) { this.ticket= id; time_setup =(datetime)HistoryOrderGetInteger(ticket,ORDER_TIME_SETUP); type=(ENUM_ORDER_TYPE)HistoryOrderGetInteger(ticket,ORDER_TYPE); state=(ENUM_ORDER_STATE)HistoryOrderGetInteger(ticket,ORDER_STATE); time_exp=(datetime)HistoryOrderGetInteger(ticket,ORDER_TIME_EXPIRATION); time_done=(datetime)HistoryOrderGetInteger(ticket,ORDER_TIME_DONE); time_setup_msc= HistoryOrderGetInteger(ticket,ORDER_TIME_SETUP_MSC); time_done_msc = HistoryOrderGetInteger(ticket,ORDER_TIME_DONE_MSC); filling=(ENUM_ORDER_TYPE_FILLING)HistoryOrderGetInteger(ticket,ORDER_TYPE_FILLING); type_time=(ENUM_ORDER_TYPE_TIME)HistoryOrderGetInteger(ticket,ORDER_TYPE_TIME); magic=HistoryOrderGetInteger(ticket,ORDER_MAGIC); position_id=HistoryOrderGetInteger(ticket,ORDER_POSITION_ID); vol_init = HistoryOrderGetDouble(ticket, ORDER_VOLUME_INITIAL); vol_curr = HistoryOrderGetDouble(ticket, ORDER_VOLUME_CURRENT); price_open=HistoryOrderGetDouble(ticket,ORDER_PRICE_OPEN); price_current=HistoryOrderGetDouble(ticket,ORDER_PRICE_CURRENT); sl = HistoryOrderGetDouble(ticket, ORDER_SL); tp = HistoryOrderGetDouble(ticket, ORDER_TP); price_stop_limit=HistoryOrderGetDouble(ticket,ORDER_PRICE_STOPLIMIT); this.Symbol(HistoryOrderGetString(ticket, ORDER_SYMBOL)); this.Comment(HistoryOrderGetString(ticket, ORDER_COMMENT)); } //+------------------------------------------------------------------+ //| Comentário de retorno da ordem | //+------------------------------------------------------------------+ string Order::Comment(void) { return CharArrayToString(m_comment); } //+------------------------------------------------------------------+ //| Retorno do símbolo da ordem | //+------------------------------------------------------------------+ string Order::Symbol(void) { return ""; } //+------------------------------------------------------------------+ //| Definir comentário da ordem | //+------------------------------------------------------------------+ void Order::Comment(string comment) { string s=StringSubstr(comment,0,32); StringToCharArray(s,m_comment); } //+------------------------------------------------------------------+ //| Definir símbolo da ordem | //+------------------------------------------------------------------+ void Order::Symbol(string symbol) { string s=StringSubstr(symbol,0,32); StringToCharArray(s,m_symbol); } //+------------------------------------------------------------------+ //| Converter para array uchar. | //+------------------------------------------------------------------+ struct OrderArray { uchar array[sizeof(Order)]; }; //+------------------------------------------------------------------+ //| Converter estrutura de ordem para array uchar | //+------------------------------------------------------------------+ void Order::ToCharArray(uchar &array[]) { OrderArray src_array; src_array=(OrderArray)this; ArrayCopy(array,src_array.array); }
A chamada ao operador sizeof mostra que essa estrutura tem 200 bytes. Desta forma, o armazenamento da coleção das ordens históricas toma o número de bytes calculado pela fórmula: sizeof (Ordem) * número de ordens históricas . Consequentemente, para a coleção que inclui 1000 ordens históricas, vamos requerer a seguinte memória 200 * 1000 = 200 000 bytes ou quase 200 KB. Não é muito para os padrões de hoje, mas no caso o tamanho de coleção ser superior a dezenas de milhares de elementos, a quantidade de memória utilizada será crucial.
No entanto, é possível desenvolver um recipiente especial para armazenar estas ordens, o que permitiria a compactação do seu conteúdo. Este recipiente, somado aos métodos convencionais de adição e eliminação de novos elementos Ordem, também irá conter os métodos Pack e Unpack que compactam o conteúdo das estruturas do tipo Ordem. Abaixo o código fonte do recipiente:
//+------------------------------------------------------------------+ //| Recipiente de ordens. | //+------------------------------------------------------------------+ class COrderList { private: CArrayObj m_orders; uchar m_packed[]; public: bool AddOrder(Order& order); int TotalOrders(void); void At(int index, Order& order); bool DeleteAt(int index); void Pack(void); void Unpack(void); bool IsPacked(); int Size(); }; //+------------------------------------------------------------------+ //| Retorna o estado compactado | //+------------------------------------------------------------------+ bool COrderList::IsPacked(void) { return (ArraySize(m_packed) > 0); } //+------------------------------------------------------------------+ //| Adiciona nova ordem. | //+------------------------------------------------------------------+ bool COrderList::AddOrder(Order &order) { if(IsPacked()) Unpack(); COrderObj *o=new COrderObj(); o.order=order; return m_orders.Add(o); } //+------------------------------------------------------------------+ //| Retorna a ordem do índice. | //+------------------------------------------------------------------+ void COrderList::At(int index,Order &order) { if(IsPacked()) Unpack(); COrderObj *o=m_orders.At(index); order=o.order; } //+------------------------------------------------------------------+ //| Retorna o total das ordens. | //+------------------------------------------------------------------+ int COrderList::TotalOrders(void) { if(IsPacked()) Unpack(); return m_orders.Total(); } //+------------------------------------------------------------------+ //| Excluir ordem pelo índice. | //+------------------------------------------------------------------+ bool COrderList::DeleteAt(int index) { if(IsPacked()) Unpack(); return m_orders.Delete(index); } //+------------------------------------------------------------------+ //| Retorna ao estado compactado. | //+------------------------------------------------------------------+ void COrderList::Unpack(void) { if(!IsPacked())return; uchar unpack[]; uchar key[]={1,0,0,0}; CryptDecode(CRYPT_ARCH_ZIP,m_packed,key,unpack); int size=ArraySize(unpack); m_orders.Clear(); for(int offset=0; offset<size; offset+=sizeof(Order)) { OrderArray o; ArrayCopy(o.array,unpack,0,offset,sizeof(Order)); COrderObj *orderObj=new COrderObj(); orderObj.order=(Order)o; m_orders.Add(orderObj); } ArrayResize(m_packed,0); } //+------------------------------------------------------------------+ //| Retorna ao estado compactado. | //+------------------------------------------------------------------+ void COrderList::Pack(void) { if(IsPacked())return; int size=m_orders.Total()*sizeof(Order); uchar array[]; ArrayResize(array,size); for(int i=0,offset=0; i<m_orders.Total(); i++,offset+=sizeof(Order)) { COrderObj *orderObj=m_orders.At(i); OrderArray o; o=(OrderArray)orderObj.order; ArrayCopy(array,o.array,0,offset); } uchar key[]={1,0,0,0}; CryptEncode(CRYPT_ARCH_ZIP,array,key,m_packed); m_orders.Clear(); } //+------------------------------------------------------------------+ //| Retorna tamanho das ordens. | //+------------------------------------------------------------------+ int COrderList::Size(void) { if(IsPacked()) return ArraySize(m_packed); return m_orders.Total()*sizeof(Order); }
A ideia é que o usuário possa adicionar novos elementos para ao recipiente, e se necessário, compactar o seu conteúdo diretamente na RAM do computador. Vamos ver como isto trabalha. Este é um script de demonstração:
//+------------------------------------------------------------------+ //| ZipTask3.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Orders.mqh> //+------------------------------------------------------------------+ //| Script da função inicial | //+------------------------------------------------------------------+ void OnStart() { OrderList list; HistorySelect(0,TimeCurrent()); int total = HistoryOrdersTotal(); for(int i = 0; i < total; i++) { ulong ticket=HistoryOrderGetTicket(i); Order order; order.InitByTicket(ticket); list.AddOrder(order); } int unpack_size=list.Size(); uint tiks=GetTickCount(); list.Pack(); uint time_tiks= GetTickCount()-tiks; int pack_size = list.Size(); string per=DoubleToString((double)pack_size/(double)unpack_size*100.0,2); string message="Unpack size: "+(string)unpack_size+"bytes; "+ "Pack size: "+(string)pack_size+" bytes ("+per+" percent compressed. "+ "Pack execute msc: "+(string) time_tiks; printf(message); int totals=list.TotalOrders(); if(list.TotalOrders()>0) { Order first; list.At(0,first); printf("First id ticket: "+(string)first.ticket); } } //+------------------------------------------------------------------+
O momento da compactação da coleção é destacado em amarelo. Anexado numa das contas que tem 858 ordens históricas, este script obteve os seguintes resultados:
2015.09.01 15:47:31.182 ZipTask3 (SBRF-9.15,H1) Unpack size: 171600 bytes; Pack size: 1521 bytes (0.89 percent compressed. Pack execute microsec.: 2534
Como você pode ver, o tamanho da coleção descompactada é 171.600 bytes. O tamanho da coleção após a compactação é apenas 1521 bytes, o que significa que a taxa de compactação ultrapassou uma centena de vezes! Isto se deve ao fato de que muitos campos da estrutura contêm dados semelhantes. Também muitos campos têm valores vazios em que a memória é alocada.
Para garantir que a compactação funcione corretamente, você precisa escolher qualquer ordem da coleção e imprimir suas propriedades. Nós escolhemos a primeira ordem e seu identificador único. Depois de compactar, o identificador da ordem foi apresentado corretamente:
2015.09.01 15:47:31.182 ZipTask3 (SBRF-9.15,H1) First id ticket: 10279280
O algoritmo descrito reduz a produtividade, ao se referir à sua coleção descompactada previamente dos dados. Portanto, os dados precisam ser compactados somente após a formação de trabalho ficar completa. Para uma taxa de compactação melhor, todos os dados são coletados num único array e então compactados. O processo inverso aplica-se para descompactar.
Curiosamente, a compactação de 858 elementos ocorre em apenas 2,5 milissegundos num computador suficientemente poderoso. Descompactar os mesmos dados é mais rápido, demora cerca de 0,9 milissegundos. Assim, um ciclo de compactação/descompactação de um array contendo milhares de elementos leva cerca de 3,5-4,0 milissegundos. Isto ajuda a economizar memória em mais de cem vezes. Tais características são suficientemente impressionantes para justificar o uso da compactação ZIP na organização de grandes conjuntos de dados.
O exemplo de um script que compacta os dados na memória de um computador está anexado a este artigo com o nome ZipTask 3.mq5 e está localizado na pasta Scripts. Também é necessário colocar o arquivo Orders.mqh na pasta Include para o correto funcionamento da operação.
Capítulo 4. Documentação para as classes que operam com arquivos ZIP
4.1. Documentação para a classe CZipContent
Este capítulo descreve os métodos e enumerações usadas nas classes que manipulam arquivos ZIP. A classe CZipContent não é usada diretamente no nível de usuário, no entanto todos os seus métodos públicos são delegados pelas classes CZipFile e CZipFolder, portanto propriedades e métodos descritos lá também se aplicam a essas classes.
Método ZipType()
O método ZipType retorna o tipo do elemento corrente no arquivo. Existem dois tipos de itens armazenados no arquivo: uma pasta (diretório) e um arquivo. O tipo de uma pasta é representado pela classe CZipDirectory; o tipo de um arquivo, pela classe CZipFile. Para mais informações sobre os tipos de arquivo ZIP você pode ler na seção 2.1 do capítulo atual: " Estrutura de arquivos compactados dentro de um arquivo, classes CZipFile e CZipFolder".
ENUM_ZIP_TYPE ZipType(void); Valor retornado
Retorna a enumeração ENUM ZIP_TYPE que descreve a qual tipo a cópia CZipContent atual pertence.
Método Name (void)
Retorna o nome da pasta ou o nome do arquivo no arquivo.
string Name(void);
Valor retornado
Nome do arquivo ou nome da pasta.
Método Name(nome da string)
Define o nome da pasta ou arquivo atual em num arquivo. Usado para alterar o nome da pasta ou arquivo atual.
void Name(nome da string);
Parâmetros:
- [in] name — nova pasta ou nome de arquivo. O nome deve ser único e não têm a simultaneidade com outros nomes em pastas de arquivo ou arquivos.
Método CreateDateTime (datetime date_time)
Define uma nova data de modificação de uma pasta ou arquivo no arquivo.
void CreateDateTime(datetime date_time);
Parâmetros:
- [in] date_time — data e hora necessárias para definir uma pasta ou arquivo.
Nota:
Data e hora são convertidos para o formato MS-DOS, são armazenados nas estruturas internas dos tipos ZipLocalHeader e ZipCentralDirectory. Para mais informações sobre maneiras de converter e apresentar este formato, por favor leia o capítulo 2.3 do presente artigo: "Relembrando MS-DOS. Formato data e hora num arquivo ZIP".
Método CreateDateTime (void)
Retorna uma data e hora para alterar uma pasta ou arquivo atual.
datetime CreateDateTime(void);
Valor retornado
Data e hora para alterar uma pasta ou arquivo atual.
Método CompressedSize()
Retorna o tamanho dos dados compactados no arquivo, sempre igual a zero para os diretórios.
uint CompressedSize(void);
Valor de Retorno
Tamanho dos dados compactados em bytes.
Método UncompressedSize()
Retorna o tamanho dos dados não compactados originais de um arquivo, sempre igual a zero aos diretórios.
uint UncompressedSize(void);
Valor de Retorno
Tamanho de dados originais em bytes.
Método TotalSize()
Retorna o tamanho total de um elemento do arquivo. Cada arquivo ou diretório, além do seu nome e conteúdo (para arquivos), armazena estruturas de serviços adicionais, e seu tamanho também está incluído no cálculo do tamanho total do arquivo.
int TotalSize(void);
Valor de Retorno
O tamanho total de um elemento do arquivo atual com dados de serviço adicional.
Método FileNameLength()
Retorna o comprimento do nome de um diretório ou um arquivo expressando a quantidade de símbolos usados.
ushort FileNameLength(void);
Valor de Retorno
Comprimento do nome de um diretório ou um arquivo expressando na quantidade de símbolos usados.
Método UnpackOnDisk()
Descompacta os conteúdos do elemento e armazena-os em um arquivo com um nome do elemento no disco rígido de um computador. Se um diretório é descompactado, então em vez de um arquivo, uma pasta importante é criada.
bool UnpackOnDisk(string folder, int file_common);
Parâmetros
- [in] folder — nome de uma pasta raiz onde uma pasta ou um arquivo atual tem de ser compactado. Se um elemento tem de ser descompactado sem a criação de uma pasta de arquivo, então esse valor deve permanecer vazio e igual a "".
- [in] file_common - esse modificador indica em qual seção um sistema de arquivos do programa MetaTrader tem que descompactar um elemento. Por favor, defina esse parâmetro igual a FILE_COMMON, se você deseja realizar uma descompactação numa seção de arquivo comum a todos os terminais MetaTrader 5.
Valor retornado
Retorna o valor verdadeiro, se um arquivo ou pasta foi descompactado num disco rígido com êxito. Retorna falso, caso contrário.
4.2. Documentação para classe CZipFile
A classe CZipFile é herdada da CZipContent e usada para armazenar arquivos. A classe CZipFile armazena o conteúdo do arquivo somente de forma compactada. Isso significa que ao transferir um arquivo para armazenamento, ele compacta automaticamente o seu conteúdo. A descompactação de arquivos também ocorre automaticamente quando chamar o método GetUnpackFile. Além de uma série de métodos da classe CZipContent suportados, a classe CZipFile também suporta métodos especiais que operam com arquivos. Veja uma descrição destes métodos abaixo.
Método AddFile()
Adiciona um arquivo do disco rígido a um elemento CZipFile atual. Para adicionar um arquivo do tipo CZip, você deve primeiro criar uma cópia da classe CZipFile e especificar seu nome e localização. Depois a amostra da classe é criada, ela terá de ser adicionada à classe CZip chamando o método apropriado. Compactação real dos conteúdos transferidos ocorre no momento da adição deles (chamando este método).
bool AddFile(string full_path, int file_common);
Parâmetros
- [in] full_path - o nome completo do arquivo, incluindo seu caminho, com relação ao catálogo de arquivos dos programas MQL.
- [in] file_common - este modificador indica em qual seção do sistema de arquivos do programa MetaTrader é necessário descompactar um elemento. Por favor, defina esse parâmetro igual a FILE_COMMON, se você deseja realizar uma descompactação numa seção de arquivo comum a todos os terminais MetaTrader 5.
Valor retornado
Retorna verdadeiro se adicionar um arquivo com êxito. Retorna falso, caso contrário.
Método AddFileArray()
Acrescenta um array de bytes do tipo uchar como o conteúdo CZipFile. Este método é utilizado no caso de uma criação dinâmica de conteúdo dos arquivos. A compactação real de conteúdos transferidos ocorre no momento em que são adicionados (chamada deste método).
bool AddFileArray(uchar& file_src[]);
Parâmetros
- [in] file_src — um array de bytes que será adicionado.
Valor retornado
Retorna verdadeiro se adicionar um arquivo com êxito. Retorna falso, caso contrário.
Método GetPackFile()
Retorna o conteúdo do arquivo compactado.
void GetPackFile(uchar& file_array[]);
Parâmetros
- [out] file_array - um array de bytes com o conteúdo dos arquivos compactados.
Método GetUnpackFile()
Retorna o conteúdo do arquivo descompactado. O conteúdo é descompactado no momento da chamada do método.
void GetUnpackFile(uchar& file_array[]);
Parâmetros
- [out] file_array - uma array de bytes com o conteúdo dos arquivos descompactados.
4.3. Documentação para classe CZip
A classe CZip implementa a principal operação com arquivos do tipo ZIP. A classe é um arquivo ZIP genérico que pode ter dois tipos de elementos ZIP adicionados: elementos que representam uma pasta (CZipDirectory) e elementos para um arquivo ZIP (CZipFile). Entre outras coisas, a classe CZip permite carregar os arquivos já existentes, tanto do disco rígido do computador, bem como sob a forma de uma sequência de bytes.
Método ToCharArray()
Ele converte o conteúdo de um arquivo ZIP numa seqüência de bytes do tipo uchar.
void ToCharArray(uchar& zip_arch[]);
Parâmetros
- [out] zip_arch — array de bytes com o conteúdo de um arquivo ZIP.
Método CreateFromCharArray()
Ele carrega um arquivo ZIP a partir de uma seqüência de bytes.
bool CreateFromCharArray(uchar& zip_arch[]);
Parâmetros
- [out] zip_arch - um array de bytes com o conteúdo do arquivo ZIP.
Valor retornado
Valor Verdadeiro, se a criação do arquivo a partir de uma seqüência de byte teve êxito, valor falso valor caso contrário.
Método SaveZipToFile()
Salva um arquivo ZIP em andamento com o seu conteúdo no arquivo indicado.
bool SaveZipToFile(string zip_name, int file_common);
Parâmetros
- [in] zip_name - o nome completo de um arquivo, incluindo o seu caminho em relação ao diretório central de programas MQL.
- [in] file_common - este modificador indica qual seção do sistema de arquivos do programa MetaTrader é necessário para descompactar um elemento. Por favor, defina esse parâmetro igual a FILE_COMMON, se você deseja realizar uma descompactação numa seção de arquivo comum a todos os terminais MetaTrader 5.
Valor retornado
Verdadeiro se a operação foi bem sucedida, e falso caso contrário.
Método LoadZipFromFile()
Carrega conteúdos de arquivos no disco rígido de um computador.
bool LoadZipFromFile(string full_path, int file_common);
Parâmetros
- [in] full_path - o nome completo do arquivo, incluindo seu caminho, com relação ao catálogo de arquivos dos programas MQL.
- [in] file_common - este modificador indica qual seção do sistema de arquivos do programa MetaTrader é necessário para descompactar um elemento. Por favor, defina esse parâmetro igual a FILE_COMMON, se você deseja realizar uma descompactação numa seção de arquivo comum a todos os terminais MetaTrader 5.
Valor retornado
Verdadeiro se o carregamento do arquivo teve êxito; e falso caso contrário.
Método LoadZipFromUrl()
Ele carrega o conteúdo do arquivo em um link url da web. Para o correto funcionamento desse método é necessário configurar a permissão para acessar o recurso solicitado. Para mais detalhes sobre este método, leia a seção 3.2 deste artigo: "Baixando um arquivo a partir de um servidor remoto, MQL5.com é utilizado como exemplo."
bool LoadZipFromUrl(string url);
Parâmetros
- [in] url — referência a um arquivo.
Método UnpackZipArchive()
Descompacta todo o conteúdo do arquivo corrente no diretório atual.
bool UnpackZipArchive(string folder, int file_common);
Parâmetros
- [in] folder — pasta onde o arquivo corrente vai ser descompactado. Se não houver necessidade de criar uma pasta de arquivo, você deve transmitir um valor nulo como parâmetro "".
- [in] file_common - este modificador indica em qual seção do sistema de arquivos do programa MetaTrader é necessário descompactar um elemento. Por favor, defina esse parâmetro igual a FILE_COMMON, se você deseja realizar uma descompactação numa seção de arquivo comum a todos os terminais MetaTrader 5.
Valor retornado
Verdadeiro se a descompressão do arquivo for bem sucedida; falso, caso contrário.
Método Size()
Retorna o tamanho do arquivo em bytes.
int Size(void); Valor retornado
Tamanho do arquivo em bytes.
Método TotalElements()
Retorna o número de elementos no arquivo. Um elemento do arquivo pode ser um diretório ou um arquivo compactado.
int TotalElements(void);
Valor retornado
Número de elementos no arquivo.
Método AddFile()
Adiciona um novo arquivo ZIP a um arquivo atual. Um arquivo deve ser apresentado sob a forma CZipFile e criado com antecedência antes de ser adicionado a um arquivo.
bool AddFile(CZipFile* file); Parâmetros
- [in] file - um arquivo ZIP que tem de ser adicionado a um arquivo.
Valor retornado
Verdadeiro se a adição do arquivo ocorreu com êxito; falso, caso contrário.
Método DeleteFile()
Exclui o arquivo tipo CZipFile com índice de um arquivo.
bool DeleteFile(int index);
Parâmetros
- [in] index - índice de um arquivo que tem de ser excluído de um arquivo.
Valor retornado
Verdadeiro se a exclusão do arquivo ocorreu com êxito. Falso, caso contrário.
Método ElementAt()
Ele obtém o tipo de elemento CZipFile localizado no índice.
CZipContent* ElementAt(int index)const;
Parâmetros
- [in] index - um índice de arquivo que tem de ser obtido a partir de um arquivo.
Valor retornado
O elemento do tipo CZipFile localizado no index.
4.4. Estrutura do ENUM_ZIP_ERROR e recebimento das informações detalhadas do erro
No processo de trabalhar com as classes CZip, CZipFile e CZipDirectory podem ocorrer vários erros, como por exemplo, ao tentar acessar um arquivo inexistente, etc. A maioria dos métodos apresentados nessas classes retornam a flag relevante do tipo bool que sinaliza o sucesso da transação. No caso de um valor negativo retorna (falso), você pode obter informações adicionais sobre as razões da falha. As causas da falha podem ser padrões, erros de sistema e erros específicos que ocorrem no processo de operação com arquivos ZIP. Para transferir erros específicos do mecanismo de transmissão dos erros de usuario, é uitizada a função SetUserError. Códigos de erros do usuário são definidos pelo enumerador ENUM_ZIP_ERROR:
Transferindo ENUM_ZIP_ERROR
| Valor | Descrição |
|---|---|
| ZIP_ERROR_EMPTY_SOURCE | Um arquivo transferido para a compactação, em branco. |
| ZIP_ERROR_BAD_PACK_ZIP | Erro interno do compactador/descompactador. |
| ZIP_ERROR_BAD_FORMAT_ZIP | Um formato de arquivo ZIP transferido não corresponde ao padrão ou está corrompido. |
| ZIP_ERROR_NAME_ALREADY_EXITS | O nome de um arquivo que o usuário deseja salvar já está sendo utilizado. |
| ZIP_ERROR_BAD_URL | Link de transferência não se refere a um arquivo ZIP, ou o acesso ao recurso específico da Web é proibido pelas configurações do terminal. |
Após o recebimento de um erro do usuário, você deve explicitamente trazê-lo ao enumerador ENUM_ZIP_ERROR e tratá-lo adequadamente. Um exemplo de trabalho com erros que surgem no decurso do funcionamento com as classes de compactação é apresentado a seguir como um script:
//+------------------------------------------------------------------+ //| ZipError.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> //+------------------------------------------------------------------+ //| Programa script da função inicial | //+------------------------------------------------------------------+ void OnStart() { CZip Zip; bool res=Zip.LoadZipFromFile("TestZip.zip",FILE_COMMON); if(!res) { uint last_error=GetLastError(); if(last_error<ERR_USER_ERROR_FIRST) printf("System error when loading archive. Error code: "+(string)last_error); else { ENUM_ZIP_ERROR error=(ENUM_ZIP_ERROR)(last_error-ERR_USER_ERROR_FIRST); printf("There was an error in archive processing at the point of loading: "+EnumToString(error)); } } } //+------------------------------------------------------------------+
4.5. Descrição dos arquivos anexados neste artigo
Abaixo temos uma breve descrição dos arquivos anexados a este artigo:
- Zip\Zip.mqh — contém a classe principal para trabalhar com arquivos CZip.
- Zip\ZipContent.mqh - contém a classe central CZipContent para as classes básicas de elementos do arquivo: CZipFile e GZipDirectory.
- Zip\ZipFile.mqh - contém a classe para operar com arquivos ZIP.
- Zip\Zip Directory.mqh - contém a classe que opera com pastas ZIP do arquivo.
- Zip\ZipHeader.mqh - o arquivo contém a descrição das Estruturas "File Local Header", "Central Directory" "End Central Directory Record".
- Zip\Zip Defines.mqh - Listas de definições, constantes e códigos de erro usados com classes de compactação.
- Dictionary.mqh - classe adicional que fornece controle de único arquivo e nomes de diretório adicionados a um arquivo. A descrição dos algorítmos desta classe são descritos no artigo "GUIA PRÁTICO MQL5: IMPLEMENTANDO UM ARRAY ASSOCIATIVO OU UM DICIONÁRIO PARA ACESSO RÁPIDO AO DADOS".
Todos os arquivos listados neste artigo tem que ser colocados no respectivo diretório interno <terminal_data_folder>\MQL5\Include. Para iniciar o trabalho com as classes você deve incluir o arquivo Zip\Zip.mqh no projeto Como exemplo, vamos descrever um script para a criação de um arquivo ZIP e escrever um arquivo de texto com uma mensagem de "teste":
//+------------------------------------------------------------------+ //| Zip.mq5 | //| Copyright 2015, Vasiliy Sokolov. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2015, Vasiliy Sokolov." #property link "https://www.mql5.com" #property version "1.00" #include <Zip\Zip.mqh> // Inclua todas as classes necessárias para uma operação com arquivo ZIP //+------------------------------------------------------------------+ //| Programa script para iniciar a função | //+------------------------------------------------------------------+ void OnStart() { CZip Zip; // Nós criamos um arquivo ZIP vazio uchar array[]; // Nós criamos um array de bytes vazio StringToCharArray("test", array); // Convertemos uma mensagem "teste" para um array de bytes CZipFile* file = new CZipFile("test.txt", array); // Criamos um novo arquivo ZIP de 'arquivo' com base no array chamado "test.txt" Zip.AddFile(file); // Nós adicionamos o arquivo ZIP de 'arquivo' criado para um arquivo ZIP Zip.SaveZipToFile("Test.zip", FILE_COMMON); // Salvamos o arquivo ZIP com o nome "Test.zip" no disco. } //+------------------------------------------------------------------+
Após sua execução no disco rígido do computador, um novo arquivo ZIP denominado Test.zip, contendo um arquivo de texto com a palavra "test", aparecera no diretório central de arquivos do MetaTrader 5.
| O arquivo anexado a este artigo foi criado por meio do arquivo CZip para MQL5 descrito aqui. |
|---|
Conclusão
Temos analisado exaustivamente a estrutura do arquivo ZIP e criado classes que implementam o trabalho com estes tipos de arquivos. Esse formato foi desenvolvido no final dos anos 80 do século passado, mas isso não impede que ele permaneça como um popular formato de compactação de dados. Uma configuração de dados dessas classes oferecem uma ajuda inestimável a um desenvolvedor de sistema de negociação. Assim, você pode armazenar eficientemente os dados coletados, um histórico de ticks, por exemplo, ou outras informações de negociação. Frequentemente vários dados analíticos também estão disponíveis na forma compactada. Neste caso, a habilidade de trabalhar com tais informações, mesmo numa forma compactada, também pode ser muito útil.
As classes descritas ocultam muitos aspectos técnicos no trabalho com arquivos, oferecendo métodos de operação simples e compreensíveis a nível de usuário, semelhantes aos que os usuários estão acostumados com programas de compactação: adicionar e extrair arquivos de arquivos compactados, criando novos e carregando os já existentes, incluindo aqueles postados nos servidores remotos de terceiros. Esses recursos têm resolvido completamente a maioria dos problemas relacionados a compactação e fazem ainda mais fácil e mais funcional a programação no MetaTrader.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/1971
 Gerenciamento de dinheiro revisitado
Gerenciamento de dinheiro revisitado
 Serviço Freelance no site MQL5.com - Encontre o Seu Desenvolvedor Favorito
Serviço Freelance no site MQL5.com - Encontre o Seu Desenvolvedor Favorito
 Testando Expert Advisors em períodos de tempo fora do padrão
Testando Expert Advisors em períodos de tempo fora do padrão
 Como Proteger Seu Expert Advisor Investindo na Bolsa de Moscou
Como Proteger Seu Expert Advisor Investindo na Bolsa de Moscou
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso