交易中的机器学习:理论、模型、实践和算法交易 - 页 558 1...551552553554555556557558559560561562563564565...3399 新评论 Alexander_K2 2018.01.09 13:04 #5571 最重要的是--来自R.Feynman关于量子转换的概率振幅的专著的数字有点让人想起SanSanych发布的图表,不是吗?我在这里 - 我即将开始广播一个新的理论,为期3或4个月...^)))))))) Maxim Dmitrievsky 2018.01.09 14:02 #5572 亚历山大_K2。最重要的是--来自R.Feynman关于量子转换的概率振幅的专著的数字有点让人联想到SanSanych发布的图表,不是吗?我在这里 - 我即将开始广播一个新的理论,为期3-4个月...^))))))))最主要的是不要让这一切成为永恒:)看起来是这样,但这里是不同振幅的概率,比如说,在一个去趋势的图表上。而如果我们加上趋势成分,就会更加复杂了 Yuriy Asaulenko 2018.01.09 14:52 #5573 亚历山大_K2。我来了--我即将开始广播一个新的理论,为期3或4个月...^)))))))) 为这个问题开一个话题,然后...(欢迎你做一年的工作。)) Vizard_ 2018.01.10 12:48 #5574 马克西姆-德米特里耶夫斯基。事实证明,即使是训练样本之外的简单NS也不能很好地发挥作用 ....不是一个简单的NS,而是一个特定配置的NS。从上到下 -产生了这个(1)-这个(2),适合这个(3) ......))))) Maxim Dmitrievsky 2018.01.10 12:59 #5575 Vizard_。 不是一个简单的NS,而是一个具有一定配置的NS。从上到下 -由this(1)-this(2)生成,适合this(3)......)))))我的大脑终于崩溃了:)去它的,我就转换BP吧:)哦,这个非线性的世界......在背景中听着戈登的歌:) Alexander_K2 2018.01.10 13:33 #5576 马克西姆-德米特里耶夫斯基。 这就是我的大脑最终崩溃的地方:)他妈的,我只是转换BP :)Vizard_的 帖子让我的量子大脑也崩溃了......。我想这是R.Feynman的近亲,他在这里用这个绰号写作 :)))) Yuriy Asaulenko 2018.01.10 15:35 #5577 马克西姆-德米特里耶夫斯基。 这就是为什么很容易混淆的原因,比方说,我们以前使用线性或回归,一切都很好,然后我们决定换成MLP来完成同样的任务......也没办法 :)这就是为什么每个人都喜欢使用分类法,尽管回归法对预测有好处 :)我甚至会说,线性或回归更适合于趋势,而MLP更适合于平坦的。那么,首先,我们只需要分类--是否进入交易。这就是全部。我们不需要其他东西--只有1和0,MLP做得非常好。我们为什么需要预测?- 这一点绝对不清楚。其次,对于MLP,我们需要明确制定任务,并消除所有不必要的东西,把它留给算法方法。第三,在训练过程中不要把你的解决方案强加给MLP,就像大多数本地文章中所做的那样。 Maxim Dmitrievsky 2018.01.10 15:44 #5578 尤里-阿索连科。嗯,首先,我们需要的是一个分类--进入或不进入交易。这就是全部。我们不需要其他东西--只需要1和0,MLP就可以了。我们为什么需要预测?- 这一点绝对不清楚。其次,对于MLP,我们需要明确制定任务,并消除所有不必要的东西,把它留给算法方法。第三,在训练中,不要把你的解决方案强加给MLP,就像大多数本地文章那样。预测是一种崩溃的方式,但你可以估计未来不稳定的概率 :) 预测是需要的,以使系统适应新的条件,Ns本身定期对市场变化进行再培训。一个分类器只是用第一个ns的结果工作。分类也是一种预测,但通过海湾/单元的组合,即简单的优化,它可以用标准的优化器相当有质量地完成。是啊,反正不知道,我就是这么做的,很好玩。+ 我没有像你那样的神经细胞,而且mql版本也没有。我也会一次完成2个变体,我们将拭目以待......我在假期中忘记了它。 Yuriy Asaulenko 2018.01.10 15:57 #5579 马克西姆-德米特里耶夫斯基。 预测是一条通往崩溃的道路,但你可以估计未来不稳定的概率 :)分类也是预测,但通过海湾/单元的组合,即简单的优化,它可以通过标准的优化器而定性地完成分类器很可能应对不稳定的概率,至少在交易可能相关的边界上是如此。内部优化器的质量好吗?- 完全不确定,比较确定的是相反)。马克西姆-德米特里耶夫斯基。 + 我没有像你这样的神经网络,而且我在mql中也没有这样的神经网络。 是什么阻止了你这样做?)我不隐藏我的NS。)我也不隐藏我的方法。我只是不透露细节。 Maxim Dmitrievsky 2018.01.10 16:00 #5580 尤里-阿索连科。分类器可以很好地处理波动概率,至少在交易可能相关的边界处。一般来说,概率问题可能根本就没有解决方案。内部优化器的质量好吗?- 我一点也不确定,我比较确定是相反的)。在这里,我做了一个预测工具,然后在一些历史上,我立即评估它的质量......如果质量还可以,那么我教第二个人根据预测进行交易,它只是定义了最佳的买入/卖出位置。(一开始用的是模糊逻辑,后来我决定把它改成布尔逻辑)。我不知道,但在云端太贵了,如果有很多参数,同一天就会像你的情况一样被训练......任务是一样的--目标函数的优化。 1...551552553554555556557558559560561562563564565...3399 新评论 您错过了交易机会: 免费交易应用程序 8,000+信号可供复制 探索金融市场的经济新闻 注册 登录 拉丁字符(不带空格) 密码将被发送至该邮箱 发生错误 使用 Google 登录 您同意网站政策和使用条款 如果您没有帐号,请注册 可以使用cookies登录MQL5.com网站。 请在您的浏览器中启用必要的设置,否则您将无法登录。 忘记您的登录名/密码? 使用 Google 登录
最重要的是--来自R.Feynman关于量子转换的概率振幅的专著的数字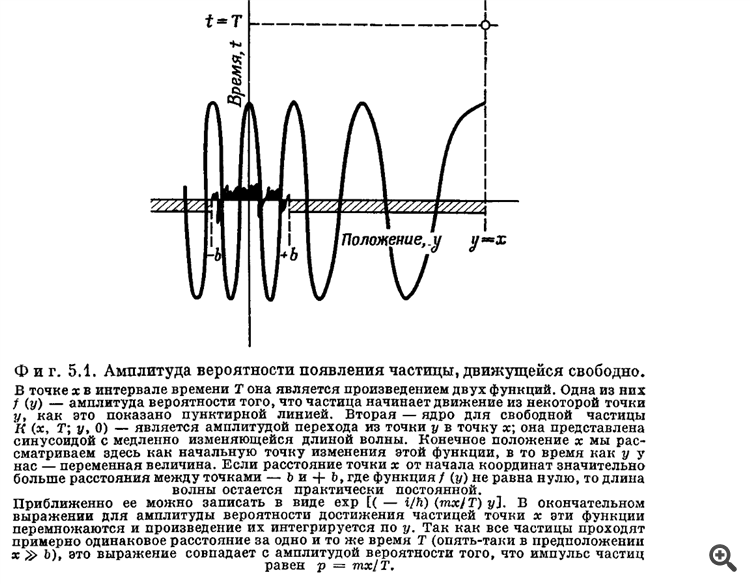
有点让人想起SanSanych发布的图表,不是吗?
我在这里 - 我即将开始广播一个新的理论,为期3或4个月...^))))))))
最重要的是--来自R.Feynman关于量子转换的概率振幅的专著的数字
有点让人联想到SanSanych发布的图表,不是吗?
我在这里 - 我即将开始广播一个新的理论,为期3-4个月...^))))))))
最主要的是不要让这一切成为永恒:)看起来是这样,但这里是不同振幅的概率,比如说,在一个去趋势的图表上。而如果我们加上趋势成分,就会更加复杂了
我来了--我即将开始广播一个新的理论,为期3或4个月...^))))))))
事实证明,即使是训练样本之外的简单NS也不能很好地发挥作用 ....
不是一个简单的NS,而是一个特定配置的NS。从上到下 -
产生了这个(1)-这个(2),适合这个(3) ......)))))
不是一个简单的NS,而是一个具有一定配置的NS。从上到下 -
由this(1)-this(2)生成,适合this(3)......)))))
我的大脑终于崩溃了:)去它的,我就转换BP吧:)
哦,这个非线性的世界......在背景中听着戈登的歌:)
这就是我的大脑最终崩溃的地方:)他妈的,我只是转换BP :)
Vizard_的 帖子让我的量子大脑也崩溃了......。
我想这是R.Feynman的近亲,他在这里用这个绰号写作 :))))
这就是为什么很容易混淆的原因,比方说,我们以前使用线性或回归,一切都很好,然后我们决定换成MLP来完成同样的任务......也没办法 :)
这就是为什么每个人都喜欢使用分类法,尽管回归法对预测有好处 :)
我甚至会说,线性或回归更适合于趋势,而MLP更适合于平坦的。
那么,首先,我们只需要分类--是否进入交易。这就是全部。我们不需要其他东西--只有1和0,MLP做得非常好。我们为什么需要预测?- 这一点绝对不清楚。
其次,对于MLP,我们需要明确制定任务,并消除所有不必要的东西,把它留给算法方法。第三,在训练过程中不要把你的解决方案强加给MLP,就像大多数本地文章中所做的那样。
嗯,首先,我们需要的是一个分类--进入或不进入交易。这就是全部。我们不需要其他东西--只需要1和0,MLP就可以了。我们为什么需要预测?- 这一点绝对不清楚。
其次,对于MLP,我们需要明确制定任务,并消除所有不必要的东西,把它留给算法方法。第三,在训练中,不要把你的解决方案强加给MLP,就像大多数本地文章那样。
预测是一种崩溃的方式,但你可以估计未来不稳定的概率 :) 预测是需要的,以使系统适应新的条件,Ns本身定期对市场变化进行再培训。
一个分类器只是用第一个ns的结果工作。
分类也是一种预测,但通过海湾/单元的组合,即简单的优化,它可以用标准的优化器相当有质量地完成。
是啊,反正不知道,我就是这么做的,很好玩。
+ 我没有像你那样的神经细胞,而且mql版本也没有。
我也会一次完成2个变体,我们将拭目以待......我在假期中忘记了它。
预测是一条通往崩溃的道路,但你可以估计未来不稳定的概率 :)
分类也是预测,但通过海湾/单元的组合,即简单的优化,它可以通过标准的优化器而定性地完成
分类器很可能应对不稳定的概率,至少在交易可能相关的边界上是如此。
内部优化器的质量好吗?- 完全不确定,比较确定的是相反)。
+ 我没有像你这样的神经网络,而且我在mql中也没有这样的神经网络。
分类器可以很好地处理波动概率,至少在交易可能相关的边界处。一般来说,概率问题可能根本就没有解决方案。
内部优化器的质量好吗?- 我一点也不确定,我比较确定是相反的)。
在这里,我做了一个预测工具,然后在一些历史上,我立即评估它的质量......如果质量还可以,那么我教第二个人根据预测进行交易,它只是定义了最佳的买入/卖出位置。
(一开始用的是模糊逻辑,后来我决定把它改成布尔逻辑)。
我不知道,但在云端太贵了,如果有很多参数,同一天就会像你的情况一样被训练......任务是一样的--目标函数的优化。