
金融モデリングにおける合成データのための敵対的生成ネットワーク(GAN)(第1回):金融モデリングにおけるGANと合成データの紹介

アルゴリズム取引は質の高い金融データに依存していますが、サンプルが少ない、または不均衡なサンプルといった問題がモデルの信頼性に悪影響を及ぼすことがあります。敵対的生成ネットワーク(GAN)は、合成データを生成し、データセットの多様性を高め、モデルの堅牢性を強化することで、この課題に対する解決策を提供します。
GANは、2014年にIan Goodfellowによって導入された機械学習モデルで、データ分布をシミュレートし、現実的なデータコピーを生成します。特に金融分野では、データの不足やノイズに対処するために広く利用されています。例えば、GANを使って合成の株価シーケンスを生成することで、限られたデータセットを補完し、モデルの一般化能力を向上させることができます。ただし、GANの訓練は計算負荷が大きいため、合成データが実際の市場状況と一致するかを慎重に検証する必要があります。
GANの構造
GANは、敵対的なゲームをおこなう2つのニューラルネットワーク(GeneratorとDiscriminator)で構成されています。これらのコンポーネントを以下に詳述します。
- Generator:「Generator」という言葉は、実際のデータを模倣するアルゴリズムを訓練することを意味しています。Generatorは、ランダムなノイズを入力として受け取り、時間の経過とともに現実的なデータサンプルを生成するように学習します。取引の観点では、Generatorは、実際の価格変動や取引量のシーケンスに似た偽のデータを生成します。
- Discriminator:Discriminatorの役割は、構造化データと合成データを区別し、どちらが本物のデータかを判断することです。各データサンプルは、その信憑性に基づいて「本物のデータか合成データか」の可能性が評価されます。その結果、訓練過程でDiscriminatorはデータを本物と識別する能力を高め、これがGeneratorがより良いデータを生成するための動機になります。
GANの強力な点は、まさにこの敵対的なプロセスにあります。以下は、訓練過程でGeneratorとDiscriminatorがどのように相互作用するかを示したものです。
- 手順1:Generatorはランダムノイズを使用して合成データのバッチを生成します。
- 手順2:Discriminatorは実際のデータとGeneratorから生成された合成データの両方を受け取り、それぞれのデータが本物か偽物かを判定します。可能性を割り当て、言い換えれば、各サンプルの信憑性について「判断を下す」のです。
- 手順3:Discriminatorからのフィードバックを基に、Generatorの重みを調整して、より現実的なデータを生成できるようにします。
- 手順4:Discriminatorは、実際のデータと偽のデータを区別しやすくするために重みも変更します。
このサイクルは、Generatorが生成する合成データが非常に現実的になり、Discriminatorによって本物のデータと区別できなくなるまで続きます。これにより、GANは訓練され、Generatorは高品質な合成データを生成できるようになります。
Generatorの損失は、生成されるデータが現実に近づくにつれて減少し、Discriminatorの損失は、DiscriminatorがGeneratorの改善された出力に適応する過程で変化します。
以下は、GeneratorとDiscriminatorがどのように相互作用するかを示すために、PythonとTensorFlowを使用した簡略化されたGANの構造です。
import tensorflow as tf from tensorflow.keras import layers # Define the Generator model def build_generator(): model = tf.keras.Sequential([ layers.Dense(128, activation='relu', input_shape=(100,)), layers.Dense(256, activation='relu'), layers.Dense(512, activation='relu'), layers.Dense(1, activation='tanh') # Output size to match the data shape ]) return model # Define the Discriminator model def build_discriminator(): model = tf.keras.Sequential([ layers.Dense(512, activation='relu', input_shape=(1,)), layers.Dense(256, activation='relu'), layers.Dense(128, activation='relu'), layers.Dense(1, activation='sigmoid') # Output is a probability ]) return model # Compile GAN with Generator and Discriminator generator = build_generator() discriminator = build_discriminator() # Combine the models in the adversarial network discriminator.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) gan = tf.keras.Sequential([generator, discriminator]) gan.compile(optimizer='adam', loss='binary_crossentropy')
この構造では、
Generatorはランダムノイズを現実的な合成データに変換し、その後Discriminatorが入力を本物か偽物かに分類します。そして、GANは両方のモデルを組み合わせ、相互に学習しながら反復的に進化します。
GANの訓練
ここまでで、GANの構造について理解できました。次は、対話型プロセスであるGANの訓練に移ります。この訓練では、GeneratorネットワークとDiscriminatorネットワークが同時に訓練され、それぞれのパフォーマンスが向上します。訓練プロセスは、各ネットワークが他のネットワークが学習できる方法で実行され、最終的に強化された結果を提供できるようにする一連の手順です。ここでは、効果的なGANを訓練するプロセスの主な部分について説明します。GAN訓練の中核は、各ネットワークが各サイクルで独立して更新される代替的な2段階プロセスです。
- 手順1:Discriminatorを訓練します。
まず、Discriminatorは実際のデータサンプルを受け取り、それぞれのサンプルが本物である確率を推定し、その後、Generatorによって生成された合成データを受け取ります。次に、Discriminatorの損失は、実際のサンプルと合成サンプルを分類する能力によって決定されます。この損失を最小化するように重みが調整され、本物のデータと偽物のデータを識別する能力が向上します。
- 手順2:Generatorを訓練します。
Generatorはランダムノイズから合成サンプルを生成し、それをDiscriminatorに渡します。その後、Discriminatorの予測を使用してGeneratorの損失を計算します。Generatorは、Discriminatorに自分が生成したデータが現実的であると認識させたいと考えているためです。Generatorの重みは損失を減らすように調整され、Discriminatorを欺く、より現実的なデータを生成できるようになります。
この予測を交互におこなうプロセスは繰り返し行われ、ネットワークは徐々に互いの変化に適応していきます。
次のコードは、TensorFlowを使用したPythonでのGAN訓練ループの中核を示しています。
import numpy as np import tensorflow as tf from tensorflow.keras import layers, Model from tensorflow.keras.optimizers import Adam tf.get_logger().setLevel('ERROR') # Only show errors # Generator model def create_generator(): input_layer = layers.Input(shape=(100,)) x = layers.Dense(128, activation="relu")(input_layer) x = layers.Dense(256, activation="relu")(x) x = layers.Dense(512, activation="relu")(x) output_layer = layers.Dense(784, activation="tanh")(x) model = Model(inputs=input_layer, outputs=output_layer) return model # Discriminator model def create_discriminator(): input_layer = layers.Input(shape=(784,)) x = layers.Dense(512, activation="relu")(input_layer) x = layers.Dense(256, activation="relu")(x) output_layer = layers.Dense(1, activation="sigmoid")(x) model = Model(inputs=input_layer, outputs=output_layer) return model # GAN model to combine generator and discriminator def create_gan(generator, discriminator): discriminator.trainable = False # Freeze discriminator during GAN training gan_input = layers.Input(shape=(100,)) x = generator(gan_input) gan_output = discriminator(x) gan_model = Model(inputs=gan_input, outputs=gan_output) return gan_model # Function to train the GAN def train_gan(generator, discriminator, gan, data, epochs=10000, batch_size=64): half_batch = batch_size // 2 for epoch in range(epochs): # Train Discriminator noise = np.random.normal(0, 1, (half_batch, 100)) generated_data = generator.predict(noise, verbose=0) real_data = data[np.random.randint(0, data.shape[0], half_batch)] # Train discriminator on real and fake data d_loss_real = discriminator.train_on_batch(real_data, np.ones((half_batch, 1))) d_loss_fake = discriminator.train_on_batch(generated_data, np.zeros((half_batch, 1))) d_loss = 0.5 * np.add(d_loss_real, d_loss_fake) # Train Generator noise = np.random.normal(0, 1, (batch_size, 100)) g_loss = gan.train_on_batch(noise, np.ones((batch_size, 1))) # Print progress every 100 epochs if epoch % 100 == 0: print(f"Epoch {epoch} | D Loss: {d_loss[0]:.4f} | G Loss: {g_loss[0]:.4f}") # Prepare data data = np.random.normal(0, 1, (1000, 784)) # Initialize models generator = create_generator() discriminator = create_discriminator() discriminator.compile(optimizer=Adam(), loss="binary_crossentropy", metrics=["accuracy"]) gan = create_gan(generator, discriminator) gan.compile(optimizer=Adam(), loss="binary_crossentropy") # Train GAN train_gan(generator, discriminator, gan, data, epochs=10000, batch_size=64)
このコードは、指定されたデータセットからの実際のデータと、実際のGeneratorによって生成された偽のデータを使ってDiscriminatorを訓練します。Discriminatorの訓練では、実際のデータは「1」に分類され、生成されたデータは「0」に分類されます。次に、Generatorはフィードバックシステムを通じてDiscriminatorから訓練され、より本物に近いデータを生成できるようになります。
Discriminatorの応答をもとに、Generatorは現実的なデータを生成する能力をさらに向上させます。また、このコードは、後で説明するように、100エポックごとにDiscriminatorとGeneratorの損失を出力します。これにより、GANの訓練進行状況を評価し、特定の時点でGANの各部分がどれだけ意図した通りに機能しているかを確認する手段が提供されます。
金融モデリングにおけるGAN
GANは、特に新しいデータの生成において金融モデリングに非常に有用になっています。金融市場では、データの不足やデータプライバシーの問題により、予測モデルの訓練とテストに必要な高品質なデータが不足しています。GANは、実際の金融データセットと統計的に類似した合成データを生成できるため、この問題を解決するのに役立ちます。
私たちが特定できる応用分野の1つはリスク評価です。GANは極端な市場状況をモデル化し、履歴データを使わずにポートフォリオのストレステストを実施するのに役立ちます。さらに、GANは多様な訓練データセットを生成し、モデルが過剰適合しないようにすることで、モデルの堅牢性を高めることができます。また、詐欺取引や市場の異常などの外れ値を示す合成データセットを作成するために、複雑なモデルを開発して外れ値生成に使用されます。
全体として、金融モデリングにおけるGANの使用は、金融機関がデータ品質の問題に対処し、あまり観察されないイベントの発生をシミュレートし、モデルの予測精度を向上させる手助けとなり、現代の金融分析と意思決定において非常に重要なツールとなっています。
MQL5でシンプルなGANを実装する
GANについて理解したので、次はMQL5での合成データ生成に進みます。取引の文脈において、合成データの概念にアプローチする新しい方法を提供する敵対的生成ネットワーク(GAN)をMQL5で訓練した結果としての合成データ生成について説明します。基本的なGANは、偽のデータ(例えば、価格トレンドなど)を生成するGeneratorと、データポイントが本物か偽物かを判断するDiscriminatorという2つのコンポーネントで構成されています。これをMQL5でシンプルなGANとして適用し、実際の市場動向を模倣した人工的な終値をモデル化する方法を見ていきましょう。
- GeneratorとDiscriminatorの定義
double GenerateSyntheticPrice() { return NormalizeDouble(MathRand() / 1000.0, 5); // Simple random price } double Discriminator(double price, double threshold) { if (MathAbs(price - threshold) < 0.001) return 1; // Real return 0; // Fake }
MQL5でGANを使用する例として、GANを使用して金融モデリングとテスト用の合成データを作成し、取引アルゴリズムの改善の可能性を広げる方法を示します。
以下は、実際のデータと合成データの両方に対する1つのエキスパートアドバイザー(EA)のテストです。
これらの結果によると、Real Dataはより現実的ではあるものの、実際の市場状況は予測不可能なため、利益が低くなる可能性があります。
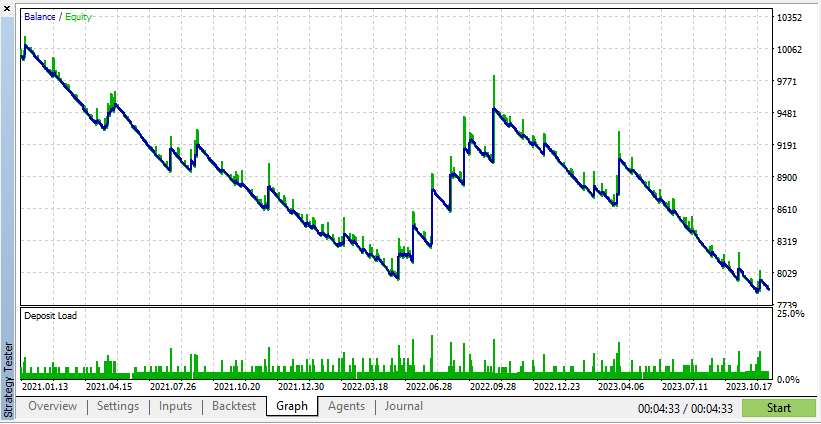
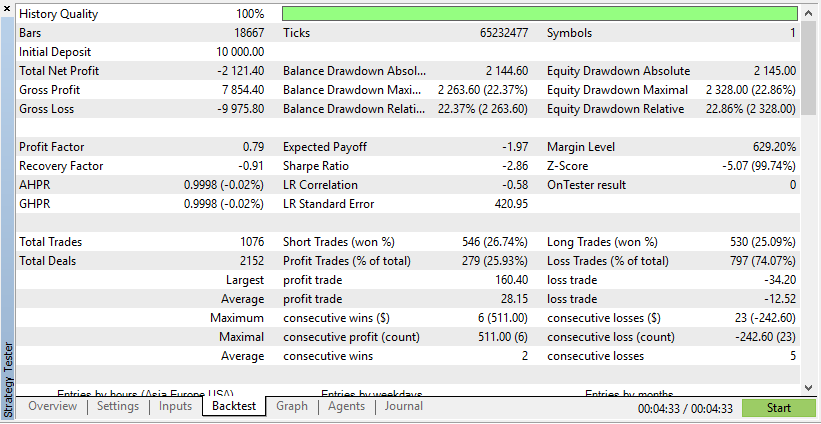
これらの結果によると、合成データは、データがEAにとって理想的な条件によるものである場合、より高い利益を示すことが示されています。
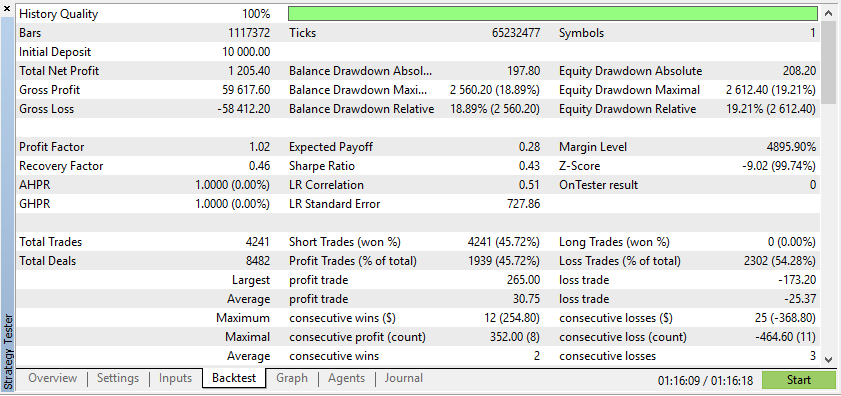
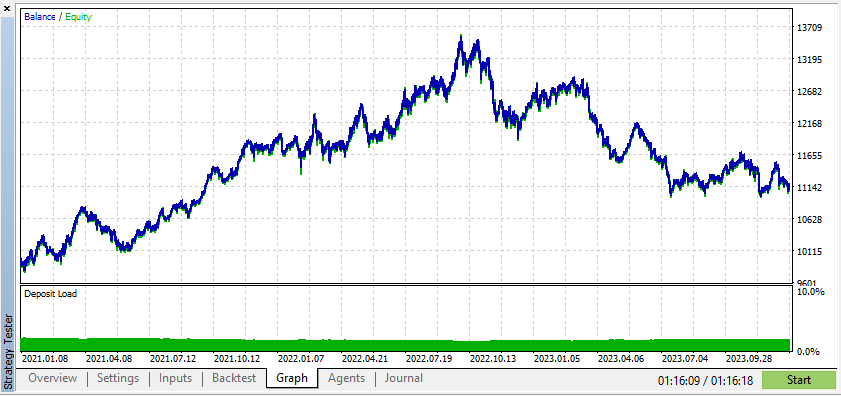
ただし、実際のデータを使用すると、実際の取引条件下でEAがどのように機能するかをより明確に理解できます。合成データに依存すると、誤解を招くバックテスト結果が生じることが多く、実際の市場では再現できない可能性があります。
GANの訓練過程の理解は、学習プロセスやモデルの安定性についての洞察を提供するため、非常に重要です。金融モデリングにおいて、視覚化は、合成データがGANによって捕えられた実際のデータのパターンを適切に再現しているかどうかをモデル作成者が理解するために使用されます。訓練の各段階で生成された出力を開発者に表示し、モード崩壊や合成データの品質低下などの潜在的な問題を検出できます。このような評価は継続的に行われるため、適切なパラメータ設定をしながら、対象となる金融パターンを反映するデータを生成するためのGANのパフォーマンスを向上させることができます。
以下は、3年間のEURUSDデータに基づいて合成商品を作成するためのコード例です。
import pandas as pd import numpy as np import matplotlib.pyplot as plt import os # Download data using the terminal # Replace 'your-api-key' with an actual API key from a data provider # Here, we simulate this with a placeholder for clarity api_key = "your-api-key" symbol = "EURUSD" output_csv = "EURUSD_3_years.csv" # Command to download the data from Alpha Vantage or any similar service # Example using Alpha Vantage (Daily FX data): https://www.alphavantage.co command = f"curl -o {output_csv} 'https://www.alphavantage.co/query?function=FX_DAILY&from_symbol=EUR&to_symbol=USD&outputsize=full&apikey={api_key}&datatype=csv'" os.system(command) # Read the downloaded CSV file data = pd.read_csv(output_csv) # Ensure the CSV is structured correctly for further processing # Rename columns if necessary to match yfinance format data.rename(columns={"close": "Close"}, inplace=True) # Print the first few rows to confirm print(data.head()) # Extract the 'Close' prices from the data prices = data['Close'].values # Normalize the prices for generating synthetic data min_price = prices.min() max_price = prices.max() normalized_prices = (prices - min_price) / (max_price - min_price) # Example: Generating some mock data def generate_real_data(samples=100): # Real data following a sine wave pattern time = np.linspace(0, 4 * np.pi, samples) data = np.sin(time) + np.random.normal(0, 0.1, samples) # Add some noise return time, data def generate_fake_data(generator, samples=100): # Fake data generated by the GAN noise = np.random.normal(0, 1, (samples, 1)) generated_data = generator.predict(noise).flatten() return generated_data # Mock generator function (replace with actual GAN generator model) class MockGenerator: def predict(self, noise): # Simulate GAN output with a cosine pattern (for illustration) return np.cos(np.linspace(0, 4 * np.pi, len(noise))).reshape(-1, 1) # Instantiate a mock generator for demonstration generator = MockGenerator() # Generate synthetic data: Let's use a simple random walk model as a basic example # (this is a placeholder for a more sophisticated method, like using GANs) np.random.seed(42) # Set seed for reproducibility synthetic_prices_normalized = normalized_prices[0] + np.cumsum(np.random.normal(0, 0.01, len(prices))) # Denormalize the synthetic prices back to the original scale synthetic_prices = synthetic_prices_normalized * (max_price - min_price) + min_price # Configure font sizes plt.rcParams.update({ 'font.size': 12, # General font size 'axes.titlesize': 16, # Title font size 'axes.labelsize': 14, # Axis labels font size 'legend.fontsize': 12, # Legend font size 'xtick.labelsize': 10, # X-axis tick labels font size 'ytick.labelsize': 10 # Y-axis tick labels font size }) # Plot both historical and synthetic data on the same graph plt.figure(figsize=(14, 7)) plt.plot(prices, label="Historical EURUSD", color='blue') plt.plot(synthetic_prices, label="Synthetic EURUSD", linestyle="--", color='red') plt.xlabel("Time Steps", fontsize=14) # Adjust fontsize directly if needed plt.ylabel("Price", fontsize=14) # Adjust fontsize directly if needed plt.title("Comparison of Historical and Synthetic EURUSD Data", fontsize=16) plt.legend() plt.show()
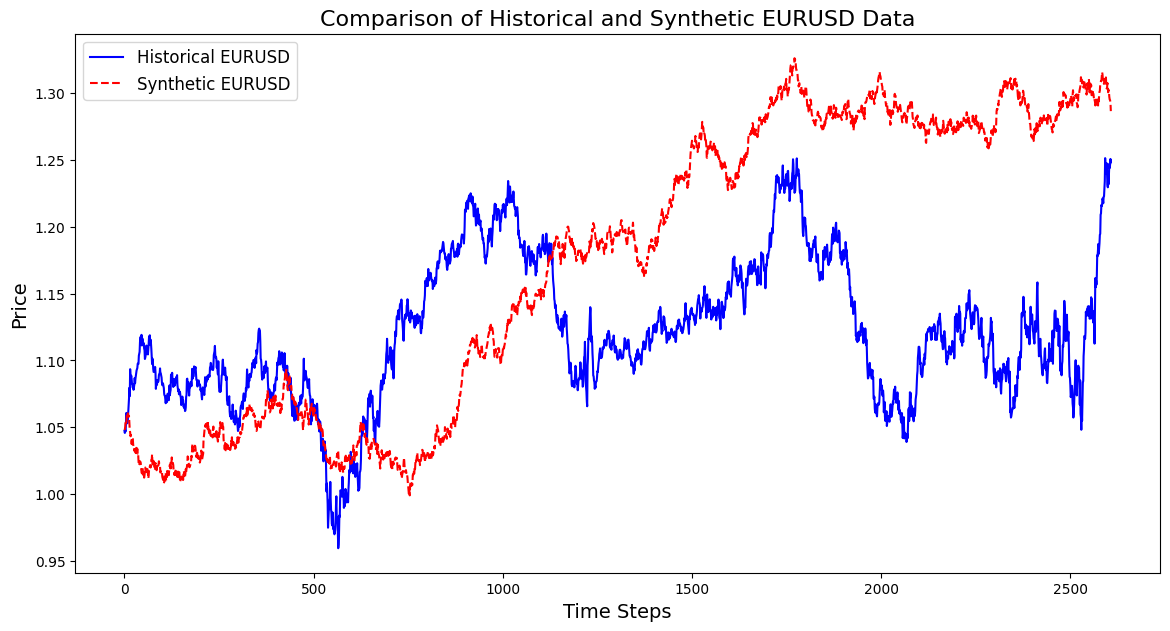
この視覚化により、合成データが実際のデータとどの程度一致しているかを追跡し、GANの進捗状況に関する洞察を提供するとともに、訓練中に改善の余地がある領域を明確にします。
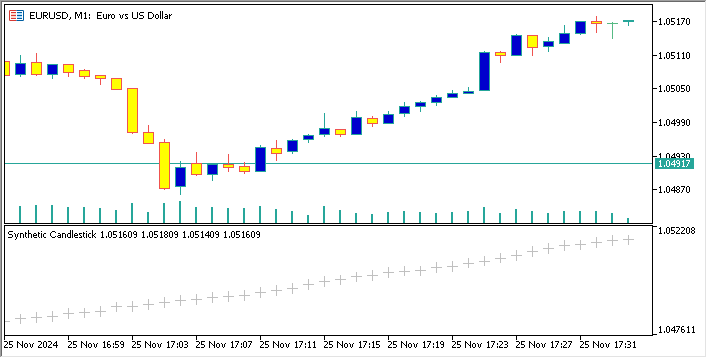
以下は、EURUSDに基づいて合成通貨ペアを作成し、EURUSDチャートにローソク足チャートを表示するコードです。
//+------------------------------------------------------------------+ //| Sythetic EURUSDChart.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property indicator_separate_window // Display in a seperate window #property indicator_buffers 4 //Buffers for Open, High,Low,Close #property indicator_plots 1 //Plot a single series(candlesticks) //+------------------------------------------------------------------+ //| Indicator to generate and display synthetic currency data | //+------------------------------------------------------------------+ double openBuffer[]; double highBuffer[]; double lowBuffer[]; double closeBuffer[]; //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { //---Set buffers for synthetic data SetIndexBuffer(0, openBuffer); SetIndexBuffer(1, highBuffer); SetIndexBuffer(2, lowBuffer); SetIndexBuffer(3, closeBuffer); //---Define the plots for candle sticks IndicatorSetString(INDICATOR_SHORTNAME, "Synthetic Candlestick"); //---Set the plot type for the candlesticks PlotIndexSetInteger(0, PLOT_DRAW_TYPE, DRAW_CANDLES); //---Setcolours for the candlesticks PlotIndexSetInteger(0, PLOT_COLOR_INDEXES, clrGreen); PlotIndexSetInteger(1, PLOT_COLOR_INDEXES, clrRed); //---Set the width of the candlesticks PlotIndexSetInteger(0, PLOT_LINE_WIDTH, 2); //---Set up the data series(buffers as series arrays) ArraySetAsSeries(openBuffer, true); ArraySetAsSeries(highBuffer, true); ArraySetAsSeries(lowBuffer, true); ArraySetAsSeries(closeBuffer, true); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Custom indicator iteration function | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { //--- int start = MathMax(prev_calculated-1, 0); //start from the most recent data double price =close[rates_total-1]; // starting price MathSrand(GetTickCount()); //initialize random seed //---Generate synthetic data for thechart for(int i = start; i < rates_total; i++) { double change = (MathRand()/ 32768.0)* 0.0002 - 0.0002; //Random price change price += change ; // Update price with the random change openBuffer[i]= price; highBuffer[i]= price + 0.0002; //simulated high lowBuffer[i]= price - 0.0002; //simulated low closeBuffer[i]= price; } //--- return value of prev_calculated for next call return(rates_total); } //+------------------------------------------------------------------+
金融モデリングにおけるGANを評価するための一般的な指標の分析
敵対的生成ネットワーク(GAN)を評価することは、合成データが実際の金融データを正確に複製しているかどうかを判断するために重要です。評価に使用される主要な指標は次のとおりです。
1.平均二乗誤差(MSE)
MSEは、実際のデータポイントと合成データポイント間の平均二乗差を測定します。MSEが低いほど、合成データが実際のデータセットに非常に似ていることを示し、価格予測やポートフォリオ管理などのタスクに適しています。トレーダーはMSEを使用して、GANによって生成されたデータが実際の市場の動きを反映しているかどうかを検証できます。たとえば、偽の株価データを生成するために敵対的生成ネットワーク(GAN)を使用するトレーダーは、エントロピーを測定し、履歴に記録された実際の価格を使用して平均二乗誤差(MSE)を計算できます。MSEが低いということは、合成データが実際の市場の動きと一致し、将来の価格変動を予測するためのAIモデルの訓練に使用できるため、合成データの堅牢性が証明されます。
2.フレシェ開始距離(FID)
FIDは画像生成でよく使用されますが、金融データにも適用できます。特徴空間における実際のデータ分布と合成データ分布を比較します。FIDスコアが低いほど、合成データと実際のデータ間の整合性が高まり、ポートフォリオのストレステストやリスク推定などのアプリケーションがサポートされます。たとえば、収益の合成分布と実際の市場収益を比較することでポートフォリオを管理します。仮説3は、FIDスコアが低いということは、GANによって生成されたリターンが実際のリターン分布に近いことを意味するため、GANモデルがポートフォリオのストレステストとリスク推定のパフォーマンスに適していることを示しています。
3.カルバック・ライブラー(KL)ダイバージェンス
KLダイバージェンスは、合成データの確率分布が実際のデータの分布にどの程度一致するかを評価します。金融分野では、KLダイバージェンスが低いということは、GAN生成データがボラティリティクラスタリングなどの重要な特性を捉えていることを意味し、リスクモデリングやアルゴリズム取引に効果的です。たとえば、モデルは、テールリスクとボラティリティクラスタリングの観点から、生成モデルまたはGANの実際の資産収益分布を認識する能力を評価します。KLダイバージェンスが低いということは、合成データが現実的なリターンリスクの重要な特徴を持っていることを意味し、したがって、GANデータに基づくリスクモデルを適用することが効果的です。
4.Discriminatorの精度
Discriminatorは、実際のデータと合成データをどれだけ正確に区別できるかを測定します。理想的には、訓練が進むにつれて、Discriminatorの精度は50%に近づき、合成データが実際のデータと区別できないことを示します。これにより、バックテストと将来のシナリオモデリングのためのGAN出力の品質が検証されます。たとえば、アルゴリズム取引戦略で使用すると、フロー検証プロセスに役立ちます。この精度を観察することで、トレーダーはGANが現実的な合成先物を作成しているかどうかを判断するのに有利な立場に立つことになります。高品質で区別がつかないシナリオは、バックテストされたデータの結果と一致し、精度は50%前後です。
これらのメトリックは、金融モデリングにおけるGANを評価するための包括的なフレームワークを提供します。これらは、開発者が合成データの品質を向上させ、ポートフォリオ管理、リスク評価、取引戦略の検証などのタスクへの適用性を確保するのに役立ちます。
結論
生成的敵対ネットワーク(GAN)を使用すると、トレーダーや金融アナリストは合成データを生成でき、実際のデータが限られている、コストがかかる、または機密性が高い場合に非常に有用です。GANは、金融モデリングにおいて信頼性の高いデータを提供し、取引モデルにおけるキャッシュフロー分析を強化します。GANの基礎知識を持っていれば、トレーダーは独自に合成データ生成を探求し、分析能力を高めることができます。
今後のトピックでは、GANの安定性と金融への応用を向上させるための高度な技術であるWasserstein GANやProgressive Growingなどを取り上げる予定です。
| ファイル名 | 詳細 |
|---|---|
| GAN_training_code.py | GANを訓練するためのファイル訓練コード |
| GAN_Inspired basic structure.mq5 | MQL5のGAN構造体のコードを含むファイル |
| GAN_Model_building.py | PythonのGAN構造体のコードを含むファイル |
| MA Crossover GAN integrated.mq5 | 実際のデータと偽のデータでテストされたEAのコードを含むファイル |
| EURUSD_historical_synthetic_ comparison.py | 履歴と合成EURUSDの比較コードを含むファイル |
| Synthetic EURUSDchart.mq5 | EURUSDチャート上に合成チャートを作成するためのコードを含むファイル |
| EURUSD_CSV.csv | エキスパートアドバイザーをテストするためにインポートされる合成データを含むファイル |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/16214
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索