
Redes neurais de maneira fácil (Parte 51): ator-crítico comportamental (BAC)

Introdução
Os dois últimos artigos foram dedicados ao algoritmo Soft Actor-Critic. Lembre-se de que esse algoritmo é usado para treinar modelos estocásticos em espaços de ação contínua. A característica principal desse método é a introdução de um componente de entropia na função de recompensa, o que permite regular o equilíbrio entre a exploração do ambiente e a operação do modelo. No entanto, essa abordagem impõe algumas limitações aos modelos treinados. O uso da entropia requer algum conhecimento da probabilidade de ação, o que é bastante difícil de calcular diretamente em espaços de ação contínua.
Nós adotamos a abordagem do uso de distribuições de quantil. E aqui está a adição de ajuste de hiperparâmetros para a distribuição de quantil. A própria abordagem do uso de distribuições de quantil nos afasta um pouco do espaço de ação contínua. Afinal, a cada escolha de ação, escolhemos um quantil de uma distribuição de probabilidade aprendida e usamos seu valor médio como a ação. Sim, com um número suficientemente grande de quantis e uma faixa suficientemente estreita de valores possíveis, nos aproximamos de um espaço de ação contínua. Mas isso aumenta a complexidade do modelo e os custos de treinamento e operação. E, claro, impõe limitações à arquitetura dos modelos treinados.
Neste artigo, vamos falar sobre uma abordagem alternativa chamada Ator-Crítico Comportamental (Behavior-Guided Actor-Critic, BAC), que foi introduzida em abril de 2021.
1. Características da construção do algoritmo
Vamos começar discutindo a necessidade de explorar o ambiente em geral. Acredito que todos concordamos com a importância desse processo. Mas para que serve especificamente e em que estágio?
Comecemos com um exemplo simples. Estamos entrando em uma sala com 3 portas idênticas e precisamos encontrar a saída para a rua. O que fazemos? Abrimos as portas uma a uma até encontrarmos a saída. Se voltarmos a entrar na mesma sala para sair novamente, não abriremos todas as portas, iremos direto para a saída conhecida. No entanto, se tivermos uma tarefa diferente, existem opções. Podemos abrir todas as portas novamente, exceto aquela que já sabemos ser a saída, e procurar a que precisamos. Ou podemos primeiro lembrar quais portas abrimos anteriormente ao procurar a saída e verificar se a que precisamos estava entre elas. Se lembrarmos da porta necessária, seguimos em direção a ela. Caso contrário, verificamos as portas que não foram abertas anteriormente.
Conclusão: A exploração do ambiente é necessária quando estamos em um estado desconhecido para escolher a ação correta. Após encontrar a rota necessária, a exploração adicional do ambiente pode apenas atrapalhar.
No entanto, ao alterar a tarefa em um estado conhecido, pode ser necessário explorar o ambiente adicionalmente. Isso inclui a busca por uma rota mais otimizada. No exemplo acima, se precisarmos passar por mais salas para sair ou sair do lado errado do prédio.
Portanto, precisamos de um algoritmo que permita intensificar a exploração do ambiente em estados não explorados e minimizar em estados previamente explorados.
A regularização de entropia usada no Soft Actor-Critic pode atender a esse requisito, mas com algumas condições. A entropia da ação é alta quando a probabilidade dela é baixa. Sim, o estado para o qual nos movemos após uma ação com baixa probabilidade provavelmente é mal explorado. A regularização de entropia nos incentiva a repeti-la para melhor explorar os estados subsequentes. Mas o que acontece após a análise desse vetor de movimento? Se encontrarmos um caminho mais ótimo, a probabilidade de executar essa ação aumenta e a entropia diminui. Isso atende aos nossos requisitos. No entanto, a probabilidade de outras ações diminui e sua entropia aumenta. Isso nos leva a explorar outras direções adicionalmente. E somente uma recompensa significativamente positiva pode manter nosso foco nesse caminho.
Por outro lado, se a nova rota não atender aos nossos requisitos, durante o treinamento do modelo, reduzimos a probabilidade dessa ação. Isso aumenta ainda mais sua entropia, incentivando-nos a repetir a ação. E somente uma penalização significativamente negativa (multa) pode nos afastar de tomar essa ação precipitada.
É por isso que a escolha equilibrada do coeficiente de temperatura é crucial para garantir o equilíbrio adequado entre a análise e a operação do modelo.
É um pouco estranho. Começamos com uma estratégia ε-greedy, na qual o equilíbrio entre reconhecimento e exploração era regulado por uma probabilidade constante. Complicamos o modelo e estamos novamente discutindo a importância da escolha do coeficiente. Deja vu.
Em busca de uma solução diferente, estamos direcionando nossa atenção para o algoritmo Behavior-Guided Actor-Critic (BAC), que foi apresentado no artigo "Behavior-Guided Actor-Critic: Improving Exploration via Learning Policy Behavior Representation for Deep Reinforcement Learning". Os autores desse método propõem substituir o componente de entropia na função de recompensa por uma medida de familiaridade da dupla estado-ação aprendida pelo modelo.
A escolha da dupla "Estado-Ação" é bastante óbvia - é o que sabemos em um momento específico. Quando estamos em um determinado estado, escolhemos uma ação. E, em certa medida, nossa transição para o próximo estado e a recompensa por essa transição dependem dela. Além disso, a mesma ação pode resultar na transição esperada para um novo estado, ou pode levar a outro estado (com uma certa probabilidade). Por exemplo, para abrir uma porta, é necessário se aproximar dela. Neste caso, é bastante previsível que a cada passo estejamos mais perto da porta. Em seguida, ao girar a maçaneta da porta, a abrimos. No entanto, pode estar trancada e não se abrir (um fator fora do nosso controle). A recompensa ou penalização nos aguarda do outro lado da porta. No entanto, não saberemos disso até chegarmos lá. Portanto, só podemos considerar que um estado foi completamente explorado após examinar todas as ações possíveis desse estado.
Como medida de familiaridade da dupla "Estado-Ação", os autores do método propõem o uso de um autocodificador. Vale ressaltar que já nos deparamos várias vezes com o uso de autocodificadores em diferentes algoritmos. No entanto, isso geralmente estava relacionado à compressão de dados ou à construção de modelos de interdependência. A experiência mostra que a construção de modelos para mercados financeiros é uma tarefa bastante complexa, devido ao grande número de fatores de influência nem sempre óbvios. No entanto, neste caso, outra propriedade do autocodificador é utilizada.
O autocodificador, em sua forma pura, reproduz bem os dados brutos. No entanto, o autocodificador é uma rede neural. E desde o início, afirmamos que redes neurais funcionam bem apenas com dados aprendidos. Caso contrário, seus resultados podem ser imprevisíveis. É por isso que sempre enfatizamos a importância da representatividade do conjunto de treinamento e da consistência dos hiperparâmetros do modelo durante o treinamento e operação.
Os autores do método aproveitaram essa propriedade das redes neurais. Após o treinamento em um conjunto de estados e ações conhecidos, obtemos uma boa reprodução deles na saída do autocodificador. No entanto, basta fornecer ao modelo uma dupla "Estado-Ação" desconhecida como entrada, e o erro na reprodução dos dados aumentará significativamente. É precisamente esse erro na reprodução dos dados que usaremos como medida de familiaridade da dupla "Estado-Ação".
Esse enfoque tem várias vantagens em relação à regularização de entropia. Primeiro, esse método é aplicável tanto a modelos estocásticos quanto determinísticos. O uso do autocodificador não afeta a escolha da arquitetura do Ator.
Em segundo lugar, o reforço da recompensa para o par "Estado-Ação" diminui à medida que ele é explorado, independentemente da recompensa recebida e da probabilidade de realizar a ação no futuro. À medida que o autocodificador é treinado, a recompensa tende a se aproximar de zero, levando ao uso total do modelo.
No entanto, quando um novo estado surge (e, dada a capacidade de generalização das redes neurais, pode ser bastante diferente dos estados previamente explorados), o modo de exploração do ambiente é ativado imediatamente.
Além disso, a recompensa de estímulo para um par "Estado-Ação" é absolutamente independente do grau de treinamento, da probabilidade de desempenho ou de outros fatores de outra ação do mesmo estado.
Naturalmente, estamos lidando com um espaço de ação contínua, e o modelo é capaz de generalizar a experiência adquirida. No entanto, ao explorar um par "Estado-Ação", a transferência de dados continuará a variar continuamente, dependendo da proximidade (semelhança) dos estados e ações.
Matematicamente, o treinamento da política pode ser representado da seguinte forma:
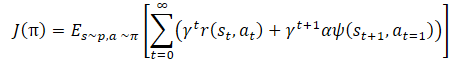
onde γ é o coeficiente de desconto,
α é o coeficiente de temperatura,
ψ(St+1, At=1) é a função de comportamento do estado subsequente (erro de cópia pelo autocodificador).
E aqui vemos novamente o coeficiente de temperatura para equilibrar o reconhecimento e a exploração do modelo. Isso, mais uma vez, leva às complexidades mencionadas na configuração de hiperparâmetros e no treinamento do modelo. Os autores do método propuseram uma pequena modificação na função de treinamento da política.
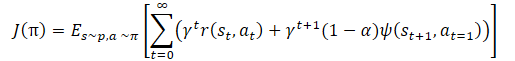
E o próprio coeficiente de temperatura α é determinado pela fórmula:
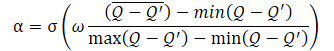
onde σ é a função sigmoide,
ω é igual a 10,
Q é a rede neural de avaliação da qualidade da ação.
A rede neural Q usada aqui é análoga ao crítico e avalia a qualidade da ação em um estado específico com base na política atual.
Como pode ser visto na fórmula apresentada, o coeficiente de temperatura (1-α) varia de 0 a 0,5. Aumenta à medida que a avaliação da qualidade da ação aumenta. É claro que neste momento o erro de cópia dos dados pelo autocodificador tende a zero. Com uma alta probabilidade, o modelo está em um mínimo local e o reconhecimento do ambiente pode ajudar a sair desse estado.
No entanto, quando a precisão na transferência de dados é baixa, a qualidade da avaliação da ação nesse estado também diminui. Isso leva ao aumento do denominador na função sigmóide. Consequentemente, o valor do argumento da sigmóide diminui, e seu resultado se aproxima de 0,5.
Aqui é importante observar que sempre subtraímos o erro menor do maior. Portanto, o argumento da sigmóide é sempre maior que "0". E quase nunca é igual a "0", pois não podemos dividir por "0".
Também é importante mencionar que o algoritmo apresentado faz parte de uma grande família de algoritmos Ator-Crítico e utiliza abordagens comuns dessa família de algoritmos. Assim como o Soft Actor-Critic, o algoritmo é usado para treinar políticas do Ator em espaços de ação contínuos. Usaremos 2 modelos de Crítico para avaliar a qualidade da ação e distribuir o gradiente do erro entre a recompensa a ação. Também usaremos a atualização suave dos modelos alvo, um buffer de experiência e outras abordagens comuns para treinar modelos Ator-Crítico.
2. Implementação no MQL5
Após examinar os aspectos teóricos desse método proposto, passamos à sua implementação no MQL5. E a primeira coisa com a qual começamos é a arquitetura dos modelos. Para comparar o desempenho dos métodos, não fiz grandes alterações na arquitetura dos modelos da última publicação. No entanto, simplifiquei um pouco a arquitetura do Ator e removi a camada neural complexa que havíamos criado para implementar o algoritmo de Ator estocástico do método Soft Actor-Critic. No entanto, ainda estamos usando uma política estocástica do Ator. Desta vez, alcançamos isso usando uma camada de estado latente de um autocodificador variacional. Como você se lembra, esta camada neural recebe um tensor de dados exatamente 2 vezes maior do que o tamanho do buffer de seus resultados. Este tensor de dados de entrada contém valores médios e dispersão da distribuição para cada elemento dos resultados. Isso nos permite reduzir a complexidade dos cálculos, mas ainda mantém o modelo do Ator como estocástico em um espaço de ação contínuo.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *autoencoder) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!autoencoder) { autoencoder = new CArrayObj(); if(!autoencoder) return false; } //--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = 8; descr.step = 8; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2*NActions; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
O modelo do Crítico foi transferido sem alterações, e não entraremos em detalhes sobre ele.
Vamos falar um pouco sobre o modelo de autocodificador. Como mencionado no bloco teórico, o autocodificador é usado como um elemento de memória para as combinações "Estado-Ação" previamente discutidas. Pode ser visto como uma espécie de contador de visitas para essas combinações de dados. No entanto, lembremos que é exatamente o par "Estado-Ação" que nossos Críticos avaliam. Mais precisamente, o Crítico avalia uma ação específica em um estado específico. É uma questão de terminologia e conceitos, mas é o mesmo conjunto de dados.
Anteriormente, para economizar recursos e tempo de treinamento dos modelos, excluímos o bloco de pré-processamento de dados brutos da arquitetura dos Críticos. Em vez disso, usamos os dados já processados do estado latente do modelo do Ator como entrada para o Crítico. Na entrada do Crítico, concatenamos o estado latente e o buffer de resultados do Ator, combinando-os em um único tensor de estado e ação.
Agora, vamos dar um passo adiante. Na entrada do nosso autocodificador, usaremos o estado latente de um dos Críticos. Sim, poderíamos ter usado uma camada de concatenação de 2 tensores de dados brutos, semelhante ao Crítico. Mas, nesse caso, teríamos que lidar com a comparação entre um buffer de resultados do autocodificador e 2 buffers de dados brutos. Usar um único buffer de dados brutos derivado da representação latente do Crítico nos permite usar um modelo de autocodificador mais simples e comparar os dados brutos diretamente com os resultados do autocodificador em uma correspondência "1:1". Portanto, na arquitetura do autocodificador, usaremos apenas camadas totalmente conectadas.
//--- Autoencoder autoencoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = prev_count / 2; descr.optimization = ADAM; descr.activation = LReLU; if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = prev_count / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 20; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; if(!(descr.Copy(autoencoder.At(2)))) { delete descr; return false; } if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; if(!(descr.Copy(autoencoder.At(1)))) { delete descr; return false; } if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; if(!(descr.Copy(autoencoder.At(0)))) { delete descr; return false; } if(!autoencoder.Add(descr)) { delete descr; return false; } //--- return true; }
Observe que, a partir da quarta camada do autocodificador, não criamos descrições completamente novas para as camadas neurais. Em vez disso, simplesmente copiamos as descrições criadas anteriormente na ordem inversa. Isso nos permite criar um Decodificador que seja uma cópia espelhada do Codificador. Qualquer alteração na arquitetura do Codificador (exceto adição de novas camadas) será refletida imediatamente nas camadas correspondentes do Decodificador. Isso é um método conveniente de sincronização de descrições de arquiteturas de camadas neurais e pode ser aplicado em várias situações.
Após criar as descrições da arquitetura dos modelos, passamos à preparação do processo de coleta de exemplos para treinar o modelo. Como antes, esse processo é realizado em um Expert Advisor (EA) chamado "..\BAC\Research.mq5". Vale a pena notar que o método BAC não introduz nenhuma alteração no algoritmo de coleta de dados primários. Portanto, as alterações neste EA foram mínimas.
Acima, modificamos a função de descrição da arquitetura dos modelos, adicionando a descrição do Autocodificador a ela. Portanto, ao chamar essa função no método OnInit do EA Research.mq5, precisamos passar três ponteiros para arrays dinâmicos de descrição da arquitetura dos modelos. No entanto, como neste EA estamos usando apenas o Ator e não precisamos da descrição de outros modelos, não criaremos um array adicional de objetos; em vez disso, passaremos duas vezes o ponteiro para o array de descrição da arquitetura do Crítico. Quando chamada dessa maneira, primeiro a descrição da arquitetura do Crítico será criada na função, em seguida, ela será excluída, e a arquitetura do Autocodificador será gravada no array. Neste caso, não é crítico para nós, pois não estamos usando nem o modelo do Crítico nem o modelo do Autocodificador.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- load models float temp; if(!Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Actor.Create(actor)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; //--- } //--- ........ ........ //--- return(INIT_SUCCEEDED); }
Além disso, estamos excluindo o componente de entropia da função de recompensa. De resto, o código do EA permanece inalterado. Você pode encontrar o código completo do EA e todas as suas funções no anexo.
No entanto, tivemos que trabalhar no código do EA de treinamento de modelos "..\BAC\Study.mq5". Aqui, usamos e inicializamos todos os modelos. Portanto, antes de chamar o método de descrição da arquitetura dos modelos, criamos um array dinâmico adicional para o Autocodificador.
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; } //--- load models float temp; if(!Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !Critic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true) || !Autoencoder.Load(FileName + "AEnc.nnw", temp, temp, temp, dtStudied, true) || !TargetCritic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !TargetCritic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *autoencoder = new CArrayObj(); if(!CreateDescriptions(actor, critic, autoencoder)) { delete actor; delete critic; delete autoencoder; return INIT_FAILED; }
Após obter a arquitetura dos modelos, inicializamos todos os modelos e controlamos o processo de execução das operações.
if(!Actor.Create(actor) || !Critic1.Create(critic) || !Critic2.Create(critic) || !Autoencoder.Create(autoencoder)) { delete actor; delete critic; delete autoencoder; return INIT_FAILED; }
E não nos esquecemos das metas dos Críticos.
if(!TargetCritic1.Create(critic) || !TargetCritic2.Create(critic)) { delete actor; delete critic; delete autoencoder; return INIT_FAILED; } delete actor; delete critic; delete autoencoder; //--- TargetCritic1.WeightsUpdate(GetPointer(Critic1), 1.0f); TargetCritic2.WeightsUpdate(GetPointer(Critic2), 1.0f); }
Em seguida, transferimos todos os modelos para um único contexto OpenCL, como antes. O Autocodificador não é exceção.
OpenCL = Actor.GetOpenCL(); Critic1.SetOpenCL(OpenCL); Critic2.SetOpenCL(OpenCL); TargetCritic1.SetOpenCL(OpenCL); TargetCritic2.SetOpenCL(OpenCL); Autoencoder.SetOpenCL(OpenCL);
Em seguida, vem o bloco de verificação da compatibilidade dos modelos.
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Actor.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Actor doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; } //--- Actor.GetLayerOutput(LatentLayer, Result); int latent_state = Result.Total(); Critic1.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Critic doesn't match latent state Actor (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; }
Aqui, adicionamos uma verificação da compatibilidade entre as arquiteturas do Autocodificador e do Crítico.
Critic1.GetLayerOutput(1, Result); latent_state = Result.Total(); Autoencoder.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Autoencoder doesn't match latent state Critic (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; }
No final do método, como antes, inicializamos um buffer auxiliar e chamamos o evento de treinamento do modelo.
Gradient.BufferInit(AccountDescr, 0); //--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Você deve ter notado que não criamos um modelo adicional para avaliação da qualidade da ação na função de cálculo dinâmico do coeficiente de temperatura. Enfatizamos que a funcionalidade desse modelo é semelhante à do Crítico. Para simplificar o processo geral de treinamento, usaremos os modelos dos nossos Críticos para implementar o cálculo dinâmico do coeficiente de temperatura.
Após a criação dos modelos, não esquecemos de salvá-los no método de desativação do EA OnDeinit. Aqui, destacamos a importância de salvar todos os modelos, bem como os sufixos dos nomes dos arquivos ao salvá-los e especificados ao carregar os modelos correspondentes.
void OnDeinit(const int reason) { //--- TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); TargetCritic1.Save(FileName + "Crt1.nnw", Critic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); TargetCritic1.Save(FileName + "Crt2.nnw", Critic2.getRecentAverageError(), 0, 0, TimeCurrent(), true); Autoencoder.Save(FileName + "AEnc.nnw", Autoencoder.getRecentAverageError(), 0, 0, TimeCurrent(), true); delete Result; }
Com isso, o trabalho preparatório está concluído, e podemos prosseguir com a implementação do algoritmo real de treinamento dos modelos no método Train do nosso EA.
No início do método, não encontraremos surpresas. Como antes, fazemos um laço de treinamento com o número de iterações especificado nos parâmetros externos do EA.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
No corpo do ciclo, determinamos aleatoriamente a trajetória da base de exemplos e o passo específico da trajetória. Em seguida, carregamos informações sobre o estado subsequente nos buffers de dados.
//--- Target State.AssignArray(Buffer[tr].States[i + 1].state); float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- if(Account.GetIndex() >= 0) Account.BufferWrite();
Depois, realizamos a propagação do Ator e das 2 modelos-alvo dos Críticos para determinar o valor do estado futuro, levando em consideração a estratégia atualizada do Ator.
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } //--- if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } TargetCritic1.getResults(Result); float reward = Result[0]; TargetCritic2.getResults(Result); reward = Buffer[tr].Revards[i] + DiscFactor * (MathMin(reward, Result[0]) - Buffer[tr].Revards[i + 1]);
À primeira vista, tudo parece igual ao uso do algoritmo Soft Actor-Critic. Também usamos a estimativa mínima do estado a partir das informações fornecidas por 2 Críticos. No entanto, observe que excluímos a componente de entropia. Isso faz sentido à luz do uso do método BAC. No entanto, não adicionamos a componente comportamental. Isso é uma divergência intencional do algoritmo original. O motivo é que estamos usando uma base de exemplos obtida por meio das passagens do Ator com diferentes políticas. Introduzir a componente comportamental agora distorceria a avaliação do Crítico, sem estimular diretamente o Ator. Sim, posteriormente, receberemos estímulo indireto ao treinar o Ator com base nas avaliações dos Críticos. Mas há outro aspecto a ser considerado: a correspondência entre a frequência de uso do par "Estado-Ação" durante o treinamento do Crítico e o mesmo par ou um par semelhante (ou próximo) "Estado-Ação" durante o treinamento do Ator. O desequilíbrio pode ocorrer em ambas as direções. Portanto, optei por usar um Autocodificador para avaliar estados e ações ao treinar o Ator. Na minha opinião, isso permitirá uma avaliação mais precisa da frequência de visitação dos estados e ações pelo Ator, levando em consideração a atualização de sua política de comportamento.
A próxima etapa é o processo de treinamento dos Críticos. E carregamos os dados do estado selecionado da base de exemplos nos buffers de dados.
//--- Q-function study State.AssignArray(Buffer[tr].States[i].state); PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Update(0, (Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Update(1, Buffer[tr].States[i].account[1] / PrevBalance); Account.Update(2, (Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Update(3, Buffer[tr].States[i].account[2]); Account.Update(4, Buffer[tr].States[i].account[3]); Account.Update(5, Buffer[tr].States[i].account[4] / PrevBalance); Account.Update(6, Buffer[tr].States[i].account[5] / PrevBalance); Account.Update(7, Buffer[tr].States[i].account[6] / PrevBalance); x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); Account.BufferWrite();
Em seguida, realizamos a propagação do Ator. Lembre-se de que, neste caso, estamos usando o Ator para o pré-processamento dos dados de estado do ambiente.
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Em seguida, precisamos realizar passagens diretas e inversas dos Críticos para ajustar seus parâmetros. Ao treinar modelos com o método Soft Actor-Critic, alternávamos entre os modelos. Neste caso, iremos treinar ambos os Críticos simultaneamente com os mesmos exemplos. Chamamos os métodos de propagação dos Críticos para ações da base de exemplos.
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Mas antes de realizar a retropropagação, precisamos preparar os dados para calcular o coeficiente de temperatura da componente comportamental de nossa função de recompensa. Primeiro, comparamos os resultados da avaliação do primeiro Crítico com a avaliação futura calculada anteriormente e atualizamos os valores de erro mínimo, máximo e médio.
Observe que, para a primeira iteração, simplesmente transferimos o erro atual para as 3 variáveis. Em seguida, atualizamos o máximo e o mínimo com base nas comparações. Em seguida, calculamos a média exponencial.
Critic1.getResults(Result); float error = reward - Result[0]; if(iter == 0) { MaxCriticError = error; MinCriticError = error; AvgCriticError = error; } else { MaxCriticError = MathMax(error, MaxCriticError); MinCriticError = MathMin(error, MinCriticError); AvgCriticError = 0.99f * AvgCriticError + 0.01f * error; }
Para o segundo Crítico, já temos valores iniciais para as variáveis. E atualizamos seus valores independentemente da iteração de treinamento dos modelos.
Critic2.getResults(Result); error = reward - Result[0]; MaxCriticError = MathMax(error, MaxCriticError); MinCriticError = MathMin(error, MinCriticError); AvgCriticError = 0.99f * AvgCriticError + 0.01f * error;
No final do processo de atualização dos parâmetros dos Críticos, resta-nos realizar o processo de retropropagação de ambos os modelos, com a mínima avaliação do estado futuro das metas.
Result.Update(0, reward); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Com isso, conclui-se o processo de atualização dos parâmetros dos críticos, e passamos para o treinamento do Ator. Os autores do método BAC recomendam o uso do Crítico com a menor avaliação da ação escolhida para treinar o Ator. Para evitar a necessidade de realizar a propagação pelos 2 Críticos e, em seguida, comparar seus resultados, faremos de maneira um pouco diferente. Vamos pegar o Crítico com o menor erro médio na previsão da avaliação do estado e da ação. Essa avaliação é recalculada a cada retropropagação do modelo Crítico. E sua extração requer um esforço mínimo, que é insignificante em comparação com a realização da propagação do modelo.
E para evitar criar estruturas ramificadas complexas com repetição de ações para o primeiro e segundo modelos do Crítico, simplesmente armazenaremos o ponteiro para o modelo necessário em uma variável local. Em seguida, trabalharemos com essa variável local.
//--- Policy study CNet *critic = NULL; if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) critic = GetPointer(Critic1); else critic = GetPointer(Critic2);
Ao contrário do TD3, os métodos Ator-Crítico atualizam a política do Ator a cada iteração. E usaremos o mesmo conjunto de dados de entrada que escolhemos para treinar os Críticos. Lembre-se de que, durante o treinamento dos Críticos, já realizamos a propagação do Ator com o conjunto de dados atual. Portanto, agora basta fazer a propagação pelo Crítico selecionado para avaliar as ações do Ator no estado atual, levando em consideração a atualização de sua política.
if(!critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Autoencoder.feedForward(critic, 1, NULL, -1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Após a propagação pelo Crítico, realizamos a propagação pelo Autocodificador. Aqui, há um detalhe importante. Anteriormente, ao combinar as duas modelos em uma entidade única, adicionamos à função de propagação a substituição da camada de dados de entrada pela camada latente do modelo subsequente, fornecendo esses dados de entrada. Isso funciona muito bem quando usamos um Ator como doador para 2 Críticos. Na primeira iteração, os Críticos removem a camada de dados de entrada desnecessária e mantêm um ponteiro para a camada latente do Ator. No entanto, no caso do Autocodificador, temos uma situação inversa. Usamos 2 modelos de Crítico como doadores para um Autocodificador. Na primeira iteração, o Autocodificador remove a camada de dados de entrada não utilizada e mantém um ponteiro para a camada latente do Crítico em uso. Mas ao mudar de Crítico, a camada de um Crítico será removida e um ponteiro para a camada de outro Crítico será mantido. Esse processo é altamente indesejável para nós e é prejudicial para todo o nosso processo de treinamento. Portanto, após a primeira remoção da camada de dados de entrada, precisamos desabilitar a sinalização de remoção de objetos ao atualizar o array da camada neural.
bool CNet::feedForward(CNet *inputNet, int inputLayer = -1, CNet *secondNet = NULL, int secondLayer = -1) { ........ ........ //--- if(layer.At(0) != neuron) if(!layer.Update(0, neuron)) { if(del_second) delete second; return false; } else layer.FreeMode(false); //--- ........ ........ //--- return true; }
Isso é um pequeno desvio do processo de treinamento e do algoritmo BAC, mas é crítico para nossa implementação do processo.
Voltando ao algoritmo do nosso método de treinamento de modelos Train. Após a propagação pelo Autocodificador, precisamos avaliar o erro de cópia dos dados. Para fazer isso, carregamos o resultado do trabalho do Autocodificador e os dados originais do estado latente do Crítico. Para melhorar a eficiência de nosso código, usaremos variáveis vetoriais nas quais carregaremos ambos os buffers de dados.
Autoencoder.getResults(AutoencoderResult);
critic.GetLayerOutput(1, Result);
Result.GetData(CriticResult);
E imediatamente carregamos os resultados da avaliação das ações pelo Crítico.
critic.getResults(Result);
Ambos fluxos de informações são necessários para determinar o valor-alvo ao treinar a política do Ator. Portanto, combinamos todo o cálculo em um único bloco.
Anteriormente, preparamos os dados para calcular o coeficiente de temperatura. E agora, primeiro calculamos o argumento da sigmoid. Em seguida, determinamos o valor da função e subtraímos 1 dele.
float alpha = (MaxCriticError == MinCriticError ? 0 : 10.0f * (AvgCriticError - MinCriticError) / (MaxCriticError - MinCriticError)); alpha = 1.0f / (1.0f + MathExp(-alpha)); alpha = 1 - alpha; reward = Result[0]; reward = (reward > 0 ? reward + PoliticAdjust : PoliticAdjust); reward += AutoencoderResult.Loss(CriticResult, LOSS_MSE) * alpha;
Em seguida, seguindo a abordagem do TD3, ajustamos os parâmetros do Ator em direção ao aumento da lucratividade das operações. Desse modo, adicionamos uma pequena constante à avaliação atual da ação, estimulando o deslocamento dos gradientes na direção do aumento da lucratividade.
Finalmente, ao formar o valor alvo, adicionamos a componente comportamental levando em consideração a função de perda do Autocodificador. Observe que, graças às operações vetoriais, o tamanho da função de perda é determinado literalmente em uma única linha.
Agora, depois de formar o valor alvo, podemos realizar a retropropagação pelo Crítico e pelo Ator para distribuir o gradiente de erro até a ação e, em seguida, ajustar os parâmetros do Ator.
Assim como antes, para evitar o ajuste mútuo dos parâmetros do Crítico e do Ator, desativamos o modo de treinamento do Crítico antes de realizar a retropropagação e não esquecemos de ativá-lo novamente após a execução das operações.
Result.Update(0, reward); critic.TrainMode(false); if(!critic.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); critic.TrainMode(true); break; } critic.TrainMode(true);
Aqui, observe que realizamos dois tipos de retropropagação para o Ator. Primeiro, distribuímos o gradiente de erro no bloco de pré-processamento de dados, o que nos permitirá ajustar os filtros das camadas de convolução com mais precisão, levando em consideração as exigências dos Críticos. Em seguida, realizamos a passagem inversa para ajustar o bloco de tomada de decisão para escolher a ação específica. É muito importante realizar essas operações exatamente nesta sequência. Isso ocorre porque, após uma propagação completa com a correção dos parâmetros do bloco de tomada de decisão, eles serão sobrescritos e os gradientes de erro para o bloco de pré-processamento de dados serão perdidos. Nesse caso, a chamada adicional de retropropagação não apenas não terá um efeito positivo, mas também pode ter um impacto negativo.
Neste estágio, atualizamos os parâmetros do Crítico e do Ator. Agora, só nos resta atualizar os parâmetros do Autocodificador. Aqui, tudo é bastante simples. Passamos os dados do estado latente do Crítico como valores de referência e realizamos a passagem inversa do modelo.
//--- Autoencoder study Result.AssignArray(CriticResult); if(!Autoencoder.backProp(Result, critic, 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
No final das iterações do ciclo de treinamento, atualizamos os modelos alvo de ambos os Críticos e informamos o usuário sobre o progresso do treinamento.
//--- Update Target Nets TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); //--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
O final do método de treinamento é o seguinte:
- limpamos o campo de comentários,
- exibimos os resultados de treinamento,
- inicializamos o final do trabalho do EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
Você pode encontrar o código completo do EA de treinamento e todos os programas usados no anexo. Lá, você também encontrará o código do EA de teste, que foi praticamente transferido da artigo anterior sem muitas alterações. No código do EA, apenas a componente de entropia foi removida ao salvar a trajetória percorrida.
Com isso, concluímos o trabalho na construção dos EAs e passamos para o teste do trabalho realizado e o treinamento dos modelos.
Devo dizer que, na minha opinião, neste trabalho, há um grande número de iterações de troca de dados entre a memória principal e o contexto OpenCL. Isso é evidente no bloco de determinação do componente comportamental da função de recompensa. E aqui há algo em que pensar. Mas vamos ver como isso afeta o desempenho geral do processo de treinamento do modelo.
3. Teste
Realizamos um trabalho considerável na implementação do algoritmo Behavior-Guided Actor-Critic e agora é hora de ver os resultados do nosso trabalho. Como antes, o treinamento dos modelos foi realizado com base em dados históricos do instrumento EURUSD, no cronograma H1, no intervalo de tempo dos primeiros 5 meses de 2023. Todos os parâmetros dos indicadores são os padrões. O saldo inicial é de 10.000 USD.
Na primeira etapa, foi criado um conjunto de treinamento com 300 passagens aleatórias, o que resultou em mais de 750 mil conjuntos de dados individuais "Estado -> Ação -> Novo estado -> Recompensa". Quero enfatizar as palavras "passagens aleatórias". Nesta fase, não temos um modelo pré-treinado. A cada passagem no testador de estratégias, o EA "..\BAC\Research.mq5" gera um novo modelo e preenche-o com parâmetros aleatórios. Por isso, o desempenho desses modelos será tão aleatório quanto seus parâmetros. Nesta fase, não limitei o nível mínimo de rentabilidade da passagem para ser salvo no banco de exemplos.
Após a coleta de exemplos, realizamos o treinamento inicial do nosso modelo. Para isso, executamos o EA "..\BAC\Study.mq5" por 500.000 iterações de treinamento de modelos.
Devo dizer que após o treinamento inicial do modelo, a estocasticidade da política do Ator é bastante pronunciada. Isso se reflete na grande variação dos resultados de passagens individuais.
Na segunda etapa, executamos novamente o EA de coleta de dados no modo otimização do testador de estratégias por 300 iterações com uma pesquisa completa de parâmetros. Desta vez, limitamos o nível mínimo de rentabilidade a níveis positivos (0 ou um pouco acima). Como resultado, um número relativamente pequeno de resultados foi adicionado, apenas cerca de 15-20 passagens.
Observe que ao executar o EA de coleta de dados após o treinamento inicial, um único modelo pré-treinado é usado em todas as passagens. E toda a variação nos resultados é devida à estocasticidade da política do Ator.
Em seguida, repetimos o processo de treinamento do modelo por mais 500.000 iterações.
O processo de coleta de exemplos e treinamento do modelo é repetido várias vezes até que o resultado desejado seja alcançado ou até que um mínimo local seja atingido, quando uma iteração adicional de coleta de exemplos e treinamento do modelo não produzirá progresso nos resultados.
Vale ressaltar que, ao executar novamente o EA de coleta de exemplos, as passagens coletadas anteriormente não são excluídas. Novas passagens são adicionadas ao final do arquivo. No entanto, para evitar a acumulação de um banco de exemplos excessivamente grande, a constante MaxReplayBuffer foi adicionada ao arquivo "..\BAC\Trajectory.mqh". Esta constante define o número máximo de passagens (não o tamanho do arquivo). À medida que o buffer é preenchido, passagens mais antigas serão excluídas. Eu recomendo que você use esta constante para ajustar o tamanho do banco de exemplos de acordo com as capacidades técnicas do seu equipamento.
#define MaxReplayBuffer 500
Após aproximadamente 7 iterações de atualização da base de exemplos e treinamento do modelo, consegui obter um modelo capaz de gerar lucro no intervalo de treinamento. O gráfico apresentado claramente mostra uma tendência de aumento de capital. No entanto, existem algumas áreas de perda.


Durante os 5 meses do período de treinamento, o EA obteve um lucro de 16% com uma queda máxima de 8,41% no Patrimônio Líquido. Já no saldo, a queda foi um pouco menor, totalizando 6,68%. No total, foram realizadas 99 operações, sendo que 51,5% delas foram fechadas com lucro. O número de operações lucrativas é praticamente igual ao número de operações deficitárias. No entanto, o lucro médio por operação lucrativa é quase 50% maior do que o de operações deficitárias. O fator de lucro foi de 1,53 e o fator de recuperação ficou quase no mesmo nível.
No entanto, estamos treinando o modelo para uso futuro, não apenas no testador de estratégias. Assim, o teste do modelo em dados fora do conjunto de treinamento é mais importante para nós. Realizamos um teste com o mesmo modelo em dados históricos de junho de 2023. Todos os outros parâmetros de teste permaneceram inalterados.


É importante mencionar que os resultados do teste do modelo em novos dados são comparáveis aos resultados no conjunto de treinamento. Em 1 mês, o EA obteve um lucro um pouco acima de 3%, o que é bastante comparável aos 16% em 5 meses de treinamento. Foram realizadas 11 operações, um número inferior ao do conjunto de treinamento. Infelizmente, a proporção de operações lucrativas também foi menor em relação ao conjunto de treinamento, representando apenas 36,4%. No entanto, o lucro médio por operação lucrativa é quase 6 vezes maior do que o de operações deficitárias. Isso elevou o fator de lucro para 3,12.
Conclusão
Neste artigo, conhecemos mais um algoritmo de treinamento Behavior-Guided Actor-Critic. Assim como o método Soft Actor-Critic, ele pertence à grande família de algoritmos Ator-Crítico e é uma alternativa ao uso do método Soft Actor-Critic. As vantagens deste algoritmo incluem a capacidade de treinar modelos tanto estocásticos quanto determinísticos em um espaço de ação contínua. O uso deste método não impõe restrições à construção de modelos treináveis.
Na parte prática deste artigo, o algoritmo proposto foi implementado utilizando a linguagem MQL5. A eficácia de nossa implementação foi confirmada pelos resultados dos testes.
No entanto, é importante ressaltar que todos os programas apresentados aqui são apenas uma demonstração da tecnologia e não estão prontos para uso em mercados financeiros reais. Antes de usá-los, é necessário ajustar os EAs e realizar testes adicionais abrangentes.
Referências
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA de coleta de exemplos |
| 2 | Study.mq5 | Expert Advisor | EA de treinamento do agente |
| 3 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 5 | NeuroNet.mqh | Biblioteca de classe | Biblioteca das classes para criar uma rede neural |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca do código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/13024
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Obrigado, senhor @Dmitriy
//+------------------------------------------------------------------+
Olá a todos. Eu tenho esta versão, depois de cerca de 3-4 ciclos (coleta de banco de dados - treinamento - teste) começou a dar apenas uma linha reta nos testes. Os negócios não abrem. O treinamento fez todas as vezes 500.000 iterações. Outro ponto interessante - em um determinado momento, o erro de um dos críticos se tornou muito grande no início e, depois, gradualmente, os erros de ambos os críticos diminuíram para 0. E, por 2 a 3 ciclos, os erros de ambos os críticos estão em 0. E, nos testes, o Test.mqh apresenta uma linha reta e nenhuma transação. Nos passes do Research.mqh, há passes com lucro e negócios negativos. Também há passagens sem transações e com resultado zero. Houve apenas 5 passagens com um resultado positivo em um dos ciclos.
Em geral, isso é estranho. Tenho treinado estritamente de acordo com as instruções de Dmitry em todos os artigos e não consegui obter um resultado de nenhum artigo. Não entendo o que estou fazendo de errado....
Novo artigo Redes neurais de maneira fácil (Parte 51): ator-crítico comportamental (BAC) foi publicado:
Autor: Dmitriy Gizlyk
Baixei a pasta zipada, mas haviam muitas outras pastas dentro.
Se possível gostaria que explicasse como implantar e treinar.
Parabens pelo ótimo trabalho!
Agradeço e muito obrigado