Так уж сложилось, что сейчас мало кто из разработчиков помнит, как написать простую DLL библиотеку и в чем особенности связывания разнородных систем. Я постараюсь за 10 минут на примерах продемонстрировать весь процесс создания простых DLL библиотек и раскрою некоторые технические детали нашей реализации связывания. Покажу пошаговый процесс создания DLL библиотеки в Visual Studio с примерами передачи разных типов переменных (числа, массивы, строки и т.д.) и защиту клиентского терминала от падений в пользовательских DLL.
そこがポイントで、5000+の機能よりも2倍優れている。
他の5000以上のチップは結果を悪化させるだけだということがわかった。
この2つであなたのモデルが何を示すかを比較するのは興味深い。
私は1つより少し多くのマットの期待値を持っており、5,000以内の利益は、精度が51%を書いている - すなわち、結果は明らかに悪化している。
はい、そしてテストサンプルでは、私はすべての100モデルで損失を得た。つまり、結果は明らかに悪化している。
はい、テストサンプルでは、すべての100モデルで損失があった。しかし、最初のサンプルでも負けています。
H1のセカンドサンプルは?そっちは上達している。1つ目のサンプルでは、私も負けている。
はい、H1サンプルのことです。私は最初train.csvで訓練し、test.csvで止め、exam.csvで独立チェックをしているので、2列のバリアントはtest.csvで失敗する。昨日のバリアントも流していたが、少し儲かったものもあった。
さて、どんなミラクルチャートがあるでしょうか?そして、これが20000本のトレーニングで10000本のバルブが進む様子である。つまり、チャートは2年間ではなく、5年間を示しています。そのうちの2年間はドローダウンに置かれ、その後もう1年間は利益が出ず、そのために平均勝率は再び取引あたり0.00002まで低下した。
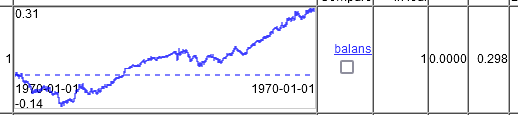
2つの時間列のみ。
5000以上の列すべてで同じ設定。少し良くなった。取引あたり0.00003。
利益0.20600、1取引あたり平均0.00004。スプレッドに比例
はい、この数字はすでに印象的です。しかし、ターゲットが売りにマークされ、そこに大きなTF上の全期間が売られている、私はそれがまた人為的に結果を向上させると思います。
すべての列で0.00002以上ですが、先ほど言ったように「スプレッド、スリッページなどが利益をすべて食いつぶしてしまう」のです。Teriminalはバーごと(つまり1時間全体)の最小スプレッドを表示しますが、取引の瞬間には5~10pt、ニュースでは20pt以上になることもあります。
私が持っているマークアップは分単位のバーで取られていて、スプレッドは通常、一定期間にわたって拡大します。5ではスプレッドがどのように機能するのかさえわかっていません - 4でのテストの方が便利だと思います。
1トレードあたりの平均利益が少なくとも0.00020のモデルを探すべきです。実際の取引では0.00010になるかもしれません。これはEURUSDの場合で、AUD NZDのような他のペアでは50ptでも十分ではなく、スプレッドは20-30ptです。
同感です。このスレッドの最初のサンプルは30 pipsのマットの期待値を与えています。だからこそ、私はマークアップは賢くあるべきだという意見に固執しているのです。
これは試験サンプルの最高のチャートです。試験で最高のバランスを与える設定をどのように選択するかは、解決策のない問題です。テストで選ぶんだ。私はtraine+testでトレーニングした。基本的に、あなたが試験を持っているもの、私はテストを持っています。
まずはサンプルの大半を選択基準点に合格させることから始めるべきだと思う。さらに、最も訓練されていないモデルを選択することは理にかなっているかもしれません。
そして、これが20000行の学習を10000行でロールフォワードする方法です。つまり、グラフ上では2年ではなく5年です。そのうちの2年間はドローダウンで座っている必要があり、その後、利益なしで別の年、このために平均勝利は再び貿易あたり0.00002に低下した。
2つの時間列のみ。
5000以上の列すべてで同じ設定。少し良くなった。取引あたり0.00003。
それでも、他の予測変数も有用であることがわかった。グループで追加してみたり、まず相関をふるいにかけて少し減らしてみたりすることができます。
期待値行列については、この戦略では、ローソク足の始値ではなく、始値から同じ30ピップスでエントリーする方が利益が出るかもしれません。
私が持っているマークアップは分足で取られています。スプレッドは通常、一定期間にわたって広がります。5ではスプレッドがどのように機能するのかさえわかっていません。私にとっては、4でテストする方が便利です。
そしてM1でも、バータイムの最小スプレッドは維持されている。ECH口座では、ほとんどすべてのM1バーが0.00001...0.00002まれにそれ以上です。すべてのシニアバーはM1から構築され、つまり同じ最小スプレッドになります。あなたはラウンドごとに4ポイントの手数料を追加する必要があります(他のブローカーセンターは、他の手数料があるかもしれません)。
他の予測変数も有用であることがわかりました。グループで追加してみたり、まず相関をふるいにかけて少し減らしてみたりすることができる。
おそらくそれらを選択すべきだろう。しかし、2個に5000個以上を加えても少ししか改善しないのであれば、モデルトレーニングで完全に総当たりで10個を選択した方が早いかもしれません。24時間相関を待つより早いと思う。ただ、ターミナルから直接ループで再トレーニングを自動化する必要がある。
katbustaにはDLL版はないのですか?DLLはターミナルから直接呼び出せます。https://www.mql5.com/ru/articles/18、http s://www.mql5.com/ru/articles/5798。
おそらく、我々は選択すべきだ。しかし、2Sに5000個以上を追加してわずかな改善しか得られないのであれば、モデルトレーニングで完全な総当たりで10個を選択した方が早いかもしれない。24時間相関を待つより早いと思う。
例えば10個のグループを作って、その組み合わせでトレーニングし、モデルを評価し、最も失敗したグループを除外し、残りのグループを再グループ化する、つまりグループ内の予測変数の数を減らして再度トレーニングすることができます。私は以前にもこの方法を使ったことがあります - 効果はありますが、やはり速くはありません。
ターミナルから直接ループで再学習を自動化する必要があります。
catbustにはDLL版はないのですか?DLLはターミナルから直接呼び出せます。https://www.mql5.com/ru/articles/18、http s://www.mql5.com/ru/articles/5798。
ターミナルから完全な学習制御ができればいいのですが、私の理解では、まだ解決策はありません。モデルを適用するだけのライブラリcatboostmodel.dllが ありますが、MQL5でどのように実装すればいいのかわかりません。理論的には、もちろんトレーニング用のライブラリの形でインターフェースを作ることは可能です。
そうですね、最初のうちはグループ分けしたほうがいいですね。たとえば10グループ作って、それらを組み合わせて訓練し、モデルを評価して、最もうまくいかなかったグループを除外して、残ったグループを再グループ化する、つまりグループ内の予測変数の数を減らして、もう一度訓練することができます。私は以前この方法を使ったことがある。効果はあるが、やはり速くはない。
私は別の方法を提案する。特徴量を1つずつモデルに追加していくのです。
1) 5000以上のモデルを1つの特徴でトレーニングする。
2) (5000+ -1)のモデルを2つの特徴で訓練する:1番目の最良の特徴と、残りの特徴(5000+ -1)。2番目に良いものを見つける。
3) (5000+ -2) モデルを3つの特徴でトレーニングする:1番目、2番目の特徴、そして残りの( 5000+ -2)。3番目に良いものを見つける。
モデルが改善するまで繰り返す。
私は通常、6~10個の特徴を追加したところでモデルの改善を止めた。10-20まで、または追加したい特徴をいくつでも増やすことができる。
しかし、テストによる特徴の選択は、モデルをデータのテストセクションにフィットさせることだと思います。重み0.3でtrayne、重み0.7でtestという選択方法もあります。しかし、これもフィットだと思います。
私はロール・フォワードをしたかったのですが、そうすると、フィッティングは多くのテスト・セクションに対して行われることになり、カウントに時間がかかることになります。
キャットバスターを動かすためのオートメーションはないけれど......。5万回以上、10個の特徴を得るためにモデルを手動で再トレーニングするのは難しいだろう。それが、私がキャットバストよりもクラフトを好む理由だ。キャットバストより5倍も10倍も動作が遅いのにね。あなたは3分間1つのモデルを持っていましたが、私は22個持っていました。
私が提案しているのはそういうことではない。モデルに一つずつ特徴を追加していく。
1) 5000以上のモデルを1つの特徴でトレーニングする。
2) (5000+ -1)のモデルを2つの特徴で訓練する:1番目の最も良い特徴と、残りの特徴(5000+ -1)。2番目に良いものを見つける。
3) (5000+ -2) モデルを3つの特徴でトレーニングする:1番目、2番目の特徴、そして残りの( 5000+ -2)。3番目に良いものを見つける。
モデルが改善するまで繰り返す。
私は通常、6~10個の特徴を追加したところでモデルの改善を止めた。10-20、または追加したい特徴の数だけ追加することもできる。
アプローチは異なってもよい - それらの本質は一般的に同じであるが、欠点はもちろん共通である - 高すぎる計算コスト。
しかし、テストによる特徴選択とは、データのテストセクションにモデルを当てはめることだと思います。重み0.3のtrayneと重み0.7のtestによる選択というバリエーションがあります。しかし、これもフィットだと思います。
valvingをforwardにしたいのですが、そうするとフィッティングは多くのテスト区間に対して行われることになり、計算に時間がかかりますが、これが最良の選択肢のように思います。
そのため、その選択を正当化するために、機能の内部に合理的な粒子を探しているのです。今のところ、イベントの再発頻度とクラス確率のシフトに落ち着いている。平均すると効果はプラスですが、この方法は相関予測因子を考慮せずに、最初の分割によって実際に評価します。しかし、強い負の素因を持つ予測変数の得点の行をサンプルから取り除くことによって、2番目の分割についても同じ方法を試すべきだと思います。
キャットバスターを実行するためのオートメーションはありませんが...。50,000回以上、10形質を得るためにモデルを手動で再トレーニングするのは難しいでしょう。
それが私がキャットバストよりもクラフトを好む理由です。キャットバストより5倍も10倍も動作が遅いのにね。あなたはカウントに3分かかるモデルを1つ持っていましたが、私は22個持っていました。
それでも私の記事を読んで......。タスクが生成され、bootnikが起動する(トレーニングに使う特徴数のタスクも含む、つまり一度にすべてのバリアントを生成して起動できる)。要するに、ターミナルにbatファイルの実行を教える必要があるのですが、それは可能だと思いますし、トレーニングの終了を制御し、結果を分析し、その結果に基づいて別のタスクを実行します。
学習率を変えることによってのみ、100のうち2つのモデルが基準を満たすことができた。
1つ目は
2つ目。
CatBoostは多くのことができるが、より積極的に設定を調整する必要があるようだ。
これらのモデルは、テストでのベストで選ぶのですか?
それとも、試験で一番良かったものから選ぶのですか?