
Tabelas eletrônicas no MQL5

Introdução
Normalmente, as tabelas eletrônicas referem-se a processadores de tabela (aplicações que armazenam e processam dados), como o EXCEL. Embora o código mostrado no artigo não é tão poderoso, ele pode ser usado como uma classe base para uma implementação com todos os recursos de um processador de tabela. Eu não tenho um propósito para criar MS Excel usando MQL5, mas eu quero implementar uma classe para operar com dados de tipos diferentes em uma matriz bidimensional.
E embora a classe implementada por mim não pode ser comparada com o seu desempenho de uma série bidimensional de dados de tipo único (com acesso direto aos dados), a classe pareceu ser conveniente para o uso. Além disso, esta classe pode ser considerada como uma implementação da classe de variantes em C++, como um caso especial de uma tabela se degenerou para uma coluna.
Para os mais impacientes e para os que não querem analisar o algoritmo de implementação, eu vou começar a descrever a classe CTable a partir dos métodos disponíveis.
1. Descrição dos métodos de classe
Em primeiro lugar, vamos considerar os métodos disponíveis da classe com uma descrição mais detalhada de sua finalidade e os princípios de utilização.
1.1. FirstResize
Disposição da tabela, descrição dos tipos de coluna, TYPE[] - série do tipo ENUM_DATATYPE que determina o tamanho da linha e tipos de células.
void FirstResize(const ENUM_DATATYPE &TYPE[]);
Na prática, este método é um construtor adicional que tem um parâmetro. Isto é conveniente por duas razões: em primeiro lugar, ele resolve o problema de passagem de um parâmetro dentro do construtor, em segundo lugar, dá a possibilidade de passar um objeto como um parâmetro, e em seguida, executar a divisão necessária da série. Este recurso permite o uso da classe como a classe variante em C++.
As peculiaridades de aplicação incluem o fato de que, apesar da função definir a primeira dimensão e o tipo de dados de colunas, ela não requer uma especificação de tamanho da primeira dimensão como o parâmetro. Este parâmetro é tomado a partir do tamanho do TIPO de série passada.
1.2. SecondResize
Muda o número de colunas para 'j'.
void SecondResize(int j);
A função define um tamanho específico para todas as séries de segunda dimensão. Assim, podemos dizer que ela adiciona linhas a uma tabela.
1.3. FirstSize
O método regressa ao tamanho da primeira dimensão (comprimento da coluna).
int FirstSize();
1.4. SecondSize
O método regressa ao tamanho da segunda dimensão (comprimento da coluna).
int SecondSize();
1.5. PruningTable
Ele define um novo tamanho para a primeira dimensão; a mudança é possível dentro do tamanho inicial.
void PruningTable(int count);
Na prática, a função não altera o comprimento da coluna, ela só reescreve o valor de uma variável que é responsável por armazenar o valor do comprimento da coluna. A classe contém uma outra variável que armazena o tamanho real da memória alocada, que é definida na divisão inicial de uma tabela. Dentro dos valores dessa variável, a mudança virtual do tamanho da primeira dimensão é possível. A função serve para cortar uma parte indesejada ao copiar uma tabela para outra.
1.6. CopyTable
O método de cópia de uma tabela para outra em todo o comprimento da segunda dimensão:
void CopyTable(CTable *sor);
A função copia uma tabela para outra. Ela começa a iniciação da tabela receptora. Ela pode ser usada como um construtor adicional. A estrutura interna das variantes de classificação não é copiada. Apenas o tamanho, tipos de colunas e os dados são copiados da tabela inicial. A função aceita a referência do objeto copiado do tipo CTable como um parâmetro, que é passado pela função GetPointer.
Copiando de uma tabela para outra, uma nova tabela é criada de acordo com a amostra 'sor'.
void CopyTable(CTable *sor,int sec_beg,int sec_end);
Substituição da função descrita acima com os parâmetros adicionais: sec_beg - ponto de partida da cópia da tabela inicial, sec_end - ponto final da cópia (por favor, não confunda com a quantidade de dados copiados). Ambos os parâmetros referem-se a segunda dimensão. Os dados serão adicionados ao início da tabela destinatária. Tamanho da tabela receptora é definida como sec_end-sec_beg+1.
1.7. TypeTable
Retorna o valor type_table (do tipo ENUM_DATATYPE) da coluna 'i'.
ENUM_DATATYPE TypeTable(int i)
1.8. Change
O método Change() realiza troca de colunas.
bool Change(int &sor0,int &sor1);
Como é mencionado acima, o método troca colunas (trabalha com a primeira dimensão). Uma vez que a informação não é movida realmente, a velocidade de funcionamento da função não é afetada pelo tamanho da segunda dimensão.
1.9. Insert
O método Insert insere uma coluna numa posição específica.
bool Insert(int rec,int sor);
A função é a mesma que a descrita acima, exceto que ela executa o puxar ou empurrar de outras colunas dependendo do local onde a coluna especificada deve ser movida. O parâmetro 'rec' especifica que a coluna será movida, 'sor' especifica de onde ele será movida.
1.10. Variant/VariantCopy
Em seguida, vêm três funções da série 'variante'. Memorização das variantes de processamento da tabela é implementado na classe.
As variantes lembram um notebook. Por exemplo, se você executar a classificação pela terceira coluna e você não deseja redefinir dados durante o processamento seguinte, você deve mudar a variante. Para acessar a variante anterior de processamento, chame a função 'variante'. Se o processamento seguinte deve basear-se no resultado do anterior, você deve copiar as variantes. Por padrão, uma variante com o número 0 está configurado.
Criação de uma variante (se não existe essa variante, ela será criada, bem como todos as variantes desaparecidas até 'ind') e obtendo a variante ativa. O método 'variantcopy' copia a variante 'sor' para a variante 'rec'.
void variant(int ind); int variant(); void variantcopy(int rec,int sor);
O método variante (int ind) muda a variante selecionada. Executa alocação automática de memória. Se o parâmetro especificado é menor do que o especificado anteriormente, a memória não é deslocada.
O método variantcopy permite copiar a variante 'sor' para a variante 'rec'. A função é criada para organizar as variantes. Ele aumenta automaticamente o número de variantes se a variante 'rec' não existe; ele também muda para a variante recém copiada.
1.11. SortTwoDimArray
O método SortTwoDimArray classifica a tabela pela linha selecionada 'i'.
void SortTwoDimArray(int i,int beg,int end,bool mode=false);
A função de classificação de uma tabela por coluna especificada. Parâmetro: i - coluna, beg - ponto de partida de classificação, final - ponto final da classificação (inclusive), o modo - variável booleana que determina direção de classificação. Se o modo = verdadeiro, isso significa que os valores aumentam junto com índices ("falso" é o valor padrão, já que os índices aumentam de cima para baixo na tabela).
1.12. QuickSearch
O método realiza uma pesquisa rápida de posição de um elemento da série pelo valor igual ao padrão 'elemento'.
int QuickSearch(int i,long element,int beg,int end,bool mode=false);
1.13. SearchFirst
Procura o primeiro elemento que é igual a um padrão em uma série ordenada. Retorna o índice do primeiro valor que é igual ao do padrão 'elemento'. é necessário especificar o tipo de classificação realizada mais cedo neste intervalo (se não houver tal elemento, ele retorna -1).
int SearchFirst(int i,long element,int beg,int end,bool mode=false);
1.14. SearchLast
Procura o último elemento que é igual a um padrão em uma série ordenada.
int SearchLast(int i,long element,int beg,int end,bool mode=false);
1.15. SearchGreat
Procura pelo elemento mais próximo que é maior que um padrão em uma série ordenada.
int SearchGreat(int i,long element,int beg,int end,bool mode=false);
1.16. SearchLess
Procura pelo elemento mais próximo que é menor que um padrão em uma série ordenada.
int SearchLess(int i,long element,int beg,int end,bool mode=false);
1.17. Set/Get
As funções Set e Get têm o tipo nulo; Eles são substituídos por quatro tipos de dados na qual a tabela trabalha. As funções reconhecem o tipo de dado e, em seguida, se o parâmetro 'valor' não corresponde ao tipo de coluna, um aviso é impresso em vez de atribuir. A única exceção é o tipo cadeia. Se o parâmetro de entrada é do tipo cadeia, ele vai ser convertido para o tipo coluna. Esta exceção é feita para transmissão de informação mais conveniente quando não há nenhuma possibilidade de definir uma variável que aceite o valor da célula.
Os métodos de definição de valores (i - índice da primeira dimensão, j - índice da segunda dimensão).
void Set(int i,int j,long value); // setting value of the i-th row and j-th column void Set(int i,int j,double value); // setting value of the i-th row and j-th columns void Set(int i,int j,datetime value);// setting value of the i-th row and j-tj column void Set(int i,int j,string value); // setting value of the i-th row and j-th column
Métodos de obtenção de valores (i - índice da primeira dimensão, j - índice da segunda dimensão).
//--- getting value void Get(int i,int j,long &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,double &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,datetime &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,string &recipient); // getting value of the i-th row and j-th column
1.19. sGet
Obtém um valor do tipo cadeia da coluna 'j' e da linha 'i'.
string sGet(int i,int j); // return value of the i-th row and j-th column
A única função da série Get que retorna o valor através do operador 'retorno' ao invés de uma variável paramétrica. Retorna um valor do tipo cadeia independentemente do tipo de coluna.
1.20. StringDigits
Quando tipos são convertidos para 'cadeia', você pode usar uma precisão definida pelas funções:
void StringDigits(int i,int digits);
para definir a precisão de 'duplo' e
int StringDigits(int i);
para definir uma precisão de exibição de segundos em 'datetime'; qualquer valor que não é igual a -1 é passado. O valor especificado é memorizado para a coluna, de modo que você não precisa indicar-lo cada vez que exibir informações. Você pode definir uma precisão muitas vezes, uma vez que a informação é armazenada em tipos originais e é transformada para a precisão especificada apenas durante a saída. Os valores de precisão não são memorizados em cópia, assim, ao copiar uma tabela para uma nova tabela, a precisão de colunas da nova tabela corresponderá à precisão padrão.
1.21. Um exemplo do uso:
#include <Table.mqh> ENUM_DATATYPE TYPE[7]= {TYPE_LONG,TYPE_LONG,TYPE_STRING,TYPE_DATETIME,TYPE_STRING,TYPE_STRING,TYPE_DOUBLE}; // 0 1 2 3 4 5 6 //7 void OnStart() { CTable table,table1; table.FirstResize(TYPE); // dividing table, determining column types table.SecondResize(5); // change the number of rows table.Set(6,0,"321.012324568"); // assigning data to the 6-th column, 0 row table.Insert(2,6); // insert 6-th column in the 2-nd position table.PruningTable(3); // cut the table to 3 columns table.StringDigits(2,5); // set precision of 5 digits after the decimal point Print("table ",table.sGet(2,0)); // print the cell located in the 2-nd column, 0 row table1.CopyTable(GetPointer(table)); // copy the entire table 'table' to the 'table1' table table1.StringDigits(2,8); // set 8-digit precision Print("table1 ",table1.sGet(2,0)); // print the cell located in the 2-nd column, 0 row of the 'table1' table. }
O resultado da operação é a impressão do conteúdo da célula (2; 0). Como você deve ter notado, a precisão dos dados copiados não excede a precisão da tabela inicial.
2011.02.09 14:18:37 Table Script (EURUSD,H1) table1 321.01232000 2011.02.09 14:18:37 Table Script (EURUSD,H1) table 321.01232
Agora vamos passar para a descrição do próprio algoritmo.
2. Escolhendo um modelo
Existem duas formas de organização de informações: o esquema de colunas ligadas (implementadas neste artigo) e sua alternativa, sob a forma de linhas conectadas que são mostrados abaixo.
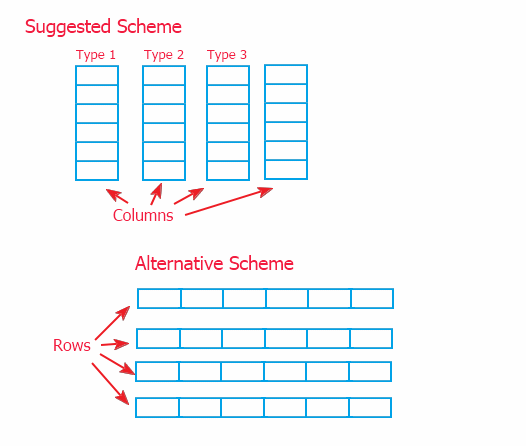
Por causa da referência à informação através de um intermediário (descrito na p. 2), não há grande diferença de execução do âmbito superior. Mas eu escolhi o modelo de colunas, uma vez que ele permite implementação do método de dados de baixo alcance nos objetos que armazenam os dados. E o esquema alternativo exigiria substituição dos métodos para trabalhar com informação na classe superior CTable. E isso pode complicar reforço da classe, caso for necessário.
Naquele, cada um dos esquemas podem ser utilizados. O esquema sugerido permite movimentação rápida de dados, e o alternativo permite mais rápida adição de dados (porque a informação é mais frequentemente adicionada à tabela linha por linha) e obtenção de colunas.
Existe também uma outra forma de arranjar uma tabela - como uma série de estruturas. E apesar de ser o mais fácil de implementar, ele tem uma desvantagem significativa. A estrutura deve ser descrita por um programador. Assim, perdemos a possibilidade de criar os atributos da tabela através de via parâmetros personalizados (sem alterar o código-fonte).
3. Unindo dados em uma série dinâmica
Para se ter a possibilidade de unir diferentes tipos de dados em uma única série dinâmica, temos de resolver o problema de atribuir diferentes tipos de células da série. Este problema já está resolvido em listas ligadas da biblioteca padrão. Meus primeiros desenvolvimentos foram baseadas na biblioteca padrão de classes. Mas durante o desenvolvimento do projeto, mostrou-se que eu preciso fazer muitas mudanças na classe base CObject.
É por isso que eu decidi desenvolver minha própria classe. Para os que não estudaram a biblioteca padrão, eu vou explicar como o problema descrito acima é resolvido. Para resolver o problema, é necessário usar o mecanismo de herança.
class CBase { public: CBase(){Print(__FUNCTION__);}; ~CBase(){Print(__FUNCTION__);}; virtual void set(int sor){}; virtual void set(double sor){}; virtual int get(int k){return(0);}; virtual double get(double k){return(0);}; }; //+------------------------------------------------------------------+ class CA: public CBase { private: int temp; public: CA(){Print(__FUNCTION__);}; ~CA(){Print(__FUNCTION__);}; void set(int sor){temp=sor;}; int get(int k){return(temp);}; }; //+------------------------------------------------------------------+ class CB: public CBase { private: double temp; public: CB(){Print(__FUNCTION__);}; ~CB(){Print(__FUNCTION__);}; void set(double sor){temp=sor;}; double get(double k){return(temp);}; }; //+------------------------------------------------------------------+ void OnStart() { CBase *a; CBase *b; a=new CA(); b=new CB(); a.set(15); b.set(13.3); Print("a=",a.get(0)," b=",b.get(0.)); delete a; delete b; }
Visualmente, o mecanismo de herança pode ser apresentado como uma crista:

Se a criação de um objeto dinâmico da classe é declarada, isso significa que o construtor da classe base será chamado. Esta propriedade exata torna possível criar um objeto em duas etapas. Como funções virtuais da classe base são substituídas, temos a possibilidade de chamar a função com diferentes tipos de parâmetros a partir das classes derivadas.
Por que a simples substituição não é suficiente? A questão é que as funções executadas são enormes, por isso, se nós descrevermos os seus corpos na classe base (sem usar a herança), então a função não utilizada com o código completo do corpo seria criada para cada objeto no código binário. E quando se utiliza o mecanismo de herança, funções vazias, que ocupam muito menos memória do que as funções preenchidas com código, são criadas.
4. Operações com séries
Segundo e a principal base que me fez recusar a utilização das classes padrão é referente aos dados. Eu uso referência indireta para células de série através de uma série intermediária de índices, em vez de referir-se pelos índices de células. Estipula uma velocidade menor de trabalhar do que quando se refere diretamente através de uma variável. A questão é que a variável que indica um índice, funciona mais rapidamente do que uma célula de série que deve ser encontrada na memória, em primeiro lugar.
Vamos analisar qual é a diferença fundamental de classificar uma série unidimensional e uma multidimensional. Antes de classificar, uma série unidimensional tem posições aleatórias de elementos e, depois de classificar os elementos, estão organizados. Ao classificar uma série bidimensional, nós não precisamos de toda a série para ser organizada, mas apenas uma de suas colunas pela qual a classificação é realizada. Todas as colunas devem mudar sua posição mantendo sua estrutura.
As próprias colunas aqui são as estruturas que contêm os dados consolidados de tipos diferentes. Para resolver esse problema, precisamos tanto classificar os dados em uma matriz selecionada quanto salvar a estrutura de índices iniciais. Desta forma, se nós sabemos qual coluna contém a célula, nós pode exibir a coluna inteira. Assim, ao classificar uma série bidimensional, precisamos obter a série de índices da série classificada sem alterar a estrutura de dados.
Por exemplo:
before sorting by the 2-nd column 4 2 3 1 5 3 3 3 6 after sorting 1 5 3 3 3 6 4 2 3 Initial array looks as following: a[0][0]= 4; a[0][1]= 2; a[0][2]= 3; a[1][0]= 1; a[1][1]= 5; a[1][2]= 3; a[2][0]= 3; a[2][1]= 3; a[2][2]= 6; And the array of indexes of sorting by the 2-nd column looks as: r[0]=1; r[1]=2; r[2]=0; Sorted values are returned according to the following scheme: a[r[0]][0]-> 1; a[r[0]][1]-> 5; a[r[0]][2]-> 3; a[r[1]][0]-> 3; a[r[1]][1]-> 3; a[r[1]][2]-> 6; a[r[2]][0]-> 4; a[r[2]][1]-> 2; a[r[2]][2]-> 3;
Assim, temos a possibilidade de classificar a informação por símbolo, data de abertura da posição, lucro, etc.
Muitos algoritmos de classificação já estão desenvolvidos. A melhor variante para esse desenvolvimento será o algoritmo de classificação estável.
O algoritmo de Classificação Rápida, que é utilizado nas classes padrões, refere-se os algoritmos de classificação instável. é por isso que não nos convêm a sua execução clássica. Mas mesmo após trazer a classificação rápida para uma forma estável (e é uma cópia adicional de dados e classificação de índices de séries), a classificação rápida parece ser mais rápida do que a bolha de classificação (um dos algoritmos mais rápidos de classificação estável). O algoritmo é muito rápido, mas ele usa recursão.
Essa é a razão pela qual eu uso Cocktail sort quando se trabalha com séries do tipo string (que exige muito mais memória stack).
5. Arranjo de uma série bidimensional
E a última questão que quero discutir é o arranjo de uma série bidimensional dinâmica. Para tal arranjo é suficiente fazer um embalagem como uma classe para uma série unidimensional e chamar o objeto-série através da série de indicadores. Em outras palavras, precisamos criar e ordenar as séries.
class CarrayInt { public: ~CarrayInt(){}; int array[]; }; //+------------------------------------------------------------------+ class CTwoarrayInt { public: ~CTwoarrayInt(){}; CarrayInt array[]; }; //+------------------------------------------------------------------+ void OnStart() { CTwoarrayInt two; two.array[0].array[0]; }
6. Estrutura do programa
Código da classe CTable foi escrito usando modelos descritos no artigo Using Pseudo-Templates as Alternative of С++ Templates. Só por causa do uso de modelos, eu pude escrever esse código grande tão rapidamente. é por isso que eu não vou descrever o código inteiro em detalhes, além disso, a maior parte do código dos algoritmos é uma modificação das classes padrão.
Eu só vou mostrar a estrutura geral da classe e algumas de suas características interessantes de funções que esclarecem vários pontos importantes.

A parte direita do diagrama de blocos é ocupada principalmente pelos métodos substituídos localizados nas classes derivadas CLONGArray, CDOUBLEArray, CDATETIMEArray e CStringArray. Cada uma delas (na seção privada) contém uma série de tipo correspondente. Essas séries exatas são usadas para todos os truques de acesso à informação. Os nomes dos métodos das classes listadas acima são as mesmas que as dos métodos comuns.
A classe base CBASEArray é preenchida com substituição de métodos virtuais e é necessária apenas para a declaração da série dinâmica de objetos CBASEArray na seção privada da classe CTable. A série de indicadores CBASEArray é declarada como uma série dinâmica de objetos dinâmicos. A construção final de objetos e escolha da instância necessária é executada na função FirstResize(). Também pode ser feito na função CopyTable(), porque ela chama FirstResize() no seu corpo.
A classe CTable também realiza a coordenação de métodos de processamento de dados (localizado nas instâncias da classe CTable) e o objeto de controlar os índices da classe Cint2D. Toda a coordenação é envolta em os métodos públicos substituídos.
Muitas vezes as partes de substituição na classe CTable são trocadas por definições para evitar a produção de linhas muito longas:
#define _CHECK0_ Print(__FUNCTION__+"("+(string)i+","+(string)j+")");return; #define _CHECK_ Print(__FUNCTION__+"("+(string)i+")");return(-1); #define _FIRST_ first_data[aic[i]] #define _PARAM0_ array_index.Ind(j),value #define _PARAM1_ array_index.Ind(j),recipient #define _PARAM2_ element,beg,end,array_index,mode
Assim, a parte de uma forma mais compacta:
int QuickSearch(int i,long element,int beg,int end,bool mode=false){if(!check_type(i,TYPE_LONG)){_CHECK_}return(_FIRST_.QuickSearch(_PARAM2_));};
No exemplo acima, fica claro como os métodos de processamento de dados são chamados (a parte interna 'retorno').
Eu já mencionei que a classe CTable não executa o movimento físico de dados durante o processamento, ele só altera o valor no objeto de índices. Para dar os métodos de processamento de dados a possibilidade de interagir com o objeto de índices, ele é passado para todas as funções de processamento como o parâmetro array_index.
O objeto array_index armazena a relação de posicionamento de elementos da segunda dimensão. Indexação da primeira dimensão é de responsabilidade da série dinâmica aic[] que é declarada na zona privada da classe CTable. Ela dá uma possibilidade de mudar a posição das colunas (claro, não fisicamente, mas através de índices).
Por exemplo, quando se realiza a operação de Change(), apenas duas células de memória, que contêm os índices de colunas, alteraram os seus lugares. Embora visualmente parece que se deslocam duas colunas. Funções da classe CTable são muito bem descritas na documentação (em algum lugar igualmente linha por linha).
Agora, vamos passar para as funções de classes herdadas de CBASEArray. Na verdade, os algoritmos destas classes são os algoritmos tomados a partir das classes padrões. Eu tirei os nomes padrões para ter uma noção sobre eles. A alteração consiste na devolução indireta de valores utilizando uma série de índices distintos dos algoritmos padrões onde os valores são devolvidos diretamente.
Em primeiro lugar, a modificação foi feita para a classificação rápida. Uma vez que o algoritmo é da categoria de instáveis, antes de iniciar a classificação, precisamos fazer uma cópia dos dados, que será passada para o algoritmo. Eu também adicionei a modificação simultânea do objecto de índices de acordo com o padrão de alteração dos dados.
int QuickSearch(int i,long element,int beg,int end,bool mode=false) { if(!check_type(i,TYPE_LONG)) { Print(__FUNCTION__+"("+(string)i+")");return(-1); } return(first_data[aic[i]].QuickSearch(element,beg,end,array_index,mode)); };
Aqui está a parte do código de classificação:
void CLONGArray::QuickSort(long &m_data[],Cint2D &index,int beg,int end,bool mode=0)
... if(i<=j) { t=m_data[i]; it=index.Ind(i); m_data[i++]=m_data[j]; index.Ind(i-1,index.Ind(j)); m_data[j]=t; index.Ind(j,it); if(j==0) break; else j--; } ...
Não há nenhuma instância da classe Cint2D no algoritmo original. Mudanças similares são feitas para os outros algoritmos padrões. Eu não vou descrever os modelos de todos os códigos. Se alguém quiser melhorar o código, eles podem fazer um modelo a partir do código real substituindo os tipos reais com o modelo.
Para escrever modelos, eu usei os códigos da classe que trabalham com o tipo longo. Em tais algoritmos econômicos, desenvolvedores tentam evitar uso desnecessário de números inteiros se houver uma possibilidade de usar int. é por isso que uma variável do tipo longo é provavelmente um parâmetro substituído. Eles devem ser substituídos por 'templat' ao usar os modelos.
Conclusão
Eu espero que este artigo seja uma boa ajuda para programadores iniciantes quando se estuda a abordagem orientada a objetos, e faça o trabalho com informações mais fácil. A classe CTable pode se tornar uma classe base para muitas aplicações complexas. Os métodos descritos no artigo podem se tornar uma base de desenvolvimento de uma grande classe de soluções, já que eles aplicam uma abordagem geral para trabalhar com os dados.
Além disso, o artigo demonstra que abusar de MQL5 não tem fundamento. Você queria que o tipo de Variante? Aqui ele é implementado por meio de MQL5. No que, não há necessidade de alterar os padrões e enfraquecer a segurança da linguagem. Boa sorte!
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/228
 Assistente MQL5: como criar um módulo de gerenciamento de risco e dinheiro
Assistente MQL5: como criar um módulo de gerenciamento de risco e dinheiro
 Assistente MQL5: como criar um módulo de sinais de comércio
Assistente MQL5: como criar um módulo de sinais de comércio
 Assistente MQL5: como criar um módulo de rastreamento de posições abertas
Assistente MQL5: como criar um módulo de rastreamento de posições abertas
 Abordagem econométrica para análise de gráficos
Abordagem econométrica para análise de gráficos
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso