トレーディングにおける機械学習:理論、モデル、実践、アルゴトレーディング - ページ 169 1...162163164165166167168169170171172173174175176...3399 新しいコメント sibirqk 2016.10.20 13:15 #1681 mytarmailS:プラグを抜いても何もない。でも、ガラス、T&S、OI...等もありますしね。は支払われません。 なるほど、ありがとうございます。mytarmailS:1分間に何度もトレードしていたら、FXで生き残れない...。そして、たとえ100万分の1の確率で奇跡が起きたとしても、お金をもらえる保証はない。さて......またまた取引状況です。 mytarmailS 2016.10.20 13:20 #1682 ミハイル・マルキュカイツ 使いこなせなければ、R-kaも役に立ちません。NSのコンサルタントであることと、ユーザーであることは別物です。これらは全く違うものですが...。誰もいないと思います、不条理に すると言うことで、司会者の発言の不条理さを理解してもらうためのもので、レシェトフは関係ないのですが・・・。エクセルで平均値を計算することにして、mqlのフォーラムに何か書き込んでいる、mt5でできるから寄生している、mqlはmqlコミュニティの役に立っていない、わかったか?JProjectionを使うから寄生虫のマイケルなんだ、そういうことなんだ...。:) Mihail Marchukajtes 2016.10.20 13:44 #1683 私も使っていますが、やはりMQLで書くというか、インジケータにネットを挿入してしまうので...。 寄生虫みたいなものですが、便利です :-) Andrey Dik 2016.10.20 15:38 #1684 mytarmailS:Rは関係ない、何に書こうが何の違いもない、利便性の問題であり、それ以上ではない...。ここで、ReshetovはJavaで彼のJProjectedを書いた、それを禁止し、それはmqlではない、それは有用ではない、この何-彼の名前は-寄生虫!!!!!。という一言に尽きます。レシェトフ氏は、その結果をMTに利用することを前提にプログラムを作っている。彼は多くのアドバイザーを書き、何千ものアイデアを出し、それがすべてMTのために働くのだから、大衆化として、多くのことをやっている。神速で好きなだけ書いてもいいけど、MTで使えるコミュニティがないと意味がない。大切に育てられ、巨額の資金を投じて拡大してきたコミュニティ。 Andrey Dik 2016.10.20 15:41 #1685 sibirqk実行可能なアイデアがあれば、それをMCLに反映させるのは難しいことではありません。また、彼がRフォーラムではなく、ここに書き込んでいることは理解できます。Rは底が浅く、高度に専門化したコミュニティは簡単には見つかりません。そして、MTコミュニティにとって、彼は疑いようのない財産である。 Rにはトレーディングのコミュニティがあるかもしれませんが、MQLのコミュニティと比べたら0です、そこでは新しい発想は生まれませんから、ここに擦り寄ってきて、あそこではダメです。 Vizard_ 2016.10.20 20:23 #1686 アレクセイ・ブルナコフ 異なる時間枠の追加サンプルでのクロスバリデーション。Dr.トレーダー 仮に1年分の学習データがあるとします。1月分のデータを使ったモデルと2月分のデータを使ったモデルの計12個を学習させたいアレクセイ・ブルナコフ これはフィッティングです。 予測変数が完全に......でない場合のために-などの科学的な表現がなければ......)。 単純明快なデータを例にして、モデル化してみましょう...。トレーニング青い点-トレンド赤いポイントバリデーション。 n1;n2;ターゲット 1;0;1 1;1;2 1;0;1 1;1;2 1;0;1 1;0;1 1;1;2 1;0;1 1;0;1 1;0;1 左上 トレンド50%、有効50%。右上-ミキシングあり。 OOS(bottom)の場合は、バカ正直に前のサンプルを追加してサンプルを増やそう。現実には未来は分からないので。 テスト(OOS)がトレーニングポイントに対応していれば、すべて問題ない。 1.5では、モデルがつまずく...。バリデーションやプリミティブを使用することによる小さなメリットを省く実生活でも、だいたい同じようなイメージで......。 СанСаныч Фоменко 2016.10.20 20:56 #1687 これはリソース所有者の公式見解です。ここからRenat Fatkhullin 2016.10.11 03:43#RU言いがかりはやめてください。どんな言語にも居場所がある。Rはインタラクティブな研究に最適です。探索2日目ですが(以前は本を読みました)、本当に内部を可視化した強力なデバッガになりそうです。Rとの共同作業により、私たちの弱点がすぐに明らかになりました。MQL5には、頻繁に行う操作のための強力な関数がほとんどありません。いろいろなことを考えると、マイクロコードを書くべきでしょう。次の2つのビルドでは、複雑な操作を1回の呼び出しで行える新機能を数十個展開する予定です。数学の機能をもっと増やしてほしい。すでにR関数アナログの最初のバージョンをベータ版としてリリースしていますが、今後はベクトルのバリエーションを追加してさらに進化させていきます。Rのグラフパッケージのような機能を持つ、シンプルで強力なグラフィカルライブラリが必要である。Rを意識して作っていきます。何のためにやるのか?私たちは、2001年にMQLで最初のアルゴリズム取引プラットフォームをリリースしました。その都度、可能性を広げていったのですが、数学的な道具立てはあまりよくありませんでした。解析、データアクセス、テスター、分散計算などを開発し、製品を販売するところまでこぎつけました。そして、ほとんどのソリューションが、テカリ、指標、フィッティングの悪循環に陥っていることが明らかになったのです。開発者に次のレベルの数学的能力を身につけさせる必要があるのです。そのため、少し前からMQL5の数学ライブラリの拡張を開始し、Alglib、Fuzzy、Statをベータ版としてリリースしています。これにより、他のシステムからMQL5へ簡単にモデルを移行することができ、Metatrader 5プラットフォーム 用に作成された分析ソリューションのクラスを上げることができます。これからの2ヶ月で、数学的環境の整備が進んでいくのがお分かりいただけると思います。複雑な数学的パッケージに関する議論や論文を歓迎・歓迎します。ラシード・ウマロフ氏に記事の依頼を書き、送る。私たちの仕事は、MQL5の世界に閉じこもることではなく、より高度な技術を持つトレーダーを奨励し、教育することです。もちろん、私たちは自分たちの言語やプラットフォームを攻撃から守るし、これからも守り続けるが、同時に開発にも取り組んでいる。だから、すべてがうまくいくのです。PS.強調表示 Dr. Trader 2016.10.20 21:22 #1688 ヴィザード_。現実の世界では、こんな絵が描かれているのですが...。 結論がよくわからないのですが。 モデルは既知のデータで動作する限り、機能するのでしょうか?つまり、新しいデータで予測する場合、ブレークダウンのタイプ(ミキシングあり/なし)に関係なく、とにかくつまずき始めるということでしょうか。お金を貯めるには、交換しないことです。モデルのパラメータを選択するだけでなく、指標とそのパラメータを選択することもやっているんだ。mt5からパラメータとラグが異なる10000の指標をダウンロードし、遺伝学を使ってこのリストに使われている指標とモデルパラメータ(森の木、ニューロンの層など)の両方を検索しているのです。これは、私流の定型的な依存関係の見つけ方だとも言えます。 もし私がMT5で標準的なパラメータを持つ標準的な指標のセットを取るなら、ニューロンカであれツリーであれ、それらでクロスバリデーションされたモデルはないでしょう。このようなクロスバリデーションでモデルが良い結果を出すような指標群を見つけることは、多くの労力と時間をかけて達成されるものである。正の結果は、空間と時間におけるすべての予測因子間に一定の相関があることを示す一定の基準である。どの区間を学習に使っても、モデルは同じ依存関係を見つけ、それに依存する。下の写真は、そのクロスバリデーションの一例です。各黒線は、アンサンブルの各個別モデルの貿易の結果(バランス成長)である。赤線は、アンサンブル内の大多数のモデルを取引した結果である。そこにあるモデルの約1/3は、遺伝子がすべての変種を検索するのに1日以上かかったにもかかわらず、利益を得ることができません。つまり、これは、結果が非常に良いわけでもないのに、見つけることができる最高の結果の1つです。任意の標準指標を無料でダイヤルすると、この黒いファンがすべて下がり、赤い線が画面の外に出る。 Vizard_ 2016.10.20 22:03 #1689 Dr.Trader:なんだか必死で陳腐になってきましたね、お金を貯めるにはトレードをしないことです。 下の写真は、そのようなクロスクオリフィケーションの一例である。各黒線は、アンサンブルの各パターンの取引結果(残高の伸び)である。赤い線は、大半のモデルを取引した結果です いいえ、実際に起こっていることを視覚的に表現しているだけです。 解決策を探す...を、現実のものとすることです。------------------------------------------------------------------------ 画面左側のドローダウンは悪くない、このあたりはモデルで描写されていない...。 Alexey Burnakov 2016.10.20 23:19 #1690 お二人への私の答えです。モデルが選択されたデータで評価されるのであれば、モデルは無価値である。たとえそれが、モデルが学習されていないデータの期間であってもです。考えてみてください。1)過学習がある。これは、学習データに対するモデルを完璧に近い状態までキャッチアップすることです。他のデータでは一般化できない。そして、2)選択バイアス(楽観的なモデル選択)がある。それは、モデルの挙動をALREADYに知っているデータ上で最適なモデルや委員会が選択された場合です。そしてまた--たとえそれがテストケースであったとしても。この現実を知るのです。クロスバリデーションテストブロックで選択された未学習モデル(テストでプラス側になるもの)が潜在的にTESTに適合しているのです。この影響を軽減するために、ネステッドクロスバリデーションが考案された。すでに選択されたモデル(または委員会)は、他のデータでさらにテストする必要があります。言い換えれば、これはモデル選択方法の検証である。もう一度言いますが、私も何十ものモデルを持っており、予測因子やパラメータを転々としています。そして、これらのモデルは、それぞれ8年かけてソリッドプラスに移行していくのですそして、それがテスト期間です。しかし、テストによって選ばれた「ベスト」なモデルを遅延サンプリングでテストすると、驚きがある。そして、これを「モデル適合クロスバリデーション」と呼びます。これがはっきりすれば、純粋な実験が続けられる。クリアでなければ、現実の世界では何倍も品質が落ちることになります。というのが、99%の確率で見受けられます。 1...162163164165166167168169170171172173174175176...3399 新しいコメント 取引の機会を逃しています。 無料取引アプリ 8千を超えるシグナルをコピー 金融ニュースで金融マーケットを探索 新規登録 ログイン スペースを含まないラテン文字 このメールにパスワードが送信されます エラーが発生しました Googleでログイン WebサイトポリシーおよびMQL5.COM利用規約に同意します。 新規登録 MQL5.com WebサイトへのログインにCookieの使用を許可します。 ログインするには、ブラウザで必要な設定を有効にしてください。 ログイン/パスワードをお忘れですか? Googleでログイン
プラグを抜いても何もない。
でも、ガラス、T&S、OI...等もありますしね。
は支払われません。
なるほど、ありがとうございます。
1分間に何度もトレードしていたら、FXで生き残れない...。そして、たとえ100万分の1の確率で奇跡が起きたとしても、お金をもらえる保証はない。
さて......またまた取引状況です。
使いこなせなければ、R-kaも役に立ちません。NSのコンサルタントであることと、ユーザーであることは別物です。これらは全く違うものですが...。
誰もいないと思います、不条理に すると言うことで、司会者の発言の不条理さを理解してもらうためのもので、レシェトフは関係ないのですが・・・。
エクセルで平均値を計算することにして、mqlのフォーラムに何か書き込んでいる、mt5でできるから寄生している、mqlはmqlコミュニティの役に立っていない、わかったか?
JProjectionを使うから寄生虫のマイケルなんだ、そういうことなんだ...。:)
Rは関係ない、何に書こうが何の違いもない、利便性の問題であり、それ以上ではない...。ここで、ReshetovはJavaで彼のJProjectedを書いた、それを禁止し、それはmqlではない、それは有用ではない、この何-彼の名前は-寄生虫!!!!!。
という一言に尽きます。
レシェトフ氏は、その結果をMTに利用することを前提にプログラムを作っている。彼は多くのアドバイザーを書き、何千ものアイデアを出し、それがすべてMTのために働くのだから、大衆化として、多くのことをやっている。
神速で好きなだけ書いてもいいけど、MTで使えるコミュニティがないと意味がない。大切に育てられ、巨額の資金を投じて拡大してきたコミュニティ。
実行可能なアイデアがあれば、それをMCLに反映させるのは難しいことではありません。また、彼がRフォーラムではなく、ここに書き込んでいることは理解できます。Rは底が浅く、高度に専門化したコミュニティは簡単には見つかりません。そして、MTコミュニティにとって、彼は疑いようのない財産である。
異なる時間枠の追加サンプルでのクロスバリデーション。
仮に1年分の学習データがあるとします。1月分のデータを使ったモデルと2月分のデータを使ったモデルの計12個を学習させたい
これはフィッティングです。
単純明快なデータを例にして、モデル化してみましょう...。トレーニング青い点-トレンド赤いポイントバリデーション。
n1;n2;ターゲット
1;0;1
1;1;2
1;0;1
1;1;2
1;0;1
1;0;1
1;1;2
1;0;1
1;0;1
1;0;1
左上 トレンド50%、有効50%。右上-ミキシングあり。
OOS(bottom)の場合は、バカ正直に前のサンプルを追加してサンプルを増やそう。現実には未来は分からないので。
テスト(OOS)がトレーニングポイントに対応していれば、すべて問題ない。
1.5では、モデルがつまずく...。バリデーションやプリミティブを使用することによる小さなメリットを省く
実生活でも、だいたい同じようなイメージで......。
これはリソース所有者の公式見解です。
ここから
言いがかりはやめてください。
どんな言語にも居場所がある。Rはインタラクティブな研究に最適です。探索2日目ですが(以前は本を読みました)、本当に内部を可視化した強力なデバッガになりそうです。
Rとの共同作業により、私たちの弱点がすぐに明らかになりました。
私たちは、2001年にMQLで最初のアルゴリズム取引プラットフォームをリリースしました。その都度、可能性を広げていったのですが、数学的な道具立てはあまりよくありませんでした。解析、データアクセス、テスター、分散計算などを開発し、製品を販売するところまでこぎつけました。
そして、ほとんどのソリューションが、テカリ、指標、フィッティングの悪循環に陥っていることが明らかになったのです。開発者に次のレベルの数学的能力を身につけさせる必要があるのです。
そのため、少し前からMQL5の数学ライブラリの拡張を開始し、Alglib、Fuzzy、Statをベータ版としてリリースしています。これにより、他のシステムからMQL5へ簡単にモデルを移行することができ、Metatrader 5プラットフォーム 用に作成された分析ソリューションのクラスを上げることができます。
これからの2ヶ月で、数学的環境の整備が進んでいくのがお分かりいただけると思います。
複雑な数学的パッケージに関する議論や論文を歓迎・歓迎します。ラシード・ウマロフ氏に記事の依頼を書き、送る。私たちの仕事は、MQL5の世界に閉じこもることではなく、より高度な技術を持つトレーダーを奨励し、教育することです。
もちろん、私たちは自分たちの言語やプラットフォームを攻撃から守るし、これからも守り続けるが、同時に開発にも取り組んでいる。だから、すべてがうまくいくのです。
PS.
強調表示
現実の世界では、こんな絵が描かれているのですが...。
結論がよくわからないのですが。
モデルは既知のデータで動作する限り、機能するのでしょうか?つまり、新しいデータで予測する場合、ブレークダウンのタイプ(ミキシングあり/なし)に関係なく、とにかくつまずき始めるということでしょうか。
お金を貯めるには、交換しないことです。
モデルのパラメータを選択するだけでなく、指標とそのパラメータを選択することもやっているんだ。mt5からパラメータとラグが異なる10000の指標をダウンロードし、遺伝学を使ってこのリストに使われている指標とモデルパラメータ(森の木、ニューロンの層など)の両方を検索しているのです。これは、私流の定型的な依存関係の見つけ方だとも言えます。
もし私がMT5で標準的なパラメータを持つ標準的な指標のセットを取るなら、ニューロンカであれツリーであれ、それらでクロスバリデーションされたモデルはないでしょう。このようなクロスバリデーションでモデルが良い結果を出すような指標群を見つけることは、多くの労力と時間をかけて達成されるものである。正の結果は、空間と時間におけるすべての予測因子間に一定の相関があることを示す一定の基準である。どの区間を学習に使っても、モデルは同じ依存関係を見つけ、それに依存する。
下の写真は、そのクロスバリデーションの一例です。各黒線は、アンサンブルの各個別モデルの貿易の結果(バランス成長)である。赤線は、アンサンブル内の大多数のモデルを取引した結果である。そこにあるモデルの約1/3は、遺伝子がすべての変種を検索するのに1日以上かかったにもかかわらず、利益を得ることができません。つまり、これは、結果が非常に良いわけでもないのに、見つけることができる最高の結果の1つです。任意の標準指標を無料でダイヤルすると、この黒いファンがすべて下がり、赤い線が画面の外に出る。
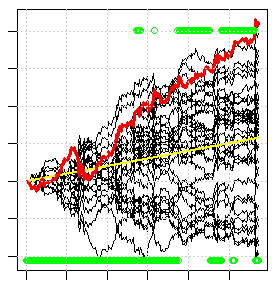
解決策を探す...を、現実のものとすることです。
------------------------------------------------------------------------
画面左側のドローダウンは悪くない、このあたりはモデルで描写されていない...。