동료는 불행히도 거래에 더 많은 시간을 할애 할 수 없지만 여전히 약간의 시간을 찾았고 명확히하기로 결정했습니다. 시각)
현상의 본질
이 현상의 본질을 상기시켜 드리겠습니다. 가격 경로의 미래 편차에 대한 "롱테일"의 영향을 분석하는 동안 발견되었습니다. 우리가 "긴 꼬리"를 분류하고 그것들이 없는 시계열 을 보면, 우리는 또한 각 케이터링에 대해 고유하고 거의 각각에 대해 고유한 이상한 현상을 관찰할 수 있습니다. 현상의 본질은 일종의 "신경"접근법을 기반으로하는 매우 구체적인 분류입니다. 사실, 이 분류는 기본 데이터를 "분류"합니다. 인용 프로세스 자체를 두 개의 하위 프로세스로 나눕니다. 저는 이를 일반적으로 " 알파 "와 " 베타 "라고 부릅니다. 일반적으로 말해서 원래 프로세스를 더 많은 하위 프로세스로 나누는 것이 가능합니다.
랜덤 구조의 시스템
이 현상은 무작위 구조의 시스템에 매우 적합합니다. 모델 자체는 매우 간단해 보입니다. 예를 볼 수 있습니다. EURUSD 초기 시리즈M 15(긴 샘플이 필요하고 가능한 한 작은 프레임이 필요함), 일부 "지금":
1단계: 분류
분류가 수행되고 두 개의 프로세스 " alpha "와 " betta "가 얻어진다. 제어 프로세스의 매개변수가 결정됩니다(견적의 최종 "조립"에 관여하는 프로세스)
2단계신분증
각 하위 프로세스에 대해 Volterri 네트워크를 기반으로 하는 모델이 정의됩니다.
아, 그리고 .. 당신은 그들을 식별할 수 있습니다.
3단계 예측 하위 프로세스
각 프로세스에 대해 100개의 판독값에 대한 예측이 이루어집니다(15분 동안, 즉 하루보다 약간 더 큼).
4단계: 시뮬레이션
미래 구현의 x.cloud를 생성할 시뮬레이션 모델이 조립되고 있습니다. 시스템 다이어그램은 간단합니다.
세 가지 사고: 각 모델에 대한 오류 및 프로세스 간 전환 조건. 다음은 구현 자체입니다(처음부터).
5단계: 거래 결정
이러한 구현에 대한 편향 분석이 수행됩니다. 다양한 방법으로 할 수 있습니다. 많은 궤적이 변위되었음을 시각적으로 알 수 있습니다. 사실을 보자:
<>
사전 테스트
나는 무작위로 약 70 "측정"을했습니다 (그는 오랫동안 계산합니다). 70%의 어딘가에서 시스템이 회피를 올바르게 결정했습니다. 이것은 아직 아무 말도 하지 않지만, 비록 메인 프로젝트에 대한 작업을 아직 끝내지 않았지만 몇 달 안에 이 방향으로 돌아가기를 희망합니다. :o(.
Может не совсем корректно: по какому принципу производится классификация и, собственно, разложение на какие процессы предполагается?
아니요, 모든 것이 맞습니다. 이것은 이 주제의 수십 페이지에서 논의된 주제 중 하나였습니다. 내가 필요하다고 생각한 모든 것 - 불행히도 지금은 주제를 더 발전시킬 시간이 없습니다. 또한, 이 특정 현상은 흥미롭긴 하지만 그다지 유망하지 않습니다. "긴 꼬리" 현상은 긴 수평선에서 나타납니다. 궤적의 큰 편차가 나타나는 곳, 그리고 이를 위해서는 프로세스 알파와 베타(및 기타 프로세스)를 멀리 예측할 필요가 있습니다. 그리고 이것은 불가능합니다. 그런 기술이 없다...
:에 대한(
모든
동료 여러분, 제가 안 받은 글이 있는 것 같습니다. 나는 당신의 용서를 구합니다, 이제 경련에 의미가 없습니다.
나는 우리가 "뚱뚱한 꼬리"의 연구에서 더 심각한 "프랙탈" 수학에 도달하기를 바랍니다. 시간이 좀 더 걸리겠지만, 이제 나는 몇 가지 생각을 하게 만든 거의 과학적 연구를 게시합니다.
모델 가정.
내가 찾고자 하는 따옴표 안에 여러 과정이 있다고 가정할 이유가 있다. 주요 "운반 프로세스"는 어떤 종류의 상승/하강 추세로, 일부 확률론적 알고리즘에 따라 다른 프로세스(또는 프로세스)를 중단합니다. 아이디어는 간단합니다. 이론적으로 "뚱뚱한 꼬리"(또는 일부 다른 하위 프로세스)와 관련된 증분을 제거하고 어떤 일이 발생하는지 확인합니다. 분류하는 가장 쉬운 첫 번째 방법은 +/- LAMBDA 내부에 있는 모든 것을 "필터링"하는 것입니다.
증분 Open(n)- Open(n-1), M15, EURUSD:
0.0001에서 0.0001에서 0.025까지 LAMBDA를 정렬하고 특정 +/- LAMBDA 채널에 속하는 증분만 남겨두고 합산하여 각 LAMBDA에 대한 선형 회귀 결정 계수를 결정합니다. 예, 차이가 있을 것이 분명하지만(저는 0으로 간주합니다) 이제 프로세스 자체를 살펴보고 싶습니다.
결정 계수(KD) / LAMBDA
CD, 아주 간단한 경우 모델이 설명하는 데이터의 양을 나타내는 특정 백분율을 상기시켜 드리겠습니다. LAMBDA= 0.0006의 경우 최대값(0.97)에 도달했습니다.
필터링된 증분을 추가할 수 있습니다. 두 가지 프로세스가 있습니다.
값 0.0006은 증분 프로세스의 표준 편차보다 약간 작습니다. 비교를 위해 LAMBDA 값이 0.0023(약 3 표준 편차)인 두 번째 로컬 극값을 볼 수 있습니다.
이러한 "추세"는 모든 인용문에서 식별할 수 있으며 일부(대부분)는 위쪽이고 일부는 아래쪽입니다. 이 방법이 사이비 과학적임이 분명하지만 다른 한편으로는 무작위 구조를 가진 시스템의 대안적 표현이라는 몇 가지 아이디어를 제공했습니다.
흥미로운 결과입니다.
이 현상은 과거 데이터가 입찰 가격이라는 사실 때문일 수 있습니까? (실험에서의 람다는 스프레드와 비슷함)
시간의 함수로 고려된다면 조각별 상수 계수를 사용하여 선형 회귀 를 사용하여 결과 "추세" 프로세스의 품질을 테스트하는 것이 더 합리적이라고 생각하지 않습니까?
틀렸다는 것이 아닙니다. "싸게 사서 비싸게 팔다"라는 표현처럼. 정확성뿐만 아니라 형식화 가능성도 중요합니다. 교활한 철학적 근거리 시장 건물을 짓는 것은 (건물이) 염소 우유와 같다면 의미가 없습니다.
손실을 감수한 후 일시적인 휴식을 공식화하기 어렵다고 생각하시나요? 아니면 또 어떤가요?
고맙습니다. 여가 시간에 SOM에 대해 생각해 보겠습니다.
링크의 기사는 시계열 세분화 방법에 대한 개요를 제공합니다. 그들은 모두 거의 같은 일을 합니다. SOM이 Forex에 가장 좋은 방법은 아니지만, 최악도 아니고 사실입니다))
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.115.6594&rep=rep1&type=pdf
동료는 불행히도 거래에 더 많은 시간을 할애 할 수 없지만 여전히 약간의 시간을 찾았고 명확히하기로 결정했습니다. 시각)
현상의 본질
이 현상의 본질을 상기시켜 드리겠습니다. 가격 경로의 미래 편차에 대한 "롱테일"의 영향을 분석하는 동안 발견되었습니다. 우리가 "긴 꼬리"를 분류하고 그것들이 없는 시계열 을 보면, 우리는 또한 각 케이터링에 대해 고유하고 거의 각각에 대해 고유한 이상한 현상을 관찰할 수 있습니다. 현상의 본질은 일종의 "신경"접근법을 기반으로하는 매우 구체적인 분류입니다. 사실, 이 분류는 기본 데이터를 "분류"합니다. 인용 프로세스 자체를 두 개의 하위 프로세스로 나눕니다. 저는 이를 일반적으로 " 알파 "와 " 베타 "라고 부릅니다. 일반적으로 말해서 원래 프로세스를 더 많은 하위 프로세스로 나누는 것이 가능합니다.
랜덤 구조의 시스템
이 현상은 무작위 구조의 시스템에 매우 적합합니다. 모델 자체는 매우 간단해 보입니다. 예를 볼 수 있습니다. EURUSD 초기 시리즈 M 15(긴 샘플이 필요하고 가능한 한 작은 프레임이 필요함), 일부 "지금":
1단계: 분류
분류가 수행되고 두 개의 프로세스 " alpha "와 " betta "가 얻어진다. 제어 프로세스의 매개변수가 결정됩니다(견적의 최종 "조립"에 관여하는 프로세스)
2단계 신분증
각 하위 프로세스에 대해 Volterri 네트워크를 기반으로 하는 모델이 정의됩니다.
아, 그리고 .. 당신은 그들을 식별할 수 있습니다.
3단계 예측 하위 프로세스
각 프로세스에 대해 100개의 판독값에 대한 예측이 이루어집니다(15분 동안, 즉 하루보다 약간 더 큼).
4단계: 시뮬레이션
미래 구현의 x.cloud를 생성할 시뮬레이션 모델이 조립되고 있습니다. 시스템 다이어그램은 간단합니다.
세 가지 사고: 각 모델에 대한 오류 및 프로세스 간 전환 조건. 다음은 구현 자체입니다(처음부터).
5단계: 거래 결정
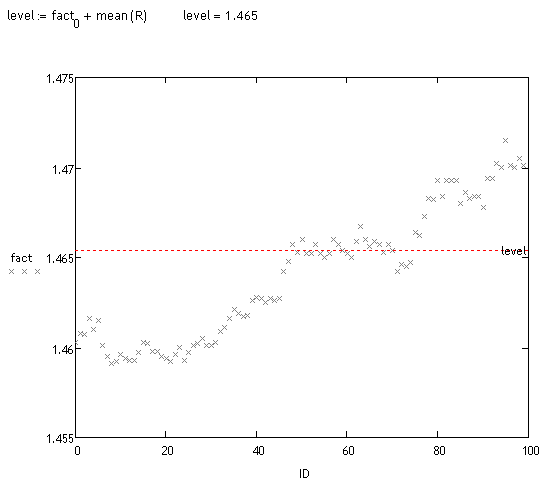
이러한 구현에 대한 편향 분석이 수행됩니다. 다양한 방법으로 할 수 있습니다. 많은 궤적이 변위되었음을 시각적으로 알 수 있습니다. 사실을 보자:
<>
사전 테스트
나는 무작위로 약 70 "측정"을했습니다 (그는 오랫동안 계산합니다). 70%의 어딘가에서 시스템이 회피를 올바르게 결정했습니다. 이것은 아직 아무 말도 하지 않지만, 비록 메인 프로젝트에 대한 작업을 아직 끝내지 않았지만 몇 달 안에 이 방향으로 돌아가기를 희망합니다. :o(.
세이후지에
Может не совсем корректно: по какому принципу производится классификация и, собственно, разложение на какие процессы предполагается?
아니요, 모든 것이 맞습니다. 이것은 이 주제의 수십 페이지에서 논의된 주제 중 하나였습니다. 내가 필요하다고 생각한 모든 것 - 불행히도 지금은 주제를 더 발전시킬 시간이 없습니다. 또한, 이 특정 현상은 흥미롭긴 하지만 그다지 유망하지 않습니다. "긴 꼬리" 현상은 긴 수평선에서 나타납니다. 궤적의 큰 편차가 나타나는 곳, 그리고 이를 위해서는 프로세스 알파와 베타(및 기타 프로세스)를 멀리 예측할 필요가 있습니다. 그리고 이것은 불가능합니다. 그런 기술이 없다...
:에 대한(
모든
동료 여러분, 제가 안 받은 글이 있는 것 같습니다. 나는 당신의 용서를 구합니다, 이제 경련에 의미가 없습니다.
Prokhvesor Fransfort, 연구에 어떤 프로그램을 사용하는지 답해주십시오.
그리고 한 가지 더... 만약 누군가가 러시아어로 된 지침을 가지고 있거나 프로그램 http://originlab.com/(OriginPro 8.5.1)에 대한 크랙이 있는 경우
흥미로운 결과입니다.
이 현상은 과거 데이터가 입찰 가격이라는 사실 때문일 수 있습니까? (실험에서의 람다는 스프레드와 비슷함)
시간의 함수로 고려된다면 조각별 상수 계수를 사용하여 선형 회귀 를 사용하여 결과 "추세" 프로세스의 품질을 테스트하는 것이 더 합리적이라고 생각하지 않습니까?
필터링된 증분을 추가할 수 있습니다. 두 가지 프로세스가 있습니다.