import catboost
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from catboost import CatBoostRegressor
x = [[1,2],[2,2],[3,2],[4,2],[5,2],[6,2],[7,2],[8,2],[9,2]]
y = [2,4,6,8,10,12,14,16,18]
print('-------- 1 DecisionTree')
tree = DecisionTreeRegressor().fit(x,y)
for ix in x: print(' {:2.2f}*{:2.2f}={:2.2f} '.format(ix[0],ix[1],tree.predict([ix])[0]))
print('-------- RandomForest 10 Tree')
regr = RandomForestRegressor(n_estimators=10).fit(x,y)
for ix in x: print(' {:2.2f}*{:2.2f}={:2.2f} '.format(ix[0],ix[1],regr.predict([ix])[0]))
print('-------- CatBoost 10 Tree')
cat = CatBoostRegressor(iterations=10, verbose=False).fit(x,y)
for ix in x: print(' {:2.2f}*{:2.2f}={:2.2f} '.format(ix[0],ix[1],cat.predict([ix])[0]))
Ivan Negreshniy さん、よくわからないのですが、CatBoostでモデルを作成しましたが、どのように接続するのでしょうか?EAからpythonへのブリッジ/チャンネルで、予測値が渡され、反対方向に計算結果が受け取られる、具象クラスなのでしょうか。
私が理解する限り、CatBoostは、私は理解していないモデルのコードをアンロードすることができますが、それは何とかMQLに統合することができますし、パイソンを使用しない限り、私は、プロの推定のためにそれを囲むのだろうその後?また、CatBoostはC++でライブラリを持っていますが、MQLで動作させることができず、pythonとコンソールコマンドを使用しないのでしょうか?
ここではっきりしないのは、Expert Advisorから直接データやモデルを作成、設定、トレーニングなどの作業をエンドツーエンドで自動化するためにブリッジが必要であること。そしてCatBoostがファイルにダンプするのは特定のモデルのシリアライズで、計算のためだけに使用できる。
もちろん、これらのファイルを元にエディタでEAを作成することもできますが、硬直したロジックの通常のEAと大差ないものになりますし、これが目的なら、私が提案したテンプレートを使ったトレーニングで達成する方がはるかに簡単だとIMHOは考えています。https://www.mql5.com/ru/forum/270216。
そこにあるものはすべて自動的に学習・生成され、各ツリーのコードは独立した論理的な関数に変換されるため、完成すれば、後で比較することができるかもしれません。
そもそも私にとって労働集約型。
予測因子の多くは指標を束ね、ATR日足に当てはめて いる。残りの時系列作業は、特性予測因子です。
2つの質問があります。
1)インジケーターの束とATR日記へのはめ込み、とはどういうことか説明してください。
2)なぜキャットバストなのか?本当に他のブーストより優れているのでしょうか?
ここではっきりしないのは、作成、設定、トレーニングなど、EAから直接データやモデルを扱うエンドツーエンドの自動化のためにブリッジが必要であることです。
なるほど、つまりMoDライブラリと連携するための独自のインターフェイスを作る機能がメインなんですね。これは、今、同じインターフェイスでも、exeファイルを起動して、そこにコマンドを送り込むという方法を考えていることに相当します。一般的には、そうですね、pythonでやると面白いのですが、残念ながら私にはそのような知識はありません。
で、CatBoostがファイルにダンプするのは、特定のモデルのシリアライズで、これは計算にしか使えません。
もちろん、これらのファイルを元にエディタでEAを作成することもできますが、硬直したロジックの通常のEAと大差ないものになりますし、それが目的であれば、IMHOとしては、私が提案したテンプレートを使ったトレーニングで達成する方がはるかに簡単です。https://www.mql5.com/ru/forum/270216。
もしあなたがこのコードを理解しているならば、例えば私がRからモデルを処理した後に葉のために行うように、各ルールに完成した説明を与えることによって、それを読みやすい形に変換する方法を教えてくれるかもしれません。
このコードの暗号化アルゴリズムが理解できないのですが、その説明やインタプリタを(たぶん有料で)作っていただけないでしょうか?
そして、それが目的なら、IMHOは、私が提案したパターン学習で達成する方がはるかに簡単です。https://www.mql5.com/ru/forum/270216。
このように、すべてが自動的に学習・生成され、各ツリーのコードが別々の論理関数に変換されるため、分析が容易になり、実行速度も速くなります。
単にモデルを得るだけでなく、葉っぱを得て、それを評価し、その葉っぱを元に新しいモデルを生成することが目的です。
そのトピックを読んでいて、よくわからないのですが、自動ネット構築のプロセスは、裸の指標とマークアップをベースに作成し、その情報をテンプレートに転送し、一方で私は指標の後処理があり、さらに私の指標の一部を利用しているので、その方法が使えないことがわかり、また~そこから葉を得ることができない...と。
2つの質問があります。
1)指標を束ねてATR日足に 合わせる意味を教えてください。
2)なぜキャットバストなのか?他のブーストと比較して本当に良いのか? や足場
1.これは市場の私の見解である、すなわち価格は、一日の初めにATRによって定義されている動きのための計画を持って、その後障害物(抵抗のレベル(市場参加者による取引決定を行う/改訂のレベル)は、指標を含む)に応じて、この計画は実装されているかどうかです。予測因子とは、このような移動計画に関する障害を表すものです。つまり、ATRの範囲に沿ったグリッドと、その中にある様々な指標をグラフ化すると、このようになります。
MetaTrader プラットフォームのスクリーンショット
Si-9.18、M1、2018.08.30
JSC ''Otkritie Broker'、MetaTrader 5、Real
メモリ用
2.CatBoost - セットアップを手伝ってもらったところです。さらに、Rでモデルを作成する私の以前のアプローチよりも明らかに速く動作し、同時に効率的で、ドキュメントがあり、DOSを介したコマンドもあります :) 。他のツール、例えばDeductor Studioと比較すると、より安定しており、モデルもより良く出てきています。
あなたは興味があるかもしれない、私は遭遇した
私は木の最適化に関するシステムを構築したいのですが、より正確にはオプティマイザーを使って木を構築することです。)
https://explained.ai/
お気遣いありがとうございます
言葉の壁で読むのが堪えるし、翻訳者は文章を馬鹿にしたり笑ったり...。哀れ
Google Translator plugin for chrome を使って、1語ずつ翻訳します。
私はクロームのImTranslator プラグインを使用して、それはあなたが一度に段落を翻訳するときに、単語を選択し、コンテキストメニューで右クリックすると正常に動作して います
ググらずにクリック
どのようなプラグインなのでしょうか?以前はChromeで使えていたのに、使えなくなり、設定方法がわからない。
なるほど、つまり、MoDライブラリーを扱うための独自のインターフェイスを作るきっかけになるわけですね。これは、今、同じインターフェイスを作ろうと思っているのですが、exeファイルを起動し、そこにコマンドを入力することで、同じインターフェイスを作ることができることに相当します。一般的には、そうですね、pythonでやると面白いのですが、残念ながら私にはそのような知識はありません。
このコードを理解した場合、例えば、Rからモデルを処理した後に葉のために行うように、各ルールに完成した説明を与えるなどして、読みやすい形に変換する方法を教えてもらえますか?
このコードの暗号化アルゴリズムがどうしても理解できないのですが、その説明・解釈を(場合によっては有償で)作ってもらえませんか?
単にモデルを得るだけでなく、葉を得、それを評価し、その葉をもとに新しいモデルを生成することが目的です。
そのテーマを読んでもよくわからないのですが、自動ネット構築のプロセスは、裸のインジケータとマークアップをベースにあなたが作成し、情報はテンプレートで転送され、私の場合はインジケータの後処理があり、さらに私は表示したくないいくつかの指標を使用しているので、そのメソッドが使用できないことが判明し、再び - あなたはそれから葉を得ることができない...。
私はなぜ手動編集の分割とツリーを決定する葉を必要とするかもしれない理解していない、はい、私はすべての分岐が自動的に論理演算子に変換されているが、正直なところ、私自身が今まで修正したことを覚えていない。
そして一般的にはCatBoostの コードを掘る価値があるのですが、どうすれば確実にわかるのでしょうか。
例えば、私は上記のように乗算表で学習するニューラルネットワークをpythonでテストし、それを木や森(DecisionTree, RandomForest, CatBoost)のテストに使っています。
明らかにCatBoostに有利な結果ではありません。)
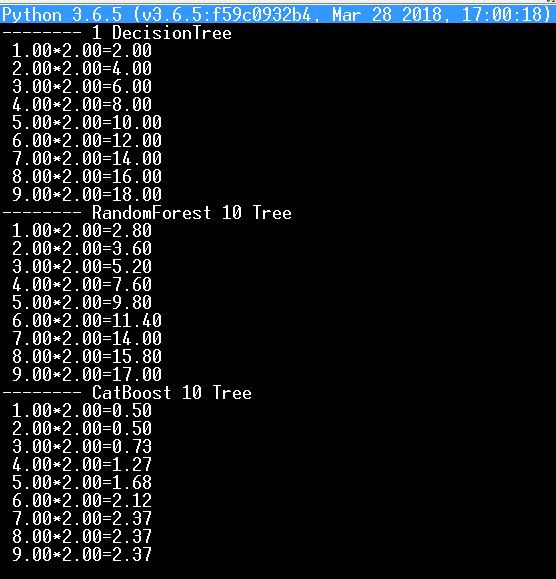
確かに、何千本も撮れば結果は良くなりますね。決定木の分岐や葉を手動で編集する必要があるのか理解できません。確かにすべての分岐を自動的に論理演算子に変換していますが、正直なところ、自分で修正した覚えはありません。
そして一般的にはCatBoostのコードを掘る価値があるのですが、どうすれば確実にわかるのでしょうか。
例えば、私は上記のように乗算表で学習するニューラルネットワークをpythonでテストし、それを木や森(DecisionTree, RandomForest, CatBoost)のテストに使用しました。
明らかにCatBoostに有利な結果ではありません。)
森やブーストが乗算表に対応してないなんてありえないでしょ
まさか、森やブーストがマルチテーブルを扱えないなんてことはないだろう。