交易中的机器学习:理论、模型、实践和算法交易 - 页 169 1...162163164165166167168169170171172173174175176...3399 新评论 sibirqk 2016.10.20 11:15 #1681 mytarmailS:如果你把塞子拿掉,就没有什么...但也有玻璃、T&S、OI...等等......。你将不会得到报酬。 我明白了,谢谢你。mytarmailS:如果你在一分钟内做几笔交易,你将无法在外汇市场上生存下去...即使你奇迹般地获得了100万分之一的机会,也不能保证你能得到报酬。嗯,又是交易条件。 mytarmailS 2016.10.20 11:20 #1682 Mihail Marchukajtes: 如果你不能够使用它,R-ka也不会帮助你。做NS顾问是一回事,做用户是另一回事。这些是非常不同的事情...我认为没有人是这样的,这叫让人感到荒谬,而且 是为了让主持人明白他的言论的荒谬性,雷谢托夫与此无关......你决定用excel计算平均数,你在mql论坛上写东西,你是一个寄生虫,因为你可以在mt5里做,mql没有帮助mql社区,明白吗?你是一个寄生虫,迈克尔,因为你使用JProjection,这就是它的作用...:) Mihail Marchukajtes 2016.10.20 11:44 #1683 我使用它,但我最终还是用MQL来写,或者说是把网插入指标中,所以.....,我有点像寄生虫,但很有用 :-) Andrey Dik 2016.10.20 13:38 #1684 mytarmailS:R与此无关,用什么写有什么区别?这是一个方便的问题,没有更多的....。在这里,Reshetov用Java写了他的JProjected,禁止它,它不是mql,它没有用,这个叫什么的--寄生虫!!!!。那是一个词。雷舍托夫是在假设结果将被用于MT的情况下制作他的程序的。他写了很多顾问,想出了成千上万的点子,而且都对MT有用,所以他作为一个普及者做了很多,很多。你可以用上帝的迅捷写出你想要的东西,但你需要社区能够在MT中使用它,否则你对社区就没有用处。一个被珍视和培育的社区,通过投入巨额资金而得到了扩展。 Andrey Dik 2016.10.20 13:41 #1685 sibirqk:如果你有一个可行的想法,把它翻译成MCL并不难。而他在这里而不是在R论坛上写文章是可以理解的--R是无底洞,一个高度专业化的社区是不容易找到的。而对于MT社区来说,他是一笔毋庸置疑的财富。 R可能有一个交易社区,但与MQL社区相比,它是0,你不能在那里得到一个新的想法,所以它在这里摩擦而不是在那里。 Vizard_ 2016.10.20 18:23 #1686 阿列克谢-伯纳科夫。 在不同的时间范围内对其他样本进行交叉验证。Dr.Trader: 假设我有一年的训练数据。我想训练12个模型--一个使用1月的数据,另一个使用2月的数据。阿列克谢-伯纳科夫。 这是一个契机。 没有科学的短语,如--对于预测因素不完全......,或.....)的情况。) 让我们以简单、清晰的数据为例,对其进行建模...培训。蓝点--趋势。红点-验证。 n1;n2;目标 1;0;1 1;1;2 1;0;1 1;1;2 1;0;1 1;0;1 1;1;2 1;0;1 1;0;1 1;0;1 左上角50%的趋势,50%有效。右上角--与混合。 对于OOS(底部),让我们通过愚蠢地增加以前的样本来增加样本。因为在现实中我们不知道未来。 只要测试(OOS)与训练点相对应,一切都很好。 在1.5时,该模型跌跌撞撞...省略了使用验证性和原始性的小优势在现实生活中,我们有大致相同的图片... СанСаныч Фоменко 2016.10.20 18:56 #1687 这是资源所有者的官方观点。从这里开始Renat Fatkhullin 2016.10.11 03:43#RU请停止指责。每种语言都有它的位置。R对交互式研究很有帮助。这是我第二天探索它(我之前读过这本书),它看起来真的是一个强大的调试器,具有可视化的内部结构。与R合作,立即暴露了我们的弱点。MQL5有少数强大的功能用于频繁的操作。对于许多事情,你应该编写微代码。在接下来的两次构建中,我们将推出几十个新的功能,以便在一次调用中进行复杂操作。需要更多的数学功能。我们已经发布了R函数类似物的第一个测试版本,现在将通过增加矢量变体来进一步推动它。我们需要一个简单而强大的图形库,其功能类似于R中的图形包。我们将以R为中心进行创作。我们这样做是为了什么?早在2001年,我们就发布了MQL的第一个算法交易平台。每一次我们都增加了它的可能性,但数学工具箱却不是那么好。我们开发了分析、数据访问、测试器、分布式计算,然后我们进入了销售产品的阶段。然后很明显的是,大多数解决方案都陷入了一个恶性循环,即分析、指标和装配。我们需要让开发者在数学能力上更上一层楼。这就是为什么前段时间我们开始在MQL5中扩展数学库,并且还发布了Alglib、Fuzzy和Stat的测试版本。他们将简化从其他系统转移到MQL5的模型,这将提高为Metatrader 5平台 创建的分析解决方案的等级。在接下来的2个月里,你将看到我们在发展数学环境方面取得的进展。我们欢迎,并欢迎关于复杂数学包的讨论和文章。撰写并向拉希德-乌马罗夫发送文章请求。我们的任务是鼓励和教育交易者掌握更复杂的技术,而不是把自己围困在自己的MQL5世界里。当然,我们捍卫并将继续捍卫我们的语言和平台免受攻击,但我们也在努力发展它们。所以一切都会好起来的。PS。我的强调 Dr. Trader 2016.10.20 19:22 #1688 Vizard_。在现实世界中,我们有一张这样的图片...... 我不完全理解你的结论。 该模型只有在已知的数据上才会起作用?也就是说,当对新的数据进行预测时,不管是什么类型的故障(有/无混合),它都会开始磕磕绊绊的?省钱的唯一方法是不做交易。我这样做不仅是为了选择模型的参数,也是为了选择指标及其参数。我从mt5下载了10000个具有不同参数和滞后期的指标,然后我使用遗传学来搜索这个列表中使用的指标和模型参数(森林中的树,神经元中的层,等等)。你可以说这是我寻找恒定依赖关系的方法。 如果我在MT5中采取一套标准参数的标准指标,那么我将不会有任何模型与之交叉验证,无论是神经元卡还是树。要找到一组指标,让模型在这种交叉验证中给出积极的结果,是一个需要大量工作和时间的成就。一个积极的结果是一个一定的标准,即所有预测因素之间在空间和时间上存在着恒定的相关性。无论采取哪种区间进行训练--模型都会找到相同的依赖关系,并依靠它们。下面的图片是这种交叉验证的一个例子。每条黑线是集合体中每个单独模型的贸易结果(平衡增长)。红线是集合中大多数模型的交易结果。那里大约有1/3的模型根本无法获得任何利润,尽管遗传学花了一天多的时间来搜索所有的变体,即这是可以找到的最好的结果之一,尽管结果甚至不是很好。如果你免费拨打任何标准指标,所有这些黑扇子都会下降,红线会在屏幕外下降。 Vizard_ 2016.10.20 20:03 #1689 Dr.Trader: 这已经有点绝望和老套了,省钱的唯一方法就是不交易。 下图是这种交叉认证的一个例子。每条黑线是集合体中每个单独模式的交易结果(平衡增长)。红线是交易大多数模型的结果 不,只是对实际发生的事情进行视觉上的表述。 寻找解决方案...在这些现实中。------------------------------------------------------------------------ 屏幕左侧的缩水情况还不错,模型没有描述这个区域... Alexey Burnakov 2016.10.20 21:19 #1690 我对你们俩的回答是。如果在选择模型的数据上对其进行评估,那么该模型就没有价值。即使它是一段没有经过训练的模型的数据。想一想吧。有1)过度学习。这就是你把训练数据上的模型赶到一个接近完美的状态。在其他数据上,没有可概括性。还有就是2)选择偏差(乐观的模型选择)。这是在已经知道模型行为的数据上选择最佳模型或委员会。再说一遍--即使它是一个测试案例。你得到这个现实。一个由交叉验证测试块选择的未经训练的模型(一个在测试中走向正方的模型)有可能被拟合到TEST上。为了减少这种影响,我们发明了嵌套交叉验证法。已经选定的模型(或委员会)应在其他数据上进一步测试。换句话说--这是对模型选择方法的验证。再一次,我也有几十个模型,我也在预测器和参数中翻滚。而这些模型在每一个8年的时间里,都会进入稳固的加分项!而这就是测试期。但是,当通过测试选出的 "最佳 "模型被延迟抽样测试时,就会出现意外。这就是所谓的--模型拟合交叉验证。当它是清楚的,纯粹的实验继续进行。如果不清楚的话,你会看到现实世界中质量的多重下降。这就是你在99%的时间里看到的情况。 1...162163164165166167168169170171172173174175176...3399 新评论 您错过了交易机会: 免费交易应用程序 8,000+信号可供复制 探索金融市场的经济新闻 注册 登录 拉丁字符(不带空格) 密码将被发送至该邮箱 发生错误 使用 Google 登录 您同意网站政策和使用条款 如果您没有帐号,请注册 可以使用cookies登录MQL5.com网站。 请在您的浏览器中启用必要的设置,否则您将无法登录。 忘记您的登录名/密码? 使用 Google 登录
如果你把塞子拿掉,就没有什么...
但也有玻璃、T&S、OI...等等......。
你将不会得到报酬。
我明白了,谢谢你。
如果你在一分钟内做几笔交易,你将无法在外汇市场上生存下去...即使你奇迹般地获得了100万分之一的机会,也不能保证你能得到报酬。
嗯,又是交易条件。
如果你不能够使用它,R-ka也不会帮助你。做NS顾问是一回事,做用户是另一回事。这些是非常不同的事情...
我认为没有人是这样的,这叫让人感到荒谬,而且 是为了让主持人明白他的言论的荒谬性,雷谢托夫与此无关......
你决定用excel计算平均数,你在mql论坛上写东西,你是一个寄生虫,因为你可以在mt5里做,mql没有帮助mql社区,明白吗?
你是一个寄生虫,迈克尔,因为你使用JProjection,这就是它的作用...:)
R与此无关,用什么写有什么区别?这是一个方便的问题,没有更多的....。在这里,Reshetov用Java写了他的JProjected,禁止它,它不是mql,它没有用,这个叫什么的--寄生虫!!!!。
那是一个词。
雷舍托夫是在假设结果将被用于MT的情况下制作他的程序的。他写了很多顾问,想出了成千上万的点子,而且都对MT有用,所以他作为一个普及者做了很多,很多。
你可以用上帝的迅捷写出你想要的东西,但你需要社区能够在MT中使用它,否则你对社区就没有用处。一个被珍视和培育的社区,通过投入巨额资金而得到了扩展。
如果你有一个可行的想法,把它翻译成MCL并不难。而他在这里而不是在R论坛上写文章是可以理解的--R是无底洞,一个高度专业化的社区是不容易找到的。而对于MT社区来说,他是一笔毋庸置疑的财富。
在不同的时间范围内对其他样本进行交叉验证。
假设我有一年的训练数据。我想训练12个模型--一个使用1月的数据,另一个使用2月的数据。
这是一个契机。
让我们以简单、清晰的数据为例,对其进行建模...培训。蓝点--趋势。红点-验证。
n1;n2;目标
1;0;1
1;1;2
1;0;1
1;1;2
1;0;1
1;0;1
1;1;2
1;0;1
1;0;1
1;0;1
左上角50%的趋势,50%有效。右上角--与混合。
对于OOS(底部),让我们通过愚蠢地增加以前的样本来增加样本。因为在现实中我们不知道未来。
只要测试(OOS)与训练点相对应,一切都很好。
在1.5时,该模型跌跌撞撞...省略了使用验证性和原始性的小优势
在现实生活中,我们有大致相同的图片...
这是资源所有者的官方观点。
从这里开始
请停止指责。
每种语言都有它的位置。R对交互式研究很有帮助。这是我第二天探索它(我之前读过这本书),它看起来真的是一个强大的调试器,具有可视化的内部结构。
与R合作,立即暴露了我们的弱点。
早在2001年,我们就发布了MQL的第一个算法交易平台。每一次我们都增加了它的可能性,但数学工具箱却不是那么好。我们开发了分析、数据访问、测试器、分布式计算,然后我们进入了销售产品的阶段。
然后很明显的是,大多数解决方案都陷入了一个恶性循环,即分析、指标和装配。我们需要让开发者在数学能力上更上一层楼。
这就是为什么前段时间我们开始在MQL5中扩展数学库,并且还发布了Alglib、Fuzzy和Stat的测试版本。他们将简化从其他系统转移到MQL5的模型,这将提高为Metatrader 5平台 创建的分析解决方案的等级。
在接下来的2个月里,你将看到我们在发展数学环境方面取得的进展。
我们欢迎,并欢迎关于复杂数学包的讨论和文章。撰写并向拉希德-乌马罗夫发送文章请求。我们的任务是鼓励和教育交易者掌握更复杂的技术,而不是把自己围困在自己的MQL5世界里。
当然,我们捍卫并将继续捍卫我们的语言和平台免受攻击,但我们也在努力发展它们。所以一切都会好起来的。
PS。
我的强调
在现实世界中,我们有一张这样的图片......
我不完全理解你的结论。
该模型只有在已知的数据上才会起作用?也就是说,当对新的数据进行预测时,不管是什么类型的故障(有/无混合),它都会开始磕磕绊绊的?
省钱的唯一方法是不做交易。
我这样做不仅是为了选择模型的参数,也是为了选择指标及其参数。我从mt5下载了10000个具有不同参数和滞后期的指标,然后我使用遗传学来搜索这个列表中使用的指标和模型参数(森林中的树,神经元中的层,等等)。你可以说这是我寻找恒定依赖关系的方法。
如果我在MT5中采取一套标准参数的标准指标,那么我将不会有任何模型与之交叉验证,无论是神经元卡还是树。要找到一组指标,让模型在这种交叉验证中给出积极的结果,是一个需要大量工作和时间的成就。一个积极的结果是一个一定的标准,即所有预测因素之间在空间和时间上存在着恒定的相关性。无论采取哪种区间进行训练--模型都会找到相同的依赖关系,并依靠它们。
下面的图片是这种交叉验证的一个例子。每条黑线是集合体中每个单独模型的贸易结果(平衡增长)。红线是集合中大多数模型的交易结果。那里大约有1/3的模型根本无法获得任何利润,尽管遗传学花了一天多的时间来搜索所有的变体,即这是可以找到的最好的结果之一,尽管结果甚至不是很好。如果你免费拨打任何标准指标,所有这些黑扇子都会下降,红线会在屏幕外下降。
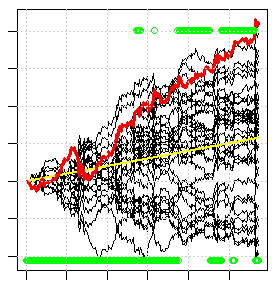
寻找解决方案...在这些现实中。
------------------------------------------------------------------------
屏幕左侧的缩水情况还不错,模型没有描述这个区域...