
Le tabelle elettroniche in MQL5

Introduzione
Di solito le tabelle elettroniche si riferiscono a elaboratori di tabelle (applicazioni che memorizzano ed elaborano dati), come EXCEL. Sebbene il codice mostrato nell'articolo non sia così potente, può essere utilizzato come classe base per un'implementazione completa di un processore di tabelle. Il mio scopo non è creare MS Excel usando MQL5, ma voglio implementare una classe per operare con dati di tipo diverso in un array bidimensionale.
E sebbene la classe da me implementata non possa essere paragonata per le sue prestazioni a un array bidimensionale di dati di tipo singolo (con accesso diretto ai dati), sembrava comunque comoda da usare. Inoltre, questa classe può essere considerata come un'implementazione della classe Variant in C++, come un caso particolare di una tabella degenerata in una colonna.
Per gli impazienti e per coloro che non vogliono analizzare l'algoritmo di implementazione, inizierò a descrivere la classe CTable con i metodi disponibili.
1. Descrizione dei metodi di classe
Innanzitutto, consideriamo i metodi disponibili della classe con una descrizione più dettagliata del loro scopo e dei principi di utilizzo.
1.1. FirstResize
Layout della tabella, descrizione dei tipi di colonna, TYPE[], un array del tipo ENUM_DATATYPE che determina la dimensione della riga e i tipi di celle.
void FirstResize(const ENUM_DATATYPE &TYPE[]);
In pratica, questo metodo è un costruttore aggiuntivo con un parametro. Ciò è conveniente per due motivi: in primo luogo, risolve il problema del passaggio di un parametro all'interno del costruttore; in secondo luogo, offre la possibilità di passare un oggetto come parametro e quindi eseguire la divisione necessaria dell'array. Questa funzionalità consente di utilizzare la classe come classe Variant in C++.
Le peculiarità dell'implementazione includono il fatto che nonostante la funzione imposti la prima dimensione e il tipo di dati delle colonne, non richiede di specificare una dimensione della prima dimensione come parametro. Questo parametro è preso dalla dimensione dell'array precedente TYPE.
1.2. SecondResize
Modifica il numero di righe in 'j'.
void SecondResize(int j);
La funzione imposta una dimensione specificata per tutti gli array della seconda dimensione. Quindi, possiamo dire che aggiunge righe a una tabella.
1.3. FirstSize
Il metodo restituisce la dimensione della prima dimensione (lunghezza della riga).
int FirstSize();
1.4. SecondSize
Il metodo restituisce la dimensione della seconda dimensione (lunghezza della colonna).
int SecondSize();1.5. PruningTable
Imposta una nuova dimensione per la prima dimensione; la modifica è possibile all'interno della dimensione iniziale.
void PruningTable(int count);
In pratica, la funzione non cambia la lunghezza della riga; riscrive solo il valore di una variabile, la quale è responsabile della memorizzazione del valore della lunghezza della riga. La classe contiene un'altra variabile che memorizza la dimensione effettiva della memoria allocata, la quale è impostata alla divisione iniziale di una tabella. All'interno dei valori di questa variabile è possibile il cambio virtuale di dimensione della prima dimensione. La funzione ha lo scopo di tagliare una parte indesiderata quando si copia una tabella in un'altra.
1.6. CopyTable
Il metodo per copiare una tabella in un'altra sull'intera lunghezza della seconda dimensione:
void CopyTable(CTable *sor);La funzione copia una tabella in un'altra e avvia l'inizializzazione della tabella ricevente. Può essere utilizzata come costruttore aggiuntivo. La struttura interna delle varianti di ordinamento non viene copiata. Dalla tabella iniziale vengono copiati solo le dimensioni, i tipi di colonne e i dati. La funzione accetta come parametro il riferimento dell'oggetto copiato di tipo CTable, che viene passato dalla funzione GetPointer.
Copiando una tabella in un'altra, viene creata una nuova tabella secondo l'esempio 'sor'.
void CopyTable(CTable *sor,int sec_beg,int sec_end);
Riscrittura della funzione sopra descritta con i parametri aggiuntivi: sec_beg, punto iniziale della copia della tabella iniziale, sec_end, punto finale della copia (da non confondere con la quantità di dati copiati). Entrambi i parametri si riferiscono alla seconda dimensione. I dati verranno aggiunti all'inizio della tabella dei destinatari. La dimensione della tabella di ricezione è impostata come sec_end-sec_beg+1.
1.7. TypeTable
Restituisce il valore type_table (del tipo ENUM_DATATYPE) della colonna 'i'.
ENUM_DATATYPE TypeTable(int i)
1.8. Modifica
Il metodo Change() esegue lo scambio di colonne.
bool Change(int &sor0,int &sor1);
Come accennato in precedenza, il metodo scambia le colonne (funziona con la prima dimensione). Poiché l'informazione non viene effettivamente spostata, la velocità di funzionamento della funzione non è influenzata dalla dimensione della seconda dimensione.
1.9. Insert
Il metodo Insert inserisce una colonna in una posizione specificata.
bool Insert(int rec,int sor);
La funzione è la stessa di quella sopra descritta, eccetto che esegue il traino o la spinta di altre colonne a seconda di dove deve essere spostata la colonna specificata. Il parametro 'rec' specifica dove verrà spostata la colonna, 'sor' specifica da dove verrà spostata.
1.10. Variant/VariantCopy
Poi ci sono tre funzioni della serie 'variant'. La memorizzazione delle varianti dell'elaborazione della tabella è implementata nella classe.
Le varianti ricordano un notebook. Ad esempio, se si esegue l'ordinamento in base alla terza colonna e non si desidera reimpostare i dati durante l'elaborazione successiva, è necessario cambiare la variante. Per accedere alla precedente variante di elaborazione, chiamare la funzione 'variant'. Se l'elaborazione successiva dovesse basarsi sul risultato della precedente, sarà necessario copiare le varianti. Di default è impostata una variante con il numero 0.
Impostando una variante (se non esiste tale variante, verrà creata insieme a tutte le varianti mancanti fino a 'ind'), si ottiene la variante attiva. Il metodo 'variantcopy' copia la variante 'sor' nella variante 'rec'.
void variant(int ind); int variant(); void variantcopy(int rec,int sor);
Il metodo variant(int ind) cambia la variante selezionata. Esegue l'allocazione automatica della memoria. Se il parametro specificato è minore di quello precedentemente specificato, la memoria non viene riallocata.
Il metodo variantcopy consente di copiare la variante 'sor' nella variante 'rec'. La funzione viene creata per disporre le varianti. Aumenta automaticamente il numero di varianti se la variante 'rec' non esiste; inoltre passa alla variante appena copiata.
1.11. SortTwoDimArray
Il metodo SortTwoDimArray ordina una tabella in base alla riga "i" selezionata.
void SortTwoDimArray(int i,int beg,int end,bool mode=false);
La funzione di ordinamento di una tabella in base a una colonna specificata. Parametro: i - colonna, inizio - punto iniziale dell'ordinamento, fine - punto finale dell'ordinamento (incluso), modalità - variabile booleana che determina la direzione dell'ordinamento. Se mode=true, significa che i valori aumentano insieme agli indici ('false' è il valore predefinito, perché gli indici aumentano dall'alto verso il basso della tabella).
1.12. QuickSearch
Il metodo esegue una ricerca rapida della posizione di un elemento nell'array in base al valore uguale al modello 'element'.
int QuickSearch(int i,long element,int beg,int end,bool mode=false);
1.13. SearchFirst
Cerca il primo elemento che è uguale a un modello in un array ordinato. Restituisce l'indice del primo valore che è uguale al modello 'element'. È necessario specificare il tipo di ordinamento eseguito in precedenza in questo intervallo (se non esiste tale elemento, restituisce -1).
int SearchFirst(int i,long element,int beg,int end,bool mode=false);
1.14. SearchLast
Cerca l'ultimo elemento che è uguale a un modello in un array ordinato.
int SearchLast(int i,long element,int beg,int end,bool mode=false);
1.15. SearchGreat
Cerca l'elemento più vicino che è maggiore di un modello in un array ordinato.
int SearchGreat(int i,long element,int beg,int end,bool mode=false);
1.16. SearchLess
Cerca l'elemento più vicino che è minore di un modello in un array ordinato.
int SearchLess(int i,long element,int beg,int end,bool mode=false);
1.17. Set/Get
Le funzioni Set e Get hanno il tipo void; vengono sovrascritti da quattro tipi di dati con cui lavora la tabella. Le funzioni riconoscono il tipo di dati, quindi se il parametro 'value' non corrisponde al tipo di colonna, viene stampato un avviso invece di assegnare. L'unica eccezione è il tipo stringa. Se il parametro di input è di tipo stringa, verrà eseguito il cast al tipo di colonna. Questa eccezione viene fatta per una trasmissione più conveniente delle informazioni quando non è possibile impostare una variabile che accetti il valore della cella.
I metodi di impostazione dei valori (i - indice della prima dimensione, j - indice della seconda dimensione).
void Set(int i,int j,long value); // setting value of the i-th row and j-th column void Set(int i,int j,double value); // setting value of the i-th row and j-th columns void Set(int i,int j,datetime value);// setting value of the i-th row and j-tj column void Set(int i,int j,string value); // setting value of the i-th row and j-th column
Metodi per ottenere valori (i - indice della prima dimensione, j- indice della seconda dimensione).
//--- getting value void Get(int i,int j,long &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,double &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,datetime &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,string &recipient); // getting value of the i-th row and j-th column
1.19. sGet
Ottiene un valore di tipo stringa dalla colonna "j" e dalla riga "i".
string sGet(int i,int j); // return value of the i-th row and j-th column
L'unica funzione della serie Get che restituisce il valore tramite l'operatore 'return' invece di una variabile parametrica. Restituisce un valore del tipo stringa indipendentemente dal tipo di colonna.
1.20. StringDigits
Quando i tipi vengono convertiti in "stringa", puoi utilizzare una precisione impostata dalle funzioni:
void StringDigits(int i,int digits);
per impostare la precisione di 'double' e
int StringDigits(int i);
per impostare una precisione di visualizzazione dei secondi in 'datetime'; viene passato qualsiasi valore diverso da -1. Il valore specificato viene memorizzato per la colonna, quindi non è necessario indicarlo ogni volta durante la visualizzazione delle informazioni. È possibile impostare una precisione molte volte, poiché le informazioni vengono archiviate nei tipi originali e vengono trasformate nella precisione specificata solo durante l'output. I valori di precisione non vengono memorizzati durante la copia, quindi, quando si copia una tabella in una nuova, la precisione delle colonne della nuova tabella corrisponderà alla precisione predefinita.
1.21. Un esempio di utilizzo:
#include <Table.mqh> ENUM_DATATYPE TYPE[7]= {TYPE_LONG,TYPE_LONG,TYPE_STRING,TYPE_DATETIME,TYPE_STRING,TYPE_STRING,TYPE_DOUBLE}; // 0 1 2 3 4 5 6 //7 void OnStart() { CTable table,table1; table.FirstResize(TYPE); // dividing table, determining column types table.SecondResize(5); // change the number of rows table.Set(6,0,"321.012324568"); // assigning data to the 6-th column, 0 row table.Insert(2,6); // insert 6-th column in the 2-nd position table.PruningTable(3); // cut the table to 3 columns table.StringDigits(2,5); // set precision of 5 digits after the decimal point Print("table ",table.sGet(2,0)); // print the cell located in the 2-nd column, 0 row table1.CopyTable(GetPointer(table)); // copy the entire table 'table' to the 'table1' table table1.StringDigits(2,8); // set 8-digit precision Print("table1 ",table1.sGet(2,0)); // print the cell located in the 2-nd column, 0 row of the 'table1' table. }
Il risultato dell'operazione è la stampa del contenuto della cella (2;0). Come probabilmente avrai notato, la precisione dei dati copiati non supera la precisione della tabella iniziale.
2011.02.09 14:18:37 Table Script (EURUSD,H1) table1 321.01232000 2011.02.09 14:18:37 Table Script (EURUSD,H1) table 321.01232
Passiamo ora alla descrizione dell'algoritmo stesso.
2. La scelta di un modello
Esistono due modi per organizzare le informazioni: lo schema delle colonne collegate (implementato in questo articolo) e la sua alternativa sotto forma di righe collegate che sono mostrati di seguito.
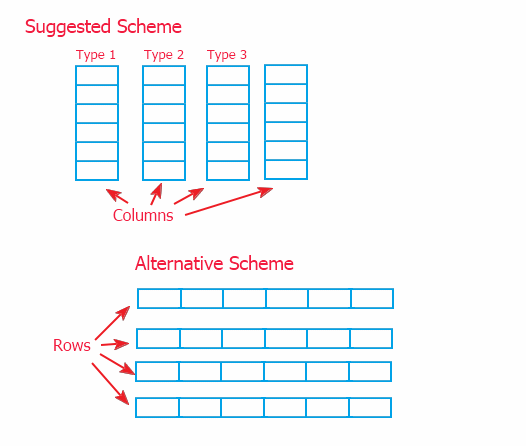
Poiché si fa riferimento alle informazioni tramite un intermediario (descritto a p. 2), non c'è una grande differenza nell'attuazione dello scope superiore. Ma ho scelto il modello delle colonne poiché consente di implementare il metodo dei dati sullo scope inferiore, negli oggetti che memorizzano i dati. E lo schema alternativo richiederebbe la riscrittura dei metodi per lavorare con le informazioni nella classe superiore CTable. E questo può complicare il potenziamento della classe, nel caso sia necessario.
A questo proposito, si può utilizzare ciascuno degli schemi. Lo schema suggerito consente lo spostamento rapido dei dati e quello alternativo consente l'aggiunta più rapida di dati (perché le informazioni vengono aggiunte più spesso a una tabella riga per riga) e l'acquisizione di righe.
C'è anche un altro modo di organizzare una tabella: come un array di strutture. E sebbene sia il più semplice da implementare, presenta uno svantaggio significativo. La struttura deve essere descritta da un programmatore. Pertanto, perdiamo la possibilità di impostare gli attributi della tabella tramite parametri personalizzati (senza modificare il codice sorgente).
3. Unione di dati in un array dinamico
Per avere la possibilità di unire diversi tipi di dati in un unico array dinamico, è necessario risolvere il problema dell'assegnazione di tipi diversi alle celle dell'array. Questo problema è già risolto negli elenchi collegati della libreria standard. I miei primi sviluppi si basavano sulla libreria standard di classi. Ma, durante lo sviluppo del progetto, sembrava che avrei dovuto apportare molte modifiche alla classe base CObject.
Ecco perché ho deciso di sviluppare la mia classe. Per chi non ha studiato la libreria standard, spiegherò come si risolve il problema sopra descritto. Per risolvere il problema è necessario utilizzare il meccanismo dell'ereditarietà.
class CBase { public: CBase(){Print(__FUNCTION__);}; ~CBase(){Print(__FUNCTION__);}; virtual void set(int sor){}; virtual void set(double sor){}; virtual int get(int k){return(0);}; virtual double get(double k){return(0);}; }; //+------------------------------------------------------------------+ class CA: public CBase { private: int temp; public: CA(){Print(__FUNCTION__);}; ~CA(){Print(__FUNCTION__);}; void set(int sor){temp=sor;}; int get(int k){return(temp);}; }; //+------------------------------------------------------------------+ class CB: public CBase { private: double temp; public: CB(){Print(__FUNCTION__);}; ~CB(){Print(__FUNCTION__);}; void set(double sor){temp=sor;}; double get(double k){return(temp);}; }; //+------------------------------------------------------------------+ void OnStart() { CBase *a; CBase *b; a=new CA(); b=new CB(); a.set(15); b.set(13.3); Print("a=",a.get(0)," b=",b.get(0.)); delete a; delete b; }
Visivamente, il meccanismo dell'ereditarietà può essere mostrato come un pettine:

Se viene dichiarata la creazione di un oggetto dinamico della classe, significa che si chiamerà il costruttore della classe base. Questa proprietà consente di creare un oggetto in due passaggi. Poiché le funzioni virtuali della classe base vengono riscritte, abbiamo la possibilità di chiamare la funzione con diversi tipi di parametri dalle classi derivate.
Perché non è basta riscrivere? Il problema è che le funzioni eseguite sono enormi, quindi se descrivessimo i loro corpi nella classe base (senza usare l'ereditarietà), allora la funzione inutilizzata con il codice completo del corpo verrebbe creata per ogni oggetto nel codice binario. E, quando si utilizza il meccanismo dell'ereditarietà, vengono create funzioni vuote che occupano molta meno memoria rispetto alle funzioni piene di codice.
4. Operazioni con gli array
Il secondo e principale caposaldo che mi ha portato a rifiutare l’uso delle classi standard, è il riferimento ai dati. Uso il riferimento indiretto alle celle dell'array attraverso un array intermedio di indici invece di fare riferimento agli indici delle celle. Prevede una velocità di lavoro inferiore rispetto a quando si utilizza il riferimento diretto tramite una variabile. Il problema è la variabile che indica che un indice funziona più velocemente di una cella di array che, all'inizio, si trova nella memoria.
Analizziamo qual è la differenza fondamentale nell'ordinamento di un array unidimensionale e multidimensionale. Prima dell'ordinamento, un array unidimensionale possiede posizioni casuali di elementi che, dopo l'ordinamento, vengono organizzati. Quando si attua la suddivisione di un array bidimensionale, non è necessario suddividere l'intero array, ma solo una delle sue colonne da cui viene eseguito l'ordinamento. Tutte le righe devono cambiare posizione mantenendo la loro struttura.
Le righe stesse qui sono le strutture associate che contengono dati di tipi diversi. Per risolvere tale problema, abbiamo bisogno sia di ordinare i dati in un array selezionato sia di salvare la struttura degli indici iniziali. In questo modo, se sappiamo quale riga conteneva la cella, potremo visualizzare l'intera riga. Pertanto, quando si ordina un array bidimensionale, è necessario ottenere l'array di indici dell'array ordinato senza modificare la struttura dei dati.
Per esempio:
before sorting by the 2-nd column 4 2 3 1 5 3 3 3 6 after sorting 1 5 3 3 3 6 4 2 3 Initial array looks as following: a[0][0]= 4; a[0][1]= 2; a[0][2]= 3; a[1][0]= 1; a[1][1]= 5; a[1][2]= 3; a[2][0]= 3; a[2][1]= 3; a[2][2]= 6; And the array of indexes of sorting by the 2-nd column looks as: r[0]=1; r[1]=2; r[2]=0; Sorted values are returned according to the following scheme: a[r[0]][0]-> 1; a[r[0]][1]-> 5; a[r[0]][2]-> 3; a[r[1]][0]-> 3; a[r[1]][1]-> 3; a[r[1]][2]-> 6; a[r[2]][0]-> 4; a[r[2]][1]-> 2; a[r[2]][2]-> 3;
Pertanto, abbiamo la possibilità di ordinare le informazioni per simbolo, data di apertura della posizione, profitto, ecc.
Sono già stati sviluppati molti algoritmi di ordinamento. La migliore variante per questo sviluppo sarà l'algoritmo di suddivisione stabile.
L'algoritmo Quick Sorting, utilizzato nelle classi standard, si riferisce agli algoritmi di ordinamento instabile. Ecco perché non ci si addice nella sua implementazione classica. Ma anche dopo aver portato l'ordinamento rapido in una forma stabile (ed è un'ulteriore copia di dati e ordinamento di array di indici), l'ordinamento rapido sembra essere più veloce dell'ordinamento a bolle (uno degli algoritmi più veloci di ordinamento stabile). L'algoritmo è molto veloce, ma utilizza la ricorsività.
Questo è il motivo per cui utilizzo Cocktail sort quando lavoro con array di tipo stringa (richiede molta più memoria dello stack).
5. Disposizione di un array bidimensionale
E l'ultima domanda a cui voglio rispondere riguarda la disposizione di un array dinamico bidimensionale. Per tale disposizione è sufficiente creare un wrapping come classe per un array unidimensionale e chiamare l'array di oggetti tramite l'array di puntatori. In altre parole, dobbiamo creare un array di array.
class CarrayInt { public: ~CarrayInt(){}; int array[]; }; //+------------------------------------------------------------------+ class CTwoarrayInt { public: ~CTwoarrayInt(){}; CarrayInt array[]; }; //+------------------------------------------------------------------+ void OnStart() { CTwoarrayInt two; two.array[0].array[0]; }
6. Struttura del programma
Il codice della classe CTable è stato scritto utilizzando i modelli descritti nell'articolo Using Pseudo-Templates as Alternative of С++ Templates. Solo grazie all'utilizzo dei modelli, ho potuto scrivere un codice così grande così rapidamente. Ecco perché non descriverò l'intero codice nei dettagli; inoltre, gran parte del codice degli algoritmi è una modifica delle classi standard.
Mostrerò solo la struttura generale della classe e alcune delle caratteristiche più interessanti delle sue funzioni che chiariscono alcuni punti importanti.

La parte destra dello schema a blocchi è occupata principalmente dai metodi riscritti che si trovano nelle classi derivate CLONGArray, CDOUBLEArray, CDATETIMEArray e CSTRINGArray. Ciascuno di essi (nella sezione privata) contiene un array del tipo corrispondente. Quegli array esatti sono usati per tutti i trucchi di accesso alle informazioni. I nomi dei metodi delle classi sopra elencate sono gli stessi dei metodi pubblici.
La classe base CBASEArray è compilata con la riscrittura dei metodi virtuali ed è necessaria solo per la dichiarazione dell'array dinamico di oggetti CBASEArray nella sezione privata della classe CTable. L'array di puntatori CBASEArray è dichiarato come un array dinamico di oggetti dinamici. La costruzione finale degli oggetti e la scelta dell'istanza necessaria viene eseguita nella funzione FirstResize(). Si può anche eseguire nella funzione CopyTable(), perché chiama FirstResize() nel suo corpo.
La classe CTable svolge anche il coordinamento dei metodi di elaborazione dei dati (collocati nelle istanze della classe CTable) e l'oggetto del controllo degli indici della classe Cint2D. L'intero coordinamento è racchiuso nei metodi pubblici riscritti.
Le parti frequentemente ripetute di riscrittura nella classe CTable vengono sostituite con delle definizioni per evitare di produrre righe molto lunghe:
#define _CHECK0_ Print(__FUNCTION__+"("+(string)i+","+(string)j+")");return; #define _CHECK_ Print(__FUNCTION__+"("+(string)i+")");return(-1); #define _FIRST_ first_data[aic[i]] #define _PARAM0_ array_index.Ind(j),value #define _PARAM1_ array_index.Ind(j),recipient #define _PARAM2_ element,beg,end,array_index,mode
Quindi, parte di una forma più compatta:
int QuickSearch(int i,long element,int beg,int end,bool mode=false){if(!check_type(i,TYPE_LONG)){_CHECK_}return(_FIRST_.QuickSearch(_PARAM2_));};
sarà sostituita con la seguente riga dal preprocessore:
int QuickSearch(int i,long element,int beg,int end,bool mode=false){if(!check_type(i,TYPE_LONG)){Print(__FUNCTION__+"("+(string)i+")");return(-1);} return(first_data[aic[i]].QuickSearch(element,beg,end,array_index,mode));};
Nell'esempio sopra è chiaro come vengono chiamate le modalità di trattamento dei dati (la parte all'interno di 'return').
Ho già detto che la classe CTable non esegue lo spostamento fisico dei dati durante l'elaborazione; cambia solo il valore nell'oggetto degli indici. Per dare ai metodi di elaborazione dei dati la possibilità di interagire con l'oggetto degli indici, viene passato a tutte le funzioni di elaborazione come parametro array_index.
L'oggetto array_index memorizza la relazione posizionale degli elementi della seconda dimensione. L'indicizzazione della prima dimensione è responsabilità dell'array dinamico aic[] dichiarato nella zona privata della classe CTable. Dà la possibilità di cambiare la posizione delle colonne (non fisicamente, ovviamente, ma tramite indici).
Ad esempio, quando si esegue l'operazione Change() solo due celle di memoria, le quali contengono gli indici delle colonne, cambiano posizione. Anche se visivamente sembra che si muovano di due colonne. Le funzioni della classe CTable sono descritte abbastanza bene nella documentazione (anche riga per riga in alcune parti).
Passiamo ora alle funzioni delle classi ereditate da CBASEArray. In realtà, gli algoritmi di queste classi sono gli algoritmi presi dalle classi standard. Ho utilizzato i nomi standard per farmene un'idea. La modifica consiste nella restituzione indiretta dei valori utilizzando un array di indici diverso dagli algoritmi standard in cui i valori vengono restituiti direttamente.
Innanzitutto, è stata apportata la modifica all'ordinamento rapido. Poiché l'algoritmo appartiene alla categoria degli instabili, prima di iniziare l'ordinamento è necessario eseguire una copia dei dati, la quale verrà passata all'algoritmo. Ho anche aggiunto la modifica sincrona dell'oggetto degli indici secondo lo schema di modifica dei dati.
void CLONGArray::QuickSort(long &m_data[],Cint2D &index,int beg,int end,bool mode=0)
Ecco la parte dell'ordinamento del codice:
... if(i<=j) { t=m_data[i]; it=index.Ind(i); m_data[i++]=m_data[j]; index.Ind(i-1,index.Ind(j)); m_data[j]=t; index.Ind(j,it); if(j==0) break; else j--; } ...
Non c'è alcuna istanza della classe Cint2D nell'algoritmo originale. Modifiche simili vengono apportate agli altri algoritmi standard. Non descriverò i modelli di tutti i codici. Se c’è qualcuno che vuole migliorare il codice, potrà creare un modello dal codice reale sostituendo i tipi reali con il modello.
Per scrivere i modelli, ho usato i codici della classe che funziona con il tipo long. Per algoritmi economici simili, gli sviluppatori cercano di evitare l'uso non necessario di numeri interi se esiste la possibilità di utilizzare int. Ecco perché una variabile di tipo long è molto probabilmente un parametro sovrascritto. Devono essere sostituiti con 'templat' quando si utilizzano i modelli.
Conclusione
Spero che questo articolo sia un valido aiuto per i programmatori alle prime armi che studiano l'approccio orientato agli oggetti e mi auguro che renderà più semplice lavorare con le informazioni. La classe CTable può diventare una classe base per molte applicazioni complesse. I metodi descritti nell'articolo possono diventare una base per lo sviluppo di una vasta classe di soluzioni, poiché implementano un approccio generale al lavoro con i dati.
Inoltre, l'articolo dimostra che l'abuso di MQL5 è infondato. Volevate il tipo Variant? Qui è implementato tramite MQL5. Per questo, non è necessario modificare gli standard e indebolire la sicurezza del linguaggio. Buona fortuna!
Tradotto dal russo da MetaQuotes Ltd.
Articolo originale: https://www.mql5.com/ru/articles/228
 L'implementazione di una modalità multivaluta su MetaTrader 5
L'implementazione di una modalità multivaluta su MetaTrader 5
 Approccio econometrico all'analisi dei grafici
Approccio econometrico all'analisi dei grafici
 Collegare NeuroSolutions Neuronets
Collegare NeuroSolutions Neuronets
 Il Wizard MQL5: Come creare un modulo di segnali di trading
Il Wizard MQL5: Come creare un modulo di segnali di trading
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso