交易中的机器学习:理论、模型、实践和算法交易 - 页 146 1...139140141142143144145146147148149150151152153...3399 新评论 Vladimir Karputov 2016.10.09 12:02 #1451 mytarmailS:我不是外汇交易员,我甚至不熟悉Metatrader :)我想在P中实验不同的配置文件,我只是不明白如何使两个向量的分布我想尝试不同的型材变体,只是不清楚用两个矢量来构建它,不一定要有体积,这只是一个开始,你几乎可以把任何东西放入型材,但应该用价格来做,这就是两个矢量。 那么你在这个论坛上做什么呢?一个完全致力于MetaTrader的论坛?毕竟,之前已经说过了--不会有来自MetaTrader生态系统之外的直接访问(API)。 mytarmailS 2016.10.09 12:11 #1452 卡尔普托夫-弗拉基米尔。 那你在这个论坛上做什么呢?一个完全专注于MetaTrader的论坛?你之前已经说过,将不会有从外部直接访问(API)MetaTrader生态系统的机会。阅读本主题的标题,告诉我Metatrader是如何参与的?那么这次讨论的重点是什么呢? Vladimir Karputov 2016.10.09 12:16 #1453 mytarmailS:阅读本主题的标题,告诉我Metatrader是如何参与的?这场讨论的重点到底是什么? 终端配备了新的数学库,比如说这些。(讨论 "MQL5中的统计分布--使用R的精华")--你为什么不为MetaTrader发布例子? mytarmailS 2016.10.09 12:44 #1454 卡尔普托夫-弗拉基米尔。 例如,新的数学库出现在终端的交付中。(讨论文章 "MQL5中的统计分布--使用R的精华")--你为什么不发表MetaTrader的例子?我不知道怎么做 :) 我对MQL不熟悉无论如何,即使是我(不是程序员) 也明白,我不能用内置函数来做,我必须自己写所有的东西......你从R 中翻译了十几个统计函数,这当然很好,甚至值得称赞,但要明白这与R的 能力相比连沧海一粟都算不上, 它在不断发展,每天都有新的库出现,不是函数而是库,你怎么能跟得上呢? 又为什么呢? 它根本就必须用... Andrey Dik 2016.10.09 13:07 #1455 mytarmailS:我不知道怎么做 :) 我对MQL不熟悉无论如何,即使是我(不是程序员) 也明白,我不能用内置函数来做,我必须自己写所有的东西......你从R 中翻译了十几个统计函数,这当然很好,甚至值得称赞,但要明白,与R的能力相比,这甚至不是沧海一粟,它在不断发展,每天都有新的库,不是函数,而是库,你怎么能跟上这个步伐?你不知道MQL语言,你不知道终端,你怎么能判断什么呢?PS。太糟糕了,这个论坛上有那么多的用户寄生在MT的生态系统上。但这也说明了该平台的巨大人气和先进性,吸引了最聪明的人研究MQL,当然也吸引了寄生虫,没有他们怎么行呢...... mytarmailS 2016.10.09 13:31 #1456 让我们停止这些无谓的讨论,每个人都有自己的观点,这个主题有一个特定的主题......那么这个分布是怎么回事?它到底能不能建立在两个向量上?:) Dr. Trader 2016.10.09 14:38 #1457 mytarmailS:那么这个分布是怎么回事?它到底能不能在两个向量上绘图?:)这里有一篇好文章:https://www.r-bloggers.com/5-ways-to-do-2d-histograms-in-r/x <- rnorm(mean=1.5, 5000) y <- rnorm(mean=1.6, 5000) df <- data.frame(x,y) library(gplots) h2 <- hist2d(df, nbins=10) #сторона квадрата = 10 h2$counts Dr. Trader 2016.10.09 15:21 #1458 这里有一个更重要的例子。在档案中是RData与eurusd h1从2012年到今天。MetaQotes-Demo同时提供tick量 和交易量,但我不知道它们的可信度如何。load("H1.RData") library(gplots) #торговые обёмы и цены закрытия за последний год hist2d(x = H1[(nrow(H1) - 6225):nrow(H1), c("Close", "Trade.volume")], nbins = 100) 附加的文件: H1.zip 671 kb mytarmailS 2016.10.09 15:58 #1459 谢谢你!我的拖车上有一个类似的...x <- D$X.CLOSE.[1:2000] y <- D$X.VOL.[1:2000] df <- data.frame(x,y) library(gplots) h2 <- hist2d(df, nbins=100) #сторона квадрата = 10 #h2$counts 我只是不知道如何解释这个h2$counts 矩阵,那里有这么多东西,令人毛骨悚然......我想得到类似于正态分布的东西,比如用hist() 记得吗?它将类似于音量曲线,甚至更好,一对一,是否可以用P-键工具来做?我在https://futures.io/matlab-r-project-python/29465-r-volume-profile-volume-price.html, 我会研究一下。 Dr. Trader 2016.10.09 17:56 #1460 mytarmailS:我想得到类似于正态分布的东西,比如用hist() 记得吗?这将类似于音量曲线,更好的是一对一,是否可以用P键工具来做?如果你只取一个向量--价格,柱状图将显示每个价格水平的重复次数。简单地说,会有酒吧从生产线上长出来。如果我们取两个向量--价格和成交量,那么价格会有自己的水平,成交量也会有自己的水平。这是两个不同的维度,形成一个平面。直方图条将从平面向上增长,显示每个价格和成交量组合的重复次数。 hist2d用颜色显示条形图的高度,而不是画出三维的。同一数据上的一个更好的版本会是这样的。要像hist()那样为价格和成交量画一个简单的直方图,你必须首先使用一个公式将两个向量(价格和成交量)转换成一个单一的向量,并为它画 一个直方图。 你必须决定这是一个什么样的新向量,你想从它那里得到什么以及从哪里得到它。粗略地说,你想从上面那张三维图片中得到一个平面直方图,这可以用无限多的方法来实现。h2$counts是该直方图的矩阵表示。以nbins=5为例,得到一个5x5的直方图,h2$counts也将是一个5x5的矩阵。直方图单元的亮度越高,相应单元的矩阵中的数字就越高。我稍后会补充更多。 找到了一个让它看起来不错的方法--library(plot3D) levels_count <- 20 volume_levels = cut(H1[(nrow(H1) - 6225):nrow(H1), "Trade.volume"], levels_count) price_levels = cut(H1[(nrow(H1) - 6225):nrow(H1), "Close"], levels_count) h3d = hist3D(z = table(volume_levels, price_levels), xlab="volume", ylab="price", zlab="frequency", border="black") 1...139140141142143144145146147148149150151152153...3399 新评论 您错过了交易机会: 免费交易应用程序 8,000+信号可供复制 探索金融市场的经济新闻 注册 登录 拉丁字符(不带空格) 密码将被发送至该邮箱 发生错误 使用 Google 登录 您同意网站政策和使用条款 如果您没有帐号,请注册 可以使用cookies登录MQL5.com网站。 请在您的浏览器中启用必要的设置,否则您将无法登录。 忘记您的登录名/密码? 使用 Google 登录
我不是外汇交易员,我甚至不熟悉Metatrader :)
我想在P中实验不同的配置文件,我只是不明白如何使两个向量的分布
我想尝试不同的型材变体,只是不清楚用两个矢量来构建它,不一定要有体积,这只是一个开始,你几乎可以把任何东西放入型材,但应该用价格来做,这就是两个矢量。
那你在这个论坛上做什么呢?一个完全专注于MetaTrader的论坛?你之前已经说过,将不会有从外部直接访问(API)MetaTrader生态系统的机会。
阅读本主题的标题,告诉我Metatrader是如何参与的?
那么这次讨论的重点是什么呢?
阅读本主题的标题,告诉我Metatrader是如何参与的?
这场讨论的重点到底是什么?
例如,新的数学库出现在终端的交付中。(讨论文章 "MQL5中的统计分布--使用R的精华")--你为什么不发表MetaTrader的例子?
我不知道怎么做 :) 我对MQL不熟悉
无论如何,即使是我(不是程序员) 也明白,我不能用内置函数来做,我必须自己写所有的东西......你从R 中翻译了十几个统计函数,这当然很好,甚至值得称赞,但要明白这与R的 能力相比连沧海一粟都算不上, 它在不断发展,每天都有新的库出现,不是函数而是库,你怎么能跟得上呢? 又为什么呢? 它根本就必须用...
我不知道怎么做 :) 我对MQL不熟悉
无论如何,即使是我(不是程序员) 也明白,我不能用内置函数来做,我必须自己写所有的东西......你从R 中翻译了十几个统计函数,这当然很好,甚至值得称赞,但要明白,与R的能力相比,这甚至不是沧海一粟,它在不断发展,每天都有新的库,不是函数,而是库,你怎么能跟上这个步伐?
你不知道MQL语言,你不知道终端,你怎么能判断什么呢?
PS。太糟糕了,这个论坛上有那么多的用户寄生在MT的生态系统上。但这也说明了该平台的巨大人气和先进性,吸引了最聪明的人研究MQL,当然也吸引了寄生虫,没有他们怎么行呢......
让我们停止这些无谓的讨论,每个人都有自己的观点,这个主题有一个特定的主题......
那么这个分布是怎么回事?它到底能不能建立在两个向量上?:)
那么这个分布是怎么回事?它到底能不能在两个向量上绘图?:)
这里有一篇好文章:https://www.r-bloggers.com/5-ways-to-do-2d-histograms-in-r/
这里有一个更重要的例子。在档案中是RData与eurusd h1从2012年到今天。
MetaQotes-Demo同时提供tick量 和交易量,但我不知道它们的可信度如何。
谢谢你!我的拖车上有一个类似的...
我只是不知道如何解释这个h2$counts 矩阵,那里有这么多东西,令人毛骨悚然......
我想得到类似于正态分布的东西,比如用hist() 记得吗?它将类似于音量曲线,甚至更好,一对一,是否可以用P-键工具来做?
我在https://futures.io/matlab-r-project-python/29465-r-volume-profile-volume-price.html, 我会研究一下。
我想得到类似于正态分布的东西,比如用hist() 记得吗?这将类似于音量曲线,更好的是一对一,是否可以用P键工具来做?
如果你只取一个向量--价格,柱状图将显示每个价格水平的重复次数。简单地说,会有酒吧从生产线上长出来。
如果我们取两个向量--价格和成交量,那么价格会有自己的水平,成交量也会有自己的水平。这是两个不同的维度,形成一个平面。直方图条将从平面向上增长,显示每个价格和成交量组合的重复次数。
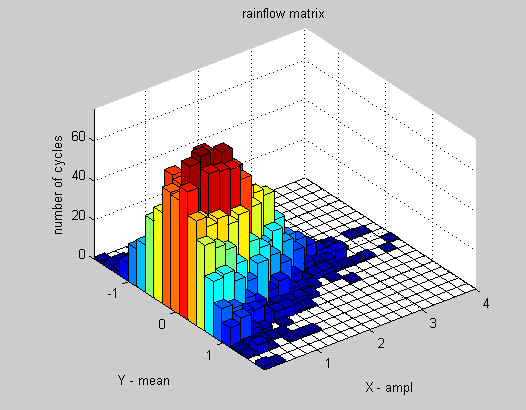
hist2d用颜色显示条形图的高度,而不是画出三维的。同一数据上的一个更好的版本会是这样的。
要像hist()那样为价格和成交量画一个简单的直方图,你必须首先使用一个公式将两个向量(价格和成交量)转换成一个单一的向量,并为它画 一个直方图。 你必须决定这是一个什么样的新向量,你想从它那里得到什么以及从哪里得到它。粗略地说,你想从上面那张三维图片中得到一个平面直方图,这可以用无限多的方法来实现。
h2$counts是该直方图的矩阵表示。以nbins=5为例,得到一个5x5的直方图,h2$counts也将是一个5x5的矩阵。直方图单元的亮度越高,相应单元的矩阵中的数字就越高。
我稍后会补充更多。
找到了一个让它看起来不错的方法--