TP = SL에서는 약 50%가 됩니다. TP = 2 * SL에서는 33 % 등이됩니다. 항상 1 거래의 평균 수익은 매우 작습니다. 약 0,00005. 그러나 그것은 교사의 마크 업에서 고려되지 않은 스프레드, 슬리피지, 스왑에 소비됩니다 (스프레드는 고려되지만 바당 최소값은 실제가 더 높습니다). 그리고 이것을 사용하여 TP = SL = 0,00400. 즉, 400의 위험으로 우리는 5 포인트의 이익, 즉 1 %의 이점을 얻습니다. 50 포인트의 움직임에서 최소 10 포인트를 가져오고 싶지만 모든 옵션은 매실입니다.
그러나 이것은 모두 내 칩과 목표입니다. 아마도 더 나은 옵션이있을 것입니다.
이 전략은 2008년부터 2023년까지 EURUSD에서 수익성 거래의 43%, TP/SL 비율 61.8, 수익성 거래의 39%만 손익분기점에 도달하면 충분합니다. 아직 수치를 확인하지 않았고 어딘가 틀렸을 수 있으며 물론 이상적인 조건입니다. 그러나 여기에는 학습 관점이 있으므로 MO를 희생하여 더 높은 비율을 끌어낼 수 있습니다.
예측 변수와 관련하여 제 글에서 예측 변수를 가져온 건가요? 제가 가지고 있는 모델에서 종종 발견됩니다 .
추가 : 예, 수익성있는 거래가 있지만 TP로 마감되지 않은 거래가 있다는 점을 고려하지 않았으며 당연히 수익이 적을 것입니다.
이 전략은 2008년부터 2023년까지 EURUSD에서 수익성 거래의 43%, 이상적인 조건에서 TP/SL 비율 61.8, 수익성 거래의 39%만 손익분기점에 도달하면 됩니다. 아직 수치를 확인하지 않았고 어딘가 틀렸을 수 있으며 물론 이상적인 조건입니다. 그러나 여기에는 학습 관점이 있으므로 MO를 희생하여 더 높은 비율을 끌어낼 수 있습니다.
예측 변수와 관련하여 제 글에서 예측 변수를 가져온 건가요? 제가 가지고 있는 모델에서도 종종 발견됩니다 .
당신의 전략이 무엇인지 잘 모르겠습니다. 하루에 한 번 진입하라는 신호를받는 것 같습니다. 결과의 통계적 유의성에 대해 이야기하는 것은 거의 없다고 생각합니다. 귀하의 데이터 세트에 대해 5000 개 이상의 예측자를 훈련했습니다. 그들은 동일한 5 포인트 이상을 제공하지 않으므로 5 포인트를 제공하는 단순한 가격 델타와 지그재그보다 낫지 않다고 생각합니다. 지금은 다른 아이디어를 확인하겠습니다. 그들이 아무것도 제공하지 않으면 내 모델을 생성하기 위해 예측자를 시도해 볼 것입니다.
2008년부터의 데이터를 가져왔습니다. 예, 데이터가 많지는 않지만 23.6 수준이 무작위가 아니고 그 교차가 시장에 중요하다고 생각하면 각 막대에서 항목을 생성 할 때 상황과 달리 서로 비교할 수있는 유사한 이벤트와 같아서 학습을 복잡하게 만드는 유사한 이벤트가 많기 때문에 어떻게 보느냐에 따라 다릅니다.
따라서 이런 방식으로 트레이닝하는 것이 합리적이라고 생각하지만 시장 참여자의 결정에 영향을 미치는 이벤트는 전략마다 달라야 합니다. 그리고 더 많은 거래 모델 세트가 필요합니다.
데이터 세트에 대해 5000개 이상의 예측자를 훈련시켰습니다. 그들은 동일한 5 포인트 이상을 제공하지 않으므로 5 포인트를 제공하는 단순한 가격 델타와 지그재그보다 낫지 않다고 생각합니다. 지금은 다른 아이디어를 확인하겠습니다. 그들이 아무것도 제공하지 않으면 내 모델을 생성하기 위해 예측자를 시도해 볼 것입니다.
첫 번째 샘플을 말하는 건가요, 아니면 두 번째 샘플을 말하는 건가요? 첫 번째 샘플이라면 좋은 변종에 대해 약 30 점의 기대 행렬을 가지고있었습니다.
이제 목표가 어느 정도 명확해졌습니다. 결과를 점수로 예상하시나요, 아니면 승패로만 예상하시나요? 후자인 것 같습니다. 포인트로 추정하는 것이 더 낫습니다.
75% 모델은 실제로 50/50으로 작동하지 않으니까요.
나는 돈으로 평가합니다 :) 예전처럼 목표도 추가합니다. 더 많은 포인트를 원하면 나중에 목표를 이동할 수 있습니다.
구체적인 전략에서는 이제 모든 것이 이익 실현입니다. 나는 계산을 많이했는데 실제로 스프레드가 비율을 크게 악화시키는 것으로 밝혀졌지만 괜찮지 만 매우 수익성이 높은 항목의 배출없이 안정성이있을 것입니다. 위험은 모든 곳에서 거의 동일합니다. 그런 다음 일시 중지를 사용하면 결과를 개선 할 수 있습니다.
이 문제를 해결할 수 있는 한 가지 방법이 있지만 샘플 파일에는 예측자가 없어야 합니다. 즉, 5000개 이상의 예측자가 필요하지 않고 모션 그래프 자체만 있으면 됩니다. OHLC로 구성되어 있는지 또는 하나의 변수가 있는지는 중요하지 않습니다. 하지만 샘플의 한 변수, 즉 5584 열에 대해 기존 방법을 시도해 보았는데, D(i)=D(i-1)+ Target_100_Buy 공식을 사용하여 차트로 변환했습니다. 세 파일 모두에 대해 다음과 같은 그래프를 얻었습니다:
1) 훈련:
2)test:
3)시험:
내가 올바르게했는지 여부는 모르겠지만 topikstarter가 예측 변수없이 새 샘플을 만들면 새 데이터에 대해 방법을 테스트하고 접근 방식에 대해 알려 드리겠습니다.
글쎄, 그리고 신경망위원회를 훈련 한 후 각 샘플의 실제 이익 (총 10 개가 있음). 이익은 스프레드=0, 커미션=0으로 포인트 수로 표시됩니다:
이 문제를 해결할 수 있는 한 가지 방법이 있지만 샘플 파일에는 예측자가 없어야 합니다. 즉, 5000개 이상의 예측자가 필요하지 않고 모션 그래프 자체만 있으면 됩니다. OHLC로 구성되어 있는지 또는 하나의 변수가 있는지는 중요하지 않습니다. 그러나 샘플의 한 변수, 즉 5584 열에 대해 기존 방법을 시도해 보았는데, 이 열은 D(i)=D(i-1)+ Target_100_Buy 공식을 사용하여 차트로 변환했습니다. 세 파일 모두에 대한 그래프는 다음과 같습니다:
순수한 가격으로 접근하면 왜 새로운 샘플이 필요한지 이해할 수 없습니다.
아래 목록의 열은 발생한 이벤트의 결과입니다. 즉, 교육에 참여해서는 안됩니다. 최대 5582 - 그러나 거기에서 예측하기 쉽다고 생각하므로 모델에 의해 그대로 복구 될 것입니다.
아래 목록의 열은 발생한 이벤트의 결과, 즉 훈련에 참여해서는 안됩니다. 최대 5582 - 그러나 예측하기 쉽다고 생각하므로 모델에 의해 복구 될 것입니다.
5581 보조
5582 보조
5583 라벨
5584 보조
5585 보조
"내가 뭘 했지?":
샘플 열차의 크기는 약 1GB입니다. 작업 공간에 로드하는 데 시간이 꽤 오래 걸립니다. 저는 24GB RAM과 빠른 SSD가 장착된 i5-3570을 사용하고 있는데 Excel에서 이 파일을 여는 데 몇 분이 걸립니다. 그래서 저는 이 시간을 줄여야겠다고 결심했습니다. 저는 너무 게을러서 5000개 이상의 열에 대한 위첨자를 알아내지 못했습니다. 5584 5586 열을 가져 와서 모든 행에 신호를 적용했습니다 (솔직히 어느 것인지 기억이 나지 않습니다. 아마도 SELL 일 것입니다). 따라서이 열은 위의 공식에 따라 차트를 형성했습니다. 즉, 첫 번째 단계는 0, 0.00007, 0.00007-0.00002=0.00005, 0.00005+0.00007=0.00012 등이었습니다. 즉, 5584 5586 열에서 바인딩이 없는 모션 차트, 즉 상대 모션 차트를 형성했습니다. 종가 차트인 것처럼, 즉 차트의 각 단계가 끝날 때마다 자산 가격이 해당 값만큼 변경됩니다.
추신 열 번호에 대해 속임수를 썼습니다 ... 가장 최근의 5586 (Excel에서 방금 조회했습니다)을 SELL 신호로 가져 왔습니다.
"... 왜 새로운 샘플":
예제에 대한 접근 방식에 대해 일정량을 보여주고 말하기 위해. OHLC를 사용할 수 있는 열의 수를 지정하거나 절 가격만 지정하면 충분합니다.
나머지에 대해:
샘플 파일의 데이터는 전혀 사용되지 않습니다. 각 파일의 5584 5586 열을 기준으로 위에서 설명한 대로 그래프가 만들어집니다. 그리고이 접근 방식은 이미 이러한 획득 된 그래프에 적용됩니다.
글쎄, 토픽 스타터는 새로운 샘플을 제공하고 싶지 않기 때문에 관심있는 사람은 누구나 자신의 샘플을 게시 할 것을 제안합니다 ... :)
이 문제를 해결할 수 있는 한 가지 방법이 있지만 샘플 파일에는 예측자가 없어야 합니다. 즉, 5000개 이상의 예측자가 필요하지 않고 모션 그래프 자체만 있으면 됩니다. OHLC로 구성되어 있는지 또는 하나의 변수가 있는지는 중요하지 않습니다. 그러나 샘플의 한 변수, 즉 열 5584에 대해 기존 방법을 시도해 보았는데, 이 변수는 D(i)=D(i-1)+ Target_100_Buy 공식을 사용하여 차트로 변환했습니다. 세 파일 모두에 대한 그래프는 다음과 같습니다:
목표 함수의 반복성이 훈련되었나요? 예를 들어 20번 성공했다면 21번도 성공할까요? 예측 변수로 입력한 값은 몇 개입니까? 다음은 약 5년 동안 TP/SL=50포인트
M5로 매수 및 매도하는 가장 간단한 목표입니다.
마크업은 각 M5 막대에 있으며, 즉 마지막 신호(5분 전)의 거래가 아직 끝나지 않았을 가능성이 높습니다. 스택을 쌓는 것이 올바른지 잘 모르겠습니다. 스택은 한 순간에 1 개의 거래 만있는 목표에 대해서는 괜찮을 것입니다. 동시에 100 개라도 하룻밤 사이에 완료되지 않을 수 있습니다.
TP = SL에서는 약 50%가 됩니다. TP = 2 * SL에서는 33 % 등이됩니다.
항상 1 거래의 평균 수익은 매우 작습니다. 약 0,00005. 그러나 그것은 교사의 마크 업에서 고려되지 않은 스프레드, 슬리피지, 스왑에 소비됩니다 (스프레드는 고려되지만 바당 최소값은 실제가 더 높습니다).
그리고 이것을 사용하여 TP = SL = 0,00400. 즉, 400의 위험으로 우리는 5 포인트의 이익, 즉 1 %의 이점을 얻습니다.
50 포인트의 움직임에서 최소 10 포인트를 가져오고 싶지만 모든 옵션은 매실입니다.
그러나 이것은 모두 내 칩과 목표입니다. 아마도 더 나은 옵션이있을 것입니다.
이 전략은 2008년부터 2023년까지 EURUSD에서 수익성 거래의 43%, TP/SL 비율 61.8, 수익성 거래의 39%만 손익분기점에 도달하면 충분합니다. 아직 수치를 확인하지 않았고 어딘가 틀렸을 수 있으며 물론 이상적인 조건입니다. 그러나 여기에는 학습 관점이 있으므로 MO를 희생하여 더 높은 비율을 끌어낼 수 있습니다.
예측 변수와 관련하여 제 글에서 예측 변수를 가져온 건가요? 제가 가지고 있는 모델에서 종종 발견됩니다 .
추가 : 예, 수익성있는 거래가 있지만 TP로 마감되지 않은 거래가 있다는 점을 고려하지 않았으며 당연히 수익이 적을 것입니다.이 전략은 2008년부터 2023년까지 EURUSD에서 수익성 거래의 43%, 이상적인 조건에서 TP/SL 비율 61.8, 수익성 거래의 39%만 손익분기점에 도달하면 됩니다. 아직 수치를 확인하지 않았고 어딘가 틀렸을 수 있으며 물론 이상적인 조건입니다. 그러나 여기에는 학습 관점이 있으므로 MO를 희생하여 더 높은 비율을 끌어낼 수 있습니다.
예측 변수와 관련하여 제 글에서 예측 변수를 가져온 건가요? 제가 가지고 있는 모델에서도 종종 발견됩니다 .
당신의 전략이 무엇인지 잘 모르겠습니다. 하루에 한 번 진입하라는 신호를받는 것 같습니다. 결과의 통계적 유의성에 대해 이야기하는 것은 거의 없다고 생각합니다.
귀하의 데이터 세트에 대해 5000 개 이상의 예측자를 훈련했습니다. 그들은 동일한 5 포인트 이상을 제공하지 않으므로 5 포인트를 제공하는 단순한 가격 델타와 지그재그보다 낫지 않다고 생각합니다.
지금은 다른 아이디어를 확인하겠습니다. 그들이 아무것도 제공하지 않으면 내 모델을 생성하기 위해 예측자를 시도해 볼 것입니다.
전략이 무엇인지 잘 모르겠습니다. 하루에 한 번 들어가라는 신호처럼 보입니다.
전략은 다음과 같습니다:
하루가 시작될 때 예상되는 가격 변동 한도 범위를 계산합니다. 이를 위해 마지막 날 말에 ATR (3)을 사용할 수 있으며 약간 다른 공식을 사용합니다. 이 범위는 당일 개장(막대) 시작부터 연기하여 100%로 간주합니다.
시초가 위/아래의 유의미한 수준에 도달하면 (관찰에 따라 다른 상품에서 종종 그런 것으로 판명되므로 23.6에서 중지했습니다) 다음 유의미한 수준 (61.8 사용)에 TP로 포지션을 열고 당일 시가에 SL을 설정합니다.
테이크프로핏으로 청산했다면 신호가 나타나면 다시 진입합니다.
테이크 아웃이 작동하지 않으면 하루가 끝날 때 (23:45) 마감하는 것이 좋지만 실제로는 TP / SL을 기다리고 있습니다.
이제 초기 마크 업은 다음과 같이 작동합니다. 수익으로 마감하면 1을, 손실로 마감하면 -1을 넣습니다.
샘플을 분할 할 때 목표 오프셋을 300 핍으로 만들었으므로 이익이 300 핍 미만이면 0이됩니다.
결과의 통계적 유의성에 대해 이야기하기에는 매우 적다고 생각합니다.
2008년부터의 데이터를 가져왔습니다. 예, 데이터가 많지는 않지만 23.6 수준이 무작위가 아니고 그 교차가 시장에 중요하다고 생각하면 각 막대에서 항목을 생성 할 때 상황과 달리 서로 비교할 수있는 유사한 이벤트와 같아서 학습을 복잡하게 만드는 유사한 이벤트가 많기 때문에 어떻게 보느냐에 따라 다릅니다.
따라서 이런 방식으로 트레이닝하는 것이 합리적이라고 생각하지만 시장 참여자의 결정에 영향을 미치는 이벤트는 전략마다 달라야 합니다. 그리고 더 많은 거래 모델 세트가 필요합니다.
데이터 세트에 대해 5000개 이상의 예측자를 훈련시켰습니다. 그들은 동일한 5 포인트 이상을 제공하지 않으므로 5 포인트를 제공하는 단순한 가격 델타와 지그재그보다 낫지 않다고 생각합니다.
지금은 다른 아이디어를 확인하겠습니다. 그들이 아무것도 제공하지 않으면 내 모델을 생성하기 위해 예측자를 시도해 볼 것입니다.
첫 번째 샘플을 말하는 건가요, 아니면 두 번째 샘플을 말하는 건가요? 첫 번째 샘플이라면 좋은 변종에 대해 약 30 점의 기대 행렬을 가지고있었습니다.
물론 샘플을 업로드해 주시면 CatBoost로 훈련해 볼 수 있습니다.
전략은 다음과 같습니다:
하루가 시작될 때 예상되는 가격 변동 한도 범위를 계산합니다. 이를 위해 마지막 날 말에 ATR(3)을 사용할 수 있으며 약간 다른 공식을 사용합니다. 이 범위를 당일 개장(막대) 시작부터 연기하여 100%로 간주합니다.
시초가 위/아래의 유의미한 수준에 도달하면 (관찰에 따라 다른 상품에서 종종 그런 것으로 판명되므로 23.6에서 중지) 다음 유의미한 수준 (61.8 사용)에 TP로 포지션을 개설하고 당일 시가에 SL을 설정합니다.
테이크프로핏으로 청산했다면 신호가 나타나면 다시 진입합니다.
테이크 아웃이 작동하지 않으면 하루가 끝날 때 (23:45) 마감하는 것이 좋지만 실제로는 지금 TP / SL을 기다리고 있습니다.
이제 초기 마크업은 다음과 같이 작동합니다. 수익으로 마감하면 1을, 손실로 마감하면 -1을 넣습니다.
샘플을 분할 할 때 목표 오프셋을 300 핍으로 만들었으므로 이익이 300 핍 미만이면 0이됩니다.
2008년부터 데이터를 가져왔습니다. 예, 데이터가 많지는 않지만 23.6 수준이 우연이 아니고 그 교차가 시장에 중요하다고 생각하면 서로 비교할 수있는 유사한 이벤트이기 때문에 어떻게 보느냐에 따라 다릅니다.
이제 목표가 어느 정도 명확해졌습니다.
결과를 핍으로 추정합니까, 아니면 승패로만 추정합니까? 후자인 것 같습니다. 핍으로 추정하는 것이 더 좋습니다.
75%를 제공하는 모델이 실제로는 50/50으로 작동하지 않습니다.
모든 막대에서 입력이 생성되는 상황과 달리 이러한 이벤트가 많아서 학습을 복잡하게 만듭니다.
가격이 100...1000 포인트까지 떨어지지 않았다면 비슷한 막대를 추가하고 건너 뛰고 싶습니다.
첫 번째 샘플에 대해 이야기하고 있습니까 아니면 두 번째 샘플에 대해 이야기하고 있습니까? 첫 번째에 대해 이야기하고 있다면 좋은 변종에 대해 약 30 핍의 기대 매트릭스를 가졌습니다.
H1의 두 번째 것. 글쎄, 첫 번째 것은 더 좋지 않았습니다 (그러나 나는 그것을 덜 조사했고 예를 들어 기능을 선택하지 않았습니다).
물론 샘플을 업로드하면 CatBoost에서 훈련 해 볼 수 있습니다.
수백 개가 있습니다. 그리고 나는 그들 중 어느 것도 거래에 넣는 것을 좋아하지 않습니다. TP나 SL 또는 다른 것을 변경하면 새로운 변종입니다. 그래서 의미가 없죠.
이제 목표가 어느 정도 명확해졌습니다.
결과를 점수로 예상하시나요, 아니면 승패로만 예상하시나요? 후자인 것 같습니다. 포인트로 추정하는 것이 더 낫습니다.
75% 모델은 실제로 50/50으로 작동하지 않으니까요.
나는 돈으로 평가합니다 :) 예전처럼 목표도 추가합니다. 더 많은 포인트를 원하면 나중에 목표를 이동할 수 있습니다.
구체적인 전략에서는 이제 모든 것이 이익 실현입니다. 나는 계산을 많이했는데 실제로 스프레드가 비율을 크게 악화시키는 것으로 밝혀졌지만 괜찮지 만 매우 수익성이 높은 항목의 배출없이 안정성이있을 것입니다. 위험은 모든 곳에서 거의 동일합니다. 그런 다음 일시 중지를 사용하면 결과를 개선 할 수 있습니다.
가격이 100...1000 포인트까지 떨어지지 않았다면 비슷한 막대를 추가하고 건너 뛰고 싶습니다.
그런 다음 각 막대, 적용 할 모델을 평가 하시겠습니까?
H1의 두 번째. 글쎄, 첫 번째는 더 좋지 않았습니다 (그러나 나는 그것을 덜 연구했고, 예를 들어 칩을 선택하지 않았습니다).
수백 개가 있습니다. 그리고 그들 중 누구도 거래에 넣고 싶지 않습니다. 나는 TP 또는 SL 또는 다른 것을 변경합니다-그것은 새로운 변형입니다. 그래서 의미가 없습니다.
제 요점은 샘플을 만드는 데 동일한 알고리즘이 있으면 예측 변수를 비교할 수 있다는 것입니다.
그런 다음 각 막대에서 추정하려면 어떤 모델을 적용해야 할까요?
예, 훈련에서와 같이 최소 XX 핍이 지나간 경우. 그러나 왜곡이있을 것입니다. 100에서 120 (200-220 등)의 첫 번째 막대 만 위로 올라가고 999-979 (899-979)가 더 자주 작동합니다.
내 요점은 샘플을 만드는 데 동일한 알고리즘이 있으면 예측자를 비교할 수 있다는 것입니다.
5000 개 이상을 원하지 않습니다. 계산하는 데 시간이 오래 걸립니다. 그러나 중요한 예측 인자를 검색 할 때이를 확인해야 할 수도 있습니다.
안녕하세요!
이 문제를 해결할 수 있는 한 가지 방법이 있지만 샘플 파일에는 예측자가 없어야 합니다. 즉, 5000개 이상의 예측자가 필요하지 않고 모션 그래프 자체만 있으면 됩니다. OHLC로 구성되어 있는지 또는 하나의 변수가 있는지는 중요하지 않습니다. 하지만 샘플의 한 변수, 즉 5584 열에 대해 기존 방법을 시도해 보았는데, D(i)=D(i-1)+ Target_100_Buy 공식을 사용하여 차트로 변환했습니다. 세 파일 모두에 대해 다음과 같은 그래프를 얻었습니다:
1) 훈련: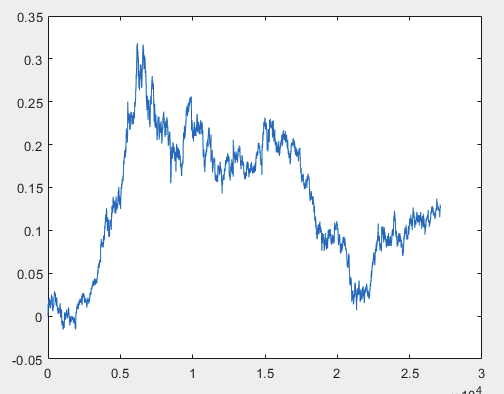
2)test: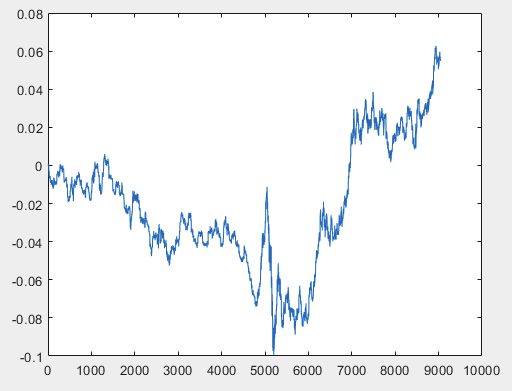
3)시험: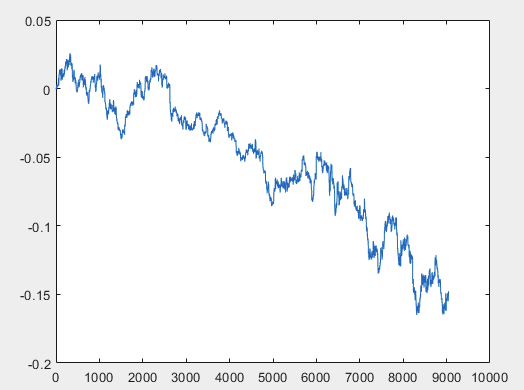
내가 올바르게했는지 여부는 모르겠지만 topikstarter가 예측 변수없이 새 샘플을 만들면 새 데이터에 대해 방법을 테스트하고 접근 방식에 대해 알려 드리겠습니다.
글쎄, 그리고 신경망위원회를 훈련 한 후 각 샘플의 실제 이익 (총 10 개가 있음). 이익은 스프레드=0, 커미션=0으로 포인트 수로 표시됩니다:
1) 훈련: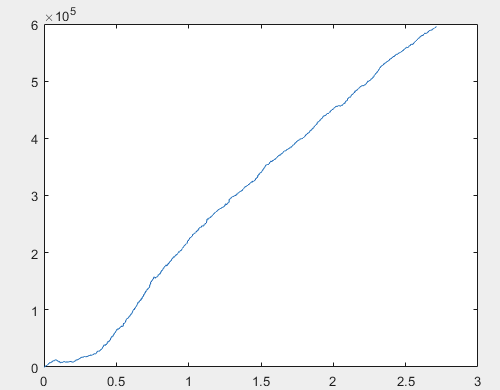
2) 테스트: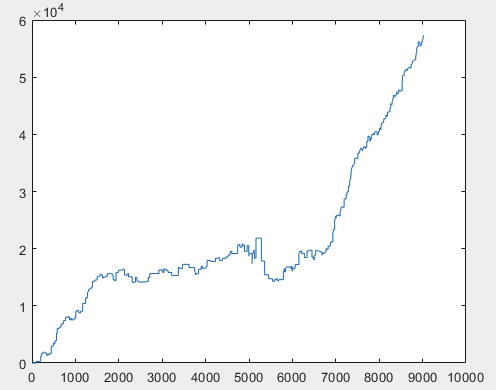
3) 시험: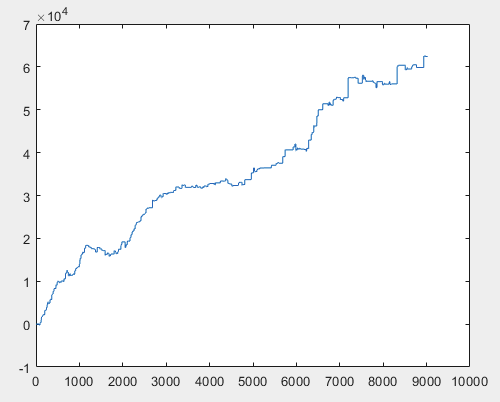
60000+ 핍의 결과는 꽤 괜찮다고 생각합니다.
나는 가장 "혼란스러운"신호로만 새로운 샘플을 만들 것을 제안합니다.
이 방법은 새로운 신호에 적용되고 결과가 표시되고 접근 방식이 어느 정도 설명됩니다.
안부, 롬필!
추신 미래는 알려지지 않았지만 그것을 제어하는 방법은 항상 찾을 수 있습니다 ... :)
안녕하세요!
이 문제를 해결할 수 있는 한 가지 방법이 있지만 샘플 파일에는 예측자가 없어야 합니다. 즉, 5000개 이상의 예측자가 필요하지 않고 모션 그래프 자체만 있으면 됩니다. OHLC로 구성되어 있는지 또는 하나의 변수가 있는지는 중요하지 않습니다. 그러나 샘플의 한 변수, 즉 5584 열에 대해 기존 방법을 시도해 보았는데, 이 열은 D(i)=D(i-1)+ Target_100_Buy 공식을 사용하여 차트로 변환했습니다. 세 파일 모두에 대한 그래프는 다음과 같습니다:
순수한 가격으로 접근하면 왜 새로운 샘플이 필요한지 이해할 수 없습니다.
아래 목록의 열은 발생한 이벤트의 결과입니다. 즉, 교육에 참여해서는 안됩니다. 최대 5582 - 그러나 거기에서 예측하기 쉽다고 생각하므로 모델에 의해 그대로 복구 될 것입니다.
5581 보조
5582 보조
5583 라벨
5584 보조
5585 보조
순수한 가격으로 접근하는 경우 왜 새로운 샘플이 필요한지 이해할 수 없습니다.
아래 목록의 열은 발생한 이벤트의 결과, 즉 훈련에 참여해서는 안됩니다. 최대 5582 - 그러나 예측하기 쉽다고 생각하므로 모델에 의해 복구 될 것입니다.
5581 보조
5582 보조
5583 라벨
5584 보조
5585 보조
"내가 뭘 했지?":
샘플 열차의 크기는 약 1GB입니다. 작업 공간에 로드하는 데 시간이 꽤 오래 걸립니다. 저는 24GB RAM과 빠른 SSD가 장착된 i5-3570을 사용하고 있는데 Excel에서 이 파일을 여는 데 몇 분이 걸립니다. 그래서 저는 이 시간을 줄여야겠다고 결심했습니다. 저는 너무 게을러서 5000개 이상의 열에 대한 위첨자를 알아내지 못했습니다. 5584 5586 열을 가져 와서 모든 행에 신호를 적용했습니다 (솔직히 어느 것인지 기억이 나지 않습니다. 아마도 SELL 일 것입니다). 따라서이 열은 위의 공식에 따라 차트를 형성했습니다. 즉, 첫 번째 단계는 0, 0.00007, 0.00007-0.00002=0.00005, 0.00005+0.00007=0.00012 등이었습니다. 즉, 5584 5586 열에서 바인딩이 없는 모션 차트, 즉 상대 모션 차트를 형성했습니다. 종가 차트인 것처럼, 즉 차트의 각 단계가 끝날 때마다 자산 가격이 해당 값만큼 변경됩니다.
추신 열 번호에 대해 속임수를 썼습니다 ... 가장 최근의 5586 (Excel에서 방금 조회했습니다)을 SELL 신호로 가져 왔습니다.
"... 왜 새로운 샘플":
예제에 대한 접근 방식에 대해 일정량을 보여주고 말하기 위해. OHLC를 사용할 수 있는 열의 수를 지정하거나 절 가격만 지정하면 충분합니다.
나머지에 대해:
샘플 파일의 데이터는 전혀 사용되지 않습니다. 각 파일의 5584 5586 열을 기준으로 위에서 설명한 대로 그래프가 만들어집니다. 그리고이 접근 방식은 이미 이러한 획득 된 그래프에 적용됩니다.
글쎄, 토픽 스타터는 새로운 샘플을 제공하고 싶지 않기 때문에 관심있는 사람은 누구나 자신의 샘플을 게시 할 것을 제안합니다 ... :)
안부, 롬필!
안녕하세요!
이 문제를 해결할 수 있는 한 가지 방법이 있지만 샘플 파일에는 예측자가 없어야 합니다. 즉, 5000개 이상의 예측자가 필요하지 않고 모션 그래프 자체만 있으면 됩니다. OHLC로 구성되어 있는지 또는 하나의 변수가 있는지는 중요하지 않습니다. 그러나 샘플의 한 변수, 즉 열 5584에 대해 기존 방법을 시도해 보았는데, 이 변수는 D(i)=D(i-1)+ Target_100_Buy 공식을 사용하여 차트로 변환했습니다. 세 파일 모두에 대한 그래프는 다음과 같습니다:
목표 함수의 반복성이 훈련되었나요? 예를 들어 20번 성공했다면 21번도 성공할까요?
예측 변수로 입력한 값은 몇 개입니까?
다음은 약 5년 동안 TP/SL=50포인트
M5로 매수 및 매도하는 가장 간단한 목표입니다.
마크업은 각 M5 막대에 있으며, 즉 마지막 신호(5분 전)의 거래가 아직 끝나지 않았을 가능성이 높습니다. 스택을 쌓는 것이 올바른지 잘 모르겠습니다. 스택은 한 순간에 1 개의 거래 만있는 목표에 대해서는 괜찮을 것입니다. 동시에 100 개라도 하룻밤 사이에 완료되지 않을 수 있습니다.
추신 - 나는 그들을 훈련시킬 수 없습니다. 제 예측기 세트에서는 항상 실패합니다.