
グループ化されたファイルの処理

はじめに
ファイルを1件読んだり書いたりすることに問題はありません。記事 File Operations via WinAPI で述べられているように、このために WinAPI を使ったとしてもです。ですが、特定のファイル内の位置と拡張しだけがわかっていて、ファイル名が正確に解らない場合はどうしたらよいのでしょうか?もちろん、必要な名前をパラメータとしてマニュアルで入力することは可能ですが、そのようなファイルが10件以上もあったらどうしたらよいのでしょうか?同類のファイル処理をを所定フォルダにグループ化する方法が必要です。このタスクは、kernel32.dll にインクルードされている関数 FindFirstFile()、 FindNextFile()、FindClose() によって効率よく解決することができます。
関数 FindFirstFile()
この関数の説明は http://msdn.microsoft.com/en-us/library/aa364418(VS.85).aspx の所定の msdn にあります。
HANDLE WINAPI FindFirstFile( __in LPCTSTR lpFileName, __out LPWIN32_FIND_DATA lpFindFileData );
この説明によると、関数は検索条件を満たす見つかったファイルのディスクリプタを返します。検索条件はファイル検索のパスとファイル名として可能性のある名前を持つ変数 lpFileName で指定されます。この関数は、検索をマスクによって指定できる点で便利です。たとえばマスク "C:\folder\*.txt" によってファイルを見つけるのです。この関数はフォルダ "C:\folder" で見つかった一番最初のファイルで txt の拡張子を持つものを返します。
戻された関数の結果は MQL4 の 'int' タイプです。入力パラメータを渡すには、'string' タイプを使います。第2パラメータとしてこの関数に何を渡すか、そのパラメータをあとでどのように処理するか整理する必要があります。この関数はおよそ以下のようにインポートされます。
#import "kernel32.dll" int FindFirstFileA(string path, .some second parameter); #import
ここで、既知のライブラリ kernel32.dll があるのがわかります。ただし関数名はFindFirstFile() ではなく、 FindFirstFileA() として指定されます。これはこのライブラリ内の多くの関数にはバージョンが2つあることによります。ユニコードの文字列を処理するもので、文字 'W'(FindFirstFileW) が名前に付け加えられているもの、同時に 'A'(FindFirstFileA)が付け加えられ ANSI を処理するものです。
次に、以下のように記述される関数の第2パラメータを整理する必要があります。
lpFindFileData [out] -見つけられたファイルまたはディレクトリに関する情報を受け取る WIN32_FIND_DATA ストラクチャに対するポインター。
それは、それが特定のストラクチャ WIN32_FIND_DATA に対するポインターであることを意味します。この場合、ストラクチャとは PC RAM の一定の領域を言います。この領域(アドレス)に対するポインターが関数に渡されるのです。メモリはデータ配列によって MQL4 に割り当てます。ポインターは文字 '&' で指定されます。そうして、ポインターに渡す必要なメモリサイズをバイト数で知る必要があるだけです。以下はストラクチャ記述です。
typedef struct _WIN32_FIND_DATA {
DWORD dwFileAttributes;
FILETIME ftCreationTime;
FILETIME ftLastAccessTime;
FILETIME ftLastWriteTime;
DWORD nFileSizeHigh;
DWORD nFileSizeLow;
DWORD dwReserved0;
DWORD dwReserved1;
TCHAR cFileName[MAX_PATH];
TCHAR cAlternateFileName[14];
} WIN32_FIND_DATA,
MQL4 では、DWORD、TCHAR、FILETIME などのタイプはありません。DWORD は4バイト使うことが判っています。MQL4 での int のようにです。TCHAR には1バイトの内部表現があります。ストラクチャ WIN32_FIND_DATA のトータルサイズをバイトで計算するには、ただ FILETIME が何であるかはっきりさせる必要があります。
typedef struct _FILETIME {
DWORD dwLowDateTime;
DWORD dwHighDateTime;
} FILETIME
FILETIME には2つ DWORD があることが判りました。それは DWORD が8バイトになることを意味します。これをすべて表にします。
| タイプ | バイトサイズ |
|---|---|
| DWORD | 4 |
| TCHAR | 1 |
| FILETIME | 8 |
次に、ストラクチャ WIN32_FIND_DATA のサイズを計算し、そのどこに何が見つかるか視覚化します。
| タイプ |
バイトサイズ | 備考 |
|---|---|---|
| dwFileAttributes | 4 | ファイル属性 |
| ftCreationTime | 8 | ファイル/フォルダ作成時刻 |
| ftLastAccessTime | 8 | 最終アクセス時刻 |
| ftLastWriteTime | 8 | 最終書き込み時刻 |
| nFileSizeHigh | 4 | 最大バイトサイズ |
| nFileSizeLow | 4 | 最小バイトサイズ |
| dwReserved0 | 4 | 通常は定義されず使用されません。 |
| dwReserved1 | 4 | 将来のために予約されています。 |
| cFileName[MAX_PATH] | 260 (MAX_PATH = 260) | File name |
| cAlternateFileName[14] | 14 | 8.3 形式での代替名 |
ストラクチャのサイズ合計は:4 + 8 + 8 + 8 + 4 + 4 + 4 +4 + 260 +14 = 318 バイト、となります。

上の数字でおわかりのように、ファイル名は45バイト目から始まっています。その前の44倍とはさまざまな補助的情報を持っています。第2パラメータとして、318 バイトで MQL4 のストラクチャをいくらか関数 FindFirstFile() に渡す必要があります。タイプの配列を使うのがもっとも便利です。それは必要サイズより小さくなることがないと思われます。318 を 4 で割り('int' タイプの内部表現は 4 バイトであるため)、79.5 を取得します。それを一番近い大きな数字に四捨五入すると、80エレメントの配列が必要であることが解ります。
ここでの関数のインポート自体は、以下のような表記になります。
#import "kernel32.dll" int FindFirstFileA(string path, int & answer[]); #import
今回は名前の末尾に文字 'A' を持つ ANSI コーディング用の関数バージョン FindFirstFileA() を使用しています。「回答」配列はリンクによって渡され、WIN32_FIND_DATA のストラクチャで埋められる役目を果たします。以下は呼出し例です。
int win32_DATA[80]; int handle = FindFirstFileA(TerminalPath() + "\experts\*.mq4",win32_DATA);
関数 FindNextFileA() および FindClose()
関数 FindNextFileA() は第1パラメータとして関数 FindFirstFileA()、または別の関数 FindNextFileA() に対するもっと以前の呼出しによって事前に取得されたファイルの「ハンドル」を受け取ります。第2パラメータは同様です。関数 FindClose() はただ検索を終了します。関数データをインポートする全記述が以下のようになるのはそのためです。
#import "kernel32.dll" int FindFirstFileA(string path, int & answer[]); bool FindNextFileA(int handle, int & answer[]); bool FindClose(int handle); #import
次に、配列 'answer[]' に書き込まれたファイル名を抽出する方法を学ぶ必要があります。
ファイル名取得
ファイル名は45バイト目から304バイト目までの配列に含まれます。'int' タイプは4バイトです。よって、配列を文字で書きだすとすれば、各配列エレメントは4文字です。そのため、ファイル名の最初の文字を参照するためには、'answer[]' 配列の 44/4 = 11 エレメントを飛ばします。ファイル名は 65 (260/4=65) の配列エレメントのつながりの内部にあり、'answer[11]' から開始し、'answer[76]' で終了しています。
よって、配列 'answer[]' から各4文字のブロックでファイル名を取得します。'int' 数は32ビットのシーケンスを表します。そこでは各8ビットごとに4ブロックを表します。
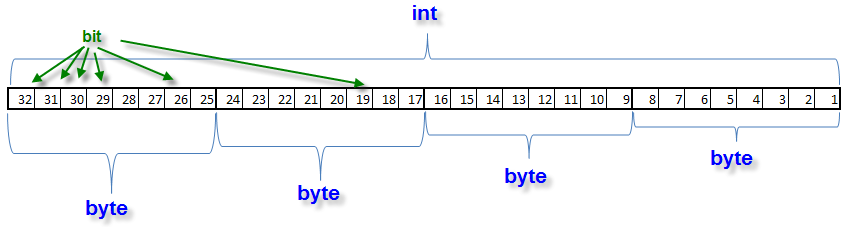
右が若いバイト、左が古いバイトとなっています。ビットは昇順で順番が付けられています。すなわち、1番目のビットから8番目までが一番若いバイトです。ビット単位処理によって必要なバイトを抽出することができます。一番若いバイト値を取得するには、9番目から32番目までの全ビットをゼロで埋めます。これは理論演算 AND によって行います。
int a = 234565; int b = a & 0x000000FF;
ここで 0x000000FF は、9番目からスタートし、全箇所にゼロ値を持つ32ビット整数です。 同時に1から8は1です。よって、取得されるナンバー b はナンバー a の1バイト(一番若いバイト)のみです。われわれは関数CharToStr() によって1文字の文字列に取得バイト(文字コード)を返します。
いいですね。1番目の文字を取得しました。では次の文字はどのように取得するのでしょうか?とても簡単です。ビット単位で8ビット右へ移動すると、2番目のビットが一番若いビットを置き換えます。そして、すでに分かっている理論処理 ANDを適用するのです。
int a = 234565; int b = (a >>8) & 0x000000FF;
ご推察どおり、3番目のバイトは16ビット移動することで取得され、同時に一番古いものは24ビットの移動によって取得されます。これにより、'int' タイプの配列エレメント1つから4文字を抽出することができるのです。以下はファイル名の最初の4文字が 'answer[]' 配列からどのように取得されるかを示しています。
string text=""; int pos = 11; int curr = answer[pos]; { text = text + CharToStr(curr & 0x000000FF) +CharToStr(curr >> 8 & 0x000000FF) +CharToStr(curr >> 16 & 0x000000FF) +CharToStr(curr >> 24 & 0x000000FF); } Print("text = ", text);
'buffer' という名前の渡された配列からテキスト文字列を返す別の関数を作成します。
//+------------------------------------------------------------------+ //| read text from buffer | //+------------------------------------------------------------------+ string bufferToString(int buffer[]) { string text=""; int pos = 10; for (int i=0; i<64; i++) { pos++; int curr = buffer[pos]; text = text + CharToStr(curr & 0x000000FF) +CharToStr(curr >> 8 & 0x000000FF) +CharToStr(curr >> 16 & 0x000000FF) +CharToStr(curr >> 24 & 0x000000FF); } return (text); }
これで、ストラクチャからファイル名を取得する問題は解決します。
ソースコードで全 Expert Advisor のリストを取得する
シンプルなスクリプトが上記関数の特性を示します。
//+------------------------------------------------------------------+ //| CheckFindFile.mq4 | //| Copyright © 2008, MetaQuotes Software Corp. | //| https://www.metaquotes.net/ | //+------------------------------------------------------------------+ #property copyright "Copyright © 2008, MetaQuotes Software Corp." #property link "https://www.metaquotes.net/" #property show_inputs #import "kernel32.dll" int FindFirstFileA(string path, int& answer[]); bool FindNextFileA(int handle, int& answer[]); bool FindClose(int handle); #import //+------------------------------------------------------------------+ //| script program start function | //+------------------------------------------------------------------+ int start() { //---- int win32_DATA[79]; int handle = FindFirstFileA(TerminalPath() + "\experts\*.mq4",win32_DATA); Print(bufferToString(win32_DATA)); ArrayInitialize(win32_DATA,0); while (FindNextFileA(handle,win32_DATA)) { Print(bufferToString(win32_DATA)); ArrayInitialize(win32_DATA,0); } if (handle>0) FindClose(handle); //---- return(0); } //+------------------------------------------------------------------+ //| read text from buffer | //+------------------------------------------------------------------+ string bufferToString(int buffer[]) { string text=""; int pos = 10; for (int i=0; i<64; i++) { pos++; int curr = buffer[pos]; text = text + CharToStr(curr & 0x000000FF) +CharToStr(curr >> 8 & 0x000000FF) +CharToStr(curr >> 16 & 0x000000FF) +CharToStr(curr >> 24 & 0x000000FF); } return (text); } //+------------------------------------------------------------------+
ここで関数 FindFirstFileA() およびFindNextFileA() の呼出し後、配列 win32_DATA(ストラクチャ WIN32_FIND_DATA)が『空』状態、すなわち配列の全エレメントがゼロで書き込まれる、に変わります。
ArrayInitialize(win32_DATA,0);
これをしなければ、以前の呼出しからのファイル名『断片』がプロセスに浸透し、無意味な言葉を入手することになります。
実装例:ソースコードのバックアップ作成
上で述べた内容の実践的特性を示す簡単な例が特殊ディレクトリでのソースコードバックアップ作成です。このために、本稿で考察される関数を記事 WinAPI によるファイル処理 にあるものと組み合わせます。そうして以下のシンプルなスクリプト backup.mq4 を取得します。添付ファイルにフルコードがありますので参照ください。ここでは、両記事で述べている関数をすべて使う start() 関数部分のみです。
//+------------------------------------------------------------------+ //| script program start function | //+------------------------------------------------------------------+ int start() { //---- string expert[1000]; // must be enough string EAname=""; // EA name int EAcounter = 0; // EAs counter int win32_DATA[80]; int handle = FindFirstFileA(TerminalPath() + "\experts\*.mq4",win32_DATA); EAname = bufferToString(win32_DATA); expert[0] = EAname; ArrayInitialize(win32_DATA,0); int i=1; while (FindNextFileA(handle,win32_DATA)) { EAname = bufferToString(win32_DATA); expert[i] = EAname; ArrayInitialize(win32_DATA,0); i++; if (i>=1000) ArrayResize(expert,2000); // now it will surely be enough } ArrayResize(expert, i); int size = i; if (handle>0) FindClose(handle); for (i = 0 ; i < size; i++) { Print(i,": ",expert[i]); string backupPathName = backup_folder + "experts\\" + expert[i]; string originalName = TerminalPath() + "\\experts\\" + expert[i]; string buffer=ReadFile(originalName); WriteFile(backupPathName,buffer); } if (size > 0 ) Print("There are ",size," files were copied to folder "+backup_folder+"experts\\"); //---- return(0); } //+------------------------------------------------------------------+
これがスクリプトの動作方法です。
おわりに
同一タイプのファイルグループを処理する方法を示しました。ご自身のロジックによって上記関数を使用してファイルを読み、処理することができます。Expert Advisor の使用、または異なるフォルダの2組のファイルを同期させることで、タイムリーなバックアップを作成し、データベースからクオートをインポートする、などが可能です。DLLの使用を制御し、ライブラリを拡張子ex4 を持つ第三者ファイルに接続されないようにすることが推奨されます。軌道しているプログラムがご自身の PC のデータを破損しないよう確認する必要があります。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/1543
 MQL4 によるHTML チュートリアル
MQL4 によるHTML チュートリアル
 一般的なトレーディングシステムを基にしたExpert Advisor と売買ロボット最適化の錬金術(パート7)
一般的なトレーディングシステムを基にしたExpert Advisor と売買ロボット最適化の錬金術(パート7)
 高速で再描画しない ZigZag の書き方
高速で再描画しない ZigZag の書き方
 WinAPI によるファイル処理
WinAPI によるファイル処理
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索