
トレーダーの為の正規表現

概論
正規表現(英語ではregular expressions)とは、指定されたモデルでテキストを処理する為の言語である特別なツールです。このモデルまたはパターンは、正規表現のテンプレートまたはマスクといった他の名前を持っています。正規表現の構文として多くのメタキャラクタやルールが定義されました。
正規表現は、2つの基本的なタスクを実行することができます。
- 文字列内のパターンの検索。
- 見つけたパターンの置換。
正規表現の為のパターン作成時には、すでに記述したように、特別な文字やメタキャラクタ、そして文字クラス(セット)が使用されます。これはつまり、正規表現は共通列であり、その中の全ての非特殊(非予約)文字は通常のものとみなされます。
文字列内の指定されたパターンの具体的な検索は、正規表現の処理器で行われます。.NET Frameworkや、ライブラリ内のMQL5用RegularExpressionsでは、正規表現の処理器は正規表現の為の返しを使用した検索を実行します。これは、従来のNFAエンジンのバリエーションで(非決定性有限オートマトン)、PerlやPython、Emacs、Tclで使用されるものと同様のものです。文字列内で発見した一致の置換を実行するものです。
1. 正規表現の基礎
メタキャラクタとは、コマンドを指定し、MQL5やC#のエスケープシーケンスで動作する特別な文字です。このような文字は逆スラッシュで先行し、これらの一つ一つが特別な役割を持っています。
下の表では、MQL5とC#の正規表現のメタキャラクタを、それぞれが持つ役割ごとにグループ化しました。
1.1. 文字クラス:
| 文字 | 意味 | 例 | 一致 |
|---|---|---|---|
| [...] | 括弧内で指定した文字のうちのいずれか | [a-z] | 元の文字列では、任意の英語のアルファベットの小文字 となります |
| [^...] | 括弧内で指定していない文字のうちのいずれか | [^0-9] | 元の文字列では、数字以外の任意の文字となります |
| . | 改行または別のUnicode文字列の区切りを除く任意の文字 | ta.d | "trade"の文字列の"trad" |
| \w | スペースやタブなどではない任意のテキスト文字 | \w | "MQL 5"列内の"M"、"Q"、"L"、"5" |
| \W | テキスト文字ではない任意の文字 | \W | "MQL 5."の文字列の中の" "、"." |
| \s | Unicodeセットの任意の空白文字 | \w\s | "MQL 5"文字列の中の"L " |
| \S | Unicodeセットの任意の非空白文字\wと\Sの文字は、 同一ではないことにご注意ください。 | \S | "MQL 5."の文字列の中の"M"、"Q"、"L"、"5"、 "." |
| \d | 任意のASCII数値[0-9]と同等 | \d | "MQL 5."の中の"5" |
1.2. 量指定子:
| 文字 | 意味 | 例 | 一致 |
|---|---|---|---|
| {n,m} | n回以上m回以下繰り返す前のパターンとの一致 | s{2,4} | "Press"、"ssl"、"progressss" |
| {n,} | n回以上繰り返す前のパターンとの一致 | s{1,} | "ssl" |
| {n} | 前のパターンにちょうどn回一致 | s{2} | "Press"、"ssl"、しかし"progressss"ではない |
| ? | 前のパターンに0回または1回一致 前のパターンは必須ではない | {0,1}と同等 | |
| + | 前のパターンに1回以上一致 | {1,}と同等 | |
| * | 前のパターンと0回以上一致 | {0,}と同等 |
1.3. 正規表現文字の選択子:
| 文字 | 意味 | 例 | 一致 |
|---|---|---|---|
| | | 左からもしくは右からの部分の一致(論理演算『または』のアナログ) | 1(1|2)0 | 文字列の中の"110"、"120" "100、110、120、130" |
| (...) | グループ化*、+、?、|などの文字を使用することができる1つのユニットに要素をグループ化させます。 次の参照で使用する為にこのグループに一致する文字を記憶します。 | ||
| (?:...) | グループ化のみ。単一のユニットに要素をグループ化しますが、このグループに一致する文字を記憶しません。 |
1.4. 正規表現のアンカー文字:
| 文字 | 意味 | 例 | 一致 |
|---|---|---|---|
| ^ | 複数行検索時の文字列の先頭または文字列表現の先頭と一致 | ^Hello | "Hello, world"だが"Ok, Hello world"ではない。つまり、この文字列では単語 "Hello"は先頭にない |
| $ | 複数行検索時の文字列の末尾または文字列表現の末尾と一致 | Hello$ | "World, Hello" |
| \b | 語の区切りと一致、つまり\wと\Wの文字の間 または\wと文字列の先頭または末尾の間の位置と一致 | \b(my)\b | 文字列"Hello my world"では"my"という語を選びます |
より詳細な正規表現要素については、Microsoftの公式サイトで参照することができます。
2. MQL5の為の正規表現実装の特徴
2.1. Internalフォルダに格納される第三者ファイル
.Netのソースコードに最大限に近づけた MQL5の為のRegularExpressionsの実装には、第三者ファイルの一部を転送する必要がありました。これらの全てはInternalフォルダに格納され、同じように興味深いものです。
Internalフォルダの内容を注意深く見ていきましょう。
- Generic — このフォルダにある厳密に型指定されたコレクション、列挙子やその為のインターフェイスの実装の為のファイルです。より詳細な説明は以下に記述されています。
- TimeSpan — 時間間隔を表すTimeSpan構造体の実装の為のファイルです。
- Array.mqh — このファイルではArrayクラスが実装されており、このクラスの為に配列を使用した静的メソッドの一連を持っています。例:ソート、バイナリ検索、列挙子の取得、要素インデックスの取得など。
- DynamicMatrix.mqh — このファイルには、多次元動的配列実装の為の2つの主要クラスがあります。これらのクラスはパターンであり、標準タイプやクラスポインタの為に適しています。
- IComparable.mqh — 型指定されたコレクションの一連のメソッドのサポートの為に必要不可欠なIComparableインターフェイスを実装するファイルです。
- Wrappers.mqh — 標準タイプの為のラップやそれらに基づくハッシュコードを見つけるメソッドです。
Generic で厳密に型指定された3つのコレクションが実装されています。
- List<T>は、インデックスで使用可能な厳密に型指定されたオブジェクトのリストです。リストの検索やソート実行、リストを使ったその他の操作の為のメソッドをサポートしています。
- Dictionary<TKey,TValue>は、キーと数値のコレクションです。
- LinkedList<T>は、二重リストです。
エキスパートアドバイザTradeHistoryParsingListのList<T>の使用を見てみましょう。このエキスパートアドバイザは、.htmlファイルから取引履歴を読み込み、それを選択した欄や記録によってフィルタリングします。取引履歴は、取引と注文の2つの表から構成されています。OrderRecord とDealRecordクラスは、それぞれ注文と取引の表から1つの記録(タプル)を解釈します。従って、それぞれの表を記録リストとして表示することができます。
List<OrderRecord*>*m_list1 = new List<OrderRecord*>(); List<DealRecord*>*m_list2 = new List<DealRecord*>();
List<T>クラスがソートメソッドをサポートしている為、Tタイプのオブジェクトはそれぞれ同等である必要があります。言い換えれば、この為に<、>、==の操作が実装されています。標準要素に何の問題も発生しないが、List<T>を作成しなければならない場合、Tの場所(カスタムクラスへのポインタ)にエラーが発生します。この問題は2つの方法で解決することができます。第一に、私達のクラスで明示的に比較演算子を再ロードすることができます。別の解決策としては、クラスをIComparableインターフェイスからの子にすることです。2つ目の方法は、実装は遥かに短いですが、ソートの正確さが欠けてしまいます。カスタムクラスの為にソートの実行が必要な場合、全ての比較演算子を再ロードする必要があり、加えて継承を実装することが望ましいです。
これはList<T>クラスの特徴の一つにすぎません。より詳細な説明は、以下の通りになります。
Dictionary<TKey,TValue> — 一意のキーに一致する数値のセットからのディクショナリです。この時、一つのキーに複数の数値がバインドされることがあります。オブジェクト作成の段階で、ユーザーは数値とキーのタイプを定義します。説明から分かるように、Dictionary<TKey,TValue>クラスは、ハッシュテーブルの役割に最適です。Dictionary<TKey,TValue>を使った作業をスピードアップする為には、IEqualityComparer<T>クラスからの子である新しいクラスを作成し、2つの関数を再ロードする必要があります。
- bool Equals(T x,T y) — xがyと等しい場合、関数はtrueを返し、その他の場合にfalse を返します。
- int GetHashCode(T obj) — 関数はobjオブジェクトからのハッシュコードを返します。
MQL5ためのRegularExpresiionsライブラリでは、この特徴は全てのディクショナリの為に使用されます。
StringEqualityComparerクラスの実装:
class StringEqualityComparer : public IEqualityComparer<string> { public: //--- Methods: //+------------------------------------------------------------------+ //| Determines whether the specified objects are equal. | //+------------------------------------------------------------------+ virtual bool Equals(string x,string y) { if(StringLen(x)!=StringLen(y)){ return (false); } else { for(int i=0; i<StringLen(x); i++) if(StringGetCharacter(x,i)!=StringGetCharacter(y,i)){ return (false); } } return (true); } int GetHashCode(string obj) { return (::GetHashCode(obj)); } };
文字列がキーとなるDictionary<TKey,TValue>クラスに属する新しいオブジェクト作成の際に、コンストラクタでパラメータとしてStringEqualityComparerオブジェクトへの指定を引き渡します。
Dictionary<string,int> *dictionary= new Dictionary<string,int>(new StringEqualityComparer);
LinkedList<T> — これは一連の要素を含むデータ構造体です。各要素は情報部分と、前と次の要素へのポインタを含んでいます。したがって、2つの要素は相互に参照されます。このようなリストのノードはLinkedListNode<T>オブジェクトによって実装されます。このようなノードにはそれぞれ、標準セットが含まれています(数値、リストへのポインタ、ノード接続のポインタ)。
また、上記の3つのコレクション全ての為に列挙子が実装されました。列挙子— これは一般的なIEnumerator<T>インターフェイスであるオブジェクトです。IEnumerator<T>は、構造体に関係なくコレクションによるフルクロールの実装を可能にします。
列挙子の取得の為には、IEnumerableインターフェイスを実装するクラスのオブジェクトからのGetEnumerator()メソッドを呼び出す必要があります。
List<int>* list = new List<int>(); list.Add(0); list.Add(1); list.Add(2); IEnumerator<int> *en = list.GetEnumerator(); while(en.MoveNext()) { Print(en.Current()); } delete en; delete list;
この例ではリスト全体で実行し、各数値を出力します。これは全て通常のforサイクルを編成することで行うことができますが、多くの場合列挙子を使用した方が便利です。このような解決法は、Dictionary<TKey,TValue>によるパスを実行する必要がある場合に適しています。
2.2. MQL5の為のRegularExpressionsライブラリの特徴
1. 正規表現の全機能を私達の計画に接続する為には、次のフラグメントを追加する必要があります:
#include <RegularExpressions\Regex.mqh>2.MQL5言語に名前空間が欠如している為(internalのようなアクセス修飾子)、私達は全てのライブラリの内部クラスやそれらの為の多くのメソッドへのアクセスを持っています。これは正規表現を使った動作の為には余計なものです。
正規表現を使った動作の為に、次のクラスを見ていきましょう。
- Capture — 正常に終了した単一の部分式キャプチャの結果を表します。
- CaptureCollection — 1 つのキャプチャグループによって作成されたキャプチャのセットを表します。
- Group — 単一のキャプチャグループからの結果を表します。
- GroupCollection — 1回の検索一致でキャプチャされたグループのセットを返します。
- Match — 正規表現の単一の一致からの結果です。
- MatchCollection — 正規表現パターンを入力文字列に繰り返し適用したときに、パターンに一致した一連の対象を表します。
- Regex — 変更不可の正規表現を表します。
上記のものに加えて、次のものを使用します。:
- MatchEvaluator — 正規表現の一致が検出される度に呼び出されるメソッドである関数へのポインタです。
- RegexOptions — 正規表現オプションを設定するために使用する列挙値を提供します。
RegexOptionsは、.Netからのオリジナルの列挙値の不完全なコピーであり、次の要素を含んでいます。
| パラメータ | 説明 |
|---|---|
| None |
パラメータが設定されていません。 |
| IgnoreCase |
検索時に大文字と小文字を区別しないことを指定します。 |
| Multiline | 複数行モードを指定します。 |
| ExplicitCapture | グループ名を捉えません。唯一の有効な選択は、明示的に指定されたグループの名前や番号です(?<名前> 表現の一部)。 |
| Singleline | 単一行モードを指定します。 |
| IgnorePatternWhitespace | パターンからエスケープが解除された空白を削除し、# でマークされたコメントを有効にします。 |
| RightToLeft | 検索が左から右ではなく右から左になされるように指定します。 |
| Debug | プログラムがデバッガの下で実行されるように指定します。 |
| ECMAScript | 式のECMAScript準拠の動作を有効にします。この値は、必ずIgnoreCase、Multiline、Compiledの各値と組み合わせて使用します。 |
これらのオプションはRegexクラスの新しいオブジェクトを作成したり、その静的メソッドを呼び出す時に使用されます。
これらの全てのクラス、ポインタ、列挙値の使用例は、Tests.mq5エキスパートアドバイザのソースコードで見ることができます。
3. .Netバージョンのように、このライブラリでは正規表現のストレージ(静的キャッシュメモリ)が実装されています。暗黙的正規表現(Regexクラスのインスタンス)は全てこのストレージに保存されます。このようなアプローチは、パターンが既存のもののいずれかに一致する場合に、正規表現を再構築する必要がなくなるので、スクリプトの動作をスピードアップすることができます。デフォルトでは、ストレージのサイズは15です。Regex::CacheSize()は、コンパイルされた正規表現の現在の静的キャッシュ内の最大エントリ数を取得または設定します。
4. 上記のストレージはクリアする必要があります。これを行うにはRegex::ClearCache()静的関数を呼び出します。必要なポインタやオブジェクトが失われる可能性が高い為、これは正規表現を使った作業を終了した後にのみ行うことをお勧めします。
5. C#言語の構文を使用することで、文字列の前に全ての書式マークを無視する為の'@'を配置することができます。MQL5ではこのようなアプローチは想定されていないので、正規表現のパターン内の全ての制御文字は明示的に表記する必要があります。
3. 取引履歴の選択例
この例では次の操作を念頭においています。
- .html形式ファイルのサンドボックスからの取引履歴の読み込み。
- 今後の使用の為の2つの表(『注文』表または『取引』表)から1つを選択する。
- 表の為のフィルターを選択する。
- フィルタリングされた表のグラフィック表示。
- フィルタリングされた表に基づく簡単な数学的統計。
- フィルタリングされた表を保存する機能。
これらの6つ全てが、TradeHistoryParsing.mq5エキスパートアドバイザで実装されています。
エキスパートアドバイザを使用するには、まず初めに取引履歴をダウンロードする必要があります。この為にはMetaTrader5取引ターミナルの『ツール』パネルの『履歴』タブを開きます。右クリックでダイアログボックスを開き、『レポート』の『HTML (InternetExplorer)で表示』を選択します。
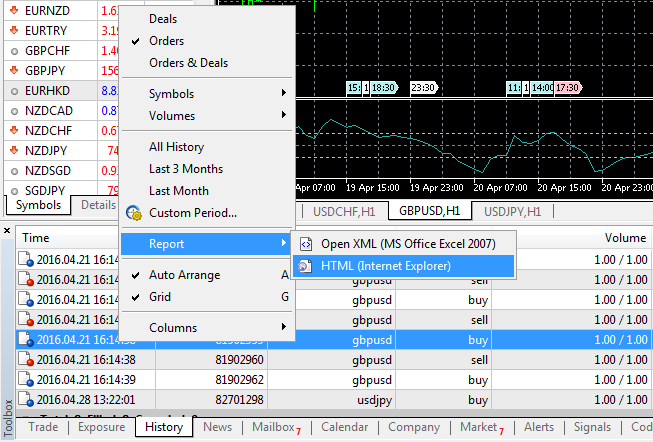
ファイルをサンドボックス(\MetaTrader 5\MQL5\Files)に保存しましょう。
エキスパートアドバイザの起動時に、ダイアログボックスで『インプット』タブを開き、file_name欄に私達のファイル名を入力します。
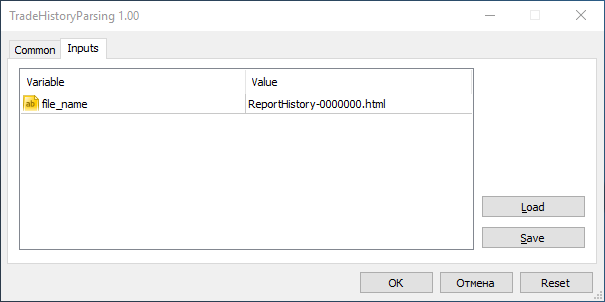
『OK』ボタンを押した後に、エキスパートアドバイザのインターフェイスが表示されます。
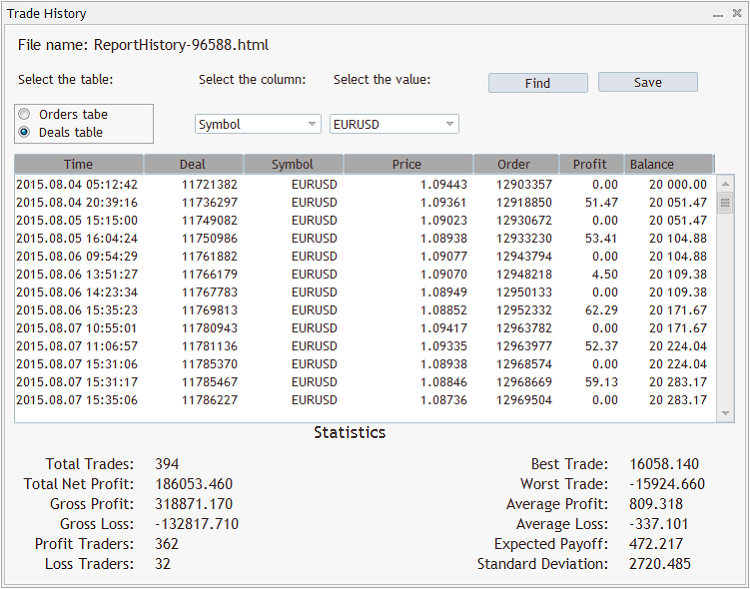
上述したように、2つの表はエキスパートアドバイザに、 List<OrderRecord*>とList<DealRecord*>の2つの型指定されたリストとして表示されます。
OrderRecordとDealRecordのクラスの為のコンストラクタは、表から1つの記録を提供する文字配列のパラメータとして取ります。
これらの配列の作成に、正規表現が必要になります。履歴全体の分析は、TradeHistoryクラスのコンストラクタで行われ、またこのクラスで両方の表の表現が格納され、そのフィルタリングメソッドが実装されています。このクラスのコンストラクタは、path(私達の場合では履歴の.htmlファイル名)という1つのパラメータを取ります。
TradeHistory(const string path) { m_file_name=path; m_handel= FileOpen(path,FILE_READ|FILE_TXT); m_list1 = new List<OrderRecord*>(); m_list2 = new List<DealRecord*>(); Regex *rgx=new Regex("(>)([^<>]*)(<)"); while(!FileIsEnding(m_handel)) { string str=FileReadString(m_handel); MatchCollection *matches=rgx.Matches(str); if(matches.Count()==23) { string in[11]; for(int i=0,j=1; i<11; i++,j+=2) { in[i]=StringSubstr(matches[j].Value(),1,StringLen(matches[j].Value())-2); } m_list1.Add(new OrderRecord(in)); } else if(matches.Count()==27) { string in[13]; for(int i=0,j=1; i<13; i++,j+=2) { in[i]=StringSubstr(matches[j].Value(),1,StringLen(matches[j].Value())-2); } m_list2.Add(new DealRecord(in)); } delete matches; } FileClose(m_handel); delete rgx; Regex::ClearCache(); }
このコンストラクタのコードからわかるように、取引履歴の分析の為に、私達は"(>)([^<>]*)(<)"のパターンを持つ1つの正規表現のみ使用します。このパターンを詳しく見ていきましょう。
| (>) | '>'文字の検索 |
| (^[<>]*) | 0回以上繰り返す'>'と'<'以外の任意の文字 |
| (<) | '<'文字の検索 |
この正規表現は'>'で始まり、'<'で終わる全てのサブストリングを検索します。それらの間にあるテキストは、'<'または'>'で始まってはいけません。簡単に言えば、まだ不要な括弧(後で削除する)がある.htmlファイルのタグの間のテストを取得します。全ての検出したサブストリングをMathcCollection(正規表現のパターンを満たし、ソース文字列で見つかった全てのサブストリングのコレクション)に保存します。.htmlファイルの構造から、一致数を数えるだけで、私達は私達の文字列が注文表の記録であるか、取引表の記録であるか、または他の文字列であるかを正確に判別することができます。一致数が23である場合、文字列は注文票の記録であり、もし一致数が27である場合、文字列は取引表の記録です。それ以外の場合は、文字列は私達にとって興味のあるものではありません。ここで私達のコレクションから、私達は全ての偶数の要素(奇数には"><"の文字列があります)を抽出し、先頭と末尾の文字をカットし、出来た文字列を配列に記録します。
in[i]=StringSubstr(matches[j].Value(),1,StringLen(matches[j].Value())-2);
この場合、各文字列の読み込み後に一致のコレクションを削除する必要があります。全てのファイルを読み込んだら、これを閉じて正規表現を削除し、正規表現のバッファをクリアする必要があります。
ここで表のフィルタリングを実装する必要があります(いくつかの欄や、そこから特定の数値を選択し、切り取った表を取得する)。私達のケースでは、リストからサブリストを取得する必要があります。この為に、私達は新しいリストを作成し、古いリストの全ての要素の完全な品分けを行い、もしリストが指定した条件を満たしている場合、これを新しいリストに追加することができます。
しかし、List<T>の為のFindAll(Predicate match)メソッドをベースにした他の方法もあります。これは、関数へのポインタである指定した述語の条件を満たす全ての要素を抽出します。
typedef bool (*Predicate)(IComparable*);
IComparableインターフェイスについては、すでに記述しました。
あとは、私達がリスト要素に適用または除外する、事前にわかっている基準のmatch関数自体を実装するだけです。私達の場合、これは列番号とその数値です。この課題の解決の為にOrderRecordとDealRecordクラスの継承である、RecordクラスにSetIndex(const int index)とSetValue(const string value)の2つの静的メソッドがあります。これらのメソッドは列番号とその数値を取り記録します。そして、これらのデータは検索の為の私達のメソッドの実装時に使用します。
static bool FindRecord(IComparable *value) { Record *record=dynamic_cast<Record*>(value); if(m_index>=ArraySize(record.m_data) || m_index<0) { Print("Iindex out of range."); return(false); } return (record.m_data[m_index] == m_value); }
ここでは、m_indexはSetIndexメソッドによって取得した静的変数、m_valueはSetValueメソッドで取得したものです。
ここで、私達に必要な列番号とその数値を指定し、私達のリストの切り取りバージョンを簡単に取得しましょう。
Record::SetValue(value); Record::SetIndex(columnIndex); List<Record*> *new_list = source_list.FindAll(Record::FindRecord);
これらのフィルタリングされた表は、エキスパートアドバイザのグラフィックインターフェイスに表示されます。
必要に応じて、これらのフィルタリングした表を.csvファイルに保存することができます。ファイルはResult.csvの名前のサンドボックスにも保存されます。
重要!ファイルを保存する時には、常に同じ名前が割り当てられます。したがって、2つ以上の表を保存する必要がある場合、それらを1つずつ保存し名前を変更する必要があります。それを行わないと、同じファイルの上書きが発生します。
4. エキスパートアドバイザの最適化結果の分析例
この例では、MetaTrader5ターミナルからのエキスパートアドバイザの最適化結果の.xmlファイルを処理します。ここでは最適化の間に取得したデータの為のグラフ表示や、それらのフィルタリング機能が実装されています。全てのデータは2つの表に分けられます。
- "Tester results table" — ここにはテストの間に取得した全ての統計データが含まれます。
- "Input parameters table" — ここには全ての入力パラメータの数値が保存されます。この表には、入力パラメータは10個までというリミットが設けられています。もしパラメータがこれ以上の場合、それらは表示されません。
フィルターの設定には、表のうちの1つにフィルタリングが行われる列名を選択し、数値の範囲を指定する必要があります。
例のグラフィックインターフェイスは次のようになります。
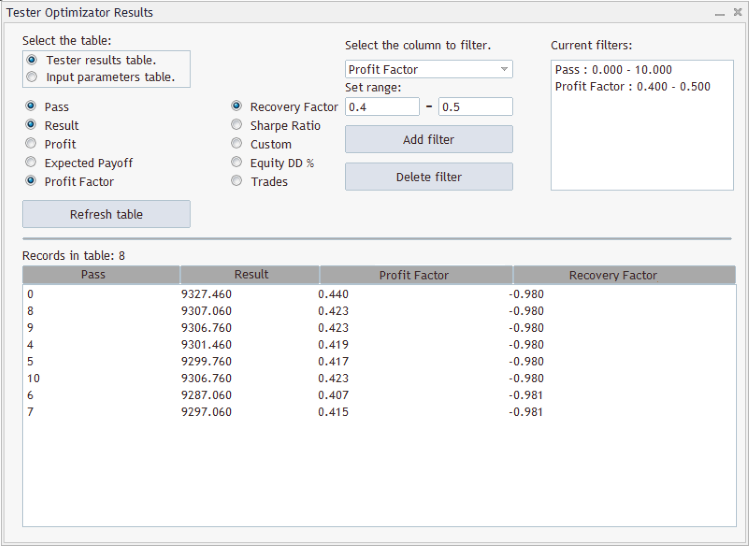
この図には、アクティブな列を持つ"Tester results table"の表が表示されます("Pass"、"Result"、"Profit Factor"、"Recovery Factor"、2つのフィルター)。
- "Pass"の列の数値は[0; 10]の範囲の数値になります。
- "Profit Factor"の列の数値は[0.4; 0.5]の範囲の数値になります。
5. MQL5のRegularExpressionsライブラリからの例の簡単な説明
記述した2つのエキスパートアドバイザの他に、MQL5のRegularExpressionsライブラリに20の例を添付します。正規表現とこのライブラリ全体の様々な機能が実装されています。これらの全てはTests.mq5エキスパートアドバイザにあります。
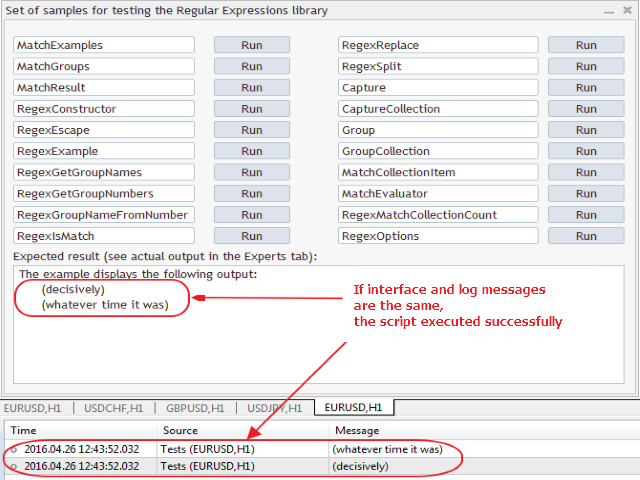
例の中からそれぞれにライブラリのどのような機能と特徴が作用しているかを見ていきましょう。
- MatchExamples — MatchCollection作成またはMatch.NextMatch()メソッドの使用を介して、全ての一致(Match)の可能性のある2つのバージョンを表示します。
- MatchGroups — 別個のグループの記録(Group)の結果の取得方法と、それらを使用した今度の作業方法を表示します。
- MatchResult — 置換の指定されたパターンの拡張を返すMatch.Result(string)メソッドの使用方法をデモンストレーションします。
- RegexConstructor — Regexクラスの作成の3つの異なるバージョンを表示します(パターンベース、指定パラメータを持つパターン、タイムアウトする前に比較方法が一致を検索を試みる時間を指定するパラメータと数値を持つパターン)。
- RegexEscape — Regex::Escape(string)メソッドの動作をデモンストレーションします。
- RegexExample — 正規表現の作成プロセスとそれらの処理を表示します。
- RegexGetGroupNames — Regex.GetGroupNames(string)メソッドの使用例を表示します。
- RegexGetGroupNumbers — Regex.GetGroupNumbers(int)メソッドの使用例を表示します。
- RegexGroupNameFromNumber — Regex.GroupNameFromNumber(int)メソッドの使用例を表示します。
- RegexIsMatch — Regex::IsMatch()静的メソッドの全てのバージョンの使用例を表示します。
- RegexReplace — Regex::Replace()静的メソッドの主要なオプションの使用例を表示します。
- RegexSplit — Regex::Split()静的メソッドの主要なオプションの使用例を表示します。
- Capture — 正常に終了した単一の部分式キャプチャ(Capture)の結果の使用例です。
- CaptureCollection — 1つのキャプチャグループによって作成されたキャプチャのセット(CaptureCollection)の使用例です。
- Group — 単一のキャプチャグループ(Group)からの結果の使用例です。
- GroupCollection — 1回の検索一致でキャプチャされたグループのセット(GroupCollection)の使用例です。
- MatchCollectionItem — Regex::Matches(string,string)静的メソッドによるMatchCollectionの作成。
- MatchEvaluator — MatchEvaluator型の関数へのポインタの作成とその使用例です。
- RegexMatchCollectionCount — MatchCollection.Count()メソッドのデモンストレーションです。
- RegexOptions — 正規表現処理へのRegexOptionsパラメータの影響をデモンストレーションします。
多くの例は、機能的に重複するもので、多くはライブラリの動作テストの為のものです。
まとめ
この記事では、正規表現の機能とその使用について簡単にご説明しました。より詳細な説明については、下記のリンクから記事をお読みいただくことをお勧めします。.Netの正規表現の構文の大部分は、MQL5への実装と一致しているので、部分的ではあってもMicrosoftの全てのヘルプを参考にすることができます。Internalフォルダのクラスも同様に関連しています。
リンク
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/2432
 マーケット用の任意の非標準チャートのインディケータを作成するには
マーケット用の任意の非標準チャートのインディケータを作成するには
 手動取引のサポーターを作成する
手動取引のサポーターを作成する
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索