What to feed to the input of the neural network? Your ideas... - page 52
You are missing trading opportunities:
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
Registration
Log in
You agree to website policy and terms of use
If you do not have an account, please register
If you look at the picture, yes, it's warm and soft, but in the code it's fine.
The brackets in the picture are wrong. It should be like this.
Ola ke tal. Thought I'd throw in my ideas.
My latest model is to collect normalised prices of 10 symbols and so train a recurrence network. For input 20 bars of the month, week and day.
That's the picture I get. The difference from separate training is that the total profit is 3 times less and the drawdown.... wow, the drawdown on the control period is barely 1%.
Seems to me that solves the problem of data scarcity.
Ola ke tal. Thought I'd throw in my ideas.
My latest model is to collect normalised prices of 10 symbols and so train a recurrence network. There are 20 bars of the month, week and day per input.
That's the picture I get. The difference from separate training is that the total profit is 3 times less and the drawdown.... wow, the drawdown on the control period is barely 1%.
Seems to me that solves the problem of data scarcity.
I think you have an extremely high level of knowledge of the topic. I'm afraid I won't understand anything.
Please tell me what this beauty on the chart is: is it Python? LSTM architecture?
Is it possible to show such a thing on MT5?
normalised prices of 10 symbols
What is "ante"
In general, anything that is not a trade secret, please share)
I think you have an extremely high level of mastery of the topic. I am afraid I won't understand anything.
Please tell me what this beauty on the chart is: is it Python? LSTM architecture?
Is it possible to show such a thing on MT5?
Here too, how prices normalised.What is "ante"
In general, anything that is not a trade secret, please share).
Of course it's python. In µl5 to select data on a condition, you have to do an enumeration and all that iff iff iff iff iff. And in python in one line to select data by any condition. I'm not talking about the speed of work. It's too convenient. Mcl5 is needed to open trades with a ready-made network.
Normalisation is the most common. Minus the mean, divided by the standard deviation. The trade secret here is the normalisation period, it is important to approach it in such a way that prices are around zero for 10 years. But not so that at the beginning of 10 years they are below zero and at the end they are above zero. That's not the way to compare...
Two test periods - ante and test. The ante before training period is 6 months. It's very convenient. The ante is always there. And the test is the future, it doesn't exist. That is, it is, but only in the past. And in the future it's not. That is, it's not.
Which do you think is more important: the architecture or the input data?
Which do you think is more important: the architecture or the input data?
I think the inputs. Here I am trying 6 characters, not 10. And I'm not passing the August-December 2023 control period. Separately, it's hard too. And a 10 character pass can be legitimately chosen based on the training results. The network is always recurrent in 1 layer of 32 states, full-link only gets used.
Some summaries:
But the neural network turned out to be unnecessary. Neither MLP, nor RNN, nor LSTM, nor BiLSTM, nor CNN, nor Q-learning, nor all of these combined and mixed.
In one of such experiments I optimised 2 inputs on 3 neurons. As a result, one of the upper sets showed the following picture
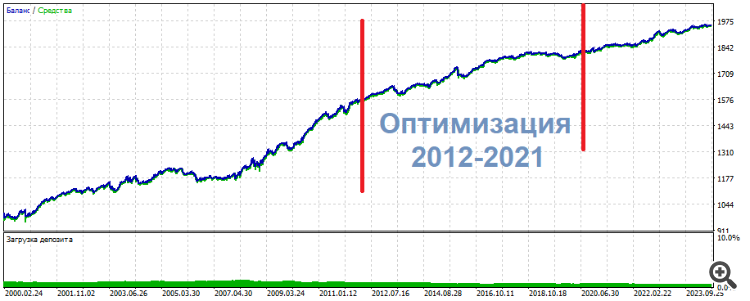
* ******* **************
UPD
Here's another set, same thing: middle - optimisation, results - on the sides. Almost the same, just more even
**********************
The trades are not pips or scalp. Rather intraday.
Thus, my subjective conclusions for the current moment:
. It is like a sighted person going blind. Just now he could see a clear silhouette, and now he can't understand what - some smear in his eyes. No information.
My opinion, as I see it
Neural network is only applicable to stationary, static patterns that have nothing to do with pricing
What kind of preprocessing, normalisation do you do? Have you tried standardisation?
Neural network remembers the path. No more than that.
Try Transformers, they say they are good for you....
oscillators are evil!
Well, not everything is so unambiguous. It's just that NS is convenient to work with continuous functions, but we need an architecture that will work with piecewise/interval functions, then NS will be able to take oscillator ranges as meaningful information.
What kind of preprocessing, normalisation do you do? Have you tried standardisation?
Try Transformers, they say they are good for you....
Well, not everything is so clear-cut. It's just that NS is convenient to work with continuous functions, but we need an architecture that will work with piecewise/interval functions, then NS will be able to take oscillator ranges as meaningful information.
1. And when how: if the data window, some increments, I bring in the range -1..1. I have not heard about standardisation
2. Accepted, thank you
3. I agree, I don't have full proof to the contrary. That's why I write from my own bell tower, as I see and imagine approximately.
Simply smoothing is a de facto erasure of information. Not generalisation. Erasure exactly. Just think of a photograph: as soon as you degrade its content, the information is irretrievably lost. And restoring it with AI is an artistic endeavour, not restoration in the true sense. It's an arbitrary re-drawing. "
Smoothing: when one number is the result of two independent information units: pattern -1/1, let's say, and pattern -6/6. The average value of each will be the same, but there were originally two patterns. They may or may not mean something, they may mean opposite signals. And here are mashki, oscillators and so on - they just stupidly erase/blur the initial "picture" of the market.
And in this "smear" we scare the NS, making it endlessly trying to work as it should.
Generalisation and smoothing are extremely unfriendly heterogeneous phenomena.
Some summaries:
But the neural network turned out to be unnecessary. Neither MLP, nor RNN, nor LSTM, nor BiLSTM, nor CNN, nor Q-learning, nor all of these combined and mixed.
In one of such experiments I optimised 2 inputs on 3 neurons. As a result, one of the upper sets showed the following picture
* ******* **************
UPD
Here's another set, same thing: middle - optimisation, results - on the sides. Almost the same, just more even
**********************
The trades are neither pips nor scalp. Rather intraday.
Thus, my subjective conclusions at the moment:
. It is like a sighted person going blind. Just now he could see a clear silhouette, and now he can't understand what - some smear in his eyes. No information.
My imho, as I see it
not a weak pips.
Is it time to sew bags?