OpenCL : tests de l'implémentation interne dans MQL5 - page 29
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
...
--
Faites 512 et voyez ce que vous obtenez. N'ayez pas peur de croquer le programme, cela ne fera que l'améliorer. :) Quand vous l'aurez fait, postez-le ici.
OK ! A 512 passages et 144000 bars :
Bien et si 60 est optimal, alors généralement cool :
//---
C'est-à-dire, sur l'ordinateur portable le plus faible présenté dans ce fil, voici le résultat. C'est très prometteur.
//---
Malheureusement, je ne suis pas en mesure de discuter librement du sujet, car je n'ai même pas abordé l'article de Joo et les réseaux neuronaux, tandis que je n'ai jamais creusé la question d'OpenCL. Je ne peux pas utiliser tel ou tel code sans en comprendre chaque ligne. Je veux tout savoir. ))) Je travaille toujours sur le moteur du programme de trading. Il y a tellement de choses à faire que j'ai déjà la tête qui tourne. )))
J'ai augmenté CountBars d'un facteur 30 (à 4 320 000), j'ai décidé de vérifier la résistance de la pierre à la charge.
Peu importe : ça marche, ça se réchauffe, mais ça ne transpire pas trop. La température augmente lentement, mais a déjà atteint la saturation.
La ligne rouge est la température, la ligne verte est la charge des cœurs.
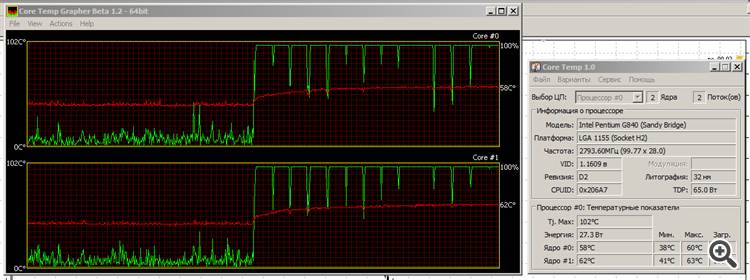
C'est pourquoi j'aime le spécimen Sandy Bridge d'Intel : il est "vert". Oui, les graphismes ne sont pas géniaux, mais nous verrons ce que devient Ivy Bridge......
C'est pourquoi j'aime le modèle Sandy Bridge d'Intel : il est "vert". Oui, les graphismes ne sont pas super, mais on verra ce que devient Ivy Bridge...Oh. (gloussements) Ça, c'est un vrai test de résistance. :) Le mien serait probablement mort maintenant.
Puis ce qu'un Haswell et ensuite un Rockwell un peu plus tard... )))
Un exemple d'implémentation d'une fougère de Barnsley en OpenCL.
Le calcul est basé sur l'algorithme Chaos Game(exemple) et utilise un générateur de nombres aléatoires avec une base de génération qui dépend de l'ID du fil et renvoie get_global_id(0) pour créer des trajectoires uniques.
Lors de la mise à l'échelle, le nombre de points requis pour maintenir la qualité de l'image croît de manière quadratique. Cette mise en œuvre suppose donc que chaque instance du noyau dessine un nombre fixe de points qui se trouvent dans la zone visible.
Le nombre de fils estimés est spécifié à la ligne 191 :
le nombre de points est à la ligne 233 :
UPD
IFS-fern.mq5 - Analogique du CPU
A l'échelle=1000 :
J'ai fait trois couches de neurones 16x7x3. En fait, je l'ai fait avant-hier, je l'ai débogué aujourd'hui. Avant cela, les résultats ne correspondaient pas à la vérification avec le CPU - je ne vais pas décrire ici les raisons, du moins pas maintenant - j'ai trop sommeil. :)
Caractéristiques temporelles :
Demain je ferai l'Optimizer pour cette grille. Ensuite je m'occuperai de charger des données réelles et de finir le testeur jusqu'aux calculs réalistes vérifiables avec MT5-tester. Ensuite je m'occuperai du générateur MLP+cl-codes des grilles pour leur optimisation.
Je ne poste pas le code source par cupidité, mais ex5 est inclus pour ceux qui voudraient le tester sur leur matériel.
Je suis aussi stable que sous Poutine :
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CpuTime/GpuTime = 24.08037178786222
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Cpu МахResult==1.09311 at 771 pass
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CPU time = 176172 ms
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Gpu МахResult==1.09311 at 771 pass
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) GPU time = 7316 ms
2012.03.08 05:35:18 ParallelTester_00-02-j16x7x3z (EURUSD,H1) OpenCL init OK!
A propos, faites attention : au niveau du temps d'exécution du CPU, la différence entre votre système et le mien (basé sur un Pentium G840) n'est pas si grande.
Votre RAM est-elle rapide ? J'ai 1333 MHz.
Une dernière chose : il est intéressant que les deux cœurs soient chargés sur le CPU pendant les calculs. La chute brutale de la charge à la fin est postérieure à la fin des calculs. Qu'est-ce que ça veut dire ?
Je suis aussi stable que sous Poutine :
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CpuTime/GpuTime = 24.08037178786222
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Cpu МахResult==1.09311 at 771 pass
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CPU time = 176172 ms
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Gpu МахResult==1.09311 at 771 pass
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) GPU time = 7316 ms
2012.03.08 05:35:18 ParallelTester_00-02-j16x7x3z (EURUSD,H1) OpenCL init OK!
1) A propos, remarquez la différence entre votre système et le mien (basé sur un Pentium G840) en ce qui concerne le temps d'exécution du CPU.
2. votre RAM est-elle rapide ? J'ai 1333 MHz.
1. J'ai restauré mon overclocking pendant mon temps libre. Une fois, j'ai eu un très mauvais plantage (j'ai découvert plus tard que le cordon d'alimentation du disque était tombé), alors j'ai appuyé sur le bouton "MemoryOK" de la carte mère à la recherche d'un miracle. Après cela, il n'a toujours pas fonctionné, seuls les paramètres CMOS ont été remis par défaut. Maintenant, j'ai overclocké le processeur à 3840 MHz à nouveau, donc il fonctionne mieux maintenant.
2. Je n'arrive toujours pas à comprendre. :) En particulier, le benchmark, vers lequel Renat a montré le lien, montre 1600MHz. Windows affiche même 1033MHz :)))), en dépit du fait que la mémoire elle-même est de 2GHz, mais ma mère peut aller jusqu'à 1866 (au sens figuré).
Une dernière chose : il est intéressant de constater que les deux cœurs sont chargés lorsque je calcule sur le CPU. La forte baisse de la charge à la fin se situe après la fin des calculs. Qu'est-ce que cela signifierait ?
Alors peut-être que ce n'est pas du tout sur le GPU ? Le pilote est en place, mais... Ma seule explication est que le calcul est effectué sur CPU-OpenCL, uniquement, bien sûr, sur tous les cœurs disponibles et en utilisant les instructions vectorielles SSE. :)
La deuxième variante est qu'il compte simultanément sur le CPU et le LPU. Je ne sais pas comment ce support (CPU-LPU) est implémenté par le pilote, mais en principe je n'exclus pas une telle variante du démarrage du traitement opentCL aussi.
C'est ma spéculation, s'il y a lieu. Ou, comme il est de bon ton de l'écrire maintenant, "IMHO". ;)
J'en doute. D'autant plus que je n'ai que deux cœurs. D'où vient alors le bénéfice multiplié par 25 ?
Si vous avez Intel Math Kernel Library ou Intel Performance Primitives (je ne les ai pas téléchargés), il est possible... dans certains cas. Mais c'est peu probable, car ils pèsent des centaines de meg.
Je vais devoir voir ce que Google a à dire à ce sujet.
Mathemat : Aussi, de façon intéressante, mes calculs CPU ont les deux cœurs chargés.
Non, je voulais parler de calcul purement CPU sans aucun OpenCL. La charge est juste en dessous de 100 % où chaque noyau a des valeurs de charge comparables. Mais lors de l'exécution du code OpenCL, il passe à 100 %, ce qui peut facilement s'expliquer par le fonctionnement du GPU.