
Simulación de mercado (Parte 23): Iniciando SQL (VI)

Introducción
En el artículo anterior Simulación de mercado (Parte 22): Iniciando SQL (V), abordé la cuestión de cómo usar, o mejor dicho, cómo una clave primaria se enlaza con una clave foránea. Si no sabes de qué estoy hablando, te sugiero que detengas la lectura y leas primero los artículos anteriores. Esto para que puedas, de hecho, entender lo que estaremos haciendo aquí.
Entendiendo el resultado de la búsqueda
Pues bien, en el artículo anterior armamos una pequeña base de datos cuyo objetivo era permitir ejemplificar el uso de claves primarias junto con claves foráneas. Sin embargo, al hacer una búsqueda en la que se utilizó esta configuración, tú muy probablemente terminarás encontrándote con un resultado muy diferente de lo esperado. Para que quede un poco más claro, vamos a usar el siguiente código para buscar en la base de datos.
SELECT * FROM tb_Quotes;
Código 01
El resultado se muestra a continuación.
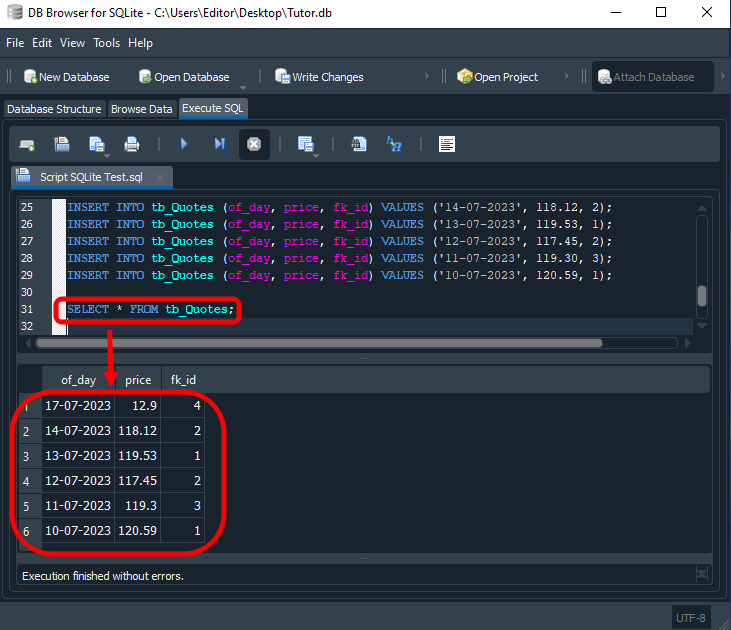
Imagen 01
Así, tú terminas preguntándote: ¿Qué hice mal? La respuesta es: NADA. Mucha gente no usa claves foráneas en sus bases de datos precisamente por no entender el concepto que hay detrás de este tipo de claves. Y, por esta razón, terminan creando bases de datos no relacionales, haciendo que el mantenimiento y la propia estructura de la base de datos sean mucho más complicados de lo que realmente podrían ser. Esto hace que el procesamiento y el trabajo de SQL sean mucho mayores de lo que ocurriría normalmente.
Uno de los mayores triunfos de SQL está en el hecho de que tú puedes crear tablas aparentemente aisladas. Sin embargo, aun así logras hacer que estas tablas, o mejor dicho, los valores presentes en estas tablas, lleguen a enlazarse de alguna forma. Y esto evita precisamente uno de los mayores problemas que existían antes de SQL: los datos duplicados. Tal vez tú no entiendas cuán perjudicial es esto para la base de datos. Pero esto, de hecho, termina destruyendo por completo la gran ventaja que existe al usar SQL cuando tu aplicación necesita crear bases de datos.
Visualizando un diagrama de la base de datos
Para visualizar un diagrama, existen diversas alternativas, algunas con más o menos recursos. En el caso de DB Browser, que se está usando aquí para explicar algunas cosas, tú no lograrás, de hecho, obtener dicho diagrama. Bueno, al menos hasta el momento en que escribo este artículo, ya que, por tratarse de un programa de código abierto y que recibe actualizaciones vía GitHub, puede ser que, en el momento en que tú estés leyendo este artículo, ese recurso ya esté presente en DB Browser. Así, una alternativa sería usar DBeaver. Este es un programa que tiene una versión gratuita que puede descargarse y utilizarse sin grandes problemas. Bien, una vez con DBeaver en tus manos, tú deberás seguir los siguientes pasos para poder visualizar un diagrama.
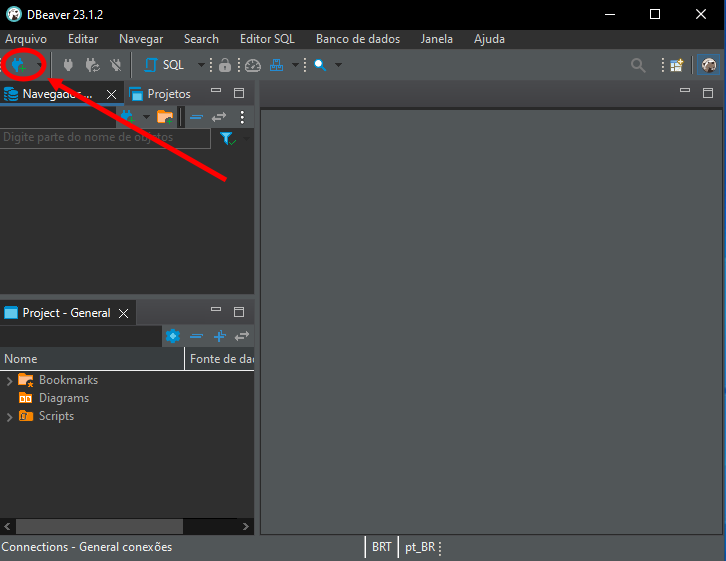
Imagen 02
Así, se te dirigirá a una nueva ventana que se muestra a continuación.
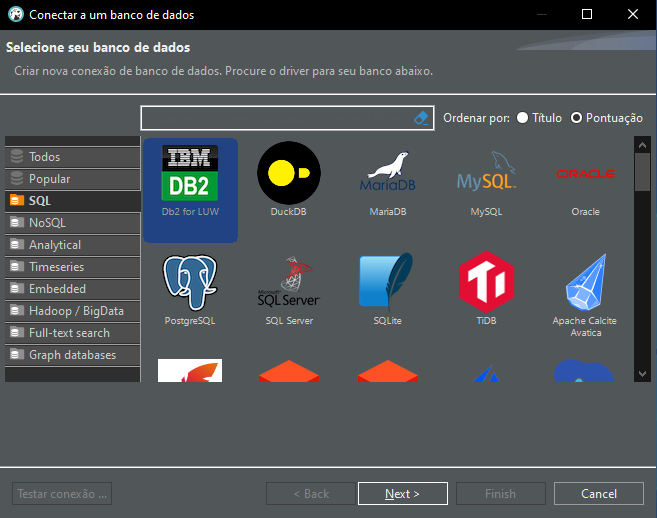
Imagen 03
Aquí, tú deberás seleccionar el tipo de base de datos que se va a visualizar. Recuerda que nuestra base de datos es del tipo SQLite. Entonces, búscala y selecciónala, como se muestra a continuación.

Imagen 04
Muy bien, ahora se te presentará la siguiente ventana.
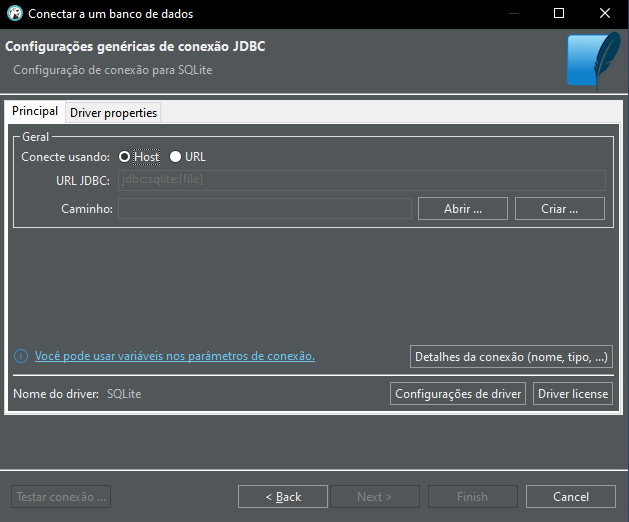
Imagen 05
Aquí, tú deberás colocar la ruta y el nombre de la base de datos que se va a abrir, como puedes ver a continuación.
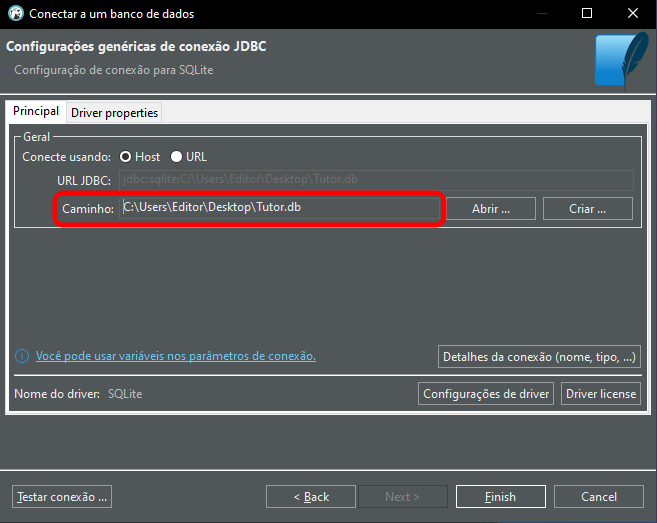
Imagen 06
Hecho esto, haz clic en Finish, y se te presentará una última pantalla.
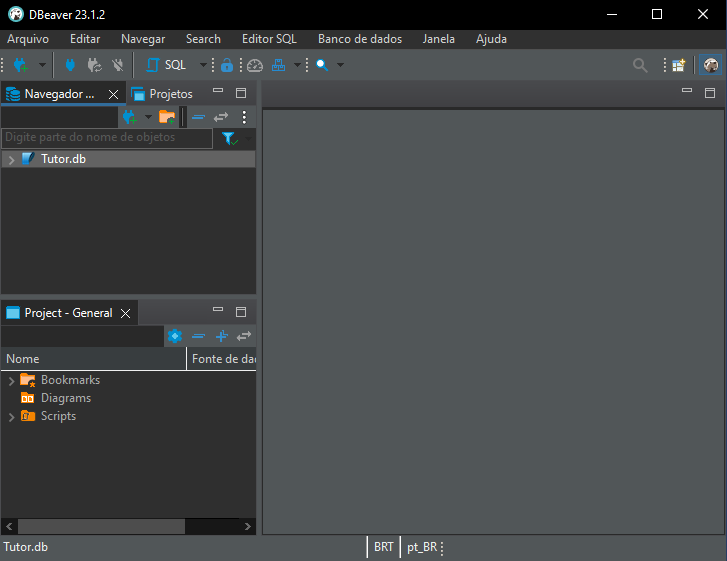
Imagen 07
Si tú hiciste todo correctamente, verás esto que podemos observar en la imagen 07, donde nuestra base de datos está lista para trabajarse. Así, finalmente, podemos abrir el diagrama haciendo clic en los puntos destacados a continuación.
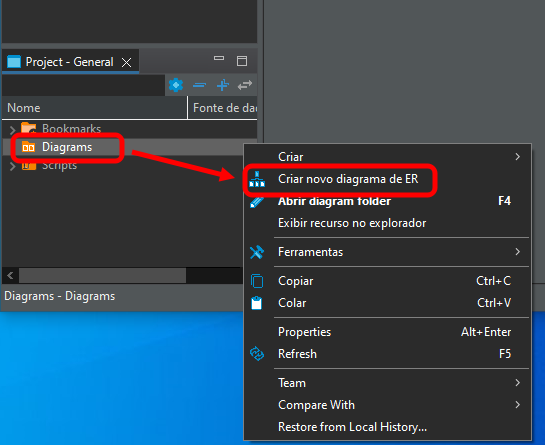
Imagen 08
Esto abrirá una ventana que puedes ver a continuación.
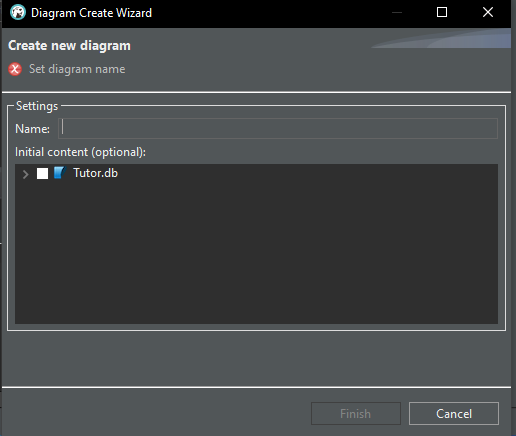
Imagen 09
Ahora, ponle un nombre al diagrama que se creará, como puede verse en la imagen de abajo. Puedes darle cualquier nombre que desees.
Imagen 10
Y, finalmente, al hacer clic en Finish, el resultado será el que se muestra a continuación.
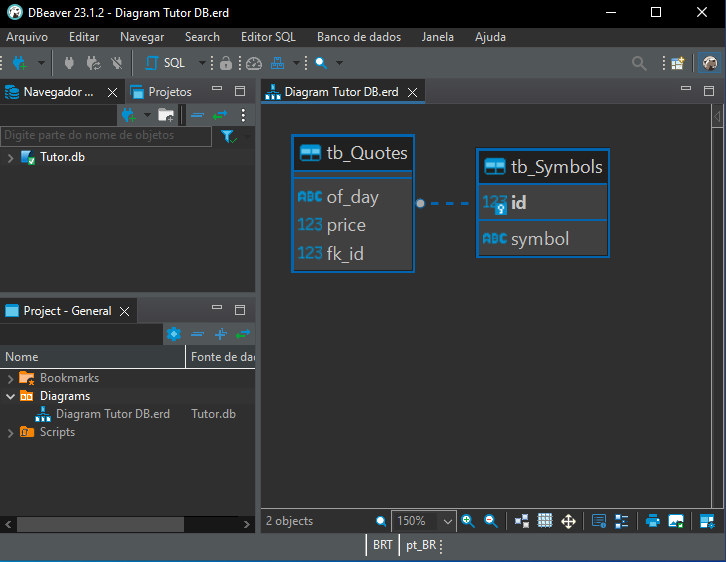
Imagen 11
Entendiendo lo que representa el diagrama
En la imagen 11, podemos ver claramente que existe una relación entre la tabla tb_Quotes y la tabla tb_Symbols. Pero tal vez tú creas que esta relación es de uno a uno. Es decir, para cada registro en la tabla tb_Symbols, existirá un registro correspondiente en la tabla tb_Quotes. Bueno, esto incluso puede ocurrir en algunos escenarios. Pero observa algo en este diagrama. Es algo bastante sutil, pero importante. En la imagen de abajo, tenemos exactamente el punto que debe observarse, destacado.
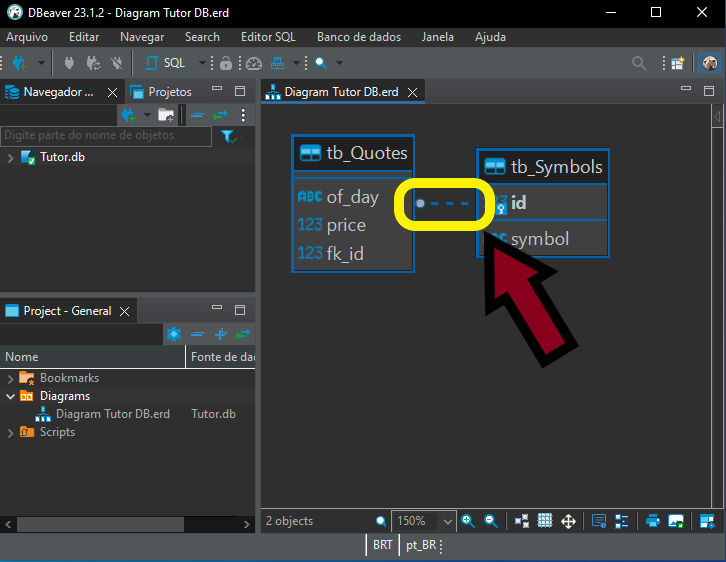
Imagen 12
Observa que, de un lado, tenemos una bolita y, del otro, no tenemos nada. Presta mucha atención a esto. Pero ¿qué significa? Pues bien, esto indica una relación de uno a muchos. Es decir, en el lado, o tabla, en el que se encuentra la bolita, podemos tener muchos registros por cada uno de los registros de la tabla a la que se esté enlazando esta línea. Saber interpretar correctamente este tipo de cosa te permitirá hacer una búsqueda de manera más adecuada. Así como también permitirá que tú hagas modificaciones o cambios en la base de datos de una forma mucho más simple y sin errores.
Esto se debe a que el hecho de tener, en una tabla, algún registro que podrá repetirse muchas veces en una, o en varias otras tablas, nos ayudará a entender y a diseñar adecuadamente el funcionamiento de gatillos, ya sea para agregar nuevos datos, eliminar algún registro o incluso actualizar alguna información en la base de datos. Pero este es un tema para otro momento. Lo que necesitamos en este momento es entender cómo este tipo de enlace puede ayudarnos a visualizar adecuadamente lo que hay en la base de datos.
Traduciendo las cosas a SQL
Muy bien, hasta el momento, todo lo que hicimos fue ver cómo producir el diagrama de la base de datos. Ahora vamos a volver a DB Browser, recordando que tú también podrás usar MetaEditor para ver el mismo tipo de resultado que se verá aquí y utilizar un código ligeramente diferente para hacer la búsqueda en la base de datos. El código en cuestión se muestra a continuación.
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT * FROM tb_Quotes, tb_Symbols;
Código 02
Así, al ejecutar este script, SQL nos estará devolviendo 24 registros. Pero ¿por qué? Pues bien, veamos lo que ocurrió aquí. Observa, en la imagen de abajo, el resultado de la ejecución del código.
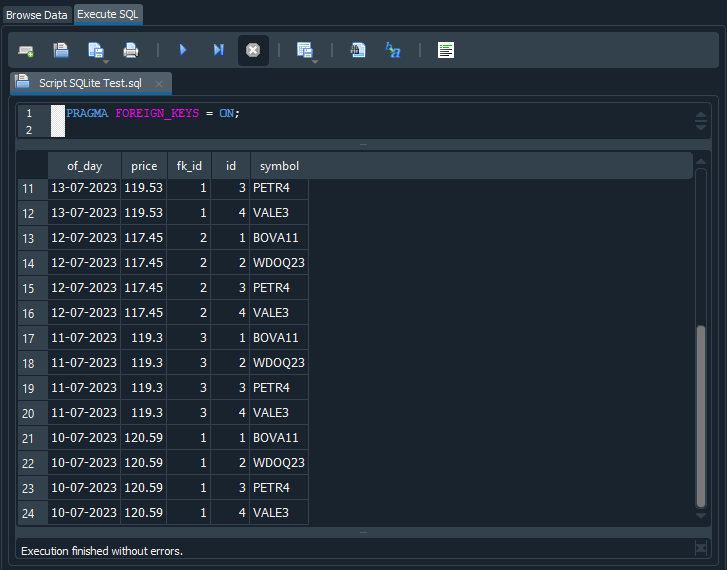
Imagen 13
Puedes notar que, entre los registros de las líneas 17 y 20, el mismo valor, tanto de cotización como de fecha, se está repitiendo. Es decir, SQL interpretó que debía ejecutar el comando select y que el contenido de las tablas tb_Quotes y tb_Symbols debía combinarse de alguna forma. Por esta razón, tenemos valores repetidos provenientes de la tabla tb_Quotes cuando el valor de la tabla tb_Symbols está cambiando, ya que tenemos seis registros en la tabla tb_Quotes y cuatro registros en la tabla tb_Symbols. Así, al combinar ambas tablas, SQL genera los 24 registros que se nos presentan. ¿Ahora entienden el motivo por el que SQL nos presenta 24 registros?
Pero observa algo en la imagen 13. Hay puntos en los que el valor de fk_id es igual al valor de id. Hum, esto es curioso, ¿verdad? Pero ¿por qué sucede esto? El motivo es que el valor del registro en fk_id nos está diciendo cuál es el valor que debemos buscar. Ahora volvamos a nuestro diagrama que se muestra en la imagen 12. Allí, vemos que el valor de id está en la tabla tb_Symbols y el valor de fk_id está en la tabla tb_Quotes.
Bien, ahora necesitamos usar lo que se conoce como alias. Es decir, necesitamos crear un apodo para poder relacionar una tabla con la otra. Esto para que SQL sepa cómo montar los datos, a fin de que se nos presenten correctamente. Para usar un alias, o apodo, debemos tener cuidado de no usar palabras reservadas. Algunas implementaciones logran manejar esto. Pero, en general, e incluso para evitar confusiones por parte de otros programadores SQL, evita usar palabras reservadas como apodos en código SQL. Así, el nuevo código que se ejecutará se muestra a continuación.
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT * 32. FROM tb_Quotes AS tq, tb_Symbols AS ts 33. WHERE tq.fk_id = ts.id;
Código 03
Al ejecutar este código, tenemos el resultado que se muestra en la imagen de abajo.
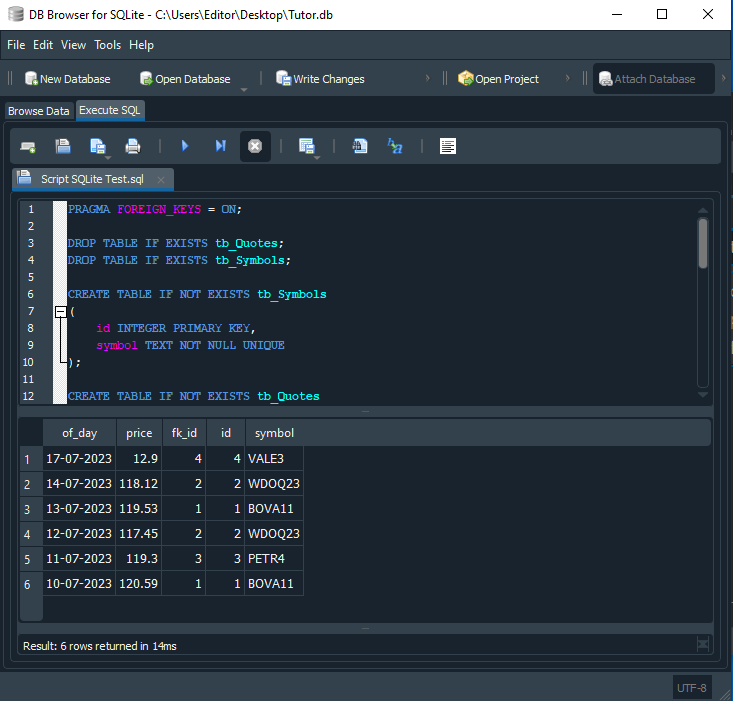
Imagen 14
Como por milagro, ahora tenemos exactamente lo que se esperaba. Es decir, podemos ver los seis registros de cotización, indicando cuál fue el símbolo, la fecha y el precio del lanzado. Ahora vamos a entender por qué sucede esto. Observa, en la línea 32 del script, que, después del nombre de cada una de las tablas, estamos agregando un alias para trabajar con las tablas.
Para que SQL sepa cómo enlazar cada una de estas tablas, y esto a fin de proporcionarnos el resultado adecuado, usamos la línea 33. En esta línea, tenemos la instrucción WHERE, que dice cuál es el criterio usado en el filtrado o armado del resultado. En este caso, queremos que, cuando el registro fk_id de la tabla tb_Quotes sea igual al registro id de la tabla tb_Symbol, SQL anote el resultado para presentárnoslo después. Entonces, el comando SELECT recorrerá todas las posibilidades de combinaciones, como se vio anteriormente. Sin embargo, debido al filtro, SQL nos devolverá solo lo que realmente se pidió.
Un detalle en la explicación dada arriba. En realidad, SQL no recorrerá todas las posibilidades o combinaciones entre las tablas. Este tipo de cosa haría que el motor de búsqueda degradara muy rápidamente el rendimiento general del sistema. En verdad, lo que ocurre es que SQL usará una de las tablas para empezar a crear los resultados; luego, buscará en la otra tabla los campos necesarios para hacer las debidas comparaciones y ajustes. De esta manera, la búsqueda se realiza de forma mucho más eficiente.
Podemos mejorar aún más lo que SQL nos está devolviendo. No es raro tener columnas con nombres bastante extraños y, otras veces, como tú viste en la imagen 14, que SQL devuelva columnas que no queremos. ¿Cómo filtrar este tipo de cosa? Es sencillo. Bastará con decirle a SQL qué columnas queremos y también qué nombre deberán tener. Así, llegamos al script que se muestra a continuación.
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT tq.of_day AS 'Data da cotação', 32. tq.price AS 'Preço Atual', 33. ts.symbol AS 'Nome do Ativo' 34. FROM tb_Quotes AS tq, tb_Symbols AS ts 35. WHERE tq.fk_id = ts.id;
Código 04
Ahora, el resultado es lo que podemos ver a continuación.
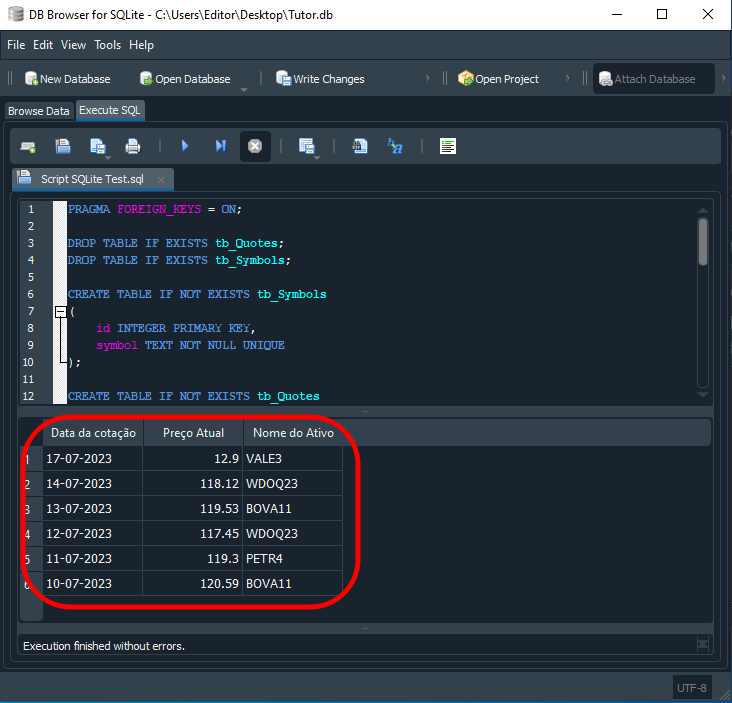
Imagen 15
¡Vaya! Entonces, ¿SQL no es exactamente lo que yo imaginaba? Siempre pensé que era un montón de instrucciones sin mucho sentido. Pero ahora veo que, de hecho, puede ser muy interesante. Pero esto de aquí es solo un aperitivo. Muchos piensan que necesitamos una programación externa para tratar aún más la información que se nos reportará. Pero tú puedes hacer esto directamente en SQL. Por ejemplo: Supongamos que tú quieras los datos en un cierto orden, donde los precios más altos queden al inicio y los más bajos al final. Para hacer esto, usamos un código como el que se muestra a continuación.
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT tq.of_day AS 'Data da cotação', 32. tq.price AS 'Preço Atual', 33. ts.symbol AS 'Nome do Ativo' 34. FROM tb_Quotes AS tq, tb_Symbols AS ts 35. WHERE tq.fk_id = ts.id 36. ORDER BY price DESC;
Código 05
Y el resultado de este código 05, al ser ejecutado por SQL, será lo que podemos ver a continuación.
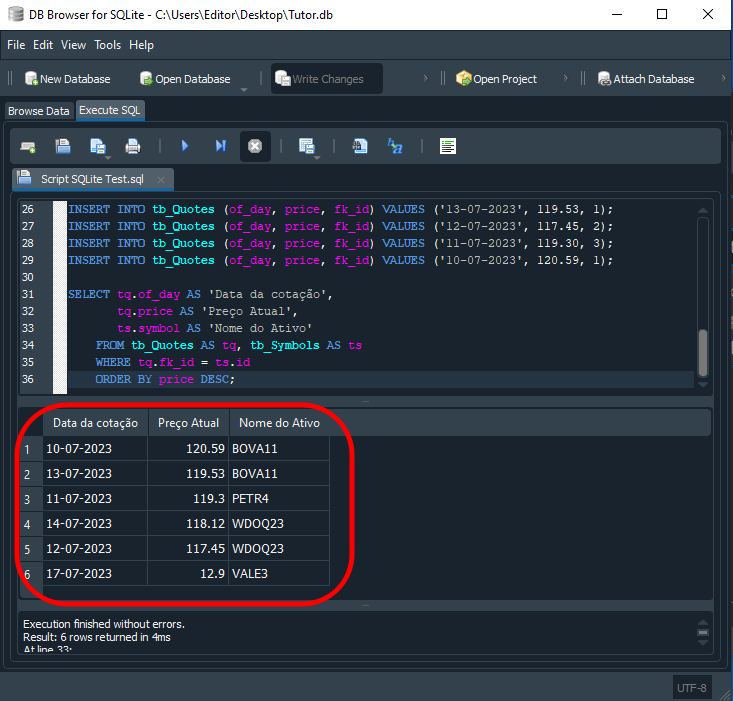
Imagen 16
Cuidado con los registros
En el artículo, Simulación de mercado (Parte 19): Iniciando SQL (II), expliqué cómo tú podrías modificar o actualizar registros usando el comando UPDATE y el comando DELETE. Aunque eso funciona, no es la mejor forma de trabajar con una base de datos relacional, ya que esa forma es muy propensa a errores cuando tenemos varias tablas relacionándose entre sí. Para entender el problema, volvamos al código 05. Lo que haremos es algo muy simple. Observa que, hasta la línea 29, creamos la base y le agregamos cosas. No importa si los datos son correctos; solo queríamos crear la base. Así, al ejecutar el SELECT en la línea 31, tenemos el resultado que se muestra a continuación.
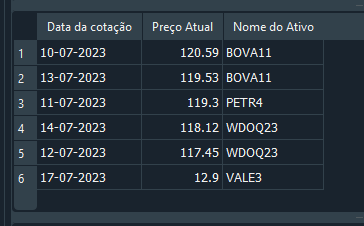
Imagen 17
Y, en este momento, tú notas que hay un registro incorrecto. Pero, en vez de recrear toda la base o borrar el registro, tú decides usar el comando UPDATE para actualizar el valor al correcto. Esto se hace como se muestra a continuación.
1. UPDATE tb_Quotes SET price = 29.58 WHERE fk_id = 3; 2. 3. SELECT tq.of_day AS 'Data da cotação', 4. tq.price AS 'Preço Atual', 5. ts.symbol AS 'Nome do Ativo' 6. FROM tb_Quotes AS tq, tb_Symbols AS ts 7. WHERE tq.fk_id = ts.id 8. ORDER BY price DESC;
Código 06
Obteniendo así el resultado que se muestra a continuación.
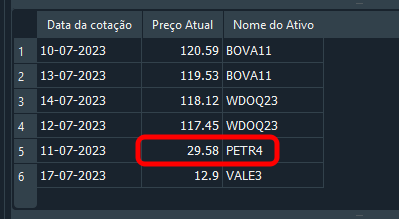
Imagen 18
Muy bien. El registro fue actualizado, y tú te sientes feliz, imaginando que ya sabes trabajar con SQL. Sin embargo, observa el código 05, donde incluimos datos en la base. Puedes notar que existe un único registro de PETR4. Entonces, la información se modificaría o incluso se eliminaría fácilmente. Pero pensemos un poco. ¿Y si, en lugar de PETR4, tú necesitaras modificar el registro de WDOQ23? ¿Cómo harías esta modificación? Tú podrías decir enseguida: Sencillo, yo usaría el siguiente comando:
01. UPDATE tb_Quotes 02. SET price = 119 03. WHERE fk_id = 2 04. AND of_day = '14-07-2023'; 05. 06. SELECT tq.of_day AS 'Data da cotação', 07. tq.price AS 'Preço Atual', 08. ts.symbol AS 'Nome do Ativo' 09. FROM tb_Quotes AS tq, tb_Symbols AS ts 10. WHERE tq.fk_id = ts.id 11. ORDER BY price DESC;
Código 07
Nuevamente, tú estás en lo correcto, ya que el resultado es el que podemos ver a continuación. Esto se debe a que tú, de forma inteligente, filtraste el resultado basándote en fk_id y en of_day.
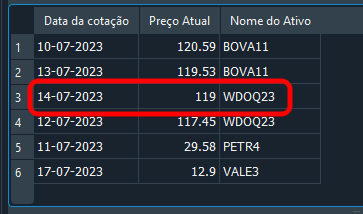
Imagen 19
Actualizando un registro en una base de datos relacional
Una buena forma, aunque no la única, de hacer una edición en una base de datos relacional es entender qué hace cada comando en SQL. O, mejor dicho: si tú no comprendes los comandos en SQL, pensarás que SQL es un lenguaje extremadamente limitado. Pero, si lo entiendes, lograrás hacer muchas cosas. Y, cuando digo muchas, es, de hecho, muchísimas cosas. Ya he visto gente usando programación externa para resolver cosas que podrían resolverse directamente usando SQL. El motivo de que la persona haga esto es que no entiende adecuadamente cómo funciona SQL. Siendo así, vamos a entender cómo hacer el mismo cambio realizado en el tema anterior, pero esta vez no necesitaremos escribir el valor de fk_id.
En este punto, tú debes estar pensando: Entonces, ¿vamos a usar un sistema de tablas no relacional? No, mi amigo lector. Mantendremos la base relacional. Así, para alcanzar el mismo objetivo logrado en el tema anterior, vamos a actualizar el código 07 a lo que se muestra a continuación.
01. UPDATE tb_Quotes 02. SET price = 4985.5 03. WHERE fk_id = (SELECT ts.id FROM tb_Symbols AS ts WHERE ts.symbol = 'WDOQ23') 04. AND of_day = '14-07-2023'; 05. 06. SELECT tq.of_day AS 'Data da cotação', 07. tq.price AS 'Preço Atual', 08. ts.symbol AS 'Nome do Ativo' 09. FROM tb_Quotes AS tq, tb_Symbols AS ts 10. WHERE tq.fk_id = ts.id 11. ORDER BY price DESC;
Código 08
Amigo, ¿qué locura es esta? ¿Estás seguro de que esto funciona? Pues yo nunca vi a nadie hacer algo tan descabellado. De hecho, tu escepticismo es adecuado, mi querido lector. Pero mira el resultado a continuación.
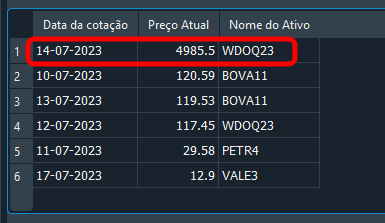
Imagen 20
Observa que puse un valor bastante diferente, justamente para mostrar que funciona. Entonces, la cuestión es: ¿cómo funciona el código de arriba? Observa que no estoy, en ningún momento, diciendo cuál es fk_id ni qué id debe buscarse. Aun así, el registro correcto se está modificando. Lo que estoy haciendo es informar el nombre del símbolo, así como la fecha en cuestión. Ya que estoy informando el nombre del símbolo, así como la fecha en cuestión. Un detalle importante aquí: aunque cada registro contenga una fecha diferente, tú debes pensar las cosas de una forma más realista. Es decir, incluso en una fecha parecida, podemos tener, en la base de datos, símbolos con cotizaciones diferentes. Por lo tanto, usar un filtrado doble, donde informamos la fecha y el símbolo, hace que la búsqueda sea considerablemente más precisa. Devolviendo exactamente la información buscada.
No sé si tú lograste notarlo, pero acabo de explicar cómo funciona el código mostrado arriba. Si tú no lograste entender o captar el mensaje, no te sientas mal. De hecho, es difícil captar las cosas así, de entrada. Pero vamos a entender con calma lo que está ocurriendo en este código 18. Observa que el comando UPDATE se colocó en varias líneas. Hice esto a propósito, para poder explicar lo que está pasando.
Muy bien, en la línea 01 decimos que queremos actualizar un registro en la tabla tb_Quotes. Si, en lugar de UPDATE, hubiéramos indicado DELETE, el registro sería eliminado de la tabla. Entonces, todo lo que explicaré también sirve para eliminar registros. Ya en la línea 02, estoy diciendo exactamente qué columna se actualizará, así como el valor que deberá constar en la columna después de la actualización. Hasta este punto, creo que todos están logrando acompañar. Ahora, en la línea 03, usando la palabra reservada WHERE, podemos informar cuál es el criterio de filtrado, a fin de que SQL sepa cómo encontrar el registro correcto. Bien, ahora presta mucha atención, porque aquí es donde está la parte que muchos principiantes no logran entender.
Cada uno de estos comandos son, en realidad, funciones. Es decir, devuelven valores. Puede ser un valor único o puede ser un valor compuesto, que contenga, en este caso, varios otros valores o campos. Entonces, cuando usamos el comando SELECT, podemos tener como retorno un valor único, como es el caso aquí. Pero también podemos tener un retorno con múltiples valores, contenidos dentro de algo que sería una tabla, justamente como ocurre cuando el comando SELECT se ejecuta en la línea 06.
Cuando el filtrado se hace de una forma muy específica y en una tabla igualmente específica, el comando SELECT devuelve algo que será único y, por lo tanto, así, este retorno puede entenderse como una variable. Pero espera un momento. SQLite no nos permite implementar variables, ¿cierto? Bueno, más o menos. Sin embargo, si tú sabes cómo manipular SQL, y no solo SQLite, podrás, virtualmente, tener variables dentro del código SQL. Esta cuestión se comprenderá mejor después, ya que necesitaremos hacer otra cosa cuando usamos tablas relacionadas, para mantener la base de datos consistente.
Pero, volviendo a la explicación, observa que, en esta línea 03, estamos diciendo cuál es el nombre del símbolo, en este caso, WDOQ23. Esto hace que SQL busque en la tabla tb_Symbols, que estamos indicando en el comando SELECT, en busca de algo. ¿Qué es ese algo? Ese algo es el valor ts.id. Es decir, cuando la búsqueda concluya, el SELECT devolverá el valor del registro de la columna id donde el nombre del símbolo es WDOQ23. Hum, interesante. Entonces, SQL buscará, en una tabla, el valor que nos dice cuál es el que debemos buscar en la otra tabla, a fin de poder encontrar el registro correcto en el que queremos hacer la modificación. ¿Es eso? Sí. Es exactamente eso lo que estamos haciendo aquí, mi querido lector. Observa que la probabilidad de error aquí es considerablemente menor.
Sin embargo, no todo es perfecto. Pues puede ocurrir que tú informes un nombre de símbolo cuyo id no se encuentre. Aunque parezca algo raro, este tipo de situación es bastante común en el día a día. Por lo tanto, este código 08 no sabrá tratar adecuadamente este tipo de situación. O, para que quede más claro, tú puedes intentar hacer algo y SQL no te dice que está mal o que no fue debidamente comprendido. Y tú te quedas imaginando que todo ocurrió perfectamente bien, ya que tendremos como resultado la presentación del resultado de la ejecución del comando SELECT de la línea 06.
En este momento, tal vez tú no entiendas por qué esto es problemático, ya que, si la implementación no indica nada incorrecto, tú quedarás con la ilusión de que todo está perfecto. Pero, cuando en un momento futuro vayas a buscar o incluso a usar esos datos que tú imaginabas que estaban allí, te llevarás una desagradable sorpresa al ver que la información no está como se esperaba. Y, muchas veces, es imposible recuperar la información correcta a fin de solucionar adecuadamente este tipo de falla.
Verificando si el registro fue actualizado
Para verificar si un registro que tú deseas actualizar se actualizó o no con éxito, hay una forma relativamente simple de hacer esto en SQLite. Para ello, necesitaremos usar un pequeño código. Pero, antes de ver el código, necesitamos pensar en algo. No es raro que muchos digan que, después de hacer una actualización o incluso insertar algún registro en la base de datos, deberíamos hacer un SELECT para analizar si todo salió bien. Hay un pequeño problema con este enfoque. Si tú estás tratando con una base pequeña o en la que, por cualquier motivo, se hicieron pocos cambios, usar un SELECT para verificar si todo ocurrió como se esperaba sí es, sí, una forma adecuada de analizar si la base se actualizó o no con éxito. Sin embargo, y principalmente en bases compartidas, si tú tienes que actualizar varios registros, la cosa no será muy simple de verificar usando un SELECT.
Afortunadamente, esas bases compartidas usan servidores. Por lo tanto, SQLite no entraría en esta situación. Pero, incluso en una base que usa SQLite, puede ocurrir, en algún momento, que tú tengas que actualizar cientos o incluso miles de registros. Piensa en todo el trabajo para analizar uno por uno, usando un SELECT para verificar si la base se actualizó o no correctamente. Es justamente esta cuestión la que nos hace tomar algún tipo de medida diferente. Verificar uno por uno los registros actualizados es algo perfectamente aceptable cuando hacemos pocos cambios en la base de datos.
Sin embargo, a medida que la carga de trabajo se intensifica y la cantidad de operaciones va aumentando, necesitamos adoptar otra forma de hacer las cosas. Además de la manera que te mostraré dentro de poco, existe otra forma casi equivalente, pero veremos eso después. En este momento, vamos a centrarnos en el primer objetivo. Es decir, cómo podemos, de alguna manera, usando SQLite, saber si todas las solicitudes de actualización de registros se ejecutaron o no.
Para hacer esto, la solución es bastante simple. Sin embargo, tú debes tener cierto cuidado, para evitar generar algún tipo de falla por el mal uso de lo que mostraré. El código de demostración se muestra a continuación.
1. UPDATE tb_Quotes 2. SET price = 4987.5 3. WHERE fk_id = (SELECT ts.id FROM tb_Symbols AS ts WHERE ts.symbol = 'WDOQ23') 4. AND of_day = '14-07-2023'; 5. 6. SELECT changes() 'Updated Records';
Código 09
Al ejecutar este código, tú verás el siguiente resultado.
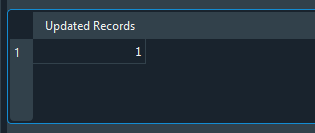
Imagen 21
Fíjate en que estamos obteniendo, como resultado, el valor de uno. ¿Por qué? El motivo es que la instrucción UPDATE está realizando una única actualización o modificación en la base de datos. Si tú ejecutarás cientos o incluso miles de actualizaciones, el valor mostrado sería exactamente la cantidad de veces que la instrucción UPDATE tuvo éxito. Sin embargo, observa el siguiente hecho: si, en este mismo código mostrado arriba, se modificara a lo que se muestra en la figura de abajo, el resultado sería otro, como puedes ver en la misma imagen.
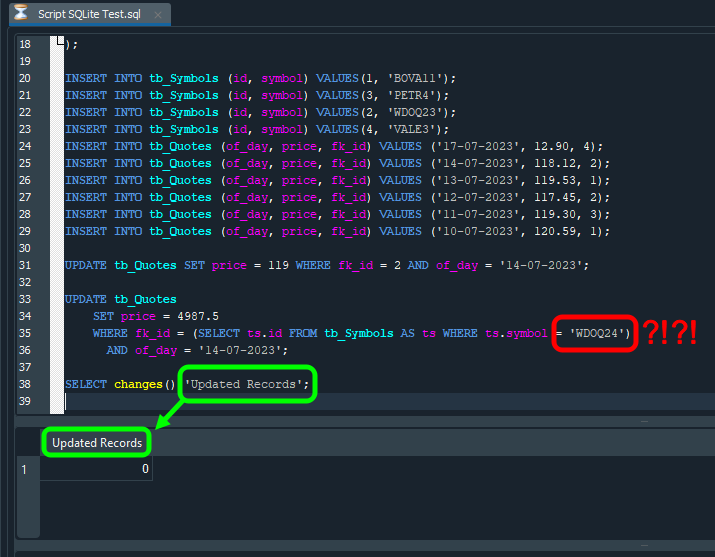
Imagen 22
En esta imagen, destaqué en rojo lo que fue modificado frente a lo que puedes ver que se hacía antes. Observa que el único cambio fue el nombre del símbolo. Y, como no existe, el comando SELECT no logrará decir cuál es el id que debe usarse. Así, el comando UPDATE no podrá ejecutarse por SQL. Por último, cuando usemos el comando SELECT, cuyo objetivo es verificar la cantidad de UPDATES que se ejecutaron correctamente, este devolverá una cantidad diferente de la que esperábamos. En este caso, cero, ya que esperábamos que se ejecutara un UPDATE. Sin embargo, debido a que indicamos el nombre de un símbolo inexistente en la tabla, no se ejecutó ningún UPDATE.
Hay otro detalle en la imagen de arriba. Este está destacado en verde. Lo que quiero decir en este punto es que el encabezado de lo que será reportado por SQL es justamente la información que se encuentra en el comando SELECT. Sin saber esto, tú podrías sentirte tentado a hacer las cosas de una manera diferente. Pero, como puedes notar, podemos controlar varias cosas con cierta facilidad.
No obstante, como te indiqué, este comando que estamos usando aquí tiene como objetivo solo verificar la cantidad de veces que un comando se ejecutó o no correctamente. Ya que SQLite nos permite desarrollar un tipo de base de datos local y personalizada, podemos hacer las cosas de una forma totalmente diferente.
Y sí, para quien no lo sepa, SQLite puede descargarse directamente del repositorio de GitHub y tener su código fuente modificado, para que podamos hacer que trabaje de una manera ligeramente diferente de lo habitual. Como el propósito de esta serie no es, de hecho, mostrar cómo hacer esto, solo estoy mencionando este hecho, ya que, dependiendo de la implementación que tú estés utilizando, en el caso específico de SQLite, puede ser que tu implementación trate las fallas de actualización o de adición de nuevos registros de una manera completamente diferente de la que mostraré. Es decir, para encontrar la mejor forma de hacer las cosas, te sugiero que estudies la documentación de la implementación que estés intentando usar.
Pero, antes de pasar al siguiente tema, veamos un detalle sobre esta forma que presenté para probar si ocurrieron o no las actualizaciones en la base de datos. Esta combinación SELECT change() solo nos mostrará el resultado de la última ejecución del comando UPDATE, en este caso. Entonces, supongamos lo siguiente: tú usas el siguiente fragmento que se muestra a continuación.
1. UPDATE tb_Quotes SET price = 119 WHERE fk_id = 2 AND of_day = '14-07-2023'; 2. 3. UPDATE tb_Quotes SET price = 4987.5 WHERE fk_id = (SELECT ts.id FROM tb_Symbols AS ts WHERE ts.symbol = 'WDOQ24') AND of_day = '14-07-2023'; 4. 5. SELECT changes() 'Updated Records';
Código 10
Observa que ahora tenemos dos comandos UPDATE ejecutándose. Obviamente, tú esperas que venga un resultado acumulativo o que sea representativo de alguna manera, ya que, en teoría, estamos usando un mismo script. Pues bien, las cosas no funcionan de esa manera. Presta mucha atención al código de la línea 03 y notarás que es exactamente el mismo que se vio en la imagen 22. Entonces, todo lo que se agregó en este código 10 es la línea 01. Muy bien. Entonces, aunque la línea 03 llegue a fallar, y fallará, en la ejecución de la línea 05, el retorno de un valor distinto de cero. Pero, al ejecutar el código, tú notas que el valor informado por SQL fue cero. ¿Qué ocurrió de manera incorrecta? ¿Será que ambas líneas, tanto la línea 01 como la línea 03, fallaron en su ejecución? No, no fallaron. Solo la línea 03 realmente falló.
Pero ¿cómo? Como, antes de analizar el resultado de la ejecución de la línea 01, hicimos un nuevo requerimiento a SQL en la línea 03, cuando le pidamos a SQL que nos diga lo que ocurrió, reportará solo el resultado de la última operación. Es decir, justamente la falla en la línea 03. Algunas personas se vuelven completamente locas al intentar entender por qué un script está o no funcionando como se esperaba. Pero todo tiene que ver con el hecho de que tú, muy probablemente, estés haciendo suposiciones. Cuando empezamos a hacer suposiciones en programación, las cosas no suelen salir muy bien, ya que las suposiciones indican que tú simplemente esperas que las cosas ocurran, y no que garantices que ocurrirán. Así que nunca hagas suposiciones. Asegúrate de que las cosas funcionen antes de empezar a lanzar insultos desde DIOS hasta el DIABLO.
Consideraciones finales
Pero, de cualquier manera, existe otro hecho, o carga, que aún necesitamos resolver, cuando hacemos uso de bases, o tablas, relacionadas, como la que estamos usando en este sistema, donde, en una tabla ponemos los nombres de los símbolos y en otra tabla ponemos los datos referentes a cotizaciones. Tal esquema podría ser mucho más elaborado y con varios enlaces, haciendo uso de varias tablas que estarían y mantendrían una relación íntima entre ellas. Todo esto haciendo uso de claves primarias y claves foráneas.
Para entender el nivel del problema, o el tamaño del hueso que tenemos que enfrentar, quiero que tú pienses e imagines el siguiente escenario: en un momento dado, en el futuro, se decide que un determinado símbolo ya no será mantenido. Esto se debe a que ya no es interesante mantenerlo u observarlo. Muy bien. Este tipo de decisión puede ocurrir tarde o temprano. El gran problema, y es aquí donde nos encontramos con el hueso en la sopa, es: ¿cómo eliminar del banco de datos los registros del símbolo? Bien, muchos podrían decir que la solución es simple. Tú simplemente haces algún tipo de bucle o alguna solicitud para que SQL elimine los registros por ti. Sí, de hecho, sería más o menos eso, si tú estuvieras trabajando con una base de datos donde tenemos una única e inmensa tabla de registros, lo que, a mi ver, es una tremenda locura. Pero está bien, cada quien sabe, o debería saber, lo que está haciendo.
Solicitarle a SQL que se borren todos los registros de un determinado símbolo sería una tarea súper simple. Todo lo que tú necesitarías hacer sería un DELETE. El comando en sí se parecería bastante al comando UPDATE. Algo trivial, en lo que no entraré en detalles aquí. Pero ¿y si la base de datos no hace uso de una tabla, sino de varias tablas que están, de alguna forma, relacionadas entre sí? ¿Cómo podrías eliminar todos los registros de un determinado símbolo? Hum. Ahora la cosa empezó a volverse un poco más complicada, ¿verdad?
Esto se debe a que, y ahora quiero que tú pienses en el esquema que estamos usando, si tú eliminaras el nombre del símbolo de la tabla tb_Symbols, con seguridad, en el momento en que fueras a buscar en la base de datos, obtendrías un cierto resultado. Esto usando el comando que se muestra a continuación.
SELECT tq.of_day AS 'Data da cotação', tq.price AS 'Preço Atual', ts.symbol AS 'Nome do Ativo' FROM tb_Quotes AS tq, tb_Symbols AS ts WHERE tq.fk_id = ts.id ORDER BY price DESC;
Código 11
| Archivo | Descripción |
|---|---|
| Experts\Expert Advisor.mq5 | Demuestra la interacción entre Chart Trade y el Asesor Experto (es necesario el Mouse Study para la interacción) |
| Indicators\Chart Trade.mq5 | Crea la ventana para configurar la orden que se enviará (es necesario el Mouse Study para la interacción) |
| Indicators\Market Replay.mq5 | Crea los controles para la interacción con el servicio de reproducción/simulador (es necesario el Mouse Study para la interacción) |
| Indicators\Mouse Study.mq5 | Permite la interacción entre los controles gráficos y el usuario (necesario tanto para operar el sistema de repetición del simulador como en el mercado real) |
| Services\Market Replay.mq5 | Crea y mantiene el servicio de reproducción y simulación de mercado (archivo principal de todo el sistema) |
| Code VS C++\Servidor.cpp | Crea y mantiene un socket servidor desarrollado en C++ (versión Mini Chat) |
| Code in Python\Server.py | Crea y mantiene un socket en Python para la comunicación entre MetaTrader 5 y Excel |
| Indicators\Mini Chat.mq5 | Permite implementar un minichat mediante un indicador (requiere el uso de un servidor para funcionar) |
| Experts\Mini Chat.mq5 | Permite implementar un minichat mediante un Asesor Experto (requiere el uso de un servidor para funcionar) |
| Scripts\SQLite.mq5 | Demuestra el uso de un script SQL mediante MQL5 |
| Files\Script 01.sql | Demuestra la creación de una tabla simple con clave foránea |
| Files\Script 02.sql | Demuestra la adición de valores en una tabla |
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/12987
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso