implements the Hidden Markov Models (HMMs). The HMM is a generative probabilistic model, in which a sequence of observable variables is generated by a sequence of internal hidden states . The hidden states are not observed directly. The transitions between hidden states are assumed to have the form of a (first-order) Markov chain. They can be...
もし、HMMを理解している人がいたら、問題を解決するのを助けてください。もし、問題が解決できるのであれば、私はその粒を共有します)
https://ru.stackoverflow.com/questions/984699/%D0%A1%D0%BA%D1%80%D1%8B%D1%82%D0%B0%D1%8F-%D0%9C%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F-%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C-hmm-%D0%BF%D0%BE%D1%87%D0%B5%D0%BC%D1%83-%D0%BE%D1%82%D0%BB%D0%B8%D1%87%D0%B0%D1%8E%D1%82%D1%81%D1%8F-%D0%BF%D1%80%D0%BE%D0%B3%D0%BD%D0%BE%D0%B7%D1%8B-%D1%81%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B9
もし、HMMを理解している人がいたら、問題を解決するのを助けてください。もし、問題が解決できるのであれば、私はその粒を共有します)
https://ru.stackoverflow.com/questions/984699/%D0%A1%D0%BA%D1%80%D1%8B%D1%82%D0%B0%D1%8F-%D0%9C%D0%B0%D1%80%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F-%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C-hmm-%D0%BF%D0%BE%D1%87%D0%B5%D0%BC%D1%83-%D0%BE%D1%82%D0%BB%D0%B8%D1%87%D0%B0%D1%8E%D1%82%D1%81%D1%8F-%D0%BF%D1%80%D0%BE%D0%B3%D0%BD%D0%BE%D0%B7%D1%8B-%D1%81%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B9
さて、状態はマルコフですが、モデルは何でしょう?
ということは、少なくとも二乗窓にはより多くのポイントが必要ということです。
また、ランダムな系列を与えた場合、5050以外の予測はどのように語られるのでしょうか?ということは、少なくとも二乗窓の点数はもっと必要ということです。
数千ポイントも取ったというのに
、 ランダムな系列が入力された場合、50/50以外の予測はどのように語られるのでしょうか。
データも同じ、モデルも同じ、何が違うの?
パッケージの全関数を使用して新しいデータを 予測したところ、(ネット上のすべての例と同じように...)結果は素晴らしいものでした。
同じモデルを使って、同じデータを 予測するのですが、スライディングウィンドウを使った場合、結果は受け入れがたいものになります。
それが問題なのです。数千のドット絵も撮ったと言ったが
データもモデルも同じです。
パッケージ内の全関数を使用して新しいデータを 予測すると、(ウェブ上のすべての例のように...)結果は素晴らしいものでした。
同じデータを 同じモデルで 予測しても、スライディングウィンドウを使用すると結果が異なる、受け入れられない。
それが本当の問題なのです。どのようなモデルで、どこから状態を得ているのかわからない。パッケージがなければ、意味がない。
もしかしたら、ランダムな状態を出さないgcfがあるから、1件目で予測されるのかもしれません。trainとtestの両方でseedを変えてみて、1番目のケースでは何も予測できないことを確認する、それ以外の場合はどうしたらいいのかわからない、アイデアが明確ではない
分類の確率に応じて分割を行う。正確には、確率ではなく、分類誤差によるものです。なぜなら、訓練ですべてが判明しているので、確率ではなく、正確な推定値がわかるからです。
分離の仕方、つまり不純物の測り方(左サンプリング、右サンプリング)が違いますが。
私が言いたかったのは、サンプルに対する分類精度の分布であって、今のような合計ではありません。
というのは、モデルが何なのか、どこから状態を取得するのかが明確でないのです。パッケージがなければ、コンセプト的にどうなのか?
もしかしたら、ランダム性を出さないgcpがあるから、1件目で予測されるのかもしれませんね。trainとtestの両方でseedを変えてみて、最初のケースでも予測不可能かどうか、そうでなければ、どうしたらこのアイデアの助けになるのかわかりません。
このファイルには、価格と、予測変数 "data1 "と "data2 "を持つ2つの列があります。
この2つの列("data1 "と "data2")に対して、Pythonでも何でも好きな方法で、(教師のいないデータトラックで) 2つの状態だけでHMMを訓練する。 価格には全く触れず、可視化のために行うだけだ
そして、ビタビアルゴリズムで、(データテストを) 思いつくわけです。
2つの状態を取得すると、次のようになります。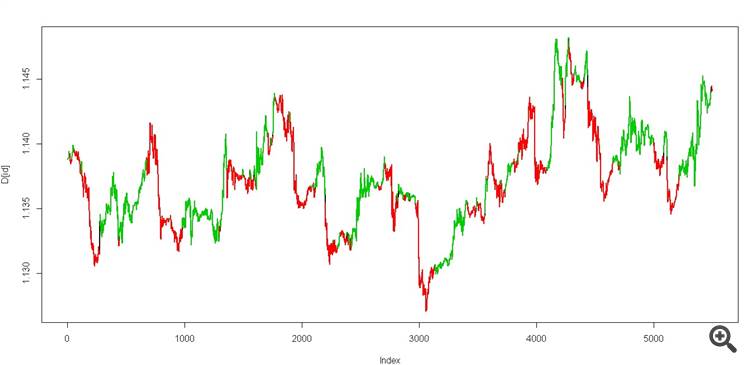
まさに聖杯です))
そして、同じデータを使ってスライディングウィンドウで同じビタビを計算してみてください
ここに、価格と予測変数 "data1 "と "data2 "の2つの列があるファイルがあります。
この2つの列("data1 "と "data2")を使って、Pythonでも何でも好きな方法で、(データトラック上の)2つの状態だけでHMMを学習します。 価格には全く触れず、可視化するためだけに使用するのです。
そして、ビタビアルゴリズムを取り、(データテスト)。
2つの状態を取得すると、次のようになります。
まさに穀潰しです(笑)。
そして、同じデータに対してスライディングウィンドウで同じビタビ計算を試してみてください
センク、後で見ますね、マルコフでやってるので、お知らせします。
senkさん、私もマルコフを扱っているので、後で調べてお知らせします。
幸か不幸か
幸か不幸か
今日は休みなのでまだ見ていません。
今までのパックを見ているとhttps://hmmlearn.readthedocs.io/en/latest/tutorial.html に合うと思います。