
Anotação de dados na análise de série temporal (Parte 4): Decomposição da interpretabilidade usando anotação de dados

Introdução
No artigo anterior, discutimos o modelo de NHits, no qual testamos a previsão dos preços de fechamento com apenas uma variável de entrada. Neste artigo, falaremos da interpretabilidade do modelo e da utilização de várias covariáveis para prever os preços de fechamento. Desta vez, para demonstração, usaremos outro modelo que oferece possibilidades ainda maiores – NBeats. O foco principal do artigo será a interpretabilidade do modelo. Veremos também para que serve a introdução do tema covariável. Ao final, você deve aprender a usar diferentes modelos para testar suas ideias a qualquer momento necessário. Claro que esses dois modelos são essencialmente modelos interpretáveis de qualidade. As ideias podem ser estendidas a outros modelos e testadas utilizando as bibliotecas mencionadas no artigo. Note que esta série de artigos está estritamente orientada a resolver a tarefa definida. Neste sentido, você deve avaliar cuidadosamente todos os riscos antes de aplicar quaisquer ideias, inclusive as mencionadas no artigo, diretamente na negociação levada à prática A implementação de ferramentas de negociação requer tanto de ajustes de parâmetros quanto de técnicas de otimização adicionais para garantir resultados confiáveis e estáveis.Referências aos três artigos anteriores:
- Anotação de dados na análise de série temporal (Parte 1): Criação de um conjunto de dados com rótulos de tendência usando um gráfico EA
- Anotação de dados na análise de série temporal (Parte 2): Criação de um conjunto de dados com rótulos de tendência usando um gráfico EA
- Anotação de dados na análise de série temporal (Parte 3): Exemplo de uso da anotação de dados
Conteúdo:
- Introdução
- Sobre o modelo NBeats
- Importação de bibliotecas
- Reescrevendo a classe TimeSeriesDataSet
- Processamento de dados
- Obtendo a taxa de aprendizado
- Definindo a função de treinamento
- Treinamento e teste do modelo
- Interpretação do modelo
- Considerações finais
Sobre o modelo NBeats
Este modelo foi amplamente discutido e explicado em várias revistas e sites. Para que você não tenha a necessidade de visitar diferentes sites e outras fontes de informação, fornecerei aqui uma introdução simples a este modelo. O modelo NBeats pode processar sequências de entrada e saída de qualquer comprimento e não depende do desenvolvimento de funções específicas ou do escalonamento de dados de entrada para séries temporais. O modelo também pode usar polinômios e séries de Fourier como funções base para configurações interpretáveis ao modelar tendências e decomposições sazonais. Além disso, o modelo usa uma topologia de dupla soma residual, de modo que cada bloco de construção tem duas ramificações residuais: uma para previsão reversa e outra para previsão direta, o que melhora significativamente a treinabilidade e a interpretabilidade do modelo. Parece impressionante!O artigo original foi publicado aqui: https://arxiv.org/pdf/1905.10437.pdf
1. Arquitetura do modelo
2. Processo de implementação do modelo
A série temporal de entrada é representada como um vetor de baixa dimensão, e a segunda parte converte o vetor de volta em uma série temporal. Este passo também se aplica ao AutoEncoder, onde ocorre o mapeamento da série temporal com um vetor de baixa dimensão para preservar a informação básica, e então ocorre sua recuperação. De forma simplificada, esse processo pode ser representado assim: 
O módulo gera dois conjuntos de coeficientes de expansão: um para a previsão do futuro (forecast), e outro para a previsão do passado (backcast). Este processo pode ser representado pela seguinte fórmula:

3. Interpretabilidade
A decomposição do modelo é interpretável. O modelo NBeats introduz alguns conhecimentos prévios em cada nível, o que permite que os níveis aprendam características específicas das séries temporais. Isso nos dá uma decomposição interpretável das séries temporais. O método de implementação consiste em restringir os coeficientes de expansão pela forma funcional da sequência de saída. Por exemplo, se é necessário que um determinado bloco de camadas preveja a sazonalidade da série temporal, pode-se usar a seguinte fórmula para que a camada de saída mostre exatamente os dados sazonais:


4. Covariáveis
Neste artigo, também veremos as covariáveis, que ajudarão a prever o valor alvo. Quais covariáveis temos:- static_categoricals — lista de variáveis categóricas que não mudam ao longo do tempo.
- static_reals — lista de variáveis contínuas que não mudam ao longo do tempo.
- time_varying_known_categoricals — lista de variáveis categóricas que mudam ao longo do tempo e são conhecidas no futuro, por exemplo, informações sobre feriados.
- time_varying_known_reals — lista de variáveis contínuas que mudam ao longo do tempo e são conhecidas no futuro, por exemplo, datas.
- time_varying_unknown_categoricals — lista de variáveis categóricas que mudam ao longo do tempo e são desconhecidas no futuro, por exemplo, tendência.
- time_varying_unknown_reals — lista de variáveis contínuas que mudam ao longo do tempo e são desconhecidas no futuro, por exemplo, crescimento ou radiação.
5. Variáveis externas
O modelo NBeats permite a introdução de variáveis externas, que aparentemente não estão relacionadas com a amostra, mas ainda assim alteram o modelo. A equipe de pesquisa chamou a expansão do modelo com variáveis exógenas de NBeatsx, mas não falaremos sobre ela em nosso artigo.Importação de bibliotecas
Explicações aqui são desnecessárias. Apenas importamos.
import lightning.pytorch as pl import os from lightning.pytorch.callbacks import EarlyStopping,ModelCheckpoint import matplotlib.pyplot as plt import numpy as np import pandas as pd from pytorch_forecasting import TimeSeriesDataSet,NBeats from pytorch_forecasting.data import NaNLabelEncoder from pytorch_forecasting.metrics import MQF2DistributionLoss from pytorch_forecasting.data.samplers import TimeSynchronizedBatchSampler from lightning.pytorch.tuner import Tuner import MetaTrader5 as mt import warnings import json
Reescrevendo a classe TimeSeriesDataSet
Aqui também não são necessárias explicações adicionais. Tudo já foi descrito anteriormente. Então, você pode ler sobre o que é feito e por que, nos artigos anteriores desta série.
class New_TmSrDt(TimeSeriesDataSet): ''' rewrite dataset class ''' def to_dataloader(self, train: bool = True, batch_size: int = 64, batch_sampler: Sampler | str = None, shuffle:bool=False, drop_last:bool=False, **kwargs) -> DataLoader: default_kwargs = dict( shuffle=shuffle, # drop_last=train and len(self) > batch_size, drop_last=drop_last, # collate_fn=self._collate_fn, batch_size=batch_size, batch_sampler=batch_sampler, ) default_kwargs.update(kwargs) kwargs = default_kwargs # print(kwargs['drop_last']) if kwargs["batch_sampler"] is not None: sampler = kwargs["batch_sampler"] if isinstance(sampler, str): if sampler == "synchronized": kwargs["batch_sampler"] = TimeSynchronizedBatchSampler( SequentialSampler(self), batch_size=kwargs["batch_size"], shuffle=kwargs["shuffle"], drop_last=kwargs["drop_last"], ) else: raise ValueError(f"batch_sampler {sampler} unknown - see docstring for valid batch_sampler") del kwargs["batch_size"] del kwargs["shuffle"] del kwargs["drop_last"] return DataLoader(self,**kwargs)
Processamento de dados
Não repetiremos aqui o carregamento e o pré-processamento de dados. As descrições completas já foram apresentadas nos três artigos anteriores, então recomendo lê-los. Neste mesmo artigo, abordaremos apenas as mudanças relevantes localmente.
1. Coleta de dados
def get_data(mt_data_len:int): if not mt.initialize(): print('initialize() failed!') else: print(mt.version()) sb=mt.symbols_total() rts=None if sb > 0: rts=mt.copy_rates_from_pos("GOLD_micro",mt.TIMEFRAME_M15,0,mt_data_len) mt.shutdown() # print(len(rts)) rts_fm=pd.DataFrame(rts) rts_fm['time']=pd.to_datetime(rts_fm['time'], unit='s') rts_fm['time_idx']= rts_fm.index%(max_encoder_length+2*max_prediction_length) rts_fm['series']=rts_fm.index//(max_encoder_length+2*max_prediction_length) return rts_fm
2. Pré-processamento
Diferentemente do que fizemos anteriormente, agora falaremos sobre covariáveis. Por que as usamos? Na verdade, existem outras variantes desse modelo: NBeatsx e GAGA. Se você estiver interessado nesses modelos ou em qualquer outro incluído na biblioteca de previsão pytorch que estamos usando, é importante entender as covariáveis. Vamos tentar entender isso, sem entrar em muitos detalhes.
No que diz respeito aos dados de forex, usamos como covariáveis os valores open, high e low. Claro que outros dados, como MACD, ADX, RSI e outros indicadores, também podem ser usados como covariáveis, mas lembre-se de que eles devem estar relacionados aos nossos dados. Não é possível adicionar variáveis externas irrelevantes, como as atas das reuniões do Federal Reserve, decisões sobre taxas de juros, dados não agrícolas etc., como covariáveis de entrada, pois o modelo não possui funções para analisar esses dados. Talvez um dia eu escreva um artigo dedicado a como adicionar variáveis externas ao modelo.
Agora, vamos ver como adicionar covariáveis na classe New_TmSrDt(). A classe fornece as seguintes definições de variáveis:
- static_categoricals (List[str])
- static_reals (List[str])
- timevaryingknown_categoricals (List[str])
- timevaryingknown_reals (List[str])
- timevaryingunknown_categoricals (List[str])
- timevaryingunknown_reals (List[str])
- timevaryingknown_categoricals
- timevaryingknown_reals
- timevaryingunknown_categoricals
- timevaryingunknown_reals
Como as variáveis open, high e low não são categorias, as opções restantes são apenas time_varying_known_reals e time_varying_unknown_reals. Alguém poderia dizer que, se precisamos prever os valores de close, e os valores de open, high e low de cada barra podem ser obtidos em tempo real, por que não podemos adicioná-los em time_varying_known_reals? Vamos olhar de perto: se estamos prevendo o valor de apenas uma barra, isso já é conhecido, então eles podem ser completamente classificados como time_varying_known_reals. Mas e se quisermos prever os valores de várias barras? Só podemos saber os dados da barra atual, e os valores seguintes são completamente desconhecidos, por isso eles não se enquadra no contexto discutido em nosso artigo. Na verdade, eles precisam ser adicionados à categoria time_varying_unknown_reals. Mas se você está prevendo o valor de close de apenas uma barra, definitivamente pode adicioná-lo em time_varying_known_reals, então é importante considerar cuidadosamente o caso de uso específico. Há também um caso especial para time_varying_known_reals. Na verdade, cada uma de nossas barras tem um ciclo fixo, como M15, H1, H4, D1, etc. Com isso, podemos calcular completamente o tempo ao qual as barras previstas pertencem. Daí que você certamente pode adicionar o tempo como time_varying_known_reals. Não vamos nos aprofundar nisso agora, mas se você estiver interessado, poderá adicionar por conta própria. Se você quiser usar covariáveis, pode mudar time_varying_unknown_reals=["close"] para time_varying_unknown_reals=["close", "high", "open", "low"]. Nossa versão do NBeats não suporta essa função!
Assim, temos o seguinte código:
def spilt_data(data:pd.DataFrame, t_drop_last:bool, t_shuffle:bool, v_drop_last:bool, v_shuffle:bool): training_cutoff = data["time_idx"].max() - max_prediction_length #max:95 context_length = max_encoder_length prediction_length = max_prediction_length training = New_TmSrDt( data[lambda x: x.time_idx <= training_cutoff], time_idx="time_idx", target="close", categorical_encoders={"series":NaNLabelEncoder().fit(data.series)}, group_ids=["series"], time_varying_unknown_reals=["close"], max_encoder_length=context_length, max_prediction_length=prediction_length, ) validation = New_TmSrDt.from_dataset(training, data, min_prediction_idx=training_cutoff + 1) train_dataloader = training.to_dataloader(train=True, shuffle=t_shuffle, drop_last=t_drop_last, batch_size=batch_size, num_workers=0,) val_dataloader = validation.to_dataloader(train=False, shuffle=v_shuffle, drop_last=v_drop_last, batch_size=batch_size, num_workers=0) return train_dataloader,val_dataloader,training
Obtendo a taxa de aprendizado
Explicações aqui são desnecessárias. Tudo já foi descrito anteriormente. Então, você pode ler sobre o que é feito e por que, nos artigos anteriores desta série.
def get_learning_rate(): pl.seed_everything(42) trainer = pl.Trainer(accelerator="cpu", gradient_clip_val=0.1,logger=False) net = NBeats.from_dataset( training, learning_rate=3e-2, weight_decay=1e-2, backcast_loss_ratio=0.0, optimizer="AdamW", ) res = Tuner(trainer).lr_find( net, train_dataloaders=t_loader, val_dataloaders=v_loader, min_lr=1e-5, max_lr=1e-1 ) # print(f"suggested learning rate: {res.suggestion()}") lr_=res.suggestion() return lr_
Nota. Há algumas diferenças entre essa função e o Nbits: a função NBeats.from_dataset() não possui parâmetros hidden_size. E o parâmetro de perda não pode usar o método MQF2DistributionLoss().
Definindo a função de treinamento
Explicações aqui são desnecessárias. Tudo já foi descrito anteriormente. Então, você pode ler sobre o que é feito e por que, nos artigos anteriores desta série.
def train():
early_stop_callback = EarlyStopping(monitor="val_loss",
min_delta=1e-4,
patience=10,
verbose=True,
mode="min")
ck_callback=ModelCheckpoint(monitor='val_loss',
mode="min",
save_top_k=1,
filename='{epoch}-{val_loss:.2f}')
trainer = pl.Trainer(
max_epochs=ep,
accelerator="cpu",
enable_model_summary=True,
gradient_clip_val=1.0,
callbacks=[early_stop_callback,ck_callback],
limit_train_batches=30,
enable_checkpointing=True,
)
net = NBeats.from_dataset(
training,
learning_rate=lr,
log_interval=10,
log_val_interval=1,
weight_decay=1e-2,
backcast_loss_ratio=0.0,
optimizer="AdamW",
stack_types = ["trend", "seasonality"],
)
trainer.fit(
net,
train_dataloaders=t_loader,
val_dataloaders=v_loader,
# ckpt_path='best'
)
return trainer
Nota. Aqui para NBeats.from_dataset() é necessário adicionar a variável interpretável do tipo de decomposição stack_types. Usamos o valor padrão. Além desses dois valores padrão, existe também a opção "geral".
Treinamento e teste do modelo
A seguir, implementamos a lógica de treinamento e previsão do modelo, que foi explicada no artigo anterior. Não há mudanças aqui, então eu não vou me aprofundar nisso.
if __name__=='__main__': ep=200 __train=False mt_data_len=200000 max_encoder_length = 2*96 max_prediction_length = 30 batch_size = 128 info_file='results.json' warnings.filterwarnings("ignore") dt=get_data(mt_data_len=mt_data_len) if __train: # print(dt) # dt=get_data(mt_data_len=mt_data_len) t_loader,v_loader,training=spilt_data(dt, t_shuffle=False,t_drop_last=True, v_shuffle=False,v_drop_last=True) lr=get_learning_rate() trainer__=train() m_c_back=trainer__.checkpoint_callback m_l_back=trainer__.early_stopping_callback best_m_p=m_c_back.best_model_path best_m_l=m_l_back.best_score.item() # print(best_m_p) if os.path.exists(info_file): with open(info_file,'r+') as f1: last=json.load(fp=f1) last_best_model=last['last_best_model'] last_best_score=last['last_best_score'] if last_best_score > best_m_l: last['last_best_model']=best_m_p last['last_best_score']=best_m_l json.dump(last,fp=f1) else: with open(info_file,'w') as f2: json.dump(dict(last_best_model=best_m_p,last_best_score=best_m_l),fp=f2) best_model = NHiTS.load_from_checkpoint(best_m_p) predictions = best_model.predict(v_loader, trainer_kwargs=dict(accelerator="cpu",logger=False), return_y=True) raw_predictions = best_model.predict(v_loader, mode="raw", return_x=True, trainer_kwargs=dict(accelerator="cpu",logger=False)) for idx in range(10): # plot 10 examples best_model.plot_prediction(raw_predictions.x, raw_predictions.output, idx=idx, add_loss_to_title=True) plt.show() else: with open(info_file) as f: best_m_p=json.load(fp=f)['last_best_model'] print('model path is:',best_m_p) best_model = NHiTS.load_from_checkpoint(best_m_p) offset=1 dt=dt.iloc[-max_encoder_length-offset:-offset,:] last_=dt.iloc[-1] # print(len(dt)) for i in range(1,max_prediction_length+1): dt.loc[dt.index[-1]+1]=last_ dt['series']=0 # dt['time_idx']=dt.apply(lambda x:x.index,args=1) dt['time_idx']=dt.index-dt.index[0] # dt=get_data(mt_data_len=max_encoder_length) predictions = best_model.predict(dt, mode='raw',trainer_kwargs=dict(accelerator="cpu",logger=False),return_x=True) best_model.plot_prediction(predictions.x,predictions.output,show_future_observed=False) plt.show()
Nota. Antes de iniciar, certifique-se de que o TensorBoard está instalado! Isso é importante, caso contrário, ocorrerão erros incompreensíveis.
Resultado do treinamento (ao executar o código, aparecerão 10 imagens, como exemplo é dado um aleatório):

Resultados do teste:

Interpretação do modelo
Existem muitas maneiras de interpretar dados, mas o modelo NBeats é único por decompor as previsões em sazonalidade e tendências (claro, já que esses dois fatores foram escolhidos para este artigo, os resultados podem ser divididos apenas nessas duas categorias, mas podem existir muitas outras combinações).
Se você terminou o treinamento e quer decompor a previsão, você precisa adicionar o seguinte código:
for idx in range(10): # plot 10 examples best_model.plot_interpretation(x, raw_predictions, idx=idx)
Se você quiser decompor a previsão ao executar a previsão, você pode adicionar o seguinte código:
best_model.plot_interpretation(predictions.x,predictions.output,idx=0) O resultado será este:
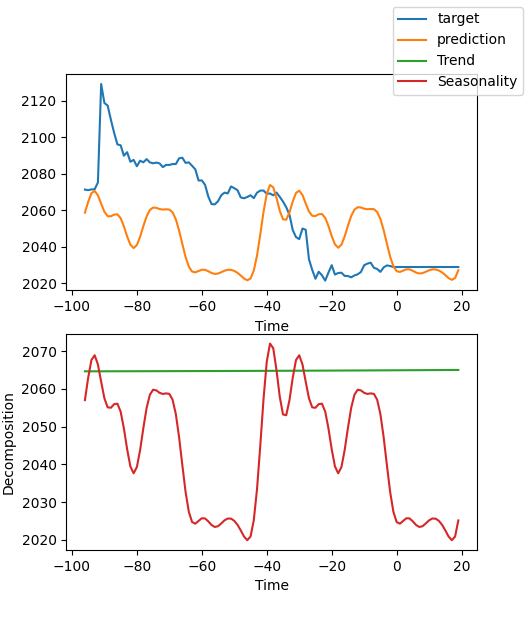
Nesta imagem, os resultados não são muito bons. Mas isso é apenas um exemplo aproximado, eu não otimizei nossa modelo cuidadosamente, e os indicadores-chave dos dados ainda não foram definidos cientificamente. Além disso, a maioria dos parâmetros do modelo é usada apenas como padrão e não é configurada, portanto, há muitas oportunidades para otimização.
Considerações finais
Neste artigo, exploramos como utilizar dados anotados para prever preços futuros utilizando o modelo NBeats. O texto também destaca a função especial de decomposição interpretativa do modelo NBeats. Apesar das mudanças no código não serem drásticas, é importante prestar atenção na discussão sobre covariáveis. Se você entendeu bem o uso de diferentes covariáveis, pode adaptar este modelo a outros cenários de uso. Creio que isso vai melhorar a precisão do Expert Advisor e permitir a execução das tarefas com maior exatidão. Este artigo é um mero exemplo; os dados apresentados estão em formato bruto e, como tal, não são adequados para serem diretamente utilizados na negociação real. Existem muitos pontos no código que necessitam de otimização adicional, portanto, evite usar diretamente no trading! Variáveis externas também são discutidas aqui. Caso haja interesse suficiente, posso considerar detalhar a implementação delas em futuros artigos desta série.
Com isso, concluímos o artigo, esperando que seja de utilidade.
O código completo:
# Copyright 2021, MetaQuotes Ltd. # https://www.mql5.com import lightning.pytorch as pl import os from lightning.pytorch.callbacks import EarlyStopping,ModelCheckpoint import matplotlib.pyplot as plt import pandas as pd from pytorch_forecasting import TimeSeriesDataSet,NBeats from pytorch_forecasting.data import NaNLabelEncoder from pytorch_forecasting.data.samplers import TimeSynchronizedBatchSampler from lightning.pytorch.tuner import Tuner import MetaTrader5 as mt import warnings import json from torch.utils.data import DataLoader from torch.utils.data.sampler import Sampler,SequentialSampler class New_TmSrDt(TimeSeriesDataSet): ''' rewrite dataset class ''' def to_dataloader(self, train: bool = True, batch_size: int = 64, batch_sampler: Sampler | str = None, shuffle:bool=False, drop_last:bool=False, **kwargs) -> DataLoader: default_kwargs = dict( shuffle=shuffle, # drop_last=train and len(self) > batch_size, drop_last=drop_last, # collate_fn=self._collate_fn, batch_size=batch_size, batch_sampler=batch_sampler, ) default_kwargs.update(kwargs) kwargs = default_kwargs # print(kwargs['drop_last']) if kwargs["batch_sampler"] is not None: sampler = kwargs["batch_sampler"] if isinstance(sampler, str): if sampler == "synchronized": kwargs["batch_sampler"] = TimeSynchronizedBatchSampler( SequentialSampler(self), batch_size=kwargs["batch_size"], shuffle=kwargs["shuffle"], drop_last=kwargs["drop_last"], ) else: raise ValueError(f"batch_sampler {sampler} unknown - see docstring for valid batch_sampler") del kwargs["batch_size"] del kwargs["shuffle"] del kwargs["drop_last"] return DataLoader(self,**kwargs) def get_data(mt_data_len:int): if not mt.initialize(): print('initialize() failed!') else: print(mt.version()) sb=mt.symbols_total() rts=None if sb > 0: rts=mt.copy_rates_from_pos("GOLD_micro",mt.TIMEFRAME_M15,0,mt_data_len) mt.shutdown() # print(len(rts)) rts_fm=pd.DataFrame(rts) rts_fm['time']=pd.to_datetime(rts_fm['time'], unit='s') rts_fm['time_idx']= rts_fm.index%(max_encoder_length+2*max_prediction_length) rts_fm['series']=rts_fm.index//(max_encoder_length+2*max_prediction_length) return rts_fm def spilt_data(data:pd.DataFrame, t_drop_last:bool, t_shuffle:bool, v_drop_last:bool, v_shuffle:bool): training_cutoff = data["time_idx"].max() - max_prediction_length #max:95 context_length = max_encoder_length prediction_length = max_prediction_length training = New_TmSrDt( data[lambda x: x.time_idx <= training_cutoff], time_idx="time_idx", target="close", categorical_encoders={"series":NaNLabelEncoder().fit(data.series)}, group_ids=["series"], time_varying_unknown_reals=["close"], max_encoder_length=context_length, # min_encoder_length=max_encoder_length//2, max_prediction_length=prediction_length, # min_prediction_length=1, ) validation = New_TmSrDt.from_dataset(training, data, min_prediction_idx=training_cutoff + 1) train_dataloader = training.to_dataloader(train=True, shuffle=t_shuffle, drop_last=t_drop_last, batch_size=batch_size, num_workers=0,) val_dataloader = validation.to_dataloader(train=False, shuffle=v_shuffle, drop_last=v_drop_last, batch_size=batch_size, num_workers=0) return train_dataloader,val_dataloader,training def get_learning_rate(): pl.seed_everything(42) trainer = pl.Trainer(accelerator="cpu", gradient_clip_val=0.1,logger=False) net = NBeats.from_dataset( training, learning_rate=3e-2, weight_decay=1e-2, backcast_loss_ratio=0.1, optimizer="AdamW", ) res = Tuner(trainer).lr_find( net, train_dataloaders=t_loader, val_dataloaders=v_loader, min_lr=1e-5, max_lr=1e-1 ) # print(f"suggested learning rate: {res.suggestion()}") lr_=res.suggestion() return lr_ def train(): early_stop_callback = EarlyStopping(monitor="val_loss", min_delta=1e-4, patience=10, verbose=True, mode="min") ck_callback=ModelCheckpoint(monitor='val_loss', mode="min", save_top_k=1, filename='{epoch}-{val_loss:.2f}') trainer = pl.Trainer( max_epochs=ep, accelerator="cpu", enable_model_summary=True, gradient_clip_val=1.0, callbacks=[early_stop_callback,ck_callback], limit_train_batches=30, enable_checkpointing=True, ) net = NBeats.from_dataset( training, learning_rate=lr, log_interval=10, log_val_interval=1, weight_decay=1e-2, backcast_loss_ratio=0.0, optimizer="AdamW", stack_types=["trend", "seasonality"], ) trainer.fit( net, train_dataloaders=t_loader, val_dataloaders=v_loader, # ckpt_path='best' ) return trainer if __name__=='__main__': ep=200 __train=False mt_data_len=80000 max_encoder_length = 96 max_prediction_length = 20 # context_length = max_encoder_length # prediction_length = max_prediction_length batch_size = 128 info_file='results.json' warnings.filterwarnings("ignore") dt=get_data(mt_data_len=mt_data_len) if __train: # print(dt) # dt=get_data(mt_data_len=mt_data_len) t_loader,v_loader,training=spilt_data(dt, t_shuffle=False,t_drop_last=True, v_shuffle=False,v_drop_last=True) lr=get_learning_rate() # lr=3e-3 trainer__=train() m_c_back=trainer__.checkpoint_callback m_l_back=trainer__.early_stopping_callback best_m_p=m_c_back.best_model_path best_m_l=m_l_back.best_score.item() # print(best_m_p) if os.path.exists(info_file): with open(info_file,'r+') as f1: last=json.load(fp=f1) last_best_model=last['last_best_model'] last_best_score=last['last_best_score'] if last_best_score > best_m_l: last['last_best_model']=best_m_p last['last_best_score']=best_m_l json.dump(last,fp=f1) else: with open(info_file,'w') as f2: json.dump(dict(last_best_model=best_m_p,last_best_score=best_m_l),fp=f2) best_model = NBeats.load_from_checkpoint(best_m_p) predictions = best_model.predict(v_loader, trainer_kwargs=dict(accelerator="cpu",logger=False), return_y=True) raw_predictions = best_model.predict(v_loader, mode="raw", return_x=True, trainer_kwargs=dict(accelerator="cpu",logger=False)) for idx in range(10): # plot 10 examples best_model.plot_prediction(raw_predictions.x, raw_predictions.output, idx=idx, add_loss_to_title=True) plt.show() else: with open(info_file) as f: best_m_p=json.load(fp=f)['last_best_model'] print('model path is:',best_m_p) best_model = NBeats.load_from_checkpoint(best_m_p) offset=1 dt=dt.iloc[-max_encoder_length-offset:-offset,:] last_=dt.iloc[-1] # print(len(dt)) for i in range(1,max_prediction_length+1): dt.loc[dt.index[-1]+1]=last_ dt['series']=0 # dt['time_idx']=dt.apply(lambda x:x.index,args=1) dt['time_idx']=dt.index-dt.index[0] # dt=get_data(mt_data_len=max_encoder_length) predictions = best_model.predict(dt, mode='raw',trainer_kwargs=dict(accelerator="cpu",logger=False),return_x=True) # best_model.plot_prediction(predictions.x,predictions.output,show_future_observed=False) best_model.plot_interpretation(predictions.x,predictions.output,idx=0) plt.show()
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/13218
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso