
古典的な戦略を再構築する(第10回):AIはMACDを強化できるか?

移動平均クロスオーバーは、おそらく最も古くから存在する取引戦略の1つです。移動平均収束拡散(MACD: Moving Average Convergence Divergence)は、移動平均クロスオーバーの概念に基づいて構築された非常に人気のあるインジケーターです。私たちのコミュニティには、最適な取引戦略を構築しようとする中で、MACDインジケーターの予測能力を知りたいと考える新しいメンバーが多くいます。また、MACDを戦略に組み込んでいる熟練したテクニカルアナリストの中にも同じ疑問を持っている方がいるかもしれません。この記事では、EURUSDペアにおけるMACDインジケーターの予測能力についての実証的分析を紹介します。さらに、AIを使用してテクニカル分析を強化するためのモデリング技法も紹介します。
取引戦略の概要
MACDインジケーターは、主に市場のトレンドを識別し、トレンドの勢いを測定するために使用されます。このインジケーターは、1970年代に故ジェラルド・アペル氏によって作成されました。アペル氏は、個人顧客向けの資産運用マネージャーとして、テクニカル分析アプローチを駆使した取引で成功を収めました。約50年前にMACDインジケーターを発明した人物です。

図1:MACDインジケーターの開発者、ジェラルド・アペル氏
テクニカルアナリストは、さまざまな方法でエントリーポイントとエグジットポイントを識別するためにこのインジケーターを使用します。以下の図2は、デフォルト設定を使用してGBPUSDペアに適用したMACDインジケーターのスクリーンショットです。このインジケーターはMetaTrader 5にデフォルトで組み込まれています。赤い線(MACDメイン)は、速い移動平均と遅い移動平均の差を計算したものです。メインラインが0を下回ると、市場は下降トレンドにあると判断され、0を上回ると逆に上昇トレンドとなります。
メインライン自体も、市場の強さを識別するために使用できます。価格が上昇すると、メインラインの値は増加し、価格が下落すればメインラインは下降します。そのため、メインラインがコップに似た形状を形成する転換点は、市場の勢いの変化を示しています。MACDを基にしたさまざまな取引戦略が考案されており、より洗練された戦略では、MACDダイバージェンスを特定することを目指します。
MACDダイバージェンスとは、価格が強いトレンドで上昇し、新たな極端なレベルに達する一方で、MACDインジケーターはトレンドが浅くなり、下降し始める現象です。通常、MACDダイバージェンスはトレンド反転の早期警告として解釈され、トレーダーは市場のボラティリティがさらに高まる前にポジションをロールバックすることが可能です。
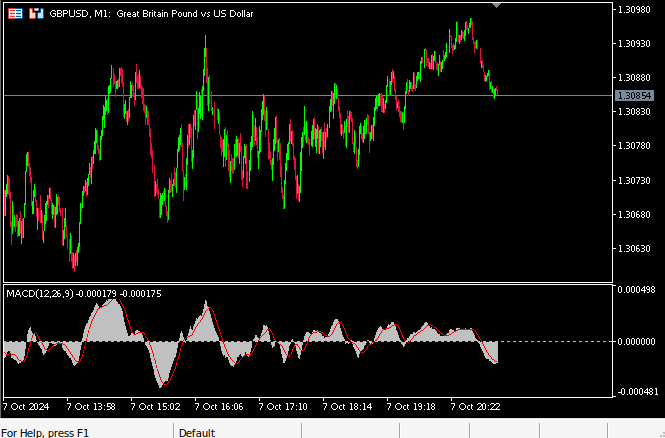
図2:GBPUSD M1チャートにおけるデフォルト設定のMACDインジケーター
MACDインジケーターの有用性そのものに疑問を抱く懐疑的な意見も多く存在します。まずは、避けて通れない議論、いわゆる「部屋の中の象」に取り組むことから始めましょう。すべてのテクニカルインジケーターは「遅行指標」と分類されます。つまり、テクニカルインジケーターは価格レベルが変化した後にのみ変化し、価格変動に先行することはできません。一方で、世界的なインフレ率などのマクロ経済インジケーターや、戦争の勃発や自然災害といった地政学的ニュースは需要と供給のバランスに影響を与える可能性があります。これらは、価格がその影響を反映する前に変化をもたらすため、「先行インジケーター」とみなされます。
多くのトレーダーは、MACDのような遅行指標によるシグナルでは、市場の動きがすでに終息してしまった段階でポジションを取ることになる可能性が高いと考えています。さらに、MACDダイバージェンスが発生していない状況でトレンド反転が起こるケースがよく見られる一方で、トレンド反転が発生しなかったMACDダイバージェンスが観察されることもあります。
これらの事実は、MACDインジケーターの信頼性や、それが本当に価値ある予測力を持っているかどうかを問う根拠となります。この問題を検証するため、AIを活用してインジケーター固有の遅延を克服できるかどうかを評価します。もしMACDインジケーターが予測インジケーターとして十分に有用であると判明した場合、次のいずれかのAIモデルを統合します。
- インジケーターの値を利用して将来の価格レベルを予測する
- MACDインジケーター自体の動きを予測する
どちらのモデリング手法がより低い誤差を示すかに基づいて選択します。一方で、現在の戦略においてMACDが予測力を欠いていることが分析により示唆された場合、価格レベルを予測する際に、最もパフォーマンスの高いモデルを採用する方針を取ります。
方法論の概要
私たちの分析は、MQL5で作成したカスタムスクリプトから始まりました。このスクリプトを使用して、EURUSDのM1市場相場データおよびそれに対応するMACDシグナルとメイン値を正確に10万行取得し、CSVファイルに出力しました。データの視覚化を行った結果、MACDインジケーターは将来の価格レベルを区別するには不適切であるように見受けられました。価格レベルの変動はインジケーターの値とは独立している可能性が高い上に、インジケーターの計算によりデータが非線形かつ複雑な構造を持ち、モデル化が困難になる可能性が示唆されました。
MetaTrader 5端末から取得したデータは、2つの部分に分割しました。データの前半部分を使用し、5分割交差検証を用いてモデルの精度を評価しました。その後、以下の3つの同一構造のディープニューラルネットワークモデルを作成し、それぞれ異なるデータのサブセットで訓練をおこないました。
- 価格モデル: MetaTrader 5のOHLC(始値、高値、安値、終値)市場相場を使用して価格レベルを予測
- MACDモデル:OHLC相場とMACDの読み取り値を使用してMACDインジケーター値を予測
- 完全なモデル:OHLC相場とMACDインジケーターを組み合わせて価格レベルを予測
データの後半部分はモデルのテストに使用しました。その結果、最初のモデル(価格モデル)が最高のテスト精度である69%を記録しました。特徴量選択アルゴリズムにより、MetaTrader 5から取得した市場相場データがMACD値よりも有益であることが明らかになりました。
これを受け、EURUSDペアの将来の価格を予測する回帰モデル(価格モデル)の最適化に取り組みました。しかし、訓練データのノイズを過剰に学習してしまう問題に直面し、テストセットで単純な線形回帰を上回る成果を挙げることができませんでした。そのため、過剰に最適化されたモデルを廃止し、代わりにサポートベクターマシン(SVM)を採用しました。
最終的に、SVMモデルをONNX形式にエクスポートし、将来のEURUSD価格レベルの予測とMACDインジケーターを組み合わせたアプローチを用いたエキスパートアドバイザー(EA)を構築しました。
必要なデータの取得
作業を開始するにあたり、まずMetaEditor統合開発環境(IDE)を使用しました。MetaTrader 5端末から市場データを取得するために、以下のスクリプトを作成しました。このスクリプトは、履歴M1データを10万行分取得し、CSV形式でエクスポートするよう設計されています。具体的には、CSVファイルに時間、始値、高値、安値、終値、および2つのMACD値の情報を出力します。私たちと同じ手順で進めたい場合は、分析対象とする通貨ペアにこのスクリプトをドラッグ&ドロップするだけで使用できます。
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/ja/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| Script Inputs | //+------------------------------------------------------------------+ input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int indicator_handler; double indicator_buffer[]; double indicator_buffer_2[]; //+------------------------------------------------------------------+ //| On start function | //+------------------------------------------------------------------+ void OnStart() { //--- Load indicator indicator_handler = iMACD(Symbol(),PERIOD_CURRENT,12,26,9,PRICE_CLOSE); CopyBuffer(indicator_handler,0,0,size,indicator_buffer); CopyBuffer(indicator_handler,1,0,size,indicator_buffer_2); ArraySetAsSeries(indicator_buffer,true); ArraySetAsSeries(indicator_buffer_2,true); //--- File name string file_name = "Market Data " + Symbol() +" MACD " + ".csv"; //--- Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close","MACD Main","MACD Signal"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i), indicator_buffer[i], indicator_buffer_2[i] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
データ前処理
データをCSV形式でエクスポートしたので、Pythonワークスペースでデータを読み込みます。まず、必要なライブラリをロードします。
#Load libraries import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt
データを読み込みます。
#Read in the data data = pd.read_csv("Market Data EURUSD MACD .csv")
どのくらい先の将来を予測すべきかを定義します。
#Forecast horizon look_ahead = 20
EURUSDの終値とMACDメインラインの両方について、現在の値が直前の20インスタンスのいずれよりも大きい場合にフラグを立てるバイナリターゲットを追加してみましょう。
#Let's add labels data["Bull Bear"] = np.where(data["Close"] < data["Close"].shift(look_ahead),0,1) data["MACD Bull"] = np.where(data["MACD Main"] < data["MACD Main"].shift(look_ahead),0,1) data = data.loc[20:,:] data
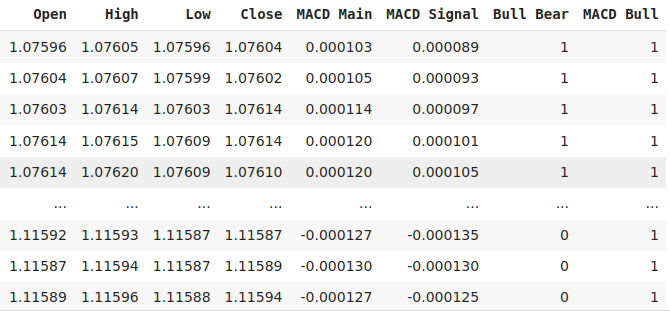
図3:データフレームの一部の列
さらに、目標値を定義する必要があります。
data["MACD Target"] = data["MACD Main"].shift(-look_ahead) data["Price Target"] = data["Close"].shift(-look_ahead) data["MACD Binary Target"] = np.where(data["MACD Main"] < data["MACD Target"],1,0) data["Price Binary Target"] = np.where(data["Close"] < data["Price Target"],1,0) data = data.iloc[:-20,:]
探索的データ分析
散布図は、従属変数と独立変数との関係を視覚的に捉えるために有効です。以下のグラフは、将来の価格レベルと現在のMACD読み取り値の間に確かな関係が存在することを示しています。しかし、課題となるのは、この関係が非線形であり、複雑な構造を持っているように見える点です。MACDインジケーターのどのような変化が強気または弱気の価格パフォーマンスにつながるのかは、直感的には理解しにくい状態です。
sns.scatterplot(data=data,x="MACD Main",y="MACD Signal",hue="Price Binary Target")
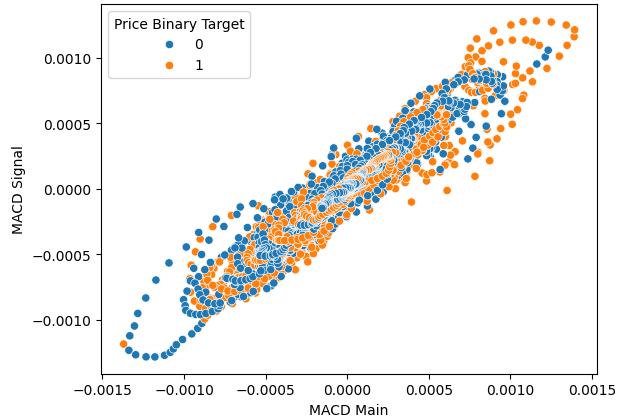
図4:MACDインジケーターと価格レベルの関係を視覚化する
3Dプロットを作成すると、この関係がいかに複雑であるかがさらに浮き彫りになります。明確な境界が存在しないため、データを分類することが難しいと予想されます。このプロットから導き出せる唯一の賢明な推論は、MACDが極端なレベルを通過した後、市場は迅速に中心付近に再び集まる傾向があるように見えるという点です。
#Define the 3D Plot fig = plt.figure(figsize=(7,7)) ax = plt.axes(projection="3d") ax.scatter(data["MACD Main"],data["MACD Signal"],data["Close"],c=data["Price Binary Target"]) ax.set_xlabel("MACD Main") ax.set_ylabel("MACD Signal") ax.set_zlabel("EURUSD Close")
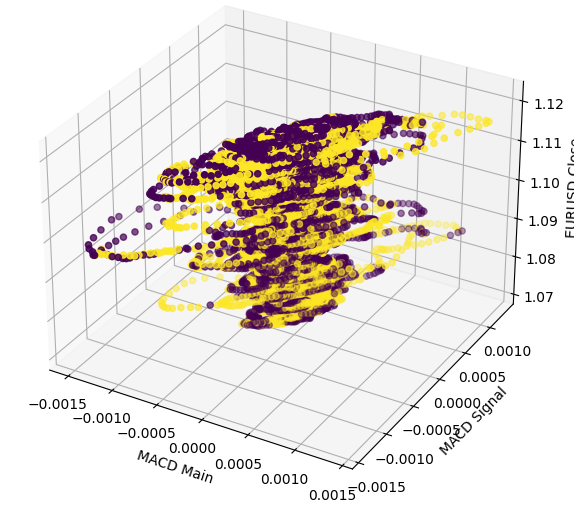
図5:MACDインジケーターとEURUSD市場の相互作用の視覚化
バイオリンプロットを使用すると、データの分布を視覚化しながら、2つの分布を同時に比較することが可能です。青いアウトラインは、MACDが上昇または下降した後における将来の価格レベルの観測分布の概要を示しています。図6では、MACDインジケーターの上昇または下降が、将来の価格変動に関連する分布にどのような違いをもたらすかを検証することを目的としていました。しかし、確認できるように、2つの分布はほとんど同一であるように見えます。さらに、それぞれの分布の中心には箱ひげ図が含まれています。インジケーターが強気か弱気かにかかわらず、両方の箱ひげ図の平均値はほぼ同じであることが確認されます。
sns.violinplot(data=data,x="MACD Bull",y="Close",hue="Price Binary Target",split=True,fill=False)
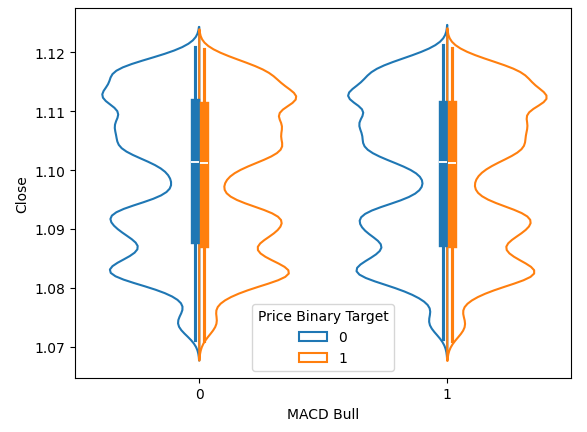
図6:MACDインジケーターが将来の価格レベルに与える影響の視覚化
データモデル化の準備
それでは、データのモデリングを始めましょう。まず最初に、ライブラリをインポートする必要があります。
#Perform train test splits from sklearn.model_selection import train_test_split,TimeSeriesSplit from sklearn.metrics import accuracy_score train,test = train_test_split(data,test_size=0.5,shuffle=False)
ここで、予測子とターゲットを定義します。
#Let's scale the data ohlc_predictors = ["Open","High","Low","Close","Bull Bear"] macd_predictors = ["MACD Main","MACD Signal","MACD Bull"] all_predictors = ohlc_predictors + macd_predictors cv_predictors = [ohlc_predictors,macd_predictors,all_predictors] #Define the targets cv_targets = ["MACD Binary Target","Price Binary Target","All"]
データをスケーリングします。
#Scaling the data
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(train[all_predictors])
train_scaled = pd.DataFrame(scaler.transform(train[all_predictors]),columns=all_predictors)
test_scaled = pd.DataFrame(scaler.transform(test[all_predictors]),columns=all_predictors) 必要なライブラリをロードします。
#Import the models we will evaluate
from sklearn.neural_network import MLPClassifier,MLPRegressor
from sklearn.linear_model import LinearRegression 時系列分割オブジェクトを作成します。
tscv = TimeSeriesSplit(n_splits=5,gap=look_ahead) データフレームのインデックスは、評価していた入力のセットにマップされます。
err_indexes = ["MACD Train","Price Train","All Train","MACD Test","Price Test","All Test"]
ここで、入力を変更する際のモデルの精度の推定値を記録するデータフレームを作成します。
#Now let us define a table to store our error levels columns = ["Model Accuracy"] cv_err = pd.DataFrame(columns=columns,index=err_indexes)
すべてのインデックスをリセットします。
#Reset index
train = train.reset_index(drop=True)
test = test.reset_index(drop=True) モデルを交差検証してみましょう。訓練セットでモデルを交差検証し、テストセットに適合させずにテストセットでその精度を記録します。
#Initailize the model price_model = MLPClassifier(hidden_layer_sizes=(10,6)) macd_model = MLPClassifier(hidden_layer_sizes=(10,6)) all_model = MLPClassifier(hidden_layer_sizes=(10,6)) price_acc = [] macd_acc = [] all_acc = [] #Cross validate each model twice for j,(train_index,test_index) in enumerate(tscv.split(train_scaled)): #Fit the models price_model.fit(train_scaled.loc[train_index,ohlc_predictors],train.loc[train_index,"Price Binary Target"]) macd_model.fit(train_scaled.loc[train_index,all_predictors],train.loc[train_index,"MACD Binary Target"]) all_model.fit(train_scaled.loc[train_index,all_predictors],train.loc[train_index,"Price Binary Target"]) #Store the accuracy price_acc.append(accuracy_score(train.loc[test_index,"Price Binary Target"],price_model.predict(train_scaled.loc[test_index,ohlc_predictors]))) macd_acc.append(accuracy_score(train.loc[test_index,cv_targets[0]],macd_model.predict(train_scaled.loc[test_index,all_predictors]))) all_acc.append(accuracy_score(train.loc[test_index,cv_targets[1]],all_model.predict(train_scaled.loc[test_index,all_predictors]))) #Now we can store our estimates of the model's error cv_err.iloc[0,0] = np.mean(price_acc) cv_err.iloc[1,0] = np.mean(macd_acc) cv_err.iloc[2,0] = np.mean(all_acc) #Estimating test error cv_err.iloc[3,0] = accuracy_score(test[cv_targets[1]],price_model.predict(test_scaled[ohlc_predictors])) cv_err.iloc[4,0] = accuracy_score(test[cv_targets[0]],macd_model.predict(test_scaled[all_predictors])) cv_err.iloc[5,0] = accuracy_score(test[cv_targets[1]],all_model.predict(test_scaled[all_predictors]))
| 入力グループ | モデルの精度 |
|---|---|
| MACD Train | 0.507129 |
| OHLC Train | 0.690267 |
| All Train | 0.504577 |
| MACD Test | 0.48669 |
| OHLC Test | 0.684069 |
| All Test | 0.487442 |
特徴量の重要性
次に、ディープニューラルネットワークの特徴量の重要度を推定してみましょう。モデルの解釈には、順列重要度を用います。順列重要度とは、まず入力列の値をシャッフルし、その後、モデルの精度の変化を評価することで各入力の重要度を測る手法です。重要な特徴量は、誤差の大幅な低下を引き起こし、一方で重要でない特徴量は、モデルの精度への影響がほぼゼロとなる、という考え方に基づいています。
ただし、いくつか留意すべき点があります。まず、順列重要度アルゴリズムは、モデルの各入力値をランダムにシャッフルします。これにより、例えば始値をシャッフルして高値よりも高く設定する、といった現実では起こり得ない状況が生成される可能性があります。したがって、アルゴリズムの結果を解釈する際には注意が必要です。このアルゴリズムは、現実には起こり得ないシミュレーション条件下で特徴量の重要性を評価するため、モデルに対して不必要なペナルティを与える可能性があり、ある種のバイアスがかかっていると言えるでしょう。さらに、現代のニューラルネットワークを訓練する際に使用される最適化アルゴリズムの確率的性質により、同じデータセットで同じニューラルネットワークを訓練した場合でも、生成される説明が毎回著しく異なる可能性があります。
#Let us try assess feature importance from sklearn.inspection import permutation_importance from sklearn.linear_model import RidgeClassifier
次に、順列重要度オブジェクトを訓練済みのディープニューラルネットワークモデルに適用します。この際、シャッフルするデータセットとして訓練データまたはテストデータを選択することができますが、私たちはテストデータを選択しました。その後、モデルの精度低下に基づいてデータを並べ替え、結果をプロットしました。以下の図7は、観測された順列重要度スコアを示しています。図からわかるように、MACDに関連する入力をシャッフルした際の効果はほぼ0に近い値を示しています。これは、MACDの列がモデルにとってそれほど重要な特徴量ではないことを意味しています。
#Let us fit the model model = MLPClassifier(hidden_layer_sizes=(10,6)) model.fit(train_scaled.loc[:,all_predictors],train.loc[:,"Price Binary Target"]) #Calculate permutation importance scores pi = permutation_importance( model, test_scaled.loc[:,all_predictors], test.loc[:,"Price Binary Target"], n_repeats=10, random_state=42, n_jobs=-1 ) #Sort the importance scores sorted_importances_idx = pi.importances_mean.argsort() importances = pd.DataFrame( pi.importances[sorted_importances_idx].T, columns=test_scaled.columns[sorted_importances_idx], ) #Create the plot ax = importances.plot.box(vert=False, whis=10) ax.set_title("Permutation Importances (test set)") ax.axvline(x=0, color="k", linestyle="--") ax.set_xlabel("Decrease in accuracy score") ax.figure.tight_layout()
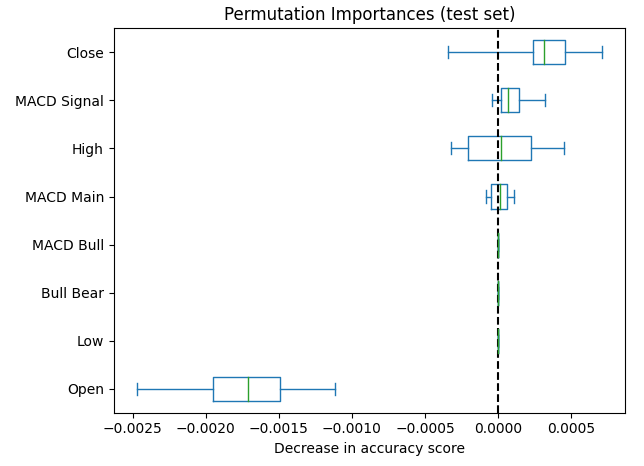
図7:順列重要度スコアは終値を最も重要な特徴としてランク付けした
より単純なモデルを使用することで、入力の重要度レベルに関する洞察も得られます。リッジ分類器は線形モデルの一種で、誤差を最小化する方向に係数を0に近づけていきます。そのため、データが標準化およびスケーリングされている場合、重要でない特徴は最小のリッジ係数を持つことになります。ご興味があればお伝えすると、リッジ分類器は通常の線形モデルにペナルティ項を追加することによってこの効果を実現しています。ペナルティ項は、モデル係数の二乗和に比例し、これはL2正則化として知られています。
#Let us fit the model model = RidgeClassifier() model.fit(train_scaled.loc[:,all_predictors],train.loc[:,"Price Binary Target"])
次に、モデルの係数をプロットしてみましょう。
ridge_importance = pd.DataFrame(model.coef_.tolist(),columns=all_predictors) #Prepare the plot fig,ax = plt.subplots(figsize=(10,5)) sns.barplot(ridge_importance,ax=ax)
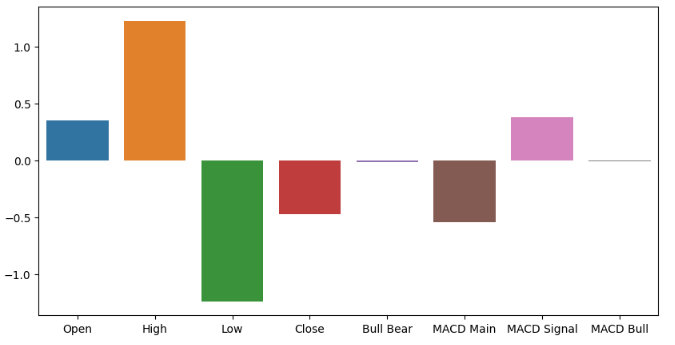
図8:リッジ係数は、高値と安値が我々が持つ最も有益な特徴量であることを示唆しています。
パラメータ調整
最高のパフォーマンスを発揮するモデルを最適化してみましょう。しかし、前述したように、このターンでは最適化ルーチンはうまくいきませんでした。残念ながら、これは最適化アルゴリズムの性質に起因するもので、解決策が必ず見つかるわけではありません。パラメータの最適化をおこなったとしても、最終的に得られるモデルが必ずしもより良くなるとは限りません。私たちは最適なモデルパラメータを近似することを試みているに過ぎません。必要なライブラリをロードします。
#Let's tune our model further from sklearn.model_selection import RandomizedSearchCV
モデルを定義します。
#Reinitialize the model model = MLPRegressor(max_iter=200)
ここで、チューナーオブジェクトを定義します。オブジェクトは、さまざまな初期化パラメータでモデルを評価し、見つかった最もパフォーマンスの高い入力を含むオブジェクトを返します。
#Define the tuner
tuner = RandomizedSearchCV(
model,
{
"activation" : ["relu","logistic","tanh","identity"],
"solver":["adam","sgd","lbfgs"],
"alpha":[0.1,0.01,0.001,0.0001,0.00001,0.00001,0.0000001],
"tol":[0.1,0.01,0.001,0.0001,0.00001,0.000001,0.0000001],
"learning_rate":['constant','adaptive','invscaling'],
"learning_rate_init":[0.1,0.01,0.001,0.0001,0.00001,0.000001,0.0000001],
"hidden_layer_sizes":[(2,4,8,2),(10,20),(5,10),(2,20),(6,8,10),(1,5),(20,10),(8,4),(2,4,8),(10,5)],
"early_stopping":[True,False],
"warm_start":[True,False],
"shuffle": [True,False]
},
n_iter=100,
cv=5,
n_jobs=-1,
scoring="neg_mean_squared_error"
) チューナーオブジェクトを適合します。
tuner.fit(train.loc[:,ohlc_predictors],train.loc[:,"Price Target"]) 以下が、見つかった最高のパラメータです。
tuner.best_params_
'tol':0.01,
'solver': 'sgd',
'shuffle':False,
'learning_rate_init':0.01,
'learning_rate': 'constant',
'hidden_layer_sizes':(20, 10),
'early_stopping':True,
'alpha':1e-07,
'activation': 'identity'}
より深い最適化
SciPyライブラリを使用することで、より良い入力設定をさらに深く探求することができます。 このライブラリを使用して、モデルの連続的なパラメータに対する大域的最適化の結果を推定します。#Deeper optimization from scipy.optimize import minimize from sklearn.metrics import mean_squared_error from sklearn.model_selection import TimeSeriesSplit
時系列分割オブジェクトを定義します。
#Define the time series split object tscv = TimeSeriesSplit(n_splits=5,gap=look_ahead)
精度レベルを保存するためのデータ構造を作成します。
#Create a dataframe to store our accuracy current_error_rate = pd.DataFrame(index = np.arange(0,5),columns=["Current Error"]) algorithm_progress = []
最小化されるコスト関数は、訓練データにおけるモデルの誤差レベルになります。
#Define the objective function def objective(x): #The parameter x represents a new value for our neural network's settings model = MLPRegressor(hidden_layer_sizes=tuner.best_params_["hidden_layer_sizes"], early_stopping=tuner.best_params_["early_stopping"], warm_start=tuner.best_params_["warm_start"], max_iter=500, activation=tuner.best_params_["activation"], learning_rate=tuner.best_params_["learning_rate"], solver=tuner.best_params_["solver"], shuffle=tuner.best_params_["shuffle"], alpha=x[0], tol=x[1], learning_rate_init=x[2] ) #Now we will cross validate the model for i,(train_index,test_index) in enumerate(tscv.split(train)): #Train the model model.fit(train.loc[train_index,ohlc_predictors],train.loc[train_index,"Price Target"]) #Measure the RMSE current_error_rate.iloc[i,0] = mean_squared_error(train.loc[test_index,"Price Target"],model.predict(train.loc[test_index,ohlc_predictors])) #Store the algorithm's progress algorithm_progress.append(current_error_rate.iloc[:,0].mean()) #Return the Mean CV RMSE return(current_error_rate.iloc[:,0].mean())
SciPyでは、最適化手順を開始するために初期値を指定することが求められます。
#Define the starting point pt = [tuner.best_params_["alpha"],tuner.best_params_["tol"],tuner.best_params_["learning_rate_init"]] bnds = ((10.00 ** -100,10.00 ** 100), (10.00 ** -100,10.00 ** 100), (10.00 ** -100,10.00 ** 100))
それでは、モデルを最適化してみましょう。
#Searching deeper for parameters result = minimize(objective,pt,method="L-BFGS-B",bounds=bnds)
アルゴリズムはなんとか収束したようです。これは、変動がほとんどない安定した入力が見つかったことを意味します。したがって、誤差レベルの変化が0に近づいていたため、これより良い解決策は存在しないという結論に達しました。
#The result of our optimization
result success:True
status:0
fun:3.730365831424036e-06
x: [ 9.939e-08 9.999e-03 9.999e-03]
nit:3
jac: [-7.896e+01 -1.133e+02 1.439e+03]
nfev:100
njev:25
hess_inv: <3x3 LbfgsInvHessProduct with dtype=float64>
手順を視覚化してみましょう。
#Store the optimal coefficients optimal_weights = result.x optima_y = min(algorithm_progress) optima_x = algorithm_progress.index(optima_y) inputs = np.arange(0,len(algorithm_progress)) #Plot the performance of our optimization procedure plt.scatter(inputs,algorithm_progress) plt.plot(optima_x,optima_y,'ro',color='r') plt.axvline(x=optima_x,ls='--',color='red') plt.axhline(y=optima_y,ls='--',color='red') plt.xlabel("Iterations") plt.ylabel("Training MSE") plt.title("Minimizing Training Error")
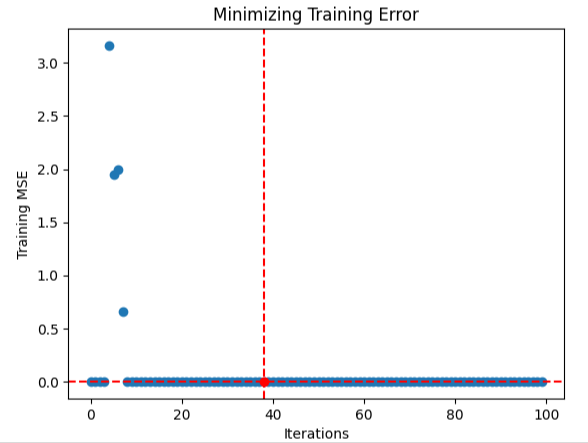
図9:ディープニューラルネットワークの最適化の視覚化
過剰適合のテスト
過剰適合は、モデルが与えられたデータから意味のない表現を学習するという望ましくない効果です。この状態のモデルは、精度が低くなるため望ましくありません。モデルが過剰適合しているかどうかは、弱い学習者や、類似のニューラルネットワークのデフォルトインスタンスと比較することでわかります。もしモデルがノイズを学習し、データ内の信号を捉えられていない場合、そのモデルは弱い学習者にパフォーマンスで負けることになります。しかし、たとえモデルが弱い学習者よりも優れたパフォーマンスを発揮しても、過剰適合している可能性は残ります。
#Testing for overfitting #Benchmark benchmark = LinearRegression() #Default default_nn = MLPRegressor(max_iter=500) #Randomized NN random_search_nn = MLPRegressor(hidden_layer_sizes=tuner.best_params_["hidden_layer_sizes"], early_stopping=tuner.best_params_["early_stopping"], warm_start=tuner.best_params_["warm_start"], max_iter=500, activation=tuner.best_params_["activation"], learning_rate=tuner.best_params_["learning_rate"], solver=tuner.best_params_["solver"], shuffle=tuner.best_params_["shuffle"], alpha=tuner.best_params_["alpha"], tol=tuner.best_params_["tol"], learning_rate_init=tuner.best_params_["learning_rate_init"] ) #LBFGS NN lbfgs_nn = MLPRegressor(hidden_layer_sizes=tuner.best_params_["hidden_layer_sizes"], early_stopping=tuner.best_params_["early_stopping"], warm_start=tuner.best_params_["warm_start"], max_iter=500, activation=tuner.best_params_["activation"], learning_rate=tuner.best_params_["learning_rate"], solver=tuner.best_params_["solver"], shuffle=tuner.best_params_["shuffle"], alpha=result.x[0], tol=result.x[1], learning_rate_init=result.x[2] )
モデルを適合させ、その精度を評価します。パフォーマンスに明らかな差が見られ、線形回帰モデルはすべてのディープニューラルネットワークを上回っていました。そこで、代わりに線形SVMを適合させてみました。ニューラルネットワークよりも優れたパフォーマンスを発揮しましたが、線形回帰モデルを上回ることはできませんでした。
#Fit the models on the training sets benchmark = LinearRegression() benchmark.fit(((train.loc[:,ohlc_predictors])),train.loc[:,"Price Target"]) mean_squared_error(test.loc[:,"Price Target"],benchmark.predict(((test.loc[:,ohlc_predictors])))) #Test the default default_nn.fit(train.loc[:,ohlc_predictors],train.loc[:,"Price Target"]) mean_squared_error(test.loc[:,"Price Target"],default_nn.predict(test.loc[:,ohlc_predictors])) #Test the random search random_search_nn.fit(train.loc[:,ohlc_predictors],train.loc[:,"Price Target"]) mean_squared_error(test.loc[:,"Price Target"],random_search_nn.predict(test.loc[:,ohlc_predictors])) #Test the lbfgs nn lbfgs_nn.fit(train.loc[:,ohlc_predictors],train.loc[:,"Price Target"]) mean_squared_error(test.loc[:,"Price Target"],lbfgs_nn.predict(test.loc[:,ohlc_predictors])
| 線形回帰 | デフォルトNN | ランダムサーチ | LBFGS NN |
|---|---|---|---|
| 2.609826e-07 | 1.996431e-05 | 0.00051 | 0.000398 |
LinearSVRを適合させてみましょう。データ内の非線形相互作用を検出する可能性が高くなります。
#From experience, I'll try LSVR from sklearn.svm import LinearSVR
モデルを初期化し、保有するすべてのデータに適合させます。SVRの誤差レベルはニューラルネットワークよりは優れていますが、線形回帰ほど優れていないことがわかります。
#Initialize the model lsvr = LinearSVR() #Fit the Linear Support Vector lsvr.fit(train.loc[:,["Open","High","Low","Close"]],train.loc[:,"Price Target"]) mean_squared_error(test.loc[:,"Price Target"],lsvr.predict(test.loc[:,["Open","High","Low","Close"]]))
ONNXへのエクスポート
Open Neural Network Exchange (ONNX)を使用すると、1つの言語で機械学習モデルを作成し、それをONNX APIをサポートする他の言語と共有できます。ONNXプロトコルにより、機械学習を活用できる環境の数が急速に変化しています。ONNXを使用すると、AIをMQL5 EAにシームレスに統合できます。
#Let's export the LSVR to ONNX import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
モデルの新しいインスタンスを作成します。
model = LinearSVR()
保有するすべてのデータにモデルを適合させます。
model.fit(data.loc[:,["Open","High","Low","Close"]],data.loc[:,"Price Target"])
モデルの入力形状を定義します。
#Define the input type initial_types = [("float_input",FloatTensorType([1,4]))]
モデルのONNX表現を作成します。
#Create the ONNX representation onnx_model = convert_sklearn(model,initial_types=initial_types,target_opset=12)
ONNXモデルを保存します。
# Save the ONNX model onnx.save_model(onnx_model,"EURUSD SVR M1.onnx")

図10:ONNXモデルの視覚化
MQL5での実装
これで、MQL5で戦略の実装を開始できます。価格が移動平均を上回り、AIが価格が上昇すると予測したときに購入するアプリケーションを構築したいと考えています。
アプリケーションを開始するには、まず、作成したONNXファイルをEAに含めます。
//+--------------------------------------------------------------+ //| EURUSD AI | //+--------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://metaquotes.com/ja/users/gamuchiraindawa" #property version "2.1" #property description "Supports M1" //+--------------------------------------------------------------+ //| Resources we need | //+--------------------------------------------------------------+ #resource "\\Files\\EURUSD SVR M1.onnx" as const uchar onnx_buffer[];
次に、取引ライブラリをロードします。
//+--------------------------------------------------------------+ //| Libraries | //+--------------------------------------------------------------+ #include <Trade\Trade.mqh> CTrade trade;
これから変更される定数をいくつか定義します。
//+--------------------------------------------------------------+ //| Constants | //+--------------------------------------------------------------+ const double stop_percent = 1; const int ma_period_shift = 0;
テクニカルインジケーターのパラメータとプログラムの一般的な動作をユーザーが制御できるようにします。
//+--------------------------------------------------------------+ //| User inputs | //+--------------------------------------------------------------+ input group "TAs" input double atr_multiple =2.5; //How wide should the stop loss be? input int atr_period = 200; //ATR Period input int ma_period = 1000; //Moving average period input group "Risk" input double risk_percentage= 0.02; //Risk percentage (0.01 - 1) input double profit_target = 1.0; //Profit target
ここで、必要なグローバル変数をすべて定義しましょう。
//+--------------------------------------------------------------+ //| Global variables | //+--------------------------------------------------------------+ double position_size = 2; int lot_multiplier = 1; bool buy_break_even_setup = false; bool sell_break_even_setup = false; double up_level = 0.03; double down_level = -0.03; double min_volume,max_volume_increase, volume_step, buy_stop_loss, sell_stop_loss,ask, bid,atr_stop,mid_point,risk_equity; double take_profit = 0; double close_price[3]; double moving_average_low_array[],close_average_reading[],moving_average_high_array[],atr_reading[]; long min_distance,login; int ma_high,ma_low,atr,close_average; bool authorized = false; double tick_value,average_market_move,margin,mid_point_height,channel_width,lot_step; string currency,server; bool all_closed =true; long onnx_model; vectorf onnx_output = vectorf::Zeros(1); ENUM_ACCOUNT_TRADE_MODE account_type;
EAは、まずユーザーが口座の取引に対してEAを有効にしているかどうかを確認し、次にONNXモデルの読み込みを試行し、ここまでの作業が成功した場合は、テクニカルインジケーターを読み込みます。
//+------------------------------------------------------------------+ //| On initialization | //+------------------------------------------------------------------+ int OnInit() { //--- Authorization if(!auth()) { return(INIT_FAILED); } //--- Load the ONNX model if(!load_onnx()) { return(INIT_FAILED); } //--- Everything went fine else { load(); return(INIT_SUCCEEDED); } }
EAが使用されていない場合は、ONNXモデルに割り当てられたメモリを解放します。
//+------------------------------------------------------------------+ //| On deinitialization | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { OnnxRelease(onnx_model); }更新された価格フィードを受信するたびに、グローバル市場変数を更新し、ポジションがない場合は取引シグナルを確認します。それ以外の場合は、トレーリングストップロスを更新します。
//+------------------------------------------------------------------+ //| On every tick | //+------------------------------------------------------------------+ void OnTick() { //On Every Function Call update(); static datetime time_stamp; datetime time = iTime(_Symbol,PERIOD_CURRENT,0); Comment("AI Forecast: ",onnx_output[0]); //On Every Candle if(time_stamp != time) { //Mark the candle time_stamp = time; OrderCalcMargin(ORDER_TYPE_BUY,_Symbol,min_volume,ask,margin); calculate_lot_size(); if(PositionsTotal() == 0) { check_signal(); } } //--- If we have positions, manage them. if(PositionsTotal() > 0) { check_atr_stop(); check_profit(); } } //+------------------------------------------------------------------+ //| Check if we have any valid setups, and execute them | //+------------------------------------------------------------------+ void check_signal(void) { //--- Get a prediction from our model model_predict(); if(onnx_output[0] > iClose(Symbol(),PERIOD_CURRENT,0)) { if(above_channel()) { check_buy(); } } else if(below_channel()) { if(onnx_output[0] < iClose(Symbol(),PERIOD_CURRENT,0)) { check_sell(); } } }
この関数は、すべてのグローバル市場変数を更新する役割を担います。
//+------------------------------------------------------------------+ //| Update our global variables | //+------------------------------------------------------------------+ void update(void) { //--- Important details that need to be updated everytick ask = SymbolInfoDouble(_Symbol,SYMBOL_ASK); bid = SymbolInfoDouble(_Symbol,SYMBOL_BID); buy_stop_loss = 0; sell_stop_loss = 0; check_price(3); CopyBuffer(ma_high,0,0,1,moving_average_high_array); CopyBuffer(ma_low,0,0,1,moving_average_low_array); CopyBuffer(atr,0,0,1,atr_reading); ArraySetAsSeries(moving_average_high_array,true); ArraySetAsSeries(moving_average_low_array,true); ArraySetAsSeries(atr_reading,true); risk_equity = AccountInfoDouble(ACCOUNT_BALANCE) * risk_percentage; atr_stop = (((min_distance + (atr_reading[0]* 1e5) * atr_multiple) * _Point)); mid_point = (moving_average_high_array[0] + moving_average_low_array[0]) / 2; mid_point_height = close_price[0] - mid_point; channel_width = moving_average_high_array[0] - moving_average_low_array[0]; }
ここで、アプリケーションの実行が許可されていることを確認する関数を定義する必要があります。実行が許可されていない場合、関数はユーザーに何をすべきかを指示し、初期化を停止するfalseを返します。
//+------------------------------------------------------------------+ //| Check if the EA is allowed to be run | //+------------------------------------------------------------------+ bool auth(void) { if(!TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { Comment("Press Ctrl + E To Give The Robot Permission To Trade And Reload The Program"); return(false); } else if(!MQLInfoInteger(MQL_TRADE_ALLOWED)) { Comment("Reload The Program And Make Sure You Clicked Allow Algo Trading"); return(false); } return(true); }
初期化中に、すべてのテクニカルインジケーターを読み込み、重要な市場の詳細を取得する関数が必要です。load関数はまさにそれを実行し、グローバル変数を参照しているため、戻り値の型はvoidになります。
//+---------------------------------------------------------------------+ //| Load our needed variables | //+---------------------------------------------------------------------+ void load(void) { //Account Info currency = AccountInfoString(ACCOUNT_CURRENCY); server = AccountInfoString(ACCOUNT_SERVER); login = AccountInfoInteger(ACCOUNT_LOGIN); //Indicators atr = iATR(_Symbol,PERIOD_CURRENT,atr_period); ma_high = iMA(_Symbol,PERIOD_CURRENT,ma_period,ma_period_shift,MODE_EMA,PRICE_HIGH); ma_low = iMA(_Symbol,PERIOD_CURRENT,ma_period,ma_period_shift,MODE_EMA,PRICE_LOW); //Market Information min_volume = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_MIN); max_volume_increase = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_MAX) / SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_MIN); min_distance = SymbolInfoInteger(_Symbol,SYMBOL_TRADE_STOPS_LEVEL); tick_value = SymbolInfoDouble(_Symbol,SYMBOL_TRADE_TICK_VALUE_PROFIT) * min_volume; lot_step = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_STEP); average_market_move = NormalizeDouble(10000 * tick_value,_Digits); }
一方、ONNXモデルは別の関数呼び出しによって読み込まれます。この関数は、先ほど定義したバッファからONNXモデルを作成し、入力と出力の形状を検証します。
//+------------------------------------------------------------------+ //| Load our ONNX model | //+------------------------------------------------------------------+ bool load_onnx(void) { onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); ulong onnx_input [] = {1,4}; ulong onnx_output[] = {1,1}; if(!OnnxSetInputShape(onnx_model,0,onnx_input)) { Comment("[INTERNAL ERROR] Failed to load AI modules. Relode the EA."); return(false); } if(!OnnxSetOutputShape(onnx_model,0,onnx_output)) { Comment("[INTERNAL ERROR] Failed to load AI modules. Relode the EA."); return(false); } return(true); }
ここで、モデルから予測を取得する関数を定義しましょう。
//+------------------------------------------------------------------+ //| Get a prediction from our model | //+------------------------------------------------------------------+ void model_predict(void) { vectorf onnx_inputs = {iOpen(Symbol(),PERIOD_CURRENT,0),iHigh(Symbol(),PERIOD_CURRENT,0),iLow(Symbol(),PERIOD_CURRENT,0),iClose(Symbol(),PERIOD_CURRENT,0)}; OnnxRun(onnx_model,ONNX_DEFAULT,onnx_inputs,onnx_output); }
ストップロスはATR値によって調整されます。現在の取引が買い取引か売り取引かによって、現在のATR値を加算してストップロスを上げるか、または現在のATR値を減算してストップロスを下げるかを判断する主な決定要因になります。また、現在のATR値の倍数を使用して、ユーザーがリスクレベルをより細かく制御できるようにすることもできます。
//+------------------------------------------------------------------+ //| Update the ATR stop loss | //+------------------------------------------------------------------+ void check_atr_stop() { for(int i = PositionsTotal() -1; i >= 0; i--) { string symbol = PositionGetSymbol(i); if(_Symbol == symbol) { ulong ticket = PositionGetInteger(POSITION_TICKET); double position_price = PositionGetDouble(POSITION_PRICE_OPEN); double type = PositionGetInteger(POSITION_TYPE); double current_stop_loss = PositionGetDouble(POSITION_SL); if(type == POSITION_TYPE_BUY) { double atr_stop_loss = (ask - (atr_stop)); double atr_take_profit = (ask + (atr_stop)); if((current_stop_loss < atr_stop_loss) || (current_stop_loss == 0)) { trade.PositionModify(ticket,atr_stop_loss,atr_take_profit); } } else if(type == POSITION_TYPE_SELL) { double atr_stop_loss = (bid + (atr_stop)); double atr_take_profit = (bid - (atr_stop)); if((current_stop_loss > atr_stop_loss) || (current_stop_loss == 0)) { trade.PositionModify(ticket,atr_stop_loss,atr_take_profit); } } } } }
最後に、買いポジションと売りポジションを開くための2つの関数と、ポジションを閉じるためのそれらの補完ペアを定義する必要があります。
//+------------------------------------------------------------------+ //| Open buy positions | //+------------------------------------------------------------------+ void check_buy() { if(PositionsTotal() == 0) { for(int i=0; i < position_size;i++) { trade.Buy(min_volume * lot_multiplier,_Symbol,ask,buy_stop_loss,0,"BUY"); Print("Position: ",i," has been setup"); } } } //+------------------------------------------------------------------+ //| Open sell positions | //+------------------------------------------------------------------+ void check_sell() { if(PositionsTotal() == 0) { for(int i=0; i < position_size;i++) { trade.Sell(min_volume * lot_multiplier,_Symbol,bid,sell_stop_loss,0,"SELL"); Print("Position: ",i," has been setup"); } } } //+------------------------------------------------------------------+ //| Close all buy positions | //+------------------------------------------------------------------+ void close_buy() { ulong ticket; int type; if(PositionsTotal() > 0) { for(int i = 0; i < PositionsTotal();i++) { if(PositionGetSymbol(i) == _Symbol) { ticket = PositionGetTicket(i); type = (int)PositionGetInteger(POSITION_TYPE); if(type == POSITION_TYPE_BUY) { trade.PositionClose(ticket); } } } } } //+------------------------------------------------------------------+ //| Close all sell positions | //+------------------------------------------------------------------+ void close_sell() { ulong ticket; int type; if(PositionsTotal() > 0) { for(int i = 0; i < PositionsTotal();i++) { if(PositionGetSymbol(i) == _Symbol) { ticket = PositionGetTicket(i); type = (int)PositionGetInteger(POSITION_TYPE); if(type == POSITION_TYPE_SELL) { trade.PositionClose(ticket); } } } } }
過去3つの価格レベルを追跡してみましょう。
//+------------------------------------------------------------------+ //| Get the last 3 quotes | //+------------------------------------------------------------------+ void check_price(int candles) { for(int i = 0; i < candles;i++) { close_price[i] = iClose(_Symbol,PERIOD_CURRENT,i); } }
このブールチェックは、移動平均を上回っている場合にtrueを返します。
//+------------------------------------------------------------------+ //| Are we completely above the MA? | //+------------------------------------------------------------------+ bool above_channel() { return (((close_price[0] - moving_average_high_array[0] > 0)) && ((close_price[0] - moving_average_low_array[0]) > 0)); }
移動平均を下回っているかどうかを確認します。
//+------------------------------------------------------------------+ //| Are we completely below the MA? | //+------------------------------------------------------------------+ bool below_channel() { return(((close_price[0] - moving_average_high_array[0]) < 0) && ((close_price[0] - moving_average_low_array[0]) < 0)); }
保有しているポジションをすべてクローズします。
//+------------------------------------------------------------------+ //| Close all positions we have | //+------------------------------------------------------------------+ void close_all() { if(PositionsTotal() > 0) { ulong ticket; for(int i =0;i < PositionsTotal();i++) { ticket = PositionGetTicket(i); trade.PositionClose(ticket); } } }
証拠金がリスクを負う資本の額と等しくなるように、使用する最適なロットサイズを計算します。
//+------------------------------------------------------------------+ //| Calculate the lot size to be used | //+------------------------------------------------------------------+ void calculate_lot_size() { //--- This is the total percentage of the account we're willing to part with for margin, or to keep a position open in other words. Print("Risk Equity: ",risk_equity); //--- Now that we're ready to part with a discrete amount for margin, how many positions can we afford under the current lot size? //--- By default we always start from minimum lot position_size = risk_equity / margin; //--- We need to keep the number of positions lower than 10 if(position_size > 10) { //--- How many times is it greater than 10? int estimated_lot_size = (int) MathFloor(position_size / 10); position_size = risk_equity / (margin * estimated_lot_size); Print("Position Size After Dividing By margin at new estimated lot size: ",position_size); int estimated_position_size = position_size; //--- Can we increase the lot size this many times? if(estimated_lot_size < max_volume_increase) { Print("Est Lot Size: ",estimated_lot_size," Position Size: ",estimated_position_size); lot_multiplier = estimated_lot_size; position_size = estimated_position_size; } } }
ポジションをクローズし、再度取引できるかどうかを確認します。
//--- This function will help us keep track of which side we need to enter the market void close_all_and_enter() { if(PositionSelect(Symbol())) { // Determine the type of position check_signal(); } else { Print("No open position found."); } }
利益目標に到達した場合は、利益を実現するために保有するポジションをすべてクローズし、再度エントリーできるかどうかを確認します。
//+------------------------------------------------------------------+ //| Chekc if we have reached our profit target | //+------------------------------------------------------------------+ void check_profit() { double current_profit = (AccountInfoDouble(ACCOUNT_EQUITY) - AccountInfoDouble(ACCOUNT_BALANCE)) / PositionsTotal(); if(current_profit > profit_target) { close_all_and_enter(); } if((current_profit * PositionsTotal()) < (risk_equity * -1)) { Comment("We've breached our risk equity, consider closing all positions"); } }
最後に、利益のない取引をすべてクローズする関数が必要です。
//+------------------------------------------------------------------+ //| Close all losing trades | //+------------------------------------------------------------------+ void close_profitable_trades() { for(int i=PositionsTotal()-1; i>=0; i--) { if(PositionSelectByTicket(PositionGetTicket(i))) { if(PositionGetDouble(POSITION_PROFIT)>profit_target) { ulong ticket; ticket = PositionGetTicket(i); trade.PositionClose(ticket); } } } } //+------------------------------------------------------------------+
図11:EA
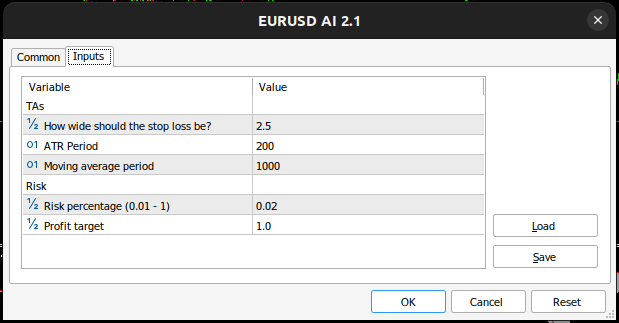
図12:アプリケーションテストに使用するパラメータ
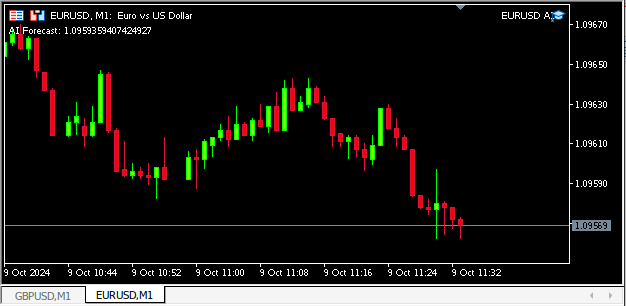
図13:アプリケーションの動作
結論
私たちの結果は期待に沿うものではありませんでしたが、まだ結論を出すには早すぎます。MACDインジケーターの解釈には他にも方法があり、それらを評価する価値があるかもしれません。たとえば、強気トレンドではMACDシグナルラインがメインラインを上回り、弱気トレンドではシグナルラインがメインラインを下回ります。この視点からインジケーターを見た場合、異なるエラーメトリックが得られる可能性があります。すべてのMACD解釈法で一貫したエラーレベルが得られると単純に考えるのは間違いです。MACDの有効性について意見を形成する前に、さまざまな解釈戦略をサンプルとして評価することが合理的です。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/16066
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索