Уже практически все современные персональные компьютеры умеют выполнять несколько задач одновременно – за счет наличия в процессоре нескольких ядер. Их число с каждым годом растет – 2, 3, 4, 6 ядер… Компания Intel недавно продемонстрировала работающий экспериментальный 80-ядерный процессор (да-да, это не опечатка - восемьдесят ядер, - жаль, в...
フィクションの時代、予測可能な時代とはどういう意味ですか?)
例えば、5から30までの期間を持つRSIや、1バーまたは50バーの増分値のログなど。
オーバーシュートで多重共線性をフォローすることが重要で、モデルが失速しないように、時々、強く相関し始めるからです
新しいデータで価格が下がり始めたらどうする?モデルは上昇すると予想しています。そんな時、私の使っているモデルは、少し鈍くなり始め、オーバーシュートして長い間トレードに居座るようになります。
まあ、人間も同じで、トレンドの時期が横ばいや逆トレンドに代わると、浅い引けであることを期待して見送ろうとするものです。
トレンドは終わるより続く可能性が高い」という言葉に出会ったことがありますが、一方で、無限に続くわけでもありません。
だからモデルは人並み)
どうやら、全体的なトレンドが変わったときには、新しいデータを蓄積し、再トレーニングをする必要があるようです。
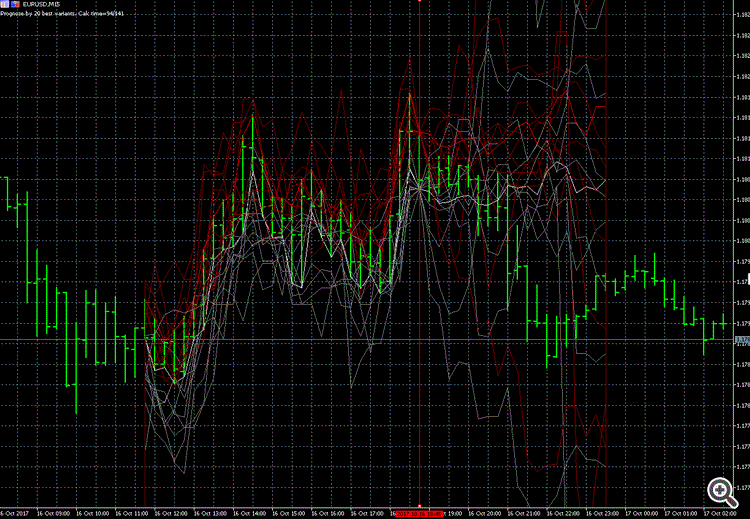
NSは、市場に典型的な状況がほとんどないため、教えることが全くない印象です。 大金を手にした特別に訓練されたロボットが、わざとパターンを破っているかです。
私のパターン・ファインダーは、典型的なダブル・トップを検出することができなかった。なぜなら、過去1年間、最も類似した20のケースで、価格はダブル・トップのパターンをやり過ごし、さらに上に飛んでいったからである。
予測は、赤(高)と白(低)の太線、履歴からのグレーと暗赤色のバリエーションで表現されています。
そして、最も似ているバリエーションは、それほど似ていない。
また、ある方向に予測すると、価格が反対方向に行くこともあります。
つまり、コインと同じように50/50なのです。
予測因子である指標の期間
指標は、市場が指標の周期にランダムに同期する場合、そして-なんとストキャスティクスがフラットで機能する場合、5%のケースでしか機能しないことをご存知でしょうか!:) ・・・そして、すべてのフラットで)
ダイナミックに変化するシステムを、固定期間のある指標で見てはいけないと思うのですが、いかがでしょうか?
私も同じことをしました))ちなみに、ある条件下では、相場は予想より後ろに行きやすいそうです。近接度は相関関係で測るのか?
近さは何によって測るのですか?
ただ、私が探していたパターンと、そのパターンに長い歴史の中の他のすべてのチャンクの各バー上の違いを合計しました。
一般的には、記事 https://www.mql5.com/ru/articles/197 のコードを確定させました。
インジケータが機能するのは5%のケースで、市場がインジケータの周期にランダムに同期して、ストキャスティクスがフラットに機能するときだけだとわかっているのでしょうか!:) ・・・そして、すべてのフラットで)
ダイナミックに変化するシステムを、固定期間のある指標で見てはいけないと思うのですが、いかがでしょうか?
まあ、いろいろな指標がありますし、期間もまちまちですからね。私はすでに、正常値(これも期間付き)に従って予測する固定期間付きの指標を持つシステムを持っています。
私も同じことをしました))ちなみに、ある条件下では、相場は予想より後ろに行きやすいそうです。近接度は相関関係で測るのか?
予後に差がないのであれば、単純な結果でより複雑なものに何倍もの時間をかける必要はないのでは?
予想が50%前後なら、MOに無駄な時間を費やす意味があるのか、と。マシュカについても、同じことが起きると思います。
予測に差がないのであれば、単純な結果でより複雑なことに何倍もの時間を費やす必要はないのでは?
わからない、哲学的な質問だ)
個人的には、レッカー車に信頼を置いていない。
p.s. そして、あなたの小物については、あなたはよく見て、それで予測を立てることができますが、市場のメカニズムを理解していないと、どこを、どの角度から見ればいいのかがわかりません。わからない、哲学的な質問だ)
個人的には、レッカー車は全く信用していない。
p.s. そして、手芸については、やはり好きな人は好きでしょうし、予想もできますが、どこをどの角度から見ればいいのか、市場の仕組みを理解する必要がありますね。数えるのにやたらと時間がかかる。1小節あたり0.1~0.5秒(テンプレートの長さにより異なります。)24時間前から最適化 してるのに、1400しか通らない。どうやら1週間はかかるようだ(
そして、最初の結果はあまりよくない。2ヶ月で50%、ドローダウンは30%である。
もう1つ改善策を考えているのですが、失敗したらマッシュキャッツに戻るかもしれません。
NSの回帰 問題を解いたことのある方に質問です。
学習値として何を与えるか(そして、何を予測するか)?
バリエーションがあります。
1) 次のバーの価格を増分して1回出力(1バーの価格の増分は通常重要ではないので、私には面白くないと思われる)
2) 10本から20本のバーを価格刻みで出力(リソースと時間がかかると思われるが、精度は高くなる。)
3) ジグザグに沿った極値(例えば、15本後にジグザグに沿った極値があり、その価格を与える)の増分価格を1回出力する。
どのオプションが良いと思いますか?もっといいものがあるのでは?
数本先(p.2、3)の予測であれば、そのパフォーマンスの確率は明らかに下がる。何番目が最適でしょうか?