Utilisation de l'intelligence artificielle chez MTS
- Questions d'un "mannequin
- Qui veut une stratégie ? Lots et gratuitement)
- où aller pour un robot acheté qui a perdu sa consigne
Equivalent à un lissage de l'AC à l'aide d'un filtre cypher avec certaines caractéristiques. Les coefficients de lissage ne sont pas équilibrés, ce qui équivaut à une brique sur le bouton d'achat. La brique (+ par exemple stochastique) fonctionne très bien par elle-même, si seulement on sait quand l'acheter et quand la vendre. Aussi, en tenant compte du fait que le CA peut descendre 2 fois en 21 bars et de la présence de 4 paramètres optimisables......))))
Mais pour moi, cela permet de comprendre comment fonctionnent les réseaux neuronaux et pourquoi ils ne sont pas aussi efficaces qu'on le souhaiterait.
J'avais un hobby au début de la période créative - écrire des EAs pour travailler sur m1 sur la base des résultats de la semaine dernière (7200 barres, par opposition à 66000) - jusqu'à 300 pourcents par semaine ont été montrés dans le testeur......
Je me demande combien d'harmoniques il faut décomposer le prix en série de Fourier pour obtenir un graal après optimisation ?
Equivalent à un lissage de l'AC à l'aide d'un filtre cypher avec certaines caractéristiques. Les coefficients de lissage ne sont pas équilibrés, ce qui équivaut à une brique sur le bouton d'achat. La brique (+ par exemple stochastique) fonctionne très bien par elle-même, si seulement on sait quand l'acheter et quand la vendre. Aussi, en tenant compte du fait que l'AC peut descendre 2 fois en 21 bars et de la présence de 4 paramètres optimisables......))))
Mais pour moi, il éclaire le fonctionnement des réseaux neuronaux et explique pourquoi ils ne sont pas aussi efficaces que nous le souhaiterions.
J'avais un hobby au début de la période créative - écrire des EAs pour travailler sur m1 sur la base des résultats de la semaine dernière (7200 barres, par opposition à 66000) - jusqu'à 300 pourcents par semaine ont été montrés dans le testeur......
Je me demande combien d'harmoniques il faut décomposer le prix en série de Fourier pour obtenir un graal après optimisation ?
Comme pour l'oscillateur AC, le Conseiller Expert ne regarde pas seulement sa dernière valeur (les décisions basées sur les dernières valeurs sont le plus souvent utilisées en analyse technique), mais il étudie l'historique, c'est-à-dire quelles étaient les 3 autres valeurs de l'indicateur dans le passé. Il s'intéresse au comportement de l'oscillateur pour prendre des décisions. Ce même comportement se retrouve à l'entrée du réseau neuronal. Et à la sortie, on obtient Acheter ou Vendre.
Une autre nouveauté n'est pas l'entraînement standard du réseau neuronal, mais la sélection des poids sur des données historiques à l'aide de l'algorithme génétique. J'ai essayé les deux variantes. La génétique donne un résultat légèrement moins bon et plus lent. Mais il n'existe pas d'algorithme neuronique intégré et son apprentissage dans MT4. Mais il existe une optimisation basée sur la génétique. Et certains chercheurs dans ce domaine ont réalisé que l'apprentissage dynamique n'est pas très adéquat si la situation change radicalement. Si les haussiers l'emportent sur le marché, le système se réorientera vers la tendance haussière et oubliera la tendance baissière, et vice versa. Samuel A. L. 1959, "Some studies in machine learning using the game of checkers" (IBM J. Research and Devepopmend 3 : 210 - 229), a été le premier à rencontrer et à décrire cette monstruosité. Il a observé que si son programme avait un adversaire professionnel, il passait progressivement à un jeu de niveau professionnel. Mais si l'adversaire était un débutant, alors le programme "oubliait" le niveau précédent et commençait à passer au jeu primitif. Par conséquent, il n'est probablement pas judicieux d'enseigner dynamiquement le neurone sur ses propres erreurs et pertes. Il est plus facile de passer par l'histoire, afin de développer une stratégie de trading adéquate au marché.
Quant aux grails, il n'est pas nécessaire d'être très intelligent. Vous devez simplement remplir un certain nombre de conditions :
1. Le système doit ouvrir des positions soit sans aucun stoploss, soit avec des stoploss à une très grande distance, de sorte que la probabilité de leur fonctionnement soit proche de 0.
2. Un filtre puissant basé sur plusieurs indicateurs avec des conditions de déclenchement séparées par un ET logique (&&). Et de tirer un grand nombre de paramètres d'entrée de ces mêmes indicateurs dans les paramètres externes de MTS, de sorte que seules quelques positions ont été ouvertes pendant plusieurs années de données historiques sur les tests.
3. À tout cela, il faut ajouter la gestion des capitaux et des risques avec une fraction élevée.
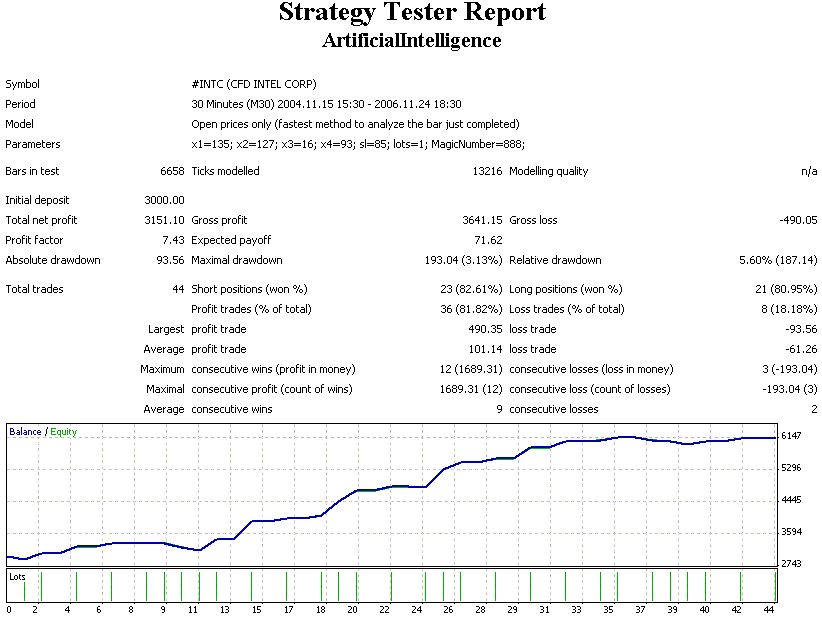
Je ne comprends pas comment tu peux discuter sérieusement d'une stratégie qui rapporte 44 affaires en 2 ans... Trop peu de statistiques !
on prend la valeur de 4 points, on multiplie chaque valeur par un coefficient, on fait la somme - qu'est-ce qui n'est pas un lissage par un filtre ?
on prend la valeur de 4 points, on multiplie chaque valeur par un coefficient, on fait la somme - qu'est-ce qui n'est pas un lissage par un filtre ?
Avez-vous entendu parler des moyennes mobiles linéaires pondérées ?
Quoi qu'il en soit, il a droit à la vie. L'idée n'est peut-être pas nouvelle, mais elle est très intéressante, et intelligemment mise en œuvre, et... est capable de faire des bénéfices. J'ai effectué plusieurs tests en avant après "l'apprentissage" ; les résultats sont encourageants. Merci à l'auteur.
Quoi qu'il en soit, il a droit à la vie. L'idée n'est peut-être pas nouvelle, mais elle est très intéressante, et intelligemment mise en œuvre, et... est capable de faire des bénéfices. J'ai effectué plusieurs tests en avant après "l'apprentissage" ; les résultats sont encourageants. Merci à l'auteur.
Et se disputer avec des gundosos pour savoir si les neurones sont efficaces ou non, eh bien, c'est juste une perte de temps. Je l'expose selon le principe suivant : si vous le voulez, vous pouvez l'avoir, mais si vous ne voulez pas le voir. Mais avec l'espoir de trouver quelqu'un qui s'y connaisse et qui puisse améliorer le code ou suggérer une idée plus intéressante pour résoudre le problème.
on prend la valeur de 4 points, on multiplie chaque valeur par un coefficient, on fait la somme - qu'est-ce qui n'est pas un lissage par un filtre ?
Avez-vous entendu parler des moyennes mobiles linéaires pondérées ?
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation