Есть ли закономерность в хаосе? Попробуем поискать! Машинное обучение на примере конкретной выборки. - страница 21
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
Срезал ещё два года с этой выборки и средняя на Exam уже стала -485 (было - 1214) , а число моделей, преодолевших придел в 3000 пунктов стало 884 (было в последний раз 277).
Однако, результаты на выборке test ухудшились со среднего значения 2115 до 186 пунктов, т.е. существенно. Что это - меньше примеров стало в выборке train похожих на выборку test?
Среднее число деревьев сократилось до 7 с 10.
Перелом нуля на графике распределение баланса сместилось к центру.
На чем строится утверждение, что результат должен быть схож с test? Я то исхожу из того, что выборки не однородны - нет в них сопоставимого числа похожих примеров, и думаю, что и распределения вероятности по квантам отличаются немного.
С трейн. Я про данные где хорошие закономерности. Если вы 1000 вариантов таблицы умножения подадите на обучение, то новые варианты ни разу не совпадающие с трейном (но внутри границ трейна) будут тоже неплохо вычисляться. 1 дерево даст ближайший вариант, случайный лес усреднит сотню ближайших и скорее всего даст ответ точнее чем из 1 дерева.
Если найдутся для рынка предикторы с закономерностью, то ООС тоже будет похож на трейн. Но не так как сейчас больше половины моделей в минус и треть в плюс. Все успешные модели стали такими случайно, от случайного seedа.
Seed должен лишь немного изменять успешность модели и в целом они должны быть все успешными. Сейчас получается что закономерности не найдены (либо переобучение/недообучение).
Участвует только для контроля остановки обучения, т.е. если на test нет улучшений при обучении на train, то обучение останавливается и деревья удаляются до точки, где было последнее улучшение на модели test.
Тогда понятно почему тесты тоже хорошие. По сути это подгонка под тест. Я это перестал делать для 1 обучения. Делаю валкинг фовард, склеиваю все ООС, потом из множества вариантов склеенных ООС выбираю лучшие гиперпараметры модели (глубина, число деревьев и т.д.). Предполагаю, что и Exam будет примерно такой же как и выбранная склейка всех ООС. В том варианте за 5 лет, у меня переобучение раз в неделю - это сотни обучений и кусков ООС.
Видимо я не четко дал указание на выборку, которую использовал - это шестая (последняя) выборка из эксперимента тут описанного, поэтому там всего 61 предиктор.
примитивные стратегии, особенно на участках флэта рынка.Ну эти 61 вы выбрали из 5000+. У меня и общее количество меньше и количество выбранных. Да и при добавлении по 1, после 3-4 отобранных, дальнейшее добавление признаков только ухудшают результат на ООС.
Вообще я могу и больше предикторов добавить, ведь сейчас только по сути с 3 ТФ они используются, за небольшим исключением - думаю ещё пару тысяч можно и добавить, но вот будут ли все использованы должным образом при обучении - сомнительно, учитывая что 10000 вариантов seed для 61 предиктора дают такой разброс...
Ну и конечно нужен предварительный отсев предикторов, что ускорит обучение.
Если они все примерно одинаковы, то вряд ли что-то серьезно улучшающее результат уже найдется. Можно пробовать совсем новые данные, или уникальные индикаторы.
Предварительный отсев тоже долгое занятие, добавление по одному в разы дольше считает, даже до 3 фичей, а если до 10 то это много дней. но в этом нет смысла, после 3-4 фич уже улучшений обычно нет. Но изредка бывают, но прирост небольшой. Прорывов там не находилось (в моих экспериментах, кто-то может и найдет).
Логично, что выбросы являются отклонениями, я как раз думаю, что это и есть неэффективности, на которых и надо обучаться, убрав белый шум. На остальных участках часто работают простые примитивные стратегии, особенно на участках флэта рынка.
На нижнем рисунке прибыльный вариант, но за 5 лет было всего 2 периода в 2017 году с сильным ростом (видимо был сильный предсказуемый тренд), модель на этих 2х периодах заработала больше всего. А хорошо бы иметь равномерный во времени рост. Я бы такую модель выключил через месяц бездействия.
Можно конечно сделать советника - ждуна белых лебедей. Но я предпочел бы активную торговлю.
Срезал ещё два года с этой выборки и средняя на Exam уже стала -485 (было - 1214) , а число моделей, преодолевших придел в 3000 пунктов стало 884 (было в последний раз 277).
Однако, результаты на выборке test ухудшились со среднего значения 2115 до 186 пунктов, т.е. существенно. Что это - меньше примеров стало в выборке train похожих на выборку test?
Среднее число деревьев сократилось до 7 с 10.
Перелом нуля на графике распределение баланса сместилось к центру.
Доброе время суток! Можете выложить файлы из первого сообщения, тоже хочется попробовать одну идею.
С трейн. Я про данные где хорошие закономерности. Если вы 1000 вариантов таблицы умножения подадите на обучение, то новые варианты ни разу не совпадающие с трейном (но внутри границ трейна) будут тоже неплохо вычисляться. 1 дерево даст ближайший вариант, случайный лес усреднит сотню ближайших и скорее всего даст ответ точнее чем из 1 дерева.
Если найдутся для рынка предикторы с закономерностью, то ООС тоже будет похож на трейн. Но не так как сейчас больше половины моделей в минус и треть в плюс. Все успешные модели стали такими случайно, от случайного seedа.
Seed должен лишь немного изменять успешность модели и в целом они должны быть все успешными. Сейчас получается что закономерности не найдены (либо переобучение/недообучение).
Никто не спорит, что при хороших данных все будет скорей всего работать идеально. Но, таких данных не получить, поэтому и думать надо, что можно выжать из того, что есть.
Факт того, что возможно получить эффективные модели случайным образом, которые будут эффективны на новых данных, меня заставляет задуматься - как снизить эту случайность, т.е. есть ли какие то закономерные метрики у квантовых отрезков, по которым была последовательна построена модель. Т.е. речь о дополнительных метриках, кроме жадности по целевой. Если удастся установить такие зависимости, то и модели можно строить с большей вероятностью успешными. Конечно, это должно работать на разных выборках.
Тогда понятно почему тесты тоже хорошие. По сути это подгонка под тест. Я это перестал делать для 1 обучения. Делаю валкинг фовард, склеиваю все ООС, потом из множества вариантов склеенных ООС выбираю лучшие гиперпараметры модели (глубина, число деревьев и т.д.). Предполагаю, что и Exam будет примерно такой же как и выбранная склейка всех ООС. В том варианте за 5 лет, у меня переобучение раз в неделю - это сотни обучений и кусков ООС.
Главное не отделять последний экзаменационный участок.
Подбираете гиперпараметры и результат оцениваете на чем? Думаю это такая же подгонка с элементом усреднения, если следовать Вашей логике.
Логика в CatBoost в том, что если нельзя улучшить модель (по Logloss), то смысла дальше обучаться нет. При этом гарантий, что модель получилась хорошей нет конечно.
Ну эти 61 вы выбрали из 5000+. У меня и общее количество меньше и количество выбранных. Да и при добавлении по 1, после 3-4 отобранных, дальнейшее добавление признаков только ухудшают результат на ООС.
Нет, выбрал не я - я же взял их из модели, при обучении на всех предикторах.
Смотрите, я вообще рассматриваю предиктор, как набор квантовых отрезков. И, по этой причине я отбираю квантовые отрезки, в целом я даже могу разложить все предикторы на бинарные - результат чуть хуже, но сопоставимый получается. Возможно для бинарных разряженных предикторов требуется особый метод обучения.
Если они все примерно одинаковы, то вряд ли что-то серьезно улучшающее результат уже найдется. Можно пробовать совсем новые данные, или уникальные индикаторы.
Что значит "примерно одинаковые", я так полагаю, что речь идет о метриках каких либо или о чём? Конечно, данные можно пробовать другие, взять другой инструмент к примеру.
Предварительный отсев тоже долгое занятие, добавление по одному в разы дольше считает, даже до 3 фичей, а если до 10 то это много дней. но в этом нет смысла, после 3-4 фич уже улучшений обычно нет. Но изредка бывают, но прирост небольшой. Прорывов там не находилось (в моих экспериментах, кто-то может и найдет).
Тот вариант, о котором говорите Вы, да долгая игра, поэтому в неё не играю (ну и полной автоматизации у меня нет). Но, я не согласен, что эффекта нет - я делал отсевы группами, с уменьшением групп - результат был положительным. Но я все же отношу эти действия к подгонке или случайности - нет обоснования выбора предикторов.
На нижнем рисунке прибыльный вариант, но за 5 лет было всего 2 периода в 2017 году с сильным ростом (видимо был сильный предсказуемый тренд), модель на этих 2х периодах заработала больше всего. А хорошо бы иметь равномерный во времени рост. Я бы такую модель выключил через месяц бездействия.
Можно конечно сделать советника - ждуна белых лебедей. Но я предпочел бы активную торговлю.
Поэтому я за использование наборов моделей, так как понимаю, что каждая может зацепить свои не частые закономерности.
Ну вообще стремятся, чтобы ошибка на трейне и тесте были примерно одинаковыми. Вот ваш Exam движется в сторону трейна и теста т.е. вверх, а они к exam т.е. вниз. Переобучение падает.
А по какой метрике похожи?
Вот смотрите, к примеру, берем метрику Precision, вычитаем из train этот показатель на выборке test, - получается дельта (ось y), а по х смотрим прибыль на выборке exam.
Особой зависимости прям таки не наблюдается, или как?
Ниже две метрики на каждой выборке - данные берутся по мере добавления нового дерева в модель.
Вот характеристики этой модели
А вот метрики другой модели, с убытками на двух выборках
Вот характеристики модели
Неудобно отвечать в стиле форума, много раз нажимая ответить. Ниже мои ответы выделены просто цветом.
Факт того, что возможно получить эффективные модели случайным образом, которые будут эффективны на новых данных, меня заставляет задуматься - как снизить эту случайность, т.е. есть ли какие то закономерные метрики у квантовых отрезков, по которым была последовательна построена модель. Т.е. речь о дополнительных метриках, кроме жадности по целевой. Если удастся установить такие зависимости, то и модели можно строить с большей вероятностью успешными. Конечно, это должно работать на разных выборках.
> Смотрел давно, как кванты строятся, основные варианты. Сначала сортируется столбец.
1) по диапазону, ровный шаг (например от 0 до 1 с шагом значения ровно через 0,1 итого 10 квантов 0.1, 0.2, 0.3 ... 0.9)
2) процентиль - т.е. по количеству примеров. Если делим на 10 квантов, то в каждый квант помещаем 10% от числа всех строк, если много дублей, то некоторые кванты будут больше 10%, т.к. дубли не должны попадать в др. кванты, например если дублей 30% от всей выборки, то в этот квант они все попадут. В зависимости от числа примеров в каждом кванте может быть такое распределение 0.001, 0.12,0.45,0.51,0,74, ... 0.98.
3) есть комбинация обоих типов
Так что ничего в построении квантов супер умного нету. Я себе оба этих метода квантования сделал. И как всегда что-то сделал так, как считаю лучше. Возможно ошибся. Да и без квантования обычно делаю расчеты, а по float данным.
Если вы сделаете все предикторы бинарными, то квантов будет всего 2, в одном все 0, в другом все 1.
Подбираете гиперпараметры и результат оцениваете на чем? Думаю это такая же подгонка с элементом усреднения, если следовать Вашей логике.
> Смотрю на графики баланса и на просадки. Автоматизировать выбор пока не получилось. Да подгонка - под лучшую склейку ООС. Но не самой модели (т.е. не под трейн), а подбор лучших гиперпараметров модели.
Что значит "примерно одинаковые", я так полагаю, что речь идет о метриках каких либо или о чём? Конечно, данные можно пробовать другие, взять другой инструмент к примеру.
> Все которые сделаны на ценах и машках.
По старому вопросу.
На чем строится утверждение, что результат должен быть схож с train? Я то исхожу из того, что выборки не однородны - нет в них сопоставимого числа похожих примеров, и думаю, что и распределения вероятности по квантам отличаются немного.
> Примеры тут https://www.mql5.com/ru/articles/3473
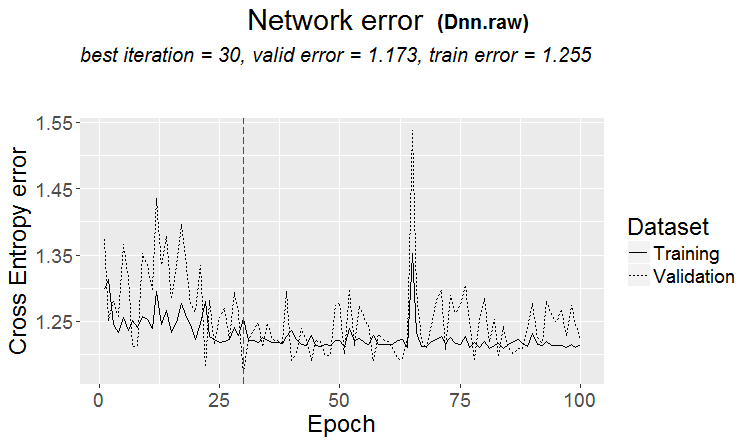
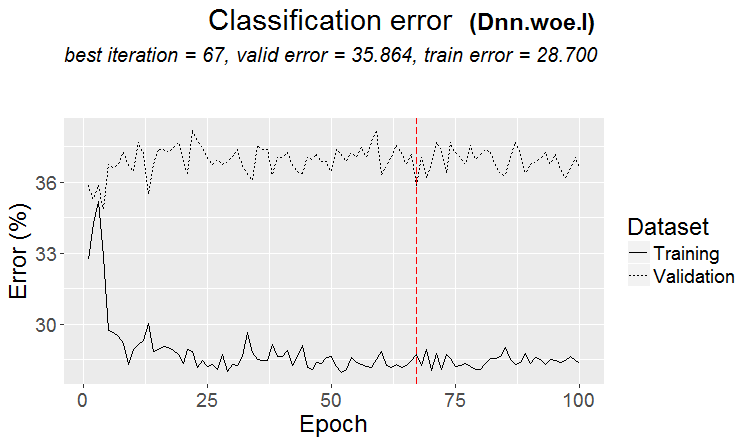
Хороший вариант, когда найдена закономерность: терйн и тест имеют почти одинаковую ошибку
На рынках чаще что-то такое получается: хороший тест, а после какого-то шага обучения (на рисунке после 3-го) начинается переобучение и ошибка теста начинает расти. Картинки к нейросетям относятся, но с лесами и бустами тоже что-то такое есть, когда модель становится переобученой.
А по какой метрике похожи?
Но это не значит, что ваши метрики плохие.
Так что ничего в построении квантов супер умного нету. Я себе оба этих метода квантования сделал. И как всегда что-то сделал так, как считаю лучше. Возможно ошибся. Да и без квантования обычно делаю расчеты, а по float данным.
Методы конечно разные есть, я около 900 квантовых таблиц сейчас использую.
Суть то не в методе, а в выборе диапазона предиктора на котором среднее значение бинарной целевой выше чем по выборке (сейчас минимум 5% ставлю плюс критерии по числу примеров - так же минимум 5%), что говорит о полезной информации в предикторе. Если такой информации нет, то надеяться, что она появиться через пяток сплитов - можно, но вероятность этого считаю меньше.
По факту бывает, что таких участков 1-2, редко бывает действительно много. И тут либо брать только эти участки, либо брать просто предикторы с такими участками, подобрав лучшую квантовую таблицу.
Лично я увидел, что предикторы, во всяком случае мои, не имеют плавных переходов вероятности, а скорей это происходит скачкообразно и меняется на противоположное отклонение, т.е. было +5 и сразу стало -5. Даже думаю, что если упорядочить эти вероятности, то модели будет проще обучаться, так как они заточены на диапазоны. По этой причине и есть смысл исключить не информативные участки и разделить конфликтующие.
Если вы сделаете все предикторы бинарными, то квантов будет всего 2, в одном все 0, в другом все 1.
На самом деле будет один - 0,5 :) Но, таким образом можно будет предиктор разложить на полезные (содержащие потенциально полезную информацию) диапазоны.
> Смотрю на графики баланса и на просадки. Автоматизировать выбор пока не получилось. Да подгонка - под лучшую склейку ООС. Но не самой модели (т.е. не под трейн), а подбор лучших гиперпараметров модели.
Ну это понятно, но не по канонам - метрика модели так же имеет важность, я думаю.
> Все которые сделаны на ценах и машках.
В теории да, и то если использовать нейросети, но по факту - нет - слишком сложные зависимости надо искать с разными вычислениями, для этого просто нет вычислительных мощностей у простых пользователей.
По старому вопросу.
> Примеры тут https://www.mql5.com/ru/articles/3473
Хороший вариант, когда найдена закономерность: терйн и тест имеют почти одинаковую ошибку
На рынках чаще что-то такое получается: хороший тест, а после какого-то шага обучения (на рисунке после 3-го) начинается переобучение и ошибка теста начинает расти. Картинки к нейросетям относятся, но с лесами и бустами тоже что-то такое есть, когда модель становится переобученой.
Закономерность найдена всегда - таков принцип - вопрос в том, будет ли эта закономерность и дальше проявляться или нет.
Не знаю, что там именно за выборка была. Бывали у меня случаи, когда test обучается быстрей train, но чаще это происходит наоборот и между ними ощутимая дельта. В идеальных условиях разница будет маленькой конечно.
Могу сказать точно, что модели недообученные как раз по той причине, что выборки не сильно похожи и происходит остановка обучения при отсутствии улучшения.
Как нибудь покажу, как графически выглядит переобученная выборка - это две выпуклости разнесенные по углам...
Срезал выборку для обучения ещё в два раза.
Моделей уже всего 306, средняя прибыль по exam -2791 пункта.
Зато получилась такая моделька
С такими характеристиками
Мат ожидание конечно упало, но зато вырос Recall в два раза - за счет этого и такой график с большим числом сделок.
Предикторы такие использовались:
И их на 9 меньше, чем в выборке - попробую взять только их и обучиться на всей выборке (на всех строках train).
Cплиты делаются только до кванта. Все что внутри кванта считается одинаковыми значениями и дальше уже не делятся. Не понимаю зачем вы вообще что-то ищете в квантах, его основное назначение - ускорение расчетов (вторичное - загрубление/обобщение модели, чтобы не было дальнейшего деления, но можно и просто ограничить глубину float данных) я его не использую, а просто на float данных делаю модели. Делал квантование на 65000 частей - результат абсолютно совпадает с моделью без квантования.
Лично я увидел, что предикторы, во всяком случае мои, не имеют плавных переходов вероятности, а скорей это происходит скачкообразно и меняется на противоположное отклонение, т.е. было +5 и сразу стало -5.
Тоже замечал подобное. Увеличение глубины на 1 резко изменяет прибыльность, иногда в + иногда в -
На самом деле будет один - 0,5 :) Но, таким образом можно будет предиктор разложить на полезные (содержащие потенциально полезную информацию) диапазоны.
Будет 1 сплит, который разделит данные на 2 сектора - в одном все 0, в другом все 1. Я не знаю что принято называть квантами, я считаю что кванты - это число секторов полученных после квантования. Возможно - это число сплитов, как имеете в виду вы.