Хорошо, чуть позже (часа через 2-3), попробую обоснованно показать, каким образом профит (или что то другое, не важно, что мы хотим получить от сети) зависит от фитнес функции.
А гарантию того, что мы получим профит в будующем, конечно, никто дать никогда не сможет. А вот к чему стремится должна сетка, пожалуй, мы должны определять для неё однозначно.
Как и обещал выкладываю картинку и пояснения к ней. Сеть: MLP один скрытый слой. 2000 точек в обучении. 1000 на аут оф сампле) На вход были даны текущее и пред значение ЕМА с первой картинки, а также пред клоуз с первой и второй картинки. Все! Почему все и так мало? Да потому, что увеличение кол-ва нейронов, слоев, входов и т.д. на результат ВООБЩЕ не влияет. Это меня и пугает) Причем, то, что изображено в качестве прогноза, можно получить, ну очень простой формулой, которая ручками считается. Почему так мне непонятно. Что нужно менять? Можно ли сделать лучше?
mrstock>>: Изначально я давал 40 последних клоузов с первого и второго чарта, а также 40 значений ема с первого чарта - результат тот же, почти один в один! Давал вместо абс значений %-ые приращения - тоже самое! Разница лишь в сотых долях %. Если итоговый "прогноз" и был более плавный, но я разницы на заметил. Можно подать одино из пред значений ЕМА, которую и нужно получить на выходе. В этом случае прогноз 100% т.к. формула ЕМА как Вы помните реккурентная, но в этом случае сети не нужны))))) Вот я и не могу понять, что такое, где я ошибаюсь.
同意。这就是我想问的,误差和利润之间有什么关系,最好是在OOS....))
Too joo你说过,有问题的结果可能是由于数据正常化造成的,我回答说没有。
我同意Leo的观点,决定最终利润的并不总是错误标准,但在我现在面临的任务中,错误才是最重要的。我将在今晚发布网格所做的预测,以获得其他人对预测质量的意见和可能的改进)
Хорошо, чуть позже (часа через 2-3), попробую обоснованно показать, каким образом профит (или что то другое, не важно, что мы хотим получить от сети) зависит от фитнес функции.
А гарантию того, что мы получим профит в будующем, конечно, никто дать никогда не сможет. А вот к чему стремится должна сетка, пожалуй, мы должны определять для неё однозначно.
你不必浪费你的时间,因为 "想要 "和 "得到 "之间的区别根本不是哲学问题,尽管它是用 "主观 "和 "客观 "的哲学概念制定的。
拟合上的结果与均方根误差成反比,这一点不用你说我们也知道。
毫不含糊地说,净值必须以OOS的利润为目标。否则就没有意义了。
То, что результаты на подгонке обратно пропорциональны среднеквадратичной ошибке - это мы и без Вас знаем.
你也在使用均方根误差吗?你是emc网络之父。:)
雷舍托夫 写道(a)>>
肯定的是,网络必须以OOS的利润为目标。否则就没有意义了。
这是可以理解的。另一个问题是它应该如何争取。
Вы тоже что ли используете среднеквадратичную ошибку? Отец эмкуэльных сетей Вы наш. :)
Это и ежу понятно. Другой вопрос, как она должна к этому стремится.
我不使用均方根误差进行交易,因为它只表征拟合的质量。
因此,样本中的误差决不应倾向于
如同承诺的那样,我在这里贴出一张图片和对它的解释。网络:MLP一个隐藏层。训练中的2000分。1000在出样器上)我从第一张图片中收到了电流和预EMA,从第一张和第二张中收到了预关闭。就这样吧!为什么是所有的,而不是那么少?因为增加神经元、层、输入等的数量根本不影响结果。这就是让我害怕的地方)而显示为预测的东西,你可以得到,嗯,一个非常简单的公式,是用手计算的。为什么我这么不清楚。我应该改变什么?能否做得更好?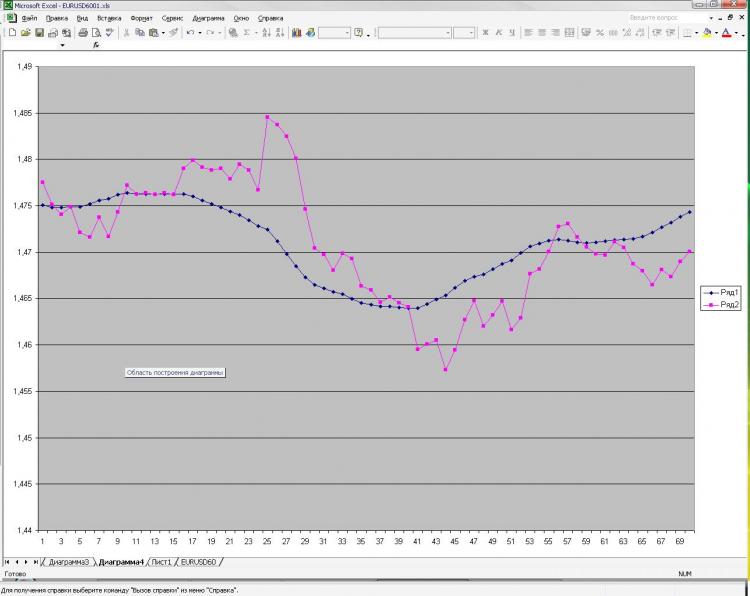
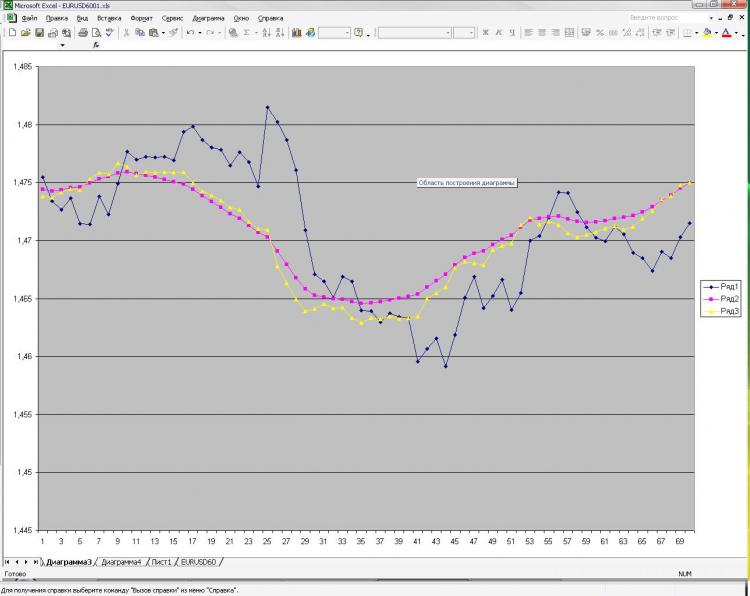
Как и обещал выкладываю картинку и пояснения к ней. Сеть: MLP один скрытый слой. 2000 точек в обучении. 1000 на аут оф сампле) На вход были даны текущее и пред значение ЕМА с первой картинки, а также пред клоуз с первой и второй картинки. Все! Почему все и так мало? Да потому, что увеличение кол-ва нейронов, слоев, входов и т.д. на результат ВООБЩЕ не влияет. Это меня и пугает) Причем, то, что изображено в качестве прогноза, можно получить, ну очень простой формулой, которая ручками считается. Почему так мне непонятно. Что нужно менять? Можно ли сделать лучше?
你已经描述了近似的问题。两个 "参考 "点并不足以描述形状。此外,你还提供了每个人的一个克隆点,它不仅没有描述曲率,而且还是一条直线。从每组输入参数中至少尝试3个点。即三个EMA点和三个子句点,所以有6个输入神经元,隐藏层有6到12个神经元。对于这个问题,隐藏层中更多的神经元数量是不合理的。
Изначально я давал 40 последних клоузов с первого и второго чарта, а также 40 значений ема с первого чарта - результат тот же, почти один в один! Давал вместо абс значений %-ые приращения - тоже самое! Разница лишь в сотых долях %. Если итоговый "прогноз" и был более плавный, но я разницы на заметил. Можно подать одино из пред значений ЕМА, которую и нужно получить на выходе. В этом случае прогноз 100% т.к. формула ЕМА как Вы помните реккурентная, но в этом случае сети не нужны))))) Вот я и не могу понять, что такое, где я ошибаюсь.
在这里给我一个样本,我在Statistica里试试