
データサイエンスと機械学習(第16回):決定木を見直す

簡単な総括
この連載で決定木についての記事を書きました。決定木とはどういうものかを説明し、気象データを分類するためのアルゴリズムを構築しました。しかし、記事で提供したコードと説明は十分に簡潔ではありませんでした。決定木を構築するためのより良いアプローチを提供してほしいという要望を受け続けているので、2つ目の記事を書き、決定木のためのより良いコードを提供した方が良いのではないかと考えています。決定木を明確にすることで、まもなくお話しするランダムフォレストアルゴリズムを理解しやすくなるでしょう。
決定木について
決定木はフローチャートのような木構造で、各内部ノードは属性(または特徴)のテストを表し、各分岐はテストの結果を表し、各葉(リーフ)ノードはクラスラベルまたは連続値を表します。決定木の一番上のノードは「根(ルート)」と呼ばれ、葉は結果または予測です。
ノードについて
決定木では、ノードは特定の特徴や属性に基づく決定点を表す基本要素です。決定木のノードには、内部ノードと葉ノードの2つのタイプがあります。
内部ノード- 内部ノードとは、特定の特徴ーに対してテストが実行される木内の決定点です。このテストは、特徴量が閾値より大きいか、特定のカテゴリに属するかといった特定の条件に依存します。
- 内部ノードには、子ノードにつながる枝(エッジ)があります。テストの結果によって、どの分岐をたどるかが決まります。
- 内部ノードは左右2つの子ノードで、中央の木ノード内部のノードです。
- 葉ノードは、最終的な決定や予測をおこなう木の終点を示します。分類タスクではクラスラベル、回帰タスクでは予測値を表します。
- 葉ノードは出て行く枝を持たず、決定プロセスの終点です。
- これをdouble変数としてコード化します。
class Node { public: // for decision node uint feature_index; double threshold; double info_gain; // for leaf node double leaf_value; Node *left_child; //left child Node Node *right_child; //right child Node Node() : left_child(NULL), right_child(NULL) {} // default constructor Node(uint feature_index_, double threshold_=NULL, Node *left_=NULL, Node *right_=NULL, double info_gain_=NULL, double value_=NULL) : left_child(left_), right_child(right_) { this.feature_index = feature_index_; this.threshold = threshold_; this.info_gain = info_gain_; this.value = value_; } void Print() { printf("feature_index: %d \nthreshold: %f \ninfo_gain: %f \nleaf_value: %f",feature_index,threshold, info_gain, value); } };
この連載でゼロからコーディングしてきたいくつかのMLアルゴリズムとは異なり、決定木はコーディングが厄介で、混乱することもあります。うまく実装するには再帰的なクラスと関数が必要になるからです。私の経験によれば、Python以外の言語でコーディングするのは難しいかもしれません。
ノードの構成要素
決定木のノードには通常、以下の情報が含まれます。
01.テスト条件
内部ノードには、特定の特徴と閾値またはカテゴリに基づくテスト条件があります。この条件によって、データがどのように子ノードに分割されるかが決まります。
Node *build_tree(matrix &data, uint curr_depth=0);
02.特徴と閾値
ノードでテストされる機能と、分割に使用される閾値またはカテゴリを示します。
uint feature_index; double threshold;
03.クラスラベルまたは値
葉ノードには、予測されたクラスラベル(分類の場合)または値(回帰の場合)が格納されます。
double leaf_value; 04.子ノード
内部ノードは、テスト条件のさまざまな結果に対応する子ノードを持ちます。各子ノードは、条件を満たすデータのサブセットを表します。
Node *left_child; //left child Node Node *right_child; //right child Node
例
果物の色からリンゴかオレンジかを分類する単純な決定木を考えてみましょう。
[ノード]
特徴:カラー
テスト条件:色は赤か?
trueなら左の子へ、falseなら右の子へ
[葉ノード-リンゴ]
-クラスのラベル:Apple
[葉ノード-オレンジ]
-クラスのラベル:Orange
決定木の種類:
CART(C&Rツリー、Classification and Regression Trees):分類と回帰の両方のタスクに使用されます。分類ではジニ不純物、回帰では平均二乗誤差に基づいてデータを分割します。
ID3 (Iterative Dichotomiser 3):主に分類作業に使用されます。エントロピーと情報利得の概念を用いて意思決定をおこないます。
C4.5:分類にはID3の改良版であるC4.5が使われます。よりレベルの高い属性への偏りに対処するため、ゲインレシオを採用しています。
分類の目的で決定木を使用することを検討しているので、情報利得、不純物計算、カテゴリ特徴を特徴とするID3アルゴリズムを構築することを検討することになります。
ID3 (Iterative Dichotomiser 3)
ID3は、情報利得を使って、各内部ノードでどの機能で分割するかを決定します。情報利得は、データセットを分割した後のエントロピーまたは不確実性の減少を測定します。double CDecisionTree::information_gain(vector &parent, vector &left_child, vector &right_child) { double weight_left = left_child.Size() / (double)parent.Size(), weight_right = right_child.Size() / (double)parent.Size(); double gain =0; switch(m_mode) { case MODE_GINI: gain = gini_index(parent) - ( (weight_left*gini_index(left_child)) + (weight_right*gini_index(right_child)) ); break; case MODE_ENTROPY: gain = entropy(parent) - ( (weight_left*entropy(left_child)) + (weight_right*entropy(right_child)) ); break; } return gain; }
エントロピーとは、データセットの不確実性や無秩序さを表す尺度です。ID3では、アルゴリズムは、より均質なクラスラベルを持つ部分集合をもたらす特徴分割を選択することによって、エントロピーを削減しようとします。
double CDecisionTree::entropy(vector &y) { vector class_labels = matrix_utils.Unique_count(y); vector p_cls = class_labels / double(y.Size()); vector entropy = (-1 * p_cls) * log2(p_cls); return entropy.Sum(); }
より柔軟性を持たせるために、エントロピーとジニ指数のどちらかを選ぶことができます。ジニ指数も決定木でよく使われる関数で、エントロピー関数と同じ働きをします。どちらもデータセットの不純物や乱れを評価します。
double CDecisionTree::gini_index(vector &y) { vector unique = matrix_utils.Unique_count(y); vector probabilities = unique / (double)y.Size(); return 1.0 - MathPow(probabilities, 2).Sum(); }
下の画像の式で与えられます。
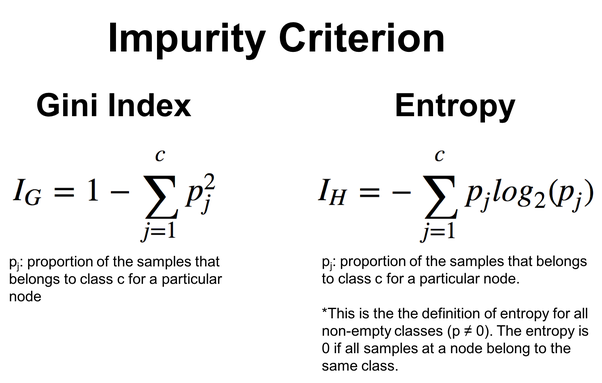
ID3は特にカテゴリ特徴量に適しており、特徴量と閾値の選択はカテゴリ分割のエントロピー削減に基づいています。以下、決定木アルゴリズムでこれを実際に見てみましょう。
決定木アルゴリズム
01.分割基準
分類では、標準的な分割基準はジニ不純物とエントロピーであり、回帰では平均二乗誤差がよく使われます。決定木アルゴリズムの分割機能を掘り下げてみましょう。分割されるデータの情報を保持する構造から始まります。
//A struct containing splitted data information struct split_info { uint feature_index; double threshold; matrix dataset_left, dataset_right; double info_gain; };
閾値を使って、閾値より小さい値を持つ特徴量を行列dataset_leftに分割し、残りを行列dataset_rightに残します。最後に、split_info構造体のインスタンスが返されます。
split_info CDecisionTree::split_data(const matrix &data, uint feature_index, double threshold=0.5) { int left_size=0, right_size =0; vector row = {}; split_info split; ulong cols = data.Cols(); split.dataset_left.Resize(0, cols); split.dataset_right.Resize(0, cols); for (ulong i=0; i<data.Rows(); i++) { row = data.Row(i); if (row[feature_index] <= threshold) { left_size++; split.dataset_left.Resize(left_size, cols); split.dataset_left.Row(row, left_size-1); } else { right_size++; split.dataset_right.Resize(right_size, cols); split.dataset_right.Row(row, right_size-1); } } return split; }
多くの分割の中から、アルゴリズムが最適な分割、つまり最大の情報利得を持つ分割を見つけ出す必要があります。
split_info CDecisionTree::get_best_split(matrix &data, uint num_features) { double max_info_gain = -DBL_MAX; vector feature_values = {}; vector left_v={}, right_v={}, y_v={}; //--- split_info best_split; split_info split; for (uint i=0; i<num_features; i++) { feature_values = data.Col(i); vector possible_thresholds = matrix_utils.Unique(feature_values); //Find unique values in the feature, representing possible thresholds for splitting. for (uint j=0; j<possible_thresholds.Size(); j++) { split = this.split_data(data, i, possible_thresholds[j]); if (split.dataset_left.Rows()>0 && split.dataset_right.Rows() > 0) { y_v = data.Col(data.Cols()-1); right_v = split.dataset_right.Col(split.dataset_right.Cols()-1); left_v = split.dataset_left.Col(split.dataset_left.Cols()-1); double curr_info_gain = this.information_gain(y_v, left_v, right_v); if (curr_info_gain > max_info_gain) // Check if the current information gain is greater than the maximum observed so far. { #ifdef DEBUG_MODE printf("split left: [%dx%d] split right: [%dx%d] curr_info_gain: %f max_info_gain: %f",split.dataset_left.Rows(),split.dataset_left.Cols(),split.dataset_right.Rows(),split.dataset_right.Cols(),curr_info_gain,max_info_gain); #endif best_split.feature_index = i; best_split.threshold = possible_thresholds[j]; best_split.dataset_left = split.dataset_left; best_split.dataset_right = split.dataset_right; best_split.info_gain = curr_info_gain; max_info_gain = curr_info_gain; } } } } return best_split; }
この関数は、全体的な特徴と可能な閾値を検索し、情報利得を最大化する最良の分割を見つけます。その結果、最良の分割に関連する特徴量、閾値、サブセットに関する情報を含むsplit_info構造体が得られます。
02.木を作る
決定木は、停止条件が満たされるまで(例えば、ある深さや最小サンプル数に達するまで)、特徴に基づいてデータセットを再帰的に分割することによって構築されます。
Node *CDecisionTree::build_tree(matrix &data, uint curr_depth=0) { matrix X; vector Y; matrix_utils.XandYSplitMatrices(data,X,Y); //Split the input matrix into feature matrix X and target vector Y. ulong samples = X.Rows(), features = X.Cols(); //Get the number of samples and features in the dataset. Node *node= NULL; // Initialize node pointer if (samples >= m_min_samples_split && curr_depth<=m_max_depth) { split_info best_split = this.get_best_split(data, (uint)features); #ifdef DEBUG_MODE Print("best_split left: [",best_split.dataset_left.Rows(),"x",best_split.dataset_left.Cols(),"]\nbest_split right: [",best_split.dataset_right.Rows(),"x",best_split.dataset_right.Cols(),"]\nfeature_index: ",best_split.feature_index,"\nInfo gain: ",best_split.info_gain,"\nThreshold: ",best_split.threshold); #endif if (best_split.info_gain > 0) { Node *left_child = this.build_tree(best_split.dataset_left, curr_depth+1); Node *right_child = this.build_tree(best_split.dataset_right, curr_depth+1); node = new Node(best_split.feature_index,best_split.threshold,left_child,right_child,best_split.info_gain); return node; } } node = new Node(); node.leaf_value = this.calculate_leaf_value(Y); return node; }
if(best_split.info_gain>0):
上記のコード行は、情報が得られたかどうかを確認します。
このブロックの中で:
Node *left_child = this.build_tree(best_split.dataset_left, curr_depth+1);
左の子ノードを再帰的に構築します。
Node *right_child = this.build_tree(best_split.dataset_right, curr_depth+1);
正しい子ノードを再帰的に構築します。
node = new Node(best_split.feature_index, best_split.threshold, left_child, right_child, best_split.info_gain);
最良の分割からの情報で決定ノードを作成します。
node = new Node(); それ以上分割する必要がない場合は、新しい葉ノードを作成します。
node.value = this.calculate_leaf_value(Y); calculate_leaf_value関数を使って葉ノードの値を設定します。
return node; 現在の分割または葉を表すノードを返します。
便利で使いやすい関数にするために、build_tree関数は、機械学習モジュールでよく使われるfit関数の中に入れておくことができます。
void CDecisionTree::fit(matrix &x, vector &y) { matrix data = matrix_utils.concatenate(x, y, 1); this.root = this.build_tree(data); }
モデルの訓練とテストにおける予測
vector CDecisionTree::predict(matrix &x) { vector ret(x.Rows()); for (ulong i=0; i<x.Rows(); i++) ret[i] = this.predict(x.Row(i)); return ret; }
リアルタイムの予測
double CDecisionTree::predict(vector &x) { return this.make_predictions(x, this.root); }
make_predictions関数は、すべての汚れ仕事をおこなう場所です。
double CDecisionTree::make_predictions(vector &x, const Node &tree) { if (tree.leaf_value != NULL) // This is a leaf leaf_value return tree.leaf_value; double feature_value = x[tree.feature_index]; double pred = 0; #ifdef DEBUG_MODE printf("Tree.threshold %f tree.feature_index %d leaf_value %f",tree.threshold,tree.feature_index,tree.leaf_value); #endif if (feature_value <= tree.threshold) { pred = this.make_predictions(x, tree.left_child); } else { pred = this.make_predictions(x, tree.right_child); } return pred; }
この関数の詳細は次の通りです。
if (feature_value <= tree.threshold): このブロックの中で:
左の子ノードに対してmake_predictionsを再帰的に呼び出します。
pred = this.make_predictions(x, *tree.left_child); 特徴量が閾値より大きい場合:
右の子ノードに対してmake_predictions関数を再帰的に呼び出します。
pred = this.make_predictions(x, *tree.right_child); return pred; 予測を返します。
葉の値の計算
以下の関数は葉の値を計算します。
double CDecisionTree::calculate_leaf_value(vector &Y) { vector uniques = matrix_utils.Unique_count(Y); vector classes = matrix_utils.Unique(Y); return classes[uniques.ArgMax()]; }
この関数は、Yから最も大きいカウントを持つ要素を返し、リスト内の最も一般的な要素を効果的に見つけます。
CDecisionTreeクラスですべてをまとめる
enum mode {MODE_ENTROPY, MODE_GINI}; class CDecisionTree { CMatrixutils matrix_utils; protected: Node *build_tree(matrix &data, uint curr_depth=0); double calculate_leaf_value(vector &Y); //--- uint m_max_depth; uint m_min_samples_split; mode m_mode; double gini_index(vector &y); double entropy(vector &y); double information_gain(vector &parent, vector &left_child, vector &right_child); split_info get_best_split(matrix &data, uint num_features); split_info split_data(const matrix &data, uint feature_index, double threshold=0.5); double make_predictions(vector &x, const Node &tree); void delete_tree(Node* node); public: Node *root; CDecisionTree(uint min_samples_split=2, uint max_depth=2, mode mode_=MODE_GINI); ~CDecisionTree(void); void fit(matrix &x, vector &y); void print_tree(Node *tree, string indent=" ",string padl=""); double predict(vector &x); vector predict(matrix &x); };
それを示したので、実際にすべてがどのように機能するか、木を構築する方法、そしてリアルタイム取引中はもちろんのこと、訓練やテストでの予測をおこなうためにそれを使用する方法を観察してみましょう。最もポピュラーなiris-CSVデータセットを使って、機能するかどうかをテストします。
EAを初期化するたびに、CSVファイルから訓練データを読み込んで決定木モデルを訓練するとします。
int OnInit() { matrix dataset = matrix_utils.ReadCsv("iris.csv"); //loading iris-data decision_tree = new CDecisionTree(3,3, MODE_GINI); //Initializing the decision tree matrix x; vector y; matrix_utils.XandYSplitMatrices(dataset,x,y); //split the data into x and y matrix and vector respectively decision_tree.fit(x, y); //Building the tree decision_tree.print_tree(decision_tree.root); //Printing the tree vector preds = decision_tree.predict(x); //making the predictions on a training data Print("Train Acc = ",metrics.confusion_matrix(y, preds)); //Measuring the accuracy return(INIT_SUCCEEDED); }
これは,出力されたときのデータセット行列の外観です。最後の列がエンコードされました。1(1)はSetosa、2(2)はVersicolor、3(3)はVirginicaを表します。
Print("iris-csv\n",dataset);
MS 0 08:54:40.958 DecisionTree Test (EURUSD,H1) iris-csv PH 0 08:54:40.958 DecisionTree Test (EURUSD,H1) [[5.1,3.5,1.4,0.2,1] CO 0 08:54:40.958 DecisionTree Test (EURUSD,H1) [4.9,3,1.4,0.2,1] ... ... NS 0 08:54:40.959 DecisionTree Test (EURUSD,H1) [5.6,2.7,4.2,1.3,2] JK 0 08:54:40.959 DecisionTree Test (EURUSD,H1) [5.7,3,4.2,1.2,2] ... ... NQ 0 08:54:40.959 DecisionTree Test (EURUSD,H1) [6.2,3.4,5.4,2.3,3] PD 0 08:54:40.959 DecisionTree Test (EURUSD,H1) [5.9,3,5.1,1.8,3]]
木の出力
コードを見ると、print_treeという関数があることにお気づきでしょうか。これは木の根を引数の1つとして受け取ります。この関数は、木全体の外観の出力を試みます。
void CDecisionTree::print_tree(Node *tree, string indent=" ",string padl="") { if (tree.leaf_value != NULL) Print((padl+indent+": "),tree.leaf_value); else //if we havent' reached the leaf node keep printing child trees { padl += " "; Print((padl+indent)+": X_",tree.feature_index, "<=", tree.threshold, "?", tree.info_gain); print_tree(tree.left_child, "left","--->"+padl); print_tree(tree.right_child, "right","--->"+padl); } }
この関数の詳細は次の通りです。
ノードの構造
この関数は、Nodeクラスが決定木を表すと仮定します。各ノードは決定ノードにも葉ノードにもなります。決定ノードは、特徴、閾値、情報利得、葉の値を示すfeature_index、threshold、info_gainを持ちます。
出力決定ノード
現在のNodeが葉ノードでない場合(すなわちtree.leaf_valueがNULL)、決定ノードに関する情報を表示します。「X_2 <= 1.9 ? 0.33」などの分割条件とインデントレベルを出力します。
葉ノードの出力
現在のノードが葉ノードである場合(すなわち、tree.leaf_valueがNULLでない場合)、葉値をインデントレベルとともに表示します。例えば、「left:0.33」です。
再帰
その後、この関数は現在のノードの左右の子ノードに対して再帰的に呼び出されます。padl引数は出力出力にインデントを加え、木構造を読みやすくします。
OnInit関数内で構築された決定木に対するprint_treeの出力は以下の通りです。
CR 0 09:26:39.990 DecisionTree Test (EURUSD,H1) : X_2<=1.9?0.3333333333333334 HO 0 09:26:39.990 DecisionTree Test (EURUSD,H1) ---> left: 1.0 RH 0 09:26:39.990 DecisionTree Test (EURUSD,H1) ---> right: X_3<=1.7?0.38969404186795487 HP 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->---> left: X_2<=4.9?0.08239026063100136 KO 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->--->---> left: X_3<=1.6?0.04079861111111116 DH 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->--->--->---> left: 2.0 HM 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->--->--->---> right: 3.0 HS 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->--->---> right: X_3<=1.5?0.2222222222222222 IH 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->--->--->---> left: 3.0 QM 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->--->--->---> right: 2.0 KP 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->---> right: X_2<=4.8?0.013547574039067499 PH 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->--->---> left: X_0<=5.9?0.4444444444444444 PE 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->--->--->---> left: 2.0 DP 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->--->--->---> right: 3.0 EE 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->--->---> right: 3.0
印象的です。
以下は、私たちの訓練済みモデルの精度です。
vector preds = decision_tree.predict(x); //making the predictions on a training data Print("Train Acc = ",metrics.confusion_matrix(y, preds)); //Measuring the accuracy
出力
PM 0 09:26:39.990 DecisionTree Test (EURUSD,H1) Confusion Matrix CE 0 09:26:39.990 DecisionTree Test (EURUSD,H1) [[50,0,0] HR 0 09:26:39.990 DecisionTree Test (EURUSD,H1) [0,50,0] ND 0 09:26:39.990 DecisionTree Test (EURUSD,H1) [0,1,49]] GS 0 09:26:39.990 DecisionTree Test (EURUSD,H1) KF 0 09:26:39.990 DecisionTree Test (EURUSD,H1) Classification Report IR 0 09:26:39.990 DecisionTree Test (EURUSD,H1) MD 0 09:26:39.990 DecisionTree Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support EQ 0 09:26:39.990 DecisionTree Test (EURUSD,H1) 1.0 50.00 50.00 100.00 50.00 50.0 HR 0 09:26:39.990 DecisionTree Test (EURUSD,H1) 2.0 51.00 50.00 100.00 50.50 50.0 PO 0 09:26:39.990 DecisionTree Test (EURUSD,H1) 3.0 49.00 50.00 100.00 49.49 50.0 EH 0 09:26:39.990 DecisionTree Test (EURUSD,H1) PR 0 09:26:39.990 DecisionTree Test (EURUSD,H1) Accuracy 0.99 HQ 0 09:26:39.990 DecisionTree Test (EURUSD,H1) Average 50.00 50.00 100.00 50.00 150.0 DJ 0 09:26:39.990 DecisionTree Test (EURUSD,H1) W Avg 50.00 50.00 100.00 50.00 150.0 LG 0 09:26:39.990 DecisionTree Test (EURUSD,H1) Train Acc = 0.993
99.3%の精度を達成し、決定木の実装が成功したことを示しています。この精度は、単純なデータセットの問題を扱うときにScikit-Learnモデルから期待されるものと一致しています。
さらに訓練を進め、サンプル外のデータでモデルをテストしてみましょう。
matrix train_x, test_x; vector train_y, test_y; matrix_utils.TrainTestSplitMatrices(dataset, train_x, train_y, test_x, test_y, 0.8, 42); //split the data into training and testing samples decision_tree.fit(train_x, train_y); //Building the tree decision_tree.print_tree(decision_tree.root); //Printing the tree vector preds = decision_tree.predict(train_x); //making the predictions on a training data Print("Train Acc = ",metrics.confusion_matrix(train_y, preds)); //Measuring the accuracy //--- preds = decision_tree.predict(test_x); //making the predictions on a test data Print("Test Acc = ",metrics.confusion_matrix(test_y, preds)); //Measuring the accuracy
出力
QD 0 14:56:03.860 DecisionTree Test (EURUSD,H1) : X_2<=1.7?0.34125 LL 0 14:56:03.860 DecisionTree Test (EURUSD,H1) ---> left: 1.0 QK 0 14:56:03.860 DecisionTree Test (EURUSD,H1) ---> right: X_3<=1.6?0.42857142857142855 GS 0 14:56:03.860 DecisionTree Test (EURUSD,H1) --->---> left: X_2<=4.9?0.09693877551020412 IL 0 14:56:03.860 DecisionTree Test (EURUSD,H1) --->--->---> left: 2.0 MD 0 14:56:03.860 DecisionTree Test (EURUSD,H1) --->--->---> right: X_3<=1.5?0.375 IS 0 14:56:03.860 DecisionTree Test (EURUSD,H1) --->--->--->---> left: 3.0 QR 0 14:56:03.860 DecisionTree Test (EURUSD,H1) --->--->--->---> right: 2.0 RH 0 14:56:03.860 DecisionTree Test (EURUSD,H1) --->---> right: 3.0 HP 0 14:56:03.860 DecisionTree Test (EURUSD,H1) Confusion Matrix FG 0 14:56:03.860 DecisionTree Test (EURUSD,H1) [[42,0,0] EO 0 14:56:03.860 DecisionTree Test (EURUSD,H1) [0,39,0] HK 0 14:56:03.860 DecisionTree Test (EURUSD,H1) [0,0,39]] OL 0 14:56:03.860 DecisionTree Test (EURUSD,H1) KE 0 14:56:03.860 DecisionTree Test (EURUSD,H1) Classification Report QO 0 14:56:03.860 DecisionTree Test (EURUSD,H1) MQ 0 14:56:03.860 DecisionTree Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support OQ 0 14:56:03.860 DecisionTree Test (EURUSD,H1) 1.0 42.00 42.00 78.00 42.00 42.0 ML 0 14:56:03.860 DecisionTree Test (EURUSD,H1) 3.0 39.00 39.00 81.00 39.00 39.0 HK 0 14:56:03.860 DecisionTree Test (EURUSD,H1) 2.0 39.00 39.00 81.00 39.00 39.0 OE 0 14:56:03.860 DecisionTree Test (EURUSD,H1) EO 0 14:56:03.860 DecisionTree Test (EURUSD,H1) Accuracy 1.00 CG 0 14:56:03.860 DecisionTree Test (EURUSD,H1) Average 40.00 40.00 80.00 40.00 120.0 LF 0 14:56:03.860 DecisionTree Test (EURUSD,H1) W Avg 40.05 40.05 79.95 40.05 120.0 PR 0 14:56:03.860 DecisionTree Test (EURUSD,H1) Train Acc = 1.0 CD 0 14:56:03.861 DecisionTree Test (EURUSD,H1) Confusion Matrix FO 0 14:56:03.861 DecisionTree Test (EURUSD,H1) [[9,2,0] RK 0 14:56:03.861 DecisionTree Test (EURUSD,H1) [1,10,0] CL 0 14:56:03.861 DecisionTree Test (EURUSD,H1) [2,0,6]] HK 0 14:56:03.861 DecisionTree Test (EURUSD,H1) DQ 0 14:56:03.861 DecisionTree Test (EURUSD,H1) Classification Report JJ 0 14:56:03.861 DecisionTree Test (EURUSD,H1) FM 0 14:56:03.861 DecisionTree Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support QM 0 14:56:03.861 DecisionTree Test (EURUSD,H1) 2.0 12.00 11.00 19.00 11.48 11.0 PH 0 14:56:03.861 DecisionTree Test (EURUSD,H1) 3.0 12.00 11.00 19.00 11.48 11.0 KD 0 14:56:03.861 DecisionTree Test (EURUSD,H1) 1.0 6.00 8.00 22.00 6.86 8.0 PP 0 14:56:03.861 DecisionTree Test (EURUSD,H1) LJ 0 14:56:03.861 DecisionTree Test (EURUSD,H1) Accuracy 0.83 NJ 0 14:56:03.861 DecisionTree Test (EURUSD,H1) Average 10.00 10.00 20.00 9.94 30.0 JR 0 14:56:03.861 DecisionTree Test (EURUSD,H1) W Avg 10.40 10.20 19.80 10.25 30.0 HP 0 14:56:03.861 DecisionTree Test (EURUSD,H1) Test Acc = 0.833
このモデルは、訓練データでは100%の精度を示し、サンプル外のデータでは83%の精度を示しました。
取引における決定木AI
決定木モデルを使って取引の側面を探らなければ、このようなことは何の意味もありません。このモデルを取引に使うために、解決したい問題を設定してみましょう。
解決すべき問題
知りたいのは、決定木のAIモデルを使って現在のバーを予測し、マーケットが上か下か、どちらに向かっているのかです。
どのようなモデルでもそうですが、モデルに学習するためのデータセットを与えたいとします。例えば、オシレーター系の2つの指標、RSI指標とストキャスティクスオシレーターを使用することにしましょう。基本的に、モデルにはこれら2つの指標間のパターンと、それが現在のバーの価格変動にどのような影響を与えるかを理解してもらいたいと考えています。
データ構造
訓練とテストの目的で収集されたデータは、以下のような構造で保存されます。リアルタイムの予測に使われるデータも同様です。
struct data{ vector stoch_buff, signal_buff, rsi_buff, target; } data_struct;
データの収集、決定木の訓練とテスト
void TrainTree() { matrix dataset(train_bars, 4); vector v; //--- Collecting indicator buffers data_struct.rsi_buff.CopyIndicatorBuffer(rsi_handle, 0, 1, train_bars); data_struct.stoch_buff.CopyIndicatorBuffer(stoch_handle, 0, 1, train_bars); data_struct.signal_buff.CopyIndicatorBuffer(stoch_handle, 1, 1, train_bars); //--- Preparing the target variable MqlRates rates[]; ArraySetAsSeries(rates, true); int size = CopyRates(Symbol(), PERIOD_CURRENT, 1,train_bars, rates); data_struct.target.Resize(size); //Resize the target vector for (int i=0; i<size; i++) { if (rates[i].close > rates[i].open) data_struct.target[i] = 1; else data_struct.target[i] = -1; } dataset.Col(data_struct.rsi_buff, 0); dataset.Col(data_struct.stoch_buff, 1); dataset.Col(data_struct.signal_buff, 2); dataset.Col(data_struct.target, 3); decision_tree = new CDecisionTree(min_sample,max_depth_, tree_mode); //Initializing the decision tree matrix train_x, test_x; vector train_y, test_y; matrix_utils.TrainTestSplitMatrices(dataset, train_x, train_y, test_x, test_y, 0.8, 42); //split the data into training and testing samples decision_tree.fit(train_x, train_y); //Building the tree decision_tree.print_tree(decision_tree.root); //Printing the tree vector preds = decision_tree.predict(train_x); //making the predictions on a training data Print("Train Acc = ",metrics.confusion_matrix(train_y, preds)); //Measuring the accuracy //--- preds = decision_tree.predict(test_x); //making the predictions on a test data Print("Test Acc = ",metrics.confusion_matrix(test_y, preds)); //Measuring the accuracy }
最小サンプルは3、最大深度は5に設定されました。
出力
KR 0 16:26:53.028 DecisionTree Test (EURUSD,H1) : X_0<=65.88930872549261?0.0058610536710859695 CN 0 16:26:53.028 DecisionTree Test (EURUSD,H1) ---> left: X_0<=29.19882857713344?0.003187469522387243 FK 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->---> left: X_1<=26.851851851853503?0.030198175526895188 RI 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->---> left: X_2<=7.319205739522295?0.040050858232676456 KG 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->---> left: X_0<=23.08345903222593?0.04347468770545693 JF 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->---> left: X_0<=21.6795921184317?0.09375 PF 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> left: -1.0 ER 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> right: -1.0 QF 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->---> right: X_2<=3.223853479489069?0.09876543209876543 LH 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> left: -1.0 FJ 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> right: 1.0 MM 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->---> right: -1.0 MG 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->---> right: 1.0 HH 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->---> right: X_0<=65.4606831930956?0.0030639039663222234 JR 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->---> left: X_0<=31.628407983040333?0.00271101025966336 PS 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->---> left: X_0<=31.20436037455599?0.0944903581267218 DO 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->---> left: X_2<=14.629981942657205?0.11111111111111116 EO 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> left: 1.0 IG 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> right: -1.0 EI 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->---> right: 1.0 LO 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->---> right: X_0<=32.4469112469684?0.003164795835173595 RO 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->---> left: X_1<=76.9736842105244?0.21875 RO 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> left: -1.0 PG 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> right: 1.0 MO 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->---> right: X_0<=61.82001028403415?0.0024932856070305487 LQ 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> left: -1.0 EQ 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> right: 1.0 LE 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->---> right: X_2<=84.68660541575225?0.09375 ED 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->---> left: -1.0 LM 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->---> right: -1.0 NE 0 16:26:53.029 DecisionTree Test (EURUSD,H1) ---> right: X_0<=85.28191275702572?0.024468404842877933 DK 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->---> left: X_1<=25.913621262458935?0.01603292204455742 LE 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->---> left: X_0<=72.18709160232456?0.2222222222222222 ED 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->---> left: X_1<=15.458937198072245?0.4444444444444444 QQ 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->---> left: 1.0 CS 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->---> right: -1.0 JE 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->---> right: -1.0 QM 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->---> right: X_0<=69.83504428897093?0.012164425148527835 HP 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->---> left: X_0<=68.39798826749553?0.07844460227272732 DL 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->---> left: X_1<=90.68322981366397?0.06611570247933873 DO 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> left: 1.0 OE 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> right: 1.0 LI 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->---> right: X_1<=88.05704099821516?0.11523809523809525 DE 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> left: 1.0 DM 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> right: -1.0 LG 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->---> right: X_0<=70.41747488780877?0.015360959832756427 OI 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->---> left: 1.0 PI 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->---> right: X_0<=70.56490391752676?0.02275277028755862 CF 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> left: -1.0 MO 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> right: 1.0 EG 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->---> right: X_1<=97.0643939393936?0.10888888888888892 CJ 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->---> left: 1.0 GN 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->---> right: X_0<=90.20261550045987?0.07901234567901233 CP 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->---> left: X_0<=85.94461490761033?0.21333333333333332 HN 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->---> left: -1.0 GE 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->---> right: X_1<=99.66856060606052?0.4444444444444444 GK 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> left: -1.0 IK 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> right: 1.0 JM 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->---> right: -1.0 KE 0 16:26:53.029 DecisionTree Test (EURUSD,H1) Confusion Matrix DO 0 16:26:53.029 DecisionTree Test (EURUSD,H1) [[122,271] QF 0 16:26:53.029 DecisionTree Test (EURUSD,H1) [51,356]] HS 0 16:26:53.029 DecisionTree Test (EURUSD,H1) LF 0 16:26:53.029 DecisionTree Test (EURUSD,H1) Classification Report JR 0 16:26:53.029 DecisionTree Test (EURUSD,H1) ND 0 16:26:53.029 DecisionTree Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support GQ 0 16:26:53.029 DecisionTree Test (EURUSD,H1) 1.0 173.00 393.00 407.00 240.24 393.0 HQ 0 16:26:53.029 DecisionTree Test (EURUSD,H1) -1.0 627.00 407.00 393.00 493.60 407.0 PM 0 16:26:53.029 DecisionTree Test (EURUSD,H1) OG 0 16:26:53.029 DecisionTree Test (EURUSD,H1) Accuracy 0.60 EO 0 16:26:53.029 DecisionTree Test (EURUSD,H1) Average 400.00 400.00 400.00 366.92 800.0 GN 0 16:26:53.029 DecisionTree Test (EURUSD,H1) W Avg 403.97 400.12 399.88 369.14 800.0 LM 0 16:26:53.029 DecisionTree Test (EURUSD,H1) Train Acc = 0.598 GK 0 16:26:53.029 DecisionTree Test (EURUSD,H1) Confusion Matrix CQ 0 16:26:53.029 DecisionTree Test (EURUSD,H1) [[75,13] CK 0 16:26:53.029 DecisionTree Test (EURUSD,H1) [86,26]] NI 0 16:26:53.029 DecisionTree Test (EURUSD,H1) RP 0 16:26:53.029 DecisionTree Test (EURUSD,H1) Classification Report HH 0 16:26:53.029 DecisionTree Test (EURUSD,H1) LR 0 16:26:53.029 DecisionTree Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support EM 0 16:26:53.029 DecisionTree Test (EURUSD,H1) -1.0 161.00 88.00 112.00 113.80 88.0 NJ 0 16:26:53.029 DecisionTree Test (EURUSD,H1) 1.0 39.00 112.00 88.00 57.85 112.0 LJ 0 16:26:53.029 DecisionTree Test (EURUSD,H1) EL 0 16:26:53.029 DecisionTree Test (EURUSD,H1) Accuracy 0.51 RG 0 16:26:53.029 DecisionTree Test (EURUSD,H1) Average 100.00 100.00 100.00 85.83 200.0 ID 0 16:26:53.029 DecisionTree Test (EURUSD,H1) W Avg 92.68 101.44 98.56 82.47 200.0 JJ 0 16:26:53.029 DecisionTree Test (EURUSD,H1) Test Acc = 0.505
このモデルは訓練では60%の確率で正しかったですが、テストでは50.5%の精度でした。モデルを構築するために使用したデータの質、あるいは悪い予測因子があるなど、多くの理由が考えられます。最も一般的な理由は、モデルのパラメータをうまく設定できていないことでしょう。
これを解決するには、パラメータを微調整して、自分のニーズに最適なものを決める必要があるかもしれません。
リアルタイム予測をおこなう関数のコードを書いてみましょう。
int desisionTreeSignal() { //--- Copy the current bar information only data_struct.rsi_buff.CopyIndicatorBuffer(rsi_handle, 0, 0, 1); data_struct.stoch_buff.CopyIndicatorBuffer(stoch_handle, 0, 0, 1); data_struct.signal_buff.CopyIndicatorBuffer(stoch_handle, 1, 0, 1); x_vars[0] = data_struct.rsi_buff[0]; x_vars[1] = data_struct.stoch_buff[0]; x_vars[2] = data_struct.signal_buff[0]; return int(decision_tree.predict(x_vars)); }
次に、簡単な売買ロジックを作ってみます。
決定木が-1、つまりローソク足が下降して引けると予測すれば、売り取引をおこないます。クラス1が予測され、ローソク足が開始位置よりも高く終了することを示す場合は、買い取引をおこないます。
void OnTick() { //--- if (!train_once) // You want to train once during EA lifetime TrainTree(); train_once = true; if (isnewBar(PERIOD_CURRENT)) // We want to trade on the bar opening { int signal = desisionTreeSignal(); double min_lot = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); SymbolInfoTick(Symbol(), ticks); if (signal == -1) { if (!PosExists(MAGICNUMBER, POSITION_TYPE_SELL)) // If a sell trade doesnt exist m_trade.Sell(min_lot, Symbol(), ticks.bid, ticks.bid+stoploss*Point(), ticks.bid - takeprofit*Point()); } else { if (!PosExists(MAGICNUMBER, POSITION_TYPE_BUY)) // If a buy trade doesnt exist m_trade.Buy(min_lot, Symbol(), ticks.ask, ticks.ask-stoploss*Point(), ticks.ask + takeprofit*Point()); } } }
機能を試すために、単月2023.01.01~2023.02.01を始値でテストしてみました。
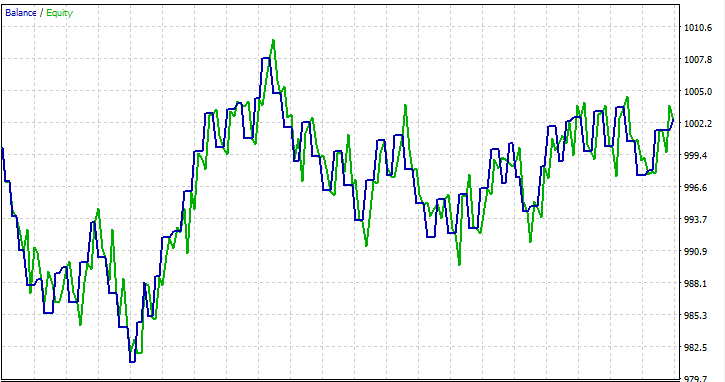
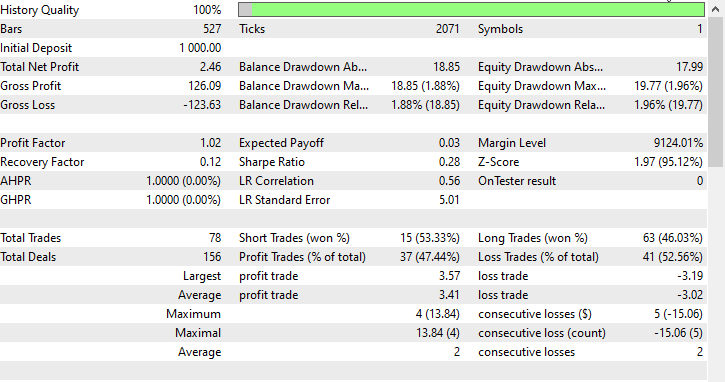
取引における決定木に関するFAQ
| 質問 | 回答 |
|---|---|
| 入力データの正規化は決定木にとって重要ですか? | いいえ、正規化は決定木にとって重要ではありません。決定木は特徴の閾値に基づいて分割をおこない、特徴のスケールは木の構造に影響を与えません。しかし、正規化がモデルのパフォーマンスに与える影響を確認するのは良い習慣です。 |
| 決定木は取引データのカテゴリ変数をどのように扱いますか? | 決定木はカテゴリ変数を自然に扱うことができます。カテゴリ変数の条件も含め、条件を満たすかどうかに基づいて二項分割をおこないます。この木は、カテゴリ特徴の最適な分割点を決定します。 |
| 取引における時系列予測に決定木を使えますか? | 決定木は取引における時系列予測に利用できますが、回帰ニューラルネットワーク(RNN)のようなモデルほど複雑な時間的パターンを効果的に捉えられない可能性があります。ランダムフォレストのようなアンサンブル手法は、より高い頑健性を提供することができます。 |
| 決定木は過剰適合に悩まされますか? | 決定木、特に深い決定木は、学習データにノイズを取り込むことで過剰適合を起こしやすくなります。枝刈りや木の深さの制限などのテクニックは、取引アプリケーションにおける過剰適合を軽減するために使用できます。 |
| 決定木は取引モデルにおける特徴の重要性分析に適していますか? | はい、決定木は特徴の重要性を評価する自然な方法を提供します。一般に、木の最上部での分割決定に大きく寄与する特徴は、より重要です。この分析によって、取引の意思決定を促す要因についての洞察を得ることができます。 |
| 決定木は取引データの外れ値に対してどの程度敏感ですか? | 決定木は、特に木が深い場合、外れ値の影響を受けやすくなります。外れ値は、ノイズを捕捉する特定の分割につながる可能性があります。この感度を緩和するために、異常値検出や除去などの前処理ステップを適用することができます。 |
| 取引モデルの決定木にチューニングすべき特定のハイパーパラメータはありますか? | チューニングの鍵となるハイパーパラメータは以下の通りです。
相互検証を用いて、与えられたデータセットに対する最適なハイパーパラメータ値を見つけることができます。 |
| 決定木はアンサンブル法の一部になり得ますか? | はい、決定木はランダムフォレストのようなアンサンブル手法の一部となり得ます。これは複数の木を組み合わせて全体的な予測性能を向上させるものです。アンサンブル法は、取引アプリケーションにおいて、ロバストで効果的であることが多いです。 |
決定木の利点
解釈可能性
- 決定木は理解しやすく、解釈しやすい:木構造をグラフィカルに表現することで、意思決定プロセスを明確に視覚化できます。
非直線性への対応
- 決定木はデータ中の非線形関係を捉えることができるため、決定境界が線形でない問題に適しています。
混合データ型の取り扱い
- 決定木は、大規模な前処理を必要とせずに、数値データとカテゴリデータの両方を扱うことができます。
特徴の重要性
- 決定木は、特徴の重要性を評価する自然な方法を提供し、ターゲット変数に影響を与える重要な要因を識別するのに役立ちます。
データ分布の仮定なし
- 決定木にはデータ分布に関する仮定がないため、汎用性が高く、さまざまなデータセットに適用できます。
外れ値に対する頑健性
- 決定木は、分割が相対比較に基づいており、絶対値の影響を受けないため、外れ値に対して比較的頑健です。
自動変数選択
- 木の構築プロセスには変数の自動選択が含まれるため、手作業による特徴量エンジニアリングの必要性が軽減されます。
欠測値の扱い
- 決定木は、利用可能なデータに基づいて分割がおこなわれるため、インピュテーションを必要とせずに特徴の欠損値を扱うことができます。
決定木の欠点
過剰適合
- 決定木は過剰適合を起こしやすく、特に深い木で学習データのノイズを捕捉している場合はなおさらです。この問題に対処するために、剪定のような技術が用いられます。
不安定
- データの小さな変化は、木構造の大きな変化につながり、決定木をやや不安定にします。
支配的なクラスへの偏り
- 不均衡なクラスを持つデータセットでは、決定木は支配的なクラスに偏る可能性があり、少数クラスに対して最適なパフォーマンスを発揮できません。
大域的最適解 vs局所的最適解
- 決定木は、各ノードで局所最適な分割を見つけることに重点を置いており、必ずしも全体最適解につながるとは限りません。
限られた表現力
- 決定木は、ニューラルネットワークのようなより洗練されたモデルに比べて、データの複雑な関係を表現できないことがあります。
連続出力に適さない
- 決定木は分類タスクには適していますが、連続的な出力を必要とするタスクには適していないことがあります。
ノイズの多いデータに敏感
- 決定木はノイズの多いデータに対して敏感であり、異常値は意味のあるパターンではなくノイズを捕らえる特定の分割につながる可能性があります。
支配的特徴への偏り
- より多くのレベルやカテゴリを持つ特徴ーは、分割の方法によってよりクリティカルに見える可能性があり、偏りをもたらす可能性があります。この問題は、特徴スケーリングのような技術で解決できます。
以上、ご精読ありがとうございました。
私のGitHubレポ(https://github.com/MegaJoctan/MALE5/tree/master)で、決定木アルゴリズムやその他多くのAIモデルの開発を追跡し、貢献してください。
添付ファイル:
| tree.mqh | メインのインクルードファイル。主に上記で説明した決定木のコードが含まれる |
| metrics.mqh | MLモデルのパフォーマンスを測定するための関数とコードが含まれる |
| matrix_utils.mqh | 行列操作のための追加関数が含まれる |
| preprocessing.mqh | 生の入力データを前処理して機械学習モデルの使用に適したものにするためのライブラリ |
| DecisionTree Test.mq5(EA) | メインファイル決定木を実行するためのEA |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/13862
 MQL5を使ったシンプルな多通貨エキスパートアドバイザーの作り方(第5回): ケルトナーチャネルのボリンジャーバンド—指標シグナル
MQL5を使ったシンプルな多通貨エキスパートアドバイザーの作り方(第5回): ケルトナーチャネルのボリンジャーバンド—指標シグナル
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索