L'apprentissage automatique dans la négociation : théorie, modèles, pratique et algo-trading - page 169
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
si vous enlevez les bougies, rien...
Mais il y a aussi le verre, T&S, OI...etc...
vous ne serez pas payé.
Je vois, merci.
Si vous faites plusieurs transactions en une minute, vous ne survivrez pas sur le forex... et même si par miracle vous avez une chance sur 1 000 000, il n'y a aucune garantie que vous serez payé.
Eh bien, les conditions commerciales sont de nouveau réunies.
Si vous n'êtes pas capable de l'utiliser, le R-ka ne vous aidera pas non plus. C'est une chose d'être un consultant NS, une autre d'être un utilisateur. Ce sont des choses très différentes...
Je pense que personne ne l'est, ça s'appelle rendre absurde et c'était destiné à ce que le modérateur comprenne l'absurdité de ses déclarations, Reshetov n'a rien à voir avec ça...
Vous avez décidé de calculer la moyenne dans excel et vous écrivez quelque chose sur le forum mql, vous êtes un parasite parce que vous pouvez le faire dans mt5, mql n'a pas aidé la communauté mql, compris ?
Vous êtes un parasite Michael, parce que vous utilisez JProjection, c'est comme ça... :)
R n'a rien à voir avec cela, quelle différence cela fait-il de savoir en quoi écrire ? c'est une question de commodité, pas plus..... Reshetov a écrit son JProjected en Java, bannissez-le, ce n'est pas mql, il n'est pas utile, ce machin - parasite !!!!
c'est un seul mot.
Reshetov réalise ses programmes dans l'espoir que les résultats seront utilisés en TA. Il a écrit de nombreux conseillers, trouvé des milliers d'idées et tout fonctionne pour MT, donc il a fait beaucoup en tant que vulgarisateur, beaucoup.
Vous pouvez écrire tout ce que vous voulez dans le martinet de Dieu, mais vous avez besoin de la communauté pour pouvoir l'utiliser dans MT, sinon vous n'êtes d'aucune utilité pour la communauté. Une communauté qui a été chérie et entretenue, qui s'est développée en investissant d'énormes sommes d'argent.
Si vous avez une idée réalisable, il n'est pas difficile de la traduire en MCL. Et le fait qu'il écrive ici et non sur les forums R est compréhensible - R est sans fond, une communauté hautement spécialisée n'est pas facile à trouver. Et pour la communauté MT, il est un atout incontestable.
Validation croisée sur des échantillons supplémentaires dans un délai différent.
Supposons que je dispose d'une année de données de formation. Je veux former 12 modèles - un utilisant les données de janvier et un autre utilisant les données de février.
C'est un ajustement.
Prenons comme exemple des données simples et claires et modélisons-les... Formation. Points bleus - tendance. Validation des points rouges.
n1;n2;cible
1;0;1
1;1;2
1;0;1
1;1;2
1;0;1
1;0;1
1;1;2
1;0;1
1;0;1
1;0;1
En haut à gauche, 50% de tendance, 50% de validité. En haut à droite - avec mélange.
Pour OOS(bottom) augmentons l'échantillon en ajoutant stupidement l'échantillon précédent. Puisqu'en réalité nous ne connaissons pas l'avenir,
introduisons un point avec la valeur 1.5. Tant que le test (OOS) correspond au point d'entraînement, tout va bien.
A 1,5, le modèle trébuche... Omettre les petits avantages de l'utilisation de la validation et de la primitivité
Dans la vie réelle, nous avons à peu près la même image...
Il s'agit du point de vue officiel du propriétaire de la ressource.
D'ici
S'il vous plaît, arrêtez avec les accusations.
Chaque langue a sa place. R est idéal pour la recherche interactive. C'est mon deuxième jour d'exploration (j'ai lu le livre avant) et cela ressemble vraiment à un débogueur puissant avec visualisation des entrailles.
Travailler avec R a immédiatement révélé nos faiblesses :
Nous avons lancé la première plateforme de trading algorithmique en MQL en 2001. Chaque fois, nous avons augmenté ses possibilités, mais la boîte à outils mathématique n'était pas si bonne. Nous avons développé l'analyse, l'accès aux données, le testeur, les calculs distribués, puis nous sommes arrivés au stade de la vente des produits.
Et puis, il est apparu que la plupart des solutions étaient coincées dans un cercle vicieux d'analyse, d'indicateurs et d'adaptation. Nous devons laisser les développeurs atteindre le niveau supérieur de capacité mathématique.
C'est pourquoi, il y a quelque temps, nous avons commencé à étendre les bibliothèques mathématiques dans MQL5 et avons également publié en version bêta Alglib, Fuzzy et Stat. Ils vous permettront de transférer facilement certains modèles d'autres systèmes vers MQL5 et d'élever la classe des solutions analytiques créées pour laplateforme Metatrader 5.
Dans les 2 prochains mois, vous verrez les progrès que nous ferons dans le développement de l'environnement mathématique.
Nous accueillons volontiers les discussions et les articles portant sur des ensembles mathématiques complexes. Écrivez et envoyez des demandes d'articles à Rashid Umarov. Notre tâche consiste à encourager et à former les traders à des techniques plus sophistiquées, et non à nous enfermer dans notre propre monde MQL5.
Bien sûr, nous défendons et continuerons à défendre notre langue et notre plateforme contre les attaques, mais nous travaillons également à leur développement. Donc tout ira bien.
PS.
C'est moi qui souligne
Dans le monde réel, nous avons une image comme celle-ci...
Je ne comprends pas bien votre conclusion.
Le modèle ne fonctionnera que dans la mesure où il fonctionne sur des données connues ? C'est-à-dire que lors de la prévision sur de nouvelles données, il commencera à trébucher de toute façon, quel que soit le type de ventilation (avec/sans mélange) ?
La seule façon d'économiser de l'argent est de ne pas faire de commerce.
Je le fais non seulement pour sélectionner les paramètres du modèle, mais aussi pour sélectionner les indicateurs et leurs paramètres. Je télécharge 10000 indicateurs avec différents paramètres et lags depuis mt5, puis j'utilise la génétique pour rechercher à la fois les indicateurs utilisés dans cette liste et les paramètres du modèle (arbres dans la forêt, couches dans le neurone, etc.). On peut dire que c'est ma façon de trouver des dépendances constantes.
Si je prends un ensemble d'indicateurs standard avec des paramètres standard dans MT5, alors je n'aurai aucun modèle validé par recoupement avec eux, que ce soit le neuronka ou les arbres. Trouver un ensemble d'indicateurs sur lesquels les modèles donneront des résultats positifs lors d'une telle validation croisée est un exploit qui demande beaucoup de travail et de temps. Un résultat positif est un critère certain qu'il existe des corrélations constantes entre tous les prédicteurs dans l'espace et le temps. Quel que soit l'intervalle utilisé pour la formation, le modèle trouvera les mêmes dépendances et s'y fiera.
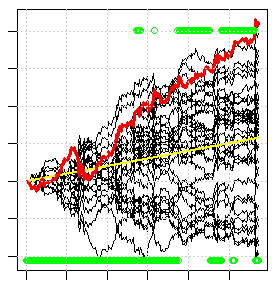
L'image ci-dessous est un exemple de cette validation croisée. Chaque ligne noire est le résultat (croissance du solde) des échanges de chaque modèle individuel de l'ensemble. La ligne rouge est le résultat de l'échange de la majorité des modèles de l'ensemble. Environ 1/3 des modèles n'obtiennent aucun bénéfice, même si la génétique a pris plus d'une journée pour rechercher toutes les variantes, c'est-à-dire que c'est l'un des meilleurs résultats que l'on puisse trouver, même si le résultat n'est même pas très bon. Si vous composez gratuitement n'importe quel indicateur standard, tout cet éventail noir s'abaissera et la ligne rouge s'abaissera en dehors de l'écran.
Vous cherchez des solutions... dans ces réalités.
------------------------------------------------------------------------
Le drawdown sur le côté gauche de l'écran n'est pas mauvais, le modèle ne décrit pas cette zone...