トレーディングにおける機械学習:理論、モデル、実践、アルゴトレーディング - ページ 3091 1...308430853086308730883089309030913092309330943095309630973098...3399 新しいコメント Maxim Dmitrievsky 2023.06.03 08:15 #30901 mytarmailS 2023.06.03 08:51 #30902 Forester #:ここまで8ページ。そして、これはまだ入門編である)) クロス・バリデーションによるシャープ(ただし、他の指標を使ってもいいと書いてある)による比較になるようだ。 私の理解では、4つのパラメータを最適化する必要があります。 summary(my_pbo) Performance function Omega with threshold 1 p_bo slope ar^2 p_loss 0.3714286 1.6891000 -0.0140000 0.3430000 p_bo ( バックテストにおけるオーバートレーニングの確率)は0に近づける。 slope ( 線形回帰の勾配係数) は 1 に近いことが望ましく、これはトレーニング・サブセットとテスト・サブセットのパフォーマンス指標値の間に強い線形関係があることを示します。 ar^2 ( 修正済み決定係数) は,1に近いことが望ましく,これは線形回帰の精度がよいことを示す. p_loss ( テスト・サブセットのパフォーマンス・メトリック値のうち、あるしきい値以下の値の割合) は、0に近いはずで、テスト・サブセットのパフォーマンス・メトリック値の大部分が、あるしきい値以上であることを示す。 ただし、これらの値は、選択されたパフォーマンス指標と閾値に依存する可能性があることに注意する必要がある。 多基準パレート前後多基準最適化の必要性 Forester 2023.06.03 08:54 #30903 mytarmailS #:私の理解では、最適化には4つのパラメータがある。 p_bo ( バックテストでのオーバートレーニングの確率)は、オーバートレーニングのリスクが低いことを示す0に近づける。 slope ( 線形回帰の勾配係数) は 1 に近いことが望ましく、これはトレーニング・サブセットとテスト・サブセットのパフォーマンス指標値の間に強い線形関係があることを示します。 ar^2 ( 修正済み決定係数) が1に近いことは,線形回帰の精度がよいことを示す. p_loss ( テスト・サブセットのパフォーマンス・メトリック値のうち、ある閾値を下回る値の割合) は、0に近いはずで、テスト・サブセットのパフォーマンス・メトリック値の大部分が、ある閾値を上回っていることを示す。 ただし、これらの値は、選択されたパフォーマンス指標と閾値に依存する可能性があることに注意する必要があります。 オーバーフィットの統計セクション 2 で紹介したフレームワークにより、ストラテジーのバックテス トの信頼性 bility を4 つの補完的な分析で特徴付けることが できる: 1. バックテストのオーバーフィットの確率 (PBO): 2. パフォーマンスの低下:これは、より大きなパーフォーマンスISが、どの程度低いパフォーマンスOOSにつながるかを決定するもので、Baileyら[1]で議論されたメモリ効果に関連する。[ 3. 損失の確率:最適として選択されたモデルISがOOSに損失を もたらす確率。 4. 確率的優位性: この分析では、戦略ISを選択するために使用される手順 dureが、 N個の の選択肢の中から1つのモデル構成をランダムに選択するよりも望ましいかどうかを判断する。 以下、各項目について詳しく説明する。 mytarmailS 2023.06.03 09:06 #30904 Forester #:これらのパラメーターが何なのか理解するには短すぎる。以下は、記事13ページからの詳細である(パッケージが記事のメソッドを完全に再現している場合だが、もしかしたら他の何かが追加/削除されているかもしれない)。 このパッケージはひどすぎる。こんなパータクはここ数年見たことがない。 コードはひどい ドキュメントはほとんど役に立たない どうやってCRANに入ったのか理解できない。 いまだに理解できないのだが、調査された取引システムはバッチに分けられているのか、それとも(このライブラリには)複数のTSがあるのか? Forester 2023.06.03 09:22 #30905 mytarmailS #:私はまだ理解できないが、1つの取引システムがバッチに分割されて研究されているのか、それとも(このライブラリでは)複数のTSなのか。異なるパラメータ/ハイパーパラメータで得られたモデル群の中から最適なモデルを選択する。入力は行列で、各列はモデルの1つの予測である。 違うかもしれない。私もまだ理解していない。 mytarmailS 2023.06.03 09:31 #30906 Forester #:異なるパラメータ/ハイパーパラメータで得られたモデル集合の中から最良のモデルを選択する。入力は行列で、各列はモデルの1つの予測値である。 これはもうわかった。 結果の扱い方がわからない 私は1つの列(1つのTS)を与える 結果 summary(my_pbo) Performance function Omega with threshold 1 p_bo slope ar^2 p_loss 0.0000 2.2673 0.9700 0.3710 私は5列(5つのTC)をフィード 私はまた、1行を取得します。 summary(my_pbo) Performance function Omega with threshold 1 p_bo slope ar^2 p_loss 0.3428571 1.9081000 0.0440000 0.2860000 5つの行があるはずだし、もしそれがベストのTSの結果なら、ベストのTSのmndexがあるはずなのだが...。 この作者を殺してやりたい mytarmailS 2023.06.03 09:51 #30907 Forester #:異なるパラメータ/ハイパーパラメータで 得られたモデル集合の中から最良のモデルを選択する。入力は行列で、各列はモデルの1つの予測です。 あるいは違うかもしれない。私もまだ理解していない これは、異なる市場セクション (パラメータ/ハイパーパラメータ)からTS利益リターンを取ると解釈することができますか? 異なる市場セクション == パラメータ/ハイパーパラメータ ? Forester 2023.06.03 10:05 #30908 mytarmailS #:それは、市場のさまざまな部分 (パラメータ/ハイパーパラメータ)からTC利益のリターンを取っていると解釈できる。 正確には利益リターン。 mytarmailS#: 市場の 異なる部分== パラメータ/ハイパーパラメータ ? 私は正確に設定を理解したように:MA、SLなどの異なる期間。 Forester 2023.06.03 10:08 #30909 mytarmailS #:ももにもにも5行か、ベストのTCならベストのmndexがあるはずだが...。 その結果、モデル(そしておそらく予測データとターゲット・データ)の全体的な評価が得られます 悪いモデルは、このような結果を与えます(0以上のOOS結果の17%のみ)。 良いモデル - 0以上のOOS結果の95 mytarmailS 2023.06.03 10:09 #30910 Forester #:到着したのは帰国子女だ。 利益と損失があるでしょ? だから、ポジションが空いたときに各州の帰国者を取るんだ。 フォレスター私の理解では、MA、SLなどの異なる期間という設定です。 TSの設定が違うのではなく、異なる領域での取引を取るだけです。 1...308430853086308730883089309030913092309330943095309630973098...3399 新しいコメント 取引の機会を逃しています。 無料取引アプリ 8千を超えるシグナルをコピー 金融ニュースで金融マーケットを探索 新規登録 ログイン スペースを含まないラテン文字 このメールにパスワードが送信されます エラーが発生しました Googleでログイン WebサイトポリシーおよびMQL5.COM利用規約に同意します。 新規登録 MQL5.com WebサイトへのログインにCookieの使用を許可します。 ログインするには、ブラウザで必要な設定を有効にしてください。 ログイン/パスワードをお忘れですか? Googleでログイン
ここまで8ページ。そして、これはまだ入門編である))
クロス・バリデーションによるシャープ(ただし、他の指標を使ってもいいと書いてある)による比較になるようだ。
私の理解では、4つのパラメータを最適化する必要があります。
ただし、これらの値は、選択されたパフォーマンス指標と閾値に依存する可能性があることに注意する必要がある。
多基準パレート前後多基準最適化の必要性
私の理解では、最適化には4つのパラメータがある。
ただし、これらの値は、選択されたパフォーマンス指標と閾値に依存する可能性があることに注意する必要があります。
オーバーフィットの統計
セクション 2 で紹介したフレームワークにより、ストラテジーのバックテス トの信頼性
bility を4 つの補完的な分析で特徴付けることが できる:
1. バックテストのオーバーフィットの確率 (PBO):
2. パフォーマンスの低下:これは、より大きなパー
フォーマンスISが、どの程度低いパフォーマンスOOSにつながるかを決定するもので、Baileyら[1]で議論されたメモリ効果に関連する
。[
3. 損失の確率:最適として選択されたモデル
ISがOOSに損失を もたらす確率。
4. 確率的優位性: この分析では、戦略ISを選択するために使用される手順
dureが、 N個の の選択肢の中から1つのモデル構成をランダムに選択
するよりも望ましいかどうかを判断する。
以下、各項目について詳しく説明する。
これらのパラメーターが何なのか理解するには短すぎる。以下は、記事13ページからの詳細である(パッケージが記事のメソッドを完全に再現している場合だが、もしかしたら他の何かが追加/削除されているかもしれない)。
このパッケージはひどすぎる。こんなパータクはここ数年見たことがない。
コードはひどい
ドキュメントはほとんど役に立たない
どうやってCRANに入ったのか理解できない。
いまだに理解できないのだが、調査された取引システムはバッチに分けられているのか、それとも(このライブラリには)複数のTSがあるのか?
私はまだ理解できないが、1つの取引システムがバッチに分割されて研究されているのか、それとも(このライブラリでは)複数のTSなのか。
異なるパラメータ/ハイパーパラメータで得られたモデル群の中から最適なモデルを選択する。入力は行列で、各列はモデルの1つの予測である。
違うかもしれない。私もまだ理解していない。異なるパラメータ/ハイパーパラメータで得られたモデル集合の中から最良のモデルを選択する。入力は行列で、各列はモデルの1つの予測値である。
これはもうわかった。
結果の扱い方がわからない
私は1つの列(1つのTS)を与える
結果
私は5列(5つのTC)をフィード
私はまた、1行を取得します。
5つの行があるはずだし、もしそれがベストのTSの結果なら、ベストのTSのmndexがあるはずなのだが...。
この作者を殺してやりたい
異なるパラメータ/ハイパーパラメータで 得られたモデル集合の中から最良のモデルを選択する。入力は行列で、各列はモデルの1つの予測です。
あるいは違うかもしれない。私もまだ理解していないこれは、異なる市場セクション (パラメータ/ハイパーパラメータ)からTS利益リターンを取ると解釈することができますか?
異なる市場セクション == パラメータ/ハイパーパラメータ ?
それは、市場のさまざまな部分 (パラメータ/ハイパーパラメータ)からTC利益のリターンを取っていると解釈できる。
正確には利益リターン。
市場の 異なる部分== パラメータ/ハイパーパラメータ ?
私は正確に設定を理解したように:MA、SLなどの異なる期間。
ももにもにも
5行か、ベストのTCならベストのmndexがあるはずだが...。
その結果、モデル(そしておそらく予測データとターゲット・データ)の全体的な評価が得られます
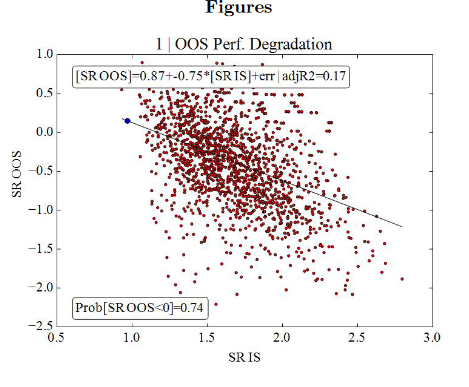
悪いモデルは、このような結果を与えます(0以上のOOS結果の17%のみ)。
良いモデル - 0以上のOOS結果の95
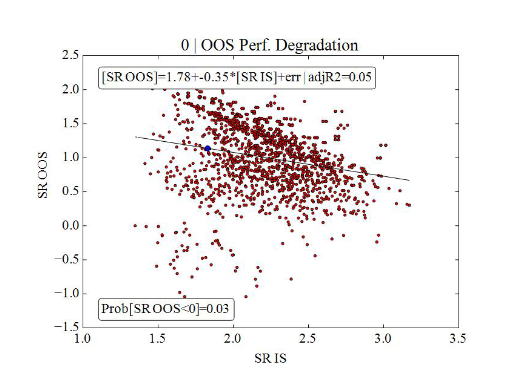
到着したのは帰国子女だ。
利益と損失があるでしょ?
だから、ポジションが空いたときに各州の帰国者を取るんだ。
私の理解では、MA、SLなどの異なる期間という設定です。
TSの設定が違うのではなく、異なる領域での取引を取るだけです。